

데이터 통계 에이전트는 Google에서 만든 에이전트입니다. BigQuery 데이터에서 데이터 인사이트를 제공합니다. 데이터 통계 에이전트를 사용하면 SQL에 대한 사전 지식이 필요하지 않습니다. 이를 통해 정보에 입각한 데이터 기반 비즈니스 결정을 내릴 수 있으며 데이터 분석가는 더 복잡한 작업에 집중할 수 있습니다.
이 페이지에서는 Google Cloud 프로젝트 관리자가 Google Cloud 콘솔 및 REST API를 사용하여 데이터 통계 에이전트를 승인, 생성, 배포하는 방법을 설명합니다. 이 페이지에서는 최종 사용자가 에이전트를 사용하는 방법도 보여줍니다.
개요
데이터 인사이트 에이전트는 다음 작업을 수행하도록 설계되었습니다.
- 사용자의 의도 파악: 연결된 데이터 소스의 컨텍스트와 사용자의 자연어 질문을 분석하여 사용자의 목표를 파악합니다.
- SQL 생성: 이러한 이해를 바탕으로 사용자의 질문을 구문 및 의미적으로 올바른 SQL 쿼리로 변환합니다.
- 데이터 가져오기: 생성된 SQL을 실행하여 연결된 데이터 소스인 BigQuery 데이터 세트에서 관련 데이터를 직접 가져옵니다.
- 인사이트 제공: 검색된 데이터를 차트, 표와 같은 시각화 또는 텍스트 기반 요약으로 표시하여 사용자의 질문에 답합니다.
데이터 통계 에이전트에게 질문할 수 있는 쿼리의 예
데이터 통계 에이전트에게 물어볼 수 있는 질문의 예는 다음과 같습니다.
- 데이터 집계 및 시각화:
- '올해 2분기 라틴 아메리카 지역의 매출은 작년 2분기와 비교해 어때?'
- '이 지역에서 상위 5개 국가의 비교를 보여주는 막대 그래프를 그려 줘.'
- 추세 분석:
- '지난 6개월 동안 발신 통화량이 지역별로 어떻게 달라졌어?'
- '별점이 3개를 초과하는 리스본 호텔의 예약 패턴을 분석해 줘.'
- 데이터 마이닝:
- "고객이 상품을 구매할 때 총 판매 가치와 상관관계가 있는 요소는 무엇인가요? 관계를 보여주는 히트맵을 만들어 줘'라고 말합니다.
- 분석 및 보고:
- '기회 및 계정 표를 요약하고 주요 추세를 강조하는 짧은 보고서를 만들어 줘.'
시작하기 전에
Gemini Enterprise에서 데이터 통계 에이전트를 사용하려면 다음 단계를 따르세요.
- 안내에 따라 Gemini Enterprise를 시작하세요.
- 안내에 따라 Gemini Enterprise 라이선스를 구매합니다.
- 데이터 통계 에이전트에 액세스하려면 Google 계정 관리자에게 문의하세요.
- BigQuery 데이터를 준비합니다. 자세한 내용은 BigQuery 문서를 참고하세요.
- 에이전트를 최대한 활용하려면 BigQuery 데이터 세트의 데이터를 이해해야 합니다.
BigQuery 데이터에 대한 액세스 권한 부여
데이터 통계 에이전트가 BigQuery 데이터를 보고 쿼리할 수 있도록 에이전트 사용자에게 Identity and Access Management (IAM) 역할을 부여하세요.
- BigQuery 데이터 뷰어(
roles/bigquery.dataViewer) - BigQuery 작업 사용자(
roles/bigquery.jobUser) - BigQuery 메타데이터 뷰어 (
roles/bigquery.metadataViewer)
워크플로
데이터 통계 에이전트를 설정하고 사용하는 전체 워크플로는 다음과 같습니다.
- 승인 세부정보를 가져옵니다.
- Google Cloud 콘솔을 사용하거나 REST API를 사용하여 에이전트를 설정합니다.
- 사용자 및 사용자 권한 추가 또는 수정
- 상담사 인스턴스의 작업 상태 변경
- 에이전트 사용
승인 세부정보 가져오기
다음 단계에 따라 승인을 설정하세요. 획득한 세부정보는 데이터 통계 에이전트가 BigQuery 데이터에 연결하도록 승인하는 데 필요합니다.
Google Cloud 콘솔의 API 및 서비스에서 사용자 인증 정보 페이지로 이동합니다.
에이전트가 쿼리할 BigQuery 데이터 세트가 포함된 Google Cloud 프로젝트를 선택합니다.
사용자 인증 정보 만들기를 클릭하고 OAuth 클라이언트 ID를 선택합니다.
애플리케이션 유형에서 웹 애플리케이션을 선택합니다.
승인된 리디렉션 URI 섹션에 다음 URI를 추가합니다.
https://vertexaisearch.cloud.google.com/oauth-redirecthttps://vertexaisearch.cloud.google.com/static/oauth/oauth.html
만들기를 클릭합니다.
OAuth 클라이언트 생성됨 패널에서 JSON 다운로드를 클릭합니다.
다운로드한 JSON에는 선택한Google Cloud 프로젝트의 다음 세부정보가 포함됩니다. 승인 리소스를 만들려면 이러한 세부정보가 필요합니다.
- Client ID(클라이언트 ID): CLIENT_ID
- 승인 URI:
앱을 승인하려면 OAuth 사용자 인증 정보 JSON 파일의 세부정보를 사용하여 특정 승인 URI를 구성해야 합니다. 다음 템플릿을 복사하고 자리표시자를 특정 값으로 바꿉니다.
승인 URI 템플릿
https://accounts.google.com/o/oauth2/v2/auth?client_id=YOUR_CLIENT_ID&redirect_uri=https%3A%2F%2Fvertexaisearch.cloud.google.com%2Fstatic%2Foauth%2Foauth.html&scope=YOUR_CUSTOM_SCOPES&include_granted_scopes=true&response_type=code&access_type=offline&prompt=consent
매개변수 분석
URI가 올바르게 작동하는지 확인하려면 다음 필드를 확인하세요.
매개변수 값 또는 작업 client_id다운로드한 JSON에 있는 client_id로 바꿉니다.redirect_uri변경하지 마세요. https://vertexaisearch.cloud.google.com/static/oauth/oauth.html이어야 합니다.scope조치 필요: 애플리케이션에 필요한 Google API 범위를 나열합니다(예: https://www.googleapis.com/auth/bigquery). 여러 범위를 사용하는 경우 공백으로 구분합니다. 공백은 URL에서%20이 됩니다.include_granted_scopestrue이어야 합니다.response_type승인 코드를 받으려면 code이어야 합니다.access_type갱신 토큰을 수신하도록 하려면 offline로 설정합니다.prompt사용자에게 항상 동의 화면이 표시되도록 하려면 consent로 설정합니다.- 토큰 URI:
https://oauth2.googleapis.com/token - 클라이언트 보안 비밀: CLIENT_SECRET
Google Cloud 콘솔을 사용하여 에이전트 설정
이 섹션에서는 Google Cloud 콘솔을 사용하여 데이터 통계 에이전트 인스턴스를 승인, 생성, 배포하는 방법을 보여줍니다. 생성된 에이전트에 액세스할 수 있는 사용자를 결정하는 사용자 권한을 추가할 수도 있습니다.
에이전트 인스턴스 승인 및 만들기
다음 단계에 따라 데이터 통계 에이전트 인스턴스를 승인하고 만드세요.
Google Cloud 콘솔에서 Gemini Enterprise로 이동합니다.
에이전트를 만들 앱을 선택합니다.
메뉴에서 에이전트를 클릭합니다.
에이전트 페이지에 기존 에이전트가 표시됩니다.
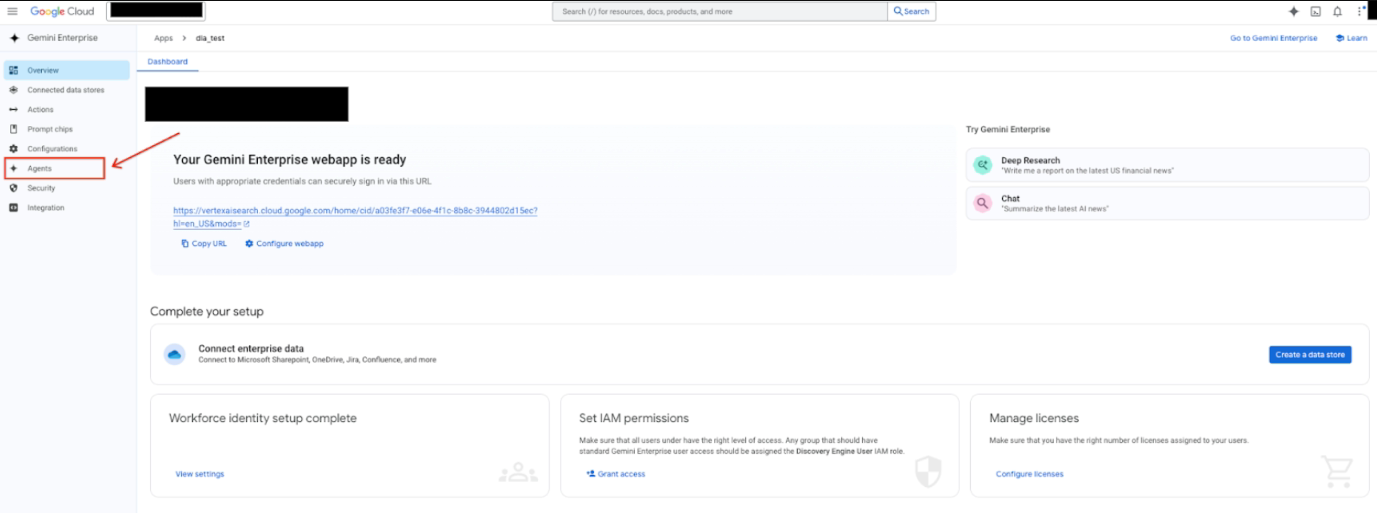
에이전트를 클릭합니다. 에이전트 추가를 클릭합니다.
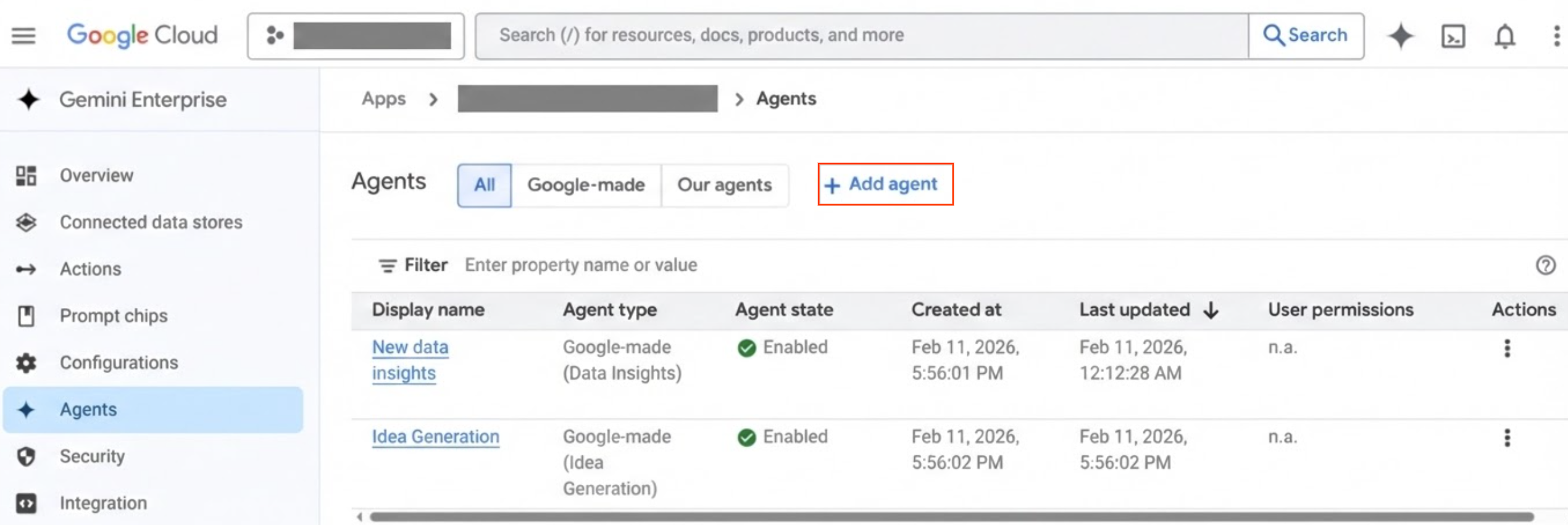
에이전트 추가를 클릭합니다. 에이전트 만들기 창에서 Google 에이전트를 선택한 다음 추가를 클릭합니다.
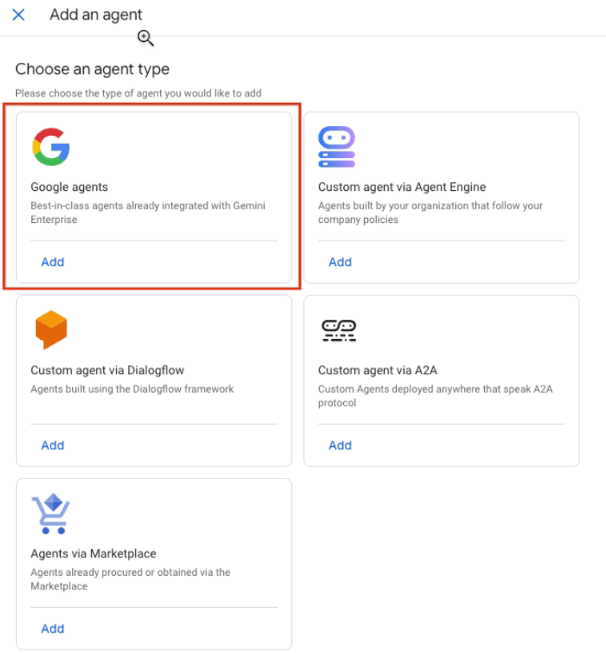
Google 상담사 선택 데이터 에이전트 카드에서 만들기를 클릭합니다.
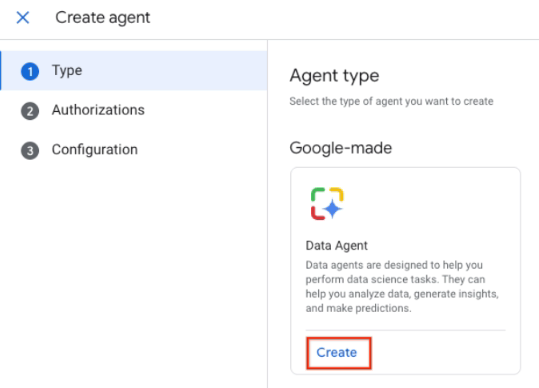
데이터 에이전트 만들기 승인에서 승인 추가를 클릭하고 승인 세부정보를 입력합니다. 자세한 내용은 승인 획득을 참고하세요.
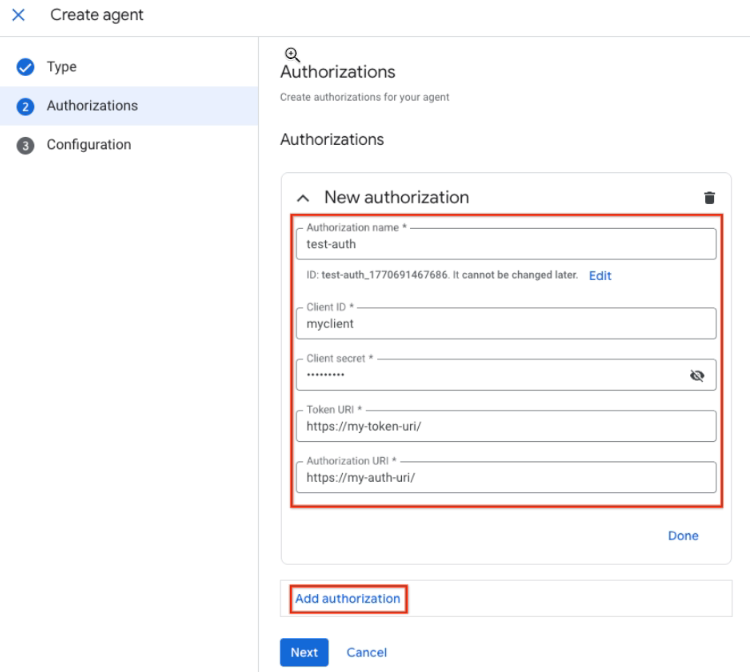
승인 세부정보 입력 완료를 클릭합니다.
다음을 클릭합니다.
다음과 같이 에이전트를 구성합니다.
에이전트 이름과 설명을 입력합니다.
BigQuery 데이터 세트에서 찾아보기를 클릭하고 다음 중 하나를 실행합니다.
- 사용 가능한 데이터 세트를 선택하고 선택을 클릭합니다.
- 필요한 BigQuery 데이터 세트의 경로를 입력하고 검색을 클릭한 다음 선택하고 선택을 선택합니다.
선택사항: 고급 옵션을 보려면 더보기를 클릭합니다.
올바른 테이블 액세스 옵션을 선택합니다. 허용 목록을 적용하려면 다음 단계를 따르세요.
또는 차단 목록을 사용하는 경우 제한된 테이블의 경로를 지정합니다.
선택사항: 자연어를 SQL로 변환하는 방식을 맞춤설정하기 위해 자연어 쿼리 구성을 정의합니다. 에이전트의 출력 품질을 개선하기 위해 자연어 질문, 예상되는 SQL 출력, 예상되는 대답의 예를 제공할 수 있습니다.
- 스키마 설명: BigQuery 데이터 세트의 스키마를 설명하는 자연어 문자열입니다.
- 자연어 쿼리의 SQL 변환 프롬프트: 자연어 쿼리가 SQL 명령어로 변환됩니다.
(선택사항) SQL 쿼리로 변환된 자연어 쿼리의 예시를 추가합니다.
- 쿼리: SQL 쿼리로 변환해야 하는 자연어 쿼리의 예입니다. 예를 들어 '캘리포니아에 거주하는 고객의 이름과 이메일 주소는 뭐야?'라고 말하면 됩니다.
- 예상 SQL: 자연어 질문에 해당하는 SQL 쿼리의 예를 보여주는 문자열입니다. 예를 들어
customers라는 BigQuery 테이블이 있다고 가정해 보겠습니다. 그러면 예상되는 SQL 쿼리는SELECT customer_name, email FROM customers WHERE state = 'California'가 됩니다. - 예상 응답: 예상 SQL 쿼리를 실행하여 쿼리에 대한 예상 답변을 제공하는 문자열입니다.
예를 들면 다음과 같습니다.
Here are the names and email addresses of your customers in California: \ * Customer name: Lara B, Email address: 222larabrown@gmail.com \ * Customer name: Alex A, Email address: baklavainthebalkans@gmail.com \ * Customer name: Bola C, Email address: cloudysanfrancisco@gmail.com \
만들기를 클릭합니다.
데이터 통계 에이전트 인스턴스가 에이전트 목록에 표시됩니다.
에이전트 작업을 시작하려면 에이전트 상태 열에 인스턴스가 사용 설정됨으로 표시될 때까지 기다립니다.
REST API를 사용하여 에이전트 설정
이 섹션에서는 REST API를 사용하여 데이터 통계 에이전트 인스턴스를 승인하고, 만들고, 배포하는 방법을 설명합니다.
에이전트 승인
관리자는 Gemini Enterprise에서 승인 리소스를 만들어야 합니다. 이렇게 하면 데이터 인사이트 에이전트가 BigQuery 데이터에 액세스할 수 있습니다.
승인 리소스를 만듭니다.
REST
다음 샘플은
authorizations.create메서드를 사용하여 승인 리소스를 만드는 방법을 보여줍니다.curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_NUMBER" \ "https://discoveryengine.googleapis.com/v1alpha/projects/PROJECT_NUMBER/locations/LOCATION/authorizations?authorizationId=AUTHORIZATION_ID" \ -d '{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/authorizations/AUTHORIZATION_ID", "serverSideOauth2": { "clientId": "CLIENT_ID", "clientSecret": "CLIENT_SECRET", "authorizationUri": "AUTHORIZATION_URI", "tokenUri": "https://oauth2.googleapis.com/token" } }'다음을 바꿉니다.
PROJECT_NUMBER: Google Cloud 프로젝트 수LOCATION: Google Cloud 프로젝트의 위치입니다.AUTHORIZATION_ID: 승인 리소스를 식별하기 위해 제공해야 하는 ID입니다.CLIENT_ID: 이전 단계에서 가져온 클라이언트 ID입니다.CLIENT_SECRET: 이전 단계에서 획득한 클라이언트 보안 비밀번호입니다.AUTHORIZATION_URI: 이전 단계에서 획득한 승인 URI입니다.
에이전트 인스턴스 만들기
Google Cloud 프로젝트 관리자는 데이터 통계 에이전트 인스턴스를 만들 수 있습니다. 이를 위해서는 에이전트를 사용하여 쿼리할 BigQuery 데이터의 프로젝트 ID와 데이터 세트 ID가 필요합니다.
REST
다음 샘플은 agents.create 메서드를 사용하여 데이터 통계 에이전트 인스턴스를 만드는 방법을 보여줍니다. 이 샘플에 추가할 수 있는 고급 필드에 대해 알아보려면 에이전트의 고급 구성 추가를 참고하세요.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Goog-User-Project: PROJECT_NUMBER" \
"https://discoveryengine.googleapis.com/v1alpha/projects/PROJECT_NUMBER/locations/LOCATION/collections/default_collection/engines/APP_ID/assistants/default_assistant/agents" \
-d '{
"displayName": "AGENT_DISPLAY_NAME",
"description": "AGENT_DESCRIPTION",
"icon": {
"uri": "AGENT_ICON_URI"
},
"managed_agent_definition": {
"tool_settings": {
"tool_description": "AGENT_DESCRIPTION"
},
"data_science_agent_config": {
"bq_project_id": "BIGQUERY_PROJECT_ID",
"bq_dataset_id": "BIGQUERY_DATASET_ID"
}
},
"authorization_config": {
"tool_authorizations" : [
"AUTHORIZATION_RESOURCE_NAME"
]
}
}'
다음을 바꿉니다.
PROJECT_NUMBER: Google Cloud 프로젝트 수LOCATION: Gemini Enterprise 앱의 위치입니다.APP_ID: 앱의 ID입니다.AGENT_DISPLAY_NAME: Data Insights 에이전트 인스턴스의 이름입니다.AGENT_ICON_URI: 에이전트 아이콘의 URI를 제공하는 선택적 필드입니다.AGENT_DESCRIPTION: 데이터 통계 에이전트 인스턴스의 설명으로, 에이전트의 목적이나 BigQuery 데이터 소스 세부정보를 나타냅니다. 이 필드는 사람이 소비하기 위한 것이며 기본 에이전트에 지침을 제공하는 데 사용되지 않습니다. 에이전트에게 시스템 요청 사항을 제공하려면nlQueryConfig객체, 특히schemaDescription및nl2sqlPrompt를 사용합니다.BIGQUERY_PROJECT_ID: BigQuery 데이터 세트가 포함된Google Cloud 프로젝트의 프로젝트 ID입니다.BIGQUERY_DATASET_ID: 쿼리할 데이터가 포함된 BigQuery 데이터 세트 ID입니다.AUTHORIZATION_RESOURCE_NAME: 이전 섹션에서 획득한 승인 리소스 이름입니다.
에이전트의 고급 구성 추가
선택적으로 nlQueryConfig 필드를 정의하여 자연어에서 SQL로의 변환에 특화된 맞춤설정을 제공할 수 있습니다. 자연어 쿼리, 예상되는 SQL 출력, 예상되는 대답을 사용하여 SQL 예를 제공할 수도 있습니다. 이렇게 하면 에이전트의 출력 품질이 향상됩니다. nl2sqlExample 필드는 반복 필드이며 제공할 수 있는 예시 수에는 제한이 없습니다. 다음 코드 스니펫은 이러한 고급 필드를 구성하는 방법을 보여줍니다.
"dataScienceAgentConfig": {
"nlQueryConfig": {
"nl2sqlPrompt": "NL_TO_SQL_INSTRUCTIONS",
"nl2sqlExample": [{
"query": "EXAMPLE_NL_QUERY",
"expectedSql": "EXPECTED_SQL_QUERY",
"expectedResponse": "EXPECTED_SQL_RESPONSE"
}],
"schemaDescription": "NL_DESCRIPTION_OF_BQ_DATASET"
}
}
다음을 바꿉니다.
NL_TO_SQL_INSTRUCTIONS: 자연어로 된 쿼리가 SQL 명령어로 변환되었습니다.EXAMPLE_NL_QUERY: SQL 쿼리로 변환해야 하는 자연어 쿼리의 예입니다. 예를 들어 '캘리포니아에 거주하는 고객의 이름과 이메일 주소는 뭐야?'라고 말하면 됩니다.EXPECTED_SQL_QUERY: 자연어 질문에 해당하는 SQL 쿼리의 예를 보여주는 문자열입니다. 예를 들어customers라는 BigQuery 테이블이 있다고 가정해 보겠습니다. 그러면 예상되는 SQL 쿼리는 'SELECT customer_name, email FROM customers WHERE state = 'California''가 됩니다.EXPECTED_SQL_RESPONSE: 쿼리의 예상 답변과 예상 SQL 쿼리를 제공하는 문자열입니다. 예를 들면 다음과 같습니다.Here are the names and email addresses of your customers in California: \ * Customer name: Lara B, Email address: 222larabrown@gmail.com \ * Customer name: Alex A, Email address: baklavainthebalkans@gmail.com \ * Customer name: Bola C, Email address: cloudysanfrancisco@gmail.com \NL_DESCRIPTION_OF_BQ_DATASET: BigQuery 데이터 세트의 스키마를 설명하는 자연어 문자열입니다.
인스턴스 배포
데이터 통계 에이전트 인스턴스를 만든 후 관리자는 최종 사용자가 사용할 수 있도록 이를 배포할 수 있습니다.
REST
에이전트를 배포합니다. 다음 샘플은
agents.deploy메서드를 사용하여 생성된 에이전트를 배포하는 방법을 보여줍니다. 에이전트 배포는 장기 실행 작업 (LRO)입니다.curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -H "X-Goog-User-Project: PROJECT_NUMBER" \ "https://discoveryengine.googleapis.com/v1alpha/AGENT_RESOURCE_NAME:deploy" \ -d '{ "name":"AGENT_RESOURCE_NAME" }'다음을 바꿉니다.
PROJECT_NUMBER: Google Cloud 프로젝트 수AGENT_RESOURCE_NAME: 이전 섹션에서 에이전트를 만들 때 획득한 에이전트 리소스 이름입니다.
배포 작업의 상태를 가져옵니다. 다음 샘플은
operations.get메서드의 배포 작업 상태를 가져오는 방법을 보여줍니다.curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ "https://discoveryengine.googleapis.com/v1alpha/DEPLOY_OPERATION_NAME"
DEPLOY_OPERATION_NAME을 이전 단계에서 에이전트를 배포할 때 가져온 LRO 이름으로 바꿉니다.응답에서
done필드 값이true이면 배포가 완료된 것입니다.done필드 값이false이면 배포가 진행 중입니다.
에이전트 사양 가져오기
API를 사용하여 BigQuery 테이블 허용 목록 및 차단 목록과 같은 데이터 통계 에이전트의 구성 및 사양을 가져올 수 있습니다.
에이전트의 사양을 가져오려면 GET 요청을 전송합니다.
REST
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "X-Goog-User-Project: PROJECT_ID" \ "https://discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/LOCATION/collections/default_collection/engines/APP_ID/assistants/default_assistant/agents/AGENT_ID"
다음을 바꿉니다.
PROJECT_ID: 프로젝트의 ID입니다.APP_ID: 앱의 ID입니다.LOCATION: Gemini Enterprise 앱의 위치입니다.AGENT_ID: 에이전트의 ID입니다.
응답 예시
요청이 성공하면 다음과 비슷한 JSON 응답이 반환됩니다.
{
"name": "projects/12345/locations/global/collections/default_collection/engines/my-app/assistants/default_assistant/agents/my-agent",
"displayName": "Data Science Agent",
"description": "An agent that helps query BigQuery data.",
"managedAgentDefinition": {
"dataScienceAgentConfig": {
"bqProjectId": "my-bq-project",
"bqDatasetId": "my-bq-dataset",
"allowlistTables": [
"sales_data_2024",
"inventory_levels"
],
"blocklistTables": [
"employee_salaries",
"pii_users"
]
}
},
"authorizationConfig": {
"toolAuthorizations": [
"projects/12345/locations/global/authorizations/test-authorization"
]
},
"state": "ENABLED",
"createTime": "2024-05-20T10:00:00Z",
"updateTime": "2024-05-20T10:05:00Z"
}
사용자 및 사용자 권한 추가 또는 수정
다음 단계에 따라 데이터 통계 에이전트 인스턴스에 주 구성원을 추가하거나 수정하고 특정 Identity and Access Management (IAM) 역할을 할당합니다.
콘솔
Google Cloud 콘솔에서 Gemini Enterprise로 이동합니다.
데이터 통계 에이전트 인스턴스가 포함된 앱을 선택합니다.
메뉴에서 에이전트를 클릭합니다.
에이전트 페이지에 기존 에이전트가 표시됩니다.
사용자를 추가하거나 수정할 상담사를 클릭합니다. 예를 들어 데이터 통계 에이전트 인스턴스를 클릭합니다.
기본적으로 새로 생성된 에이전트에는 사용자가 없습니다.
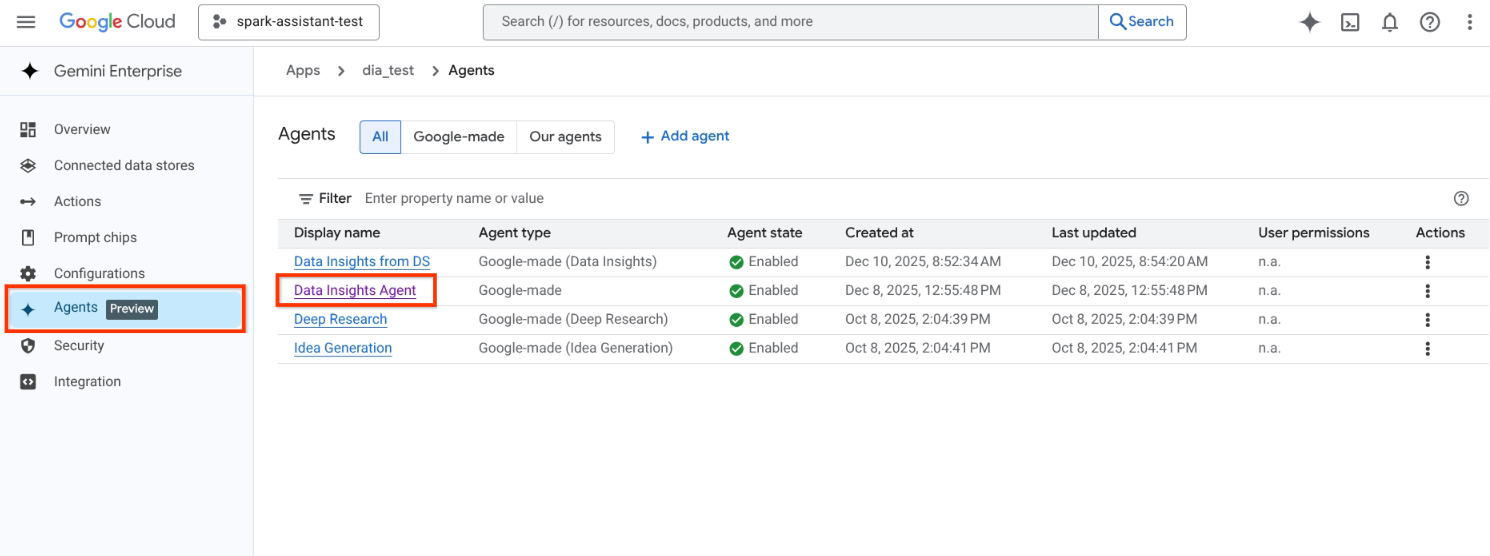
데이터 통계 에이전트 인스턴스를 클릭합니다. 사용자 권한을 클릭합니다.
권한이 있는 사용자 표에서 사용자 추가를 클릭합니다.
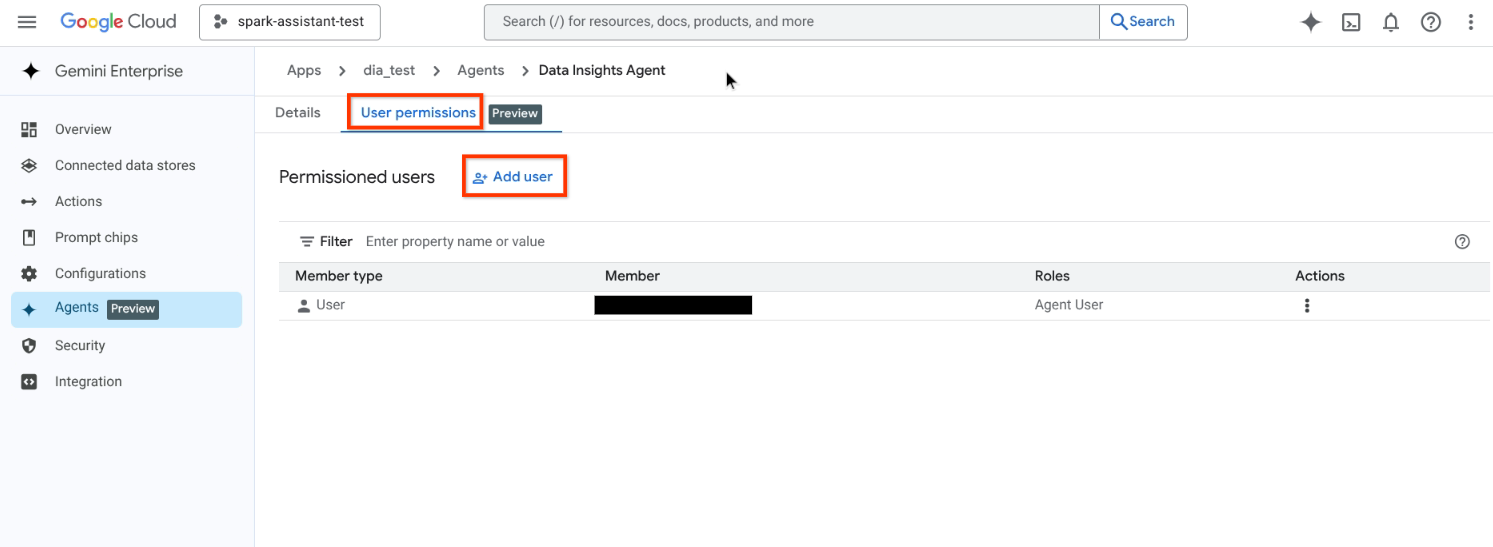
사용자 추가로 이동 사용 가능한 목록에서 회원 유형을 선택합니다.
사용자 또는 그룹의 경우 이메일 주소를 회원 문자열로 입력하고 역할을 선택합니다.
직원 ID 풀의 경우 유효한 주 구성원을 회원 문자열로 입력하고 역할을 선택합니다.
모든 사용자의 경우 역할을 선택합니다.
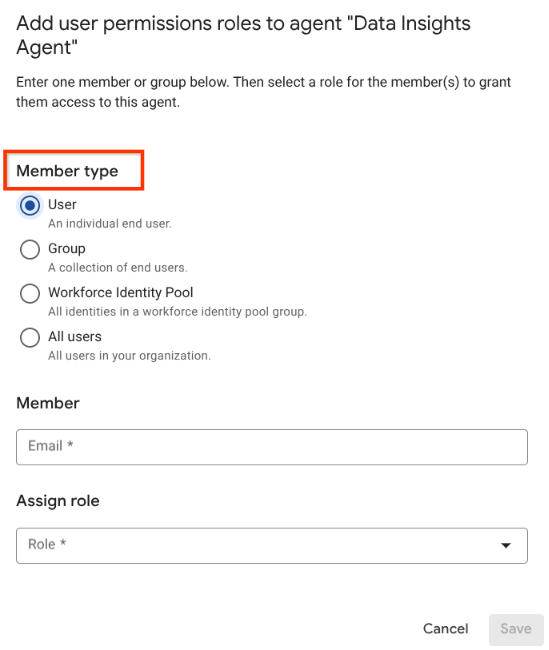
회원 유형 선택 저장을 클릭합니다.
IAM 정책이 업데이트되고 사용자가 권한이 있는 사용자 목록에 추가됩니다.
할당된 권한을 삭제하려면 작업 열에서 을 클릭한 다음 삭제를 클릭합니다.
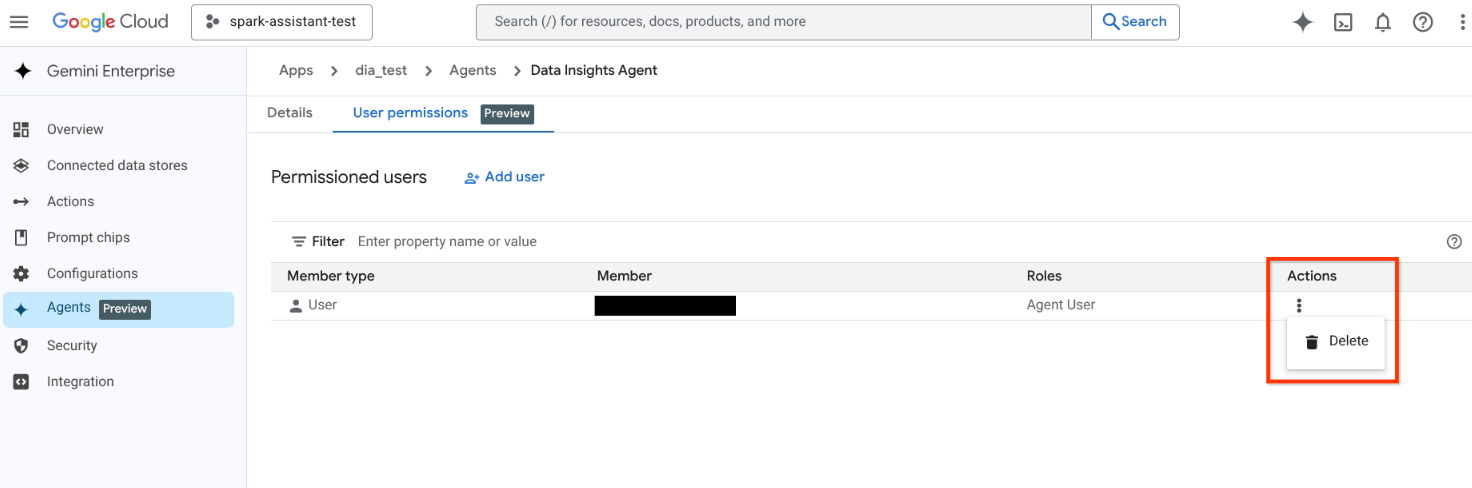
역할 삭제
인스턴스의 작동 상태 변경
데이터 통계 에이전트 인스턴스를 만들면 에이전트가 기본적으로 사용 설정됩니다. 다음 단계에 따라 작동 상태를 미리보기, 사용 중지, 일시중지 또는 삭제로 변경할 수 있습니다.
콘솔
Google Cloud 콘솔에서 Gemini Enterprise로 이동합니다.
데이터 통계 에이전트 인스턴스가 포함된 앱을 선택합니다.
메뉴에서 에이전트를 클릭합니다.
에이전트 페이지에 기존 에이전트가 표시됩니다.
사용자 추가로 이동 상담사의 작업 열에서 을 클릭하고 다음 중 하나를 선택합니다.
- 미리보기: 새 탭에서 에이전트를 엽니다.
- 사용 중지: 에이전트를 만든 사용자를 제외한 모든 사용자가 에이전트를 사용할 수 없도록 합니다.
- 정지: 에이전트를 일시적으로 사용할 수 없도록 합니다. 하지만 에이전트에 액세스할 수 있는 권한이 있는 사용자는 계속해서 에이전트를 볼 수 있습니다.
- 삭제: 에이전트 인스턴스를 삭제합니다.
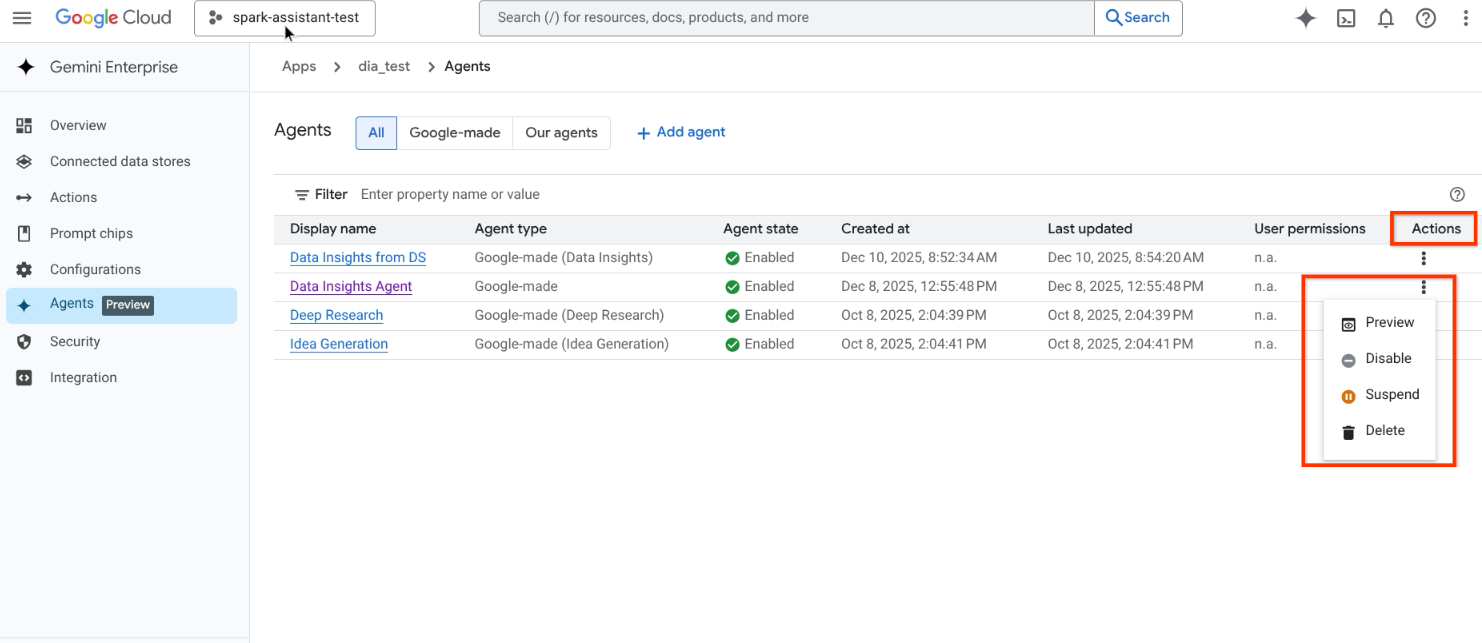
에이전트의 작업 중 하나를 선택합니다.
에이전트 사용
이 섹션에서는 최종 사용자가 데이터 통계 에이전트와 상호작용하여 BigQuery 데이터에서 통계를 얻는 방법을 설명합니다. Gemini Enterprise 앱에서 에이전트를 사용하거나 API를 사용하여 프로그래매틱 방식으로 사용할 수 있습니다.
앱에서 에이전트 사용
에이전트를 사용하여 데이터 통계를 확인하려면 다음 단계를 따르세요.
앱
앱 탐색 메뉴에서 상담사를 클릭합니다.
모든 에이전트 보기를 클릭합니다.
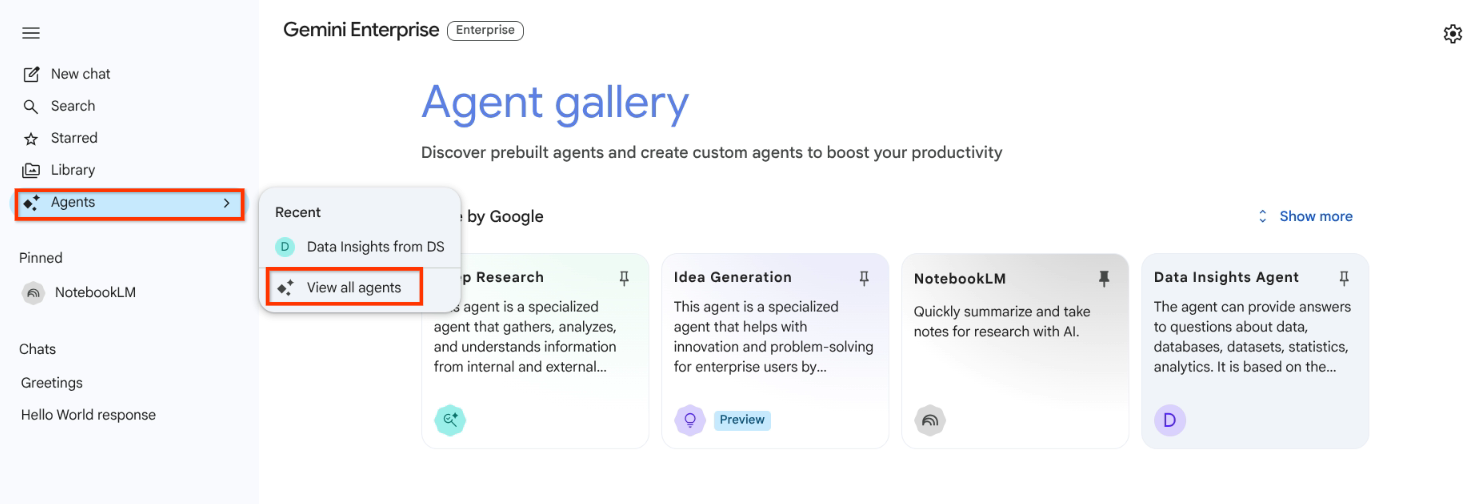
모든 상담사 보기 표시된 상담사 목록 또는 최근 목록에서 상담사를 선택합니다.
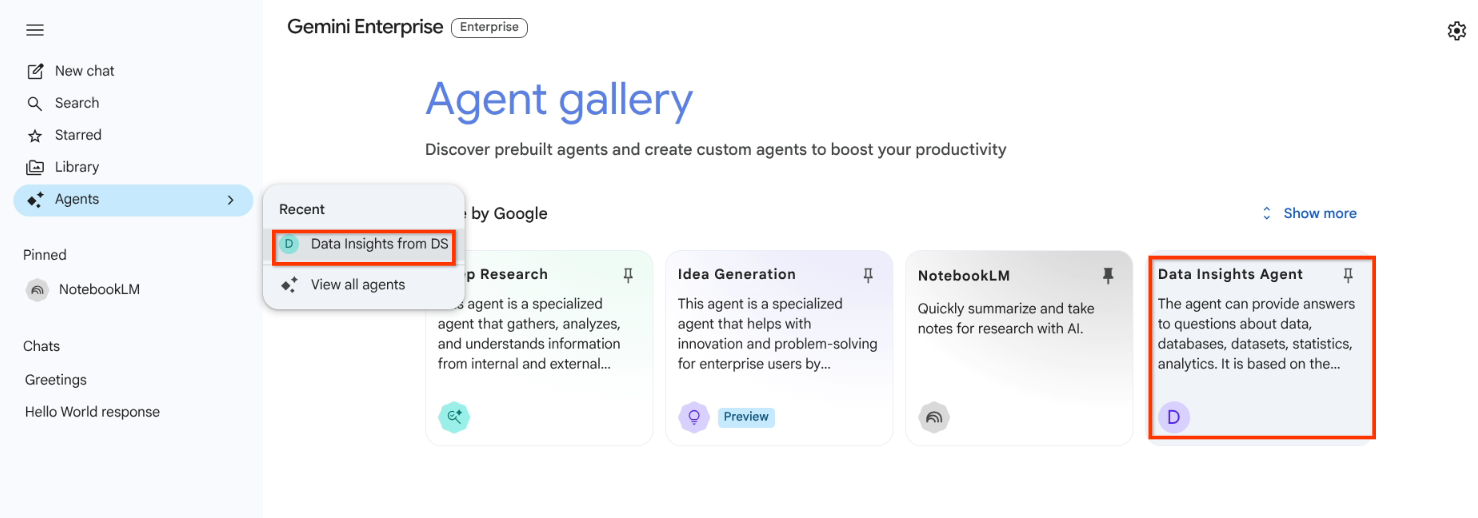
에이전트 인스턴스 선택 상담사에게 추가 승인이 필요한 경우 승인을 클릭하고 승인 세부정보를 제공합니다.
검색창에서 다음을 수행합니다.
아이콘을 클릭하여 에이전트가 사용할 파일을 추가 데이터 소스로 추가합니다.
아이콘을 클릭하여 데이터를 관리합니다.
질문이나 프롬프트를 입력하고 Enter 키를 누릅니다.
API를 사용하여 프로그래매틱 방식으로 데이터 통계 에이전트와 상호작용할 수도 있습니다.
API를 사용하여 데이터 통계 에이전트 사용
데이터 통계 에이전트는 승인된 사용자에게 API를 통해 제공됩니다. 프로그래매틱 방식으로 에이전트와 상호작용하려면 streamAssist 메서드에 POST 요청을 전송합니다.
curl
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Goog-User-Project: PROJECT_ID" \
"https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/collections/default_collection/engines/APP_ID/assistants/default_assistant:streamAssist" \
-d '{
"query": {
"text": "QUERY"
},
"agentsSpec": {
"agentSpecs": {
"agentId": "AGENT_ID"
}
}
}'
다음을 바꿉니다.
PROJECT_ID: 프로젝트의 ID입니다.LOCATION: Gemini Enterprise 앱의 위치입니다 (예:global).APP_ID: 앱의 ID입니다.QUERY: 자연어 질문입니다 (예: '지출이 가장 많은 상위 10명의 고객 목록을 생성하고 가장 많이 구매한 항목이 포함된 차트를 생성해 줘').AGENT_ID: 에이전트의 ID입니다.
응답 예시
streamAssist 메서드는 AssistAnswer 객체 목록을 반환합니다. 다음 예시는 에이전트의 내부 추론과 최종 답변이 포함된 응답 스트림을 보여줍니다. 요청이 성공하면 다음 잘린 응답과 비슷한 JSON 응답이 표시됩니다.
[
{
"answer": {
"state": "IN_PROGRESS",
"replies": [
{
"groundedContent": {
"content": {
"role": "model",
"text": "",
"thought": true
}
}
}
]
},
"assistToken": "M8gKCwiBkYrMBhDUqLFcEiQ2OTgyNWVlMS0wMDAwLTJjMzUtYjVmOS1mNDAzMDQzYmFjNmM"
},
{
"answer": {
"state": "IN_PROGRESS",
"replies": [
{
"groundedContent": {
"content": {
"role": "model",
"text": "I am an expert data analyst with access to the `spark-assistant-test.bikestores` dataset...",
"thought": true
}
}
}
]
},
"assistToken": "M8gKCwiBkYrMBhDUqLFcEiQ2OTgyNWVlMS0wMDAwLTJjMzUtYjVmOS1mNDAzMDQzYmFjNmM"
},
{
"answer": {
"name": "projects/12345/locations/global/collections/default_collection/engines/APP_ID/sessions/SESSION_ID/assistAnswers/ANSWER_ID",
"state": "SUCCEEDED",
"groundedContent": {
"content": {
"role": "model",
"text": "I am an expert data analyst with access to the `spark-assistant-test.bikestores` dataset..."
}
}
}
]
},
"sessionInfo": {
"session": "projects/PROJECT_ID/locations/LOCATION/collections/default_collection/engines/APP_ID/sessions/SESSION_ID"
}
}
]
응답 필드 정의
| 필드 | 설명 |
|---|---|
answer.state |
대답 생성 상태입니다. 에이전트가 생성 중일 때는 IN_PROGRESS를 반환하고 완료되면 SUCCEEDED를 반환합니다.
|
answer.replies |
생성된 콘텐츠 요소를 포함하는 목록입니다. |
replies.groundedContent.content.text |
에이전트가 생성한 텍스트 콘텐츠입니다. |
replies.groundedContent.content.thought |
true인 경우 텍스트가 최종 응답이 아닌 에이전트의 내부 추론 프로세스(예: SQL 공식화)임을 나타냅니다.
|
sessionInfo.session |
세션의 고유 식별자입니다. 이 리소스 이름은 후속 API 호출에서 대화 기록을 유지하는 데 사용할 수 있습니다. |