
Creare un lakehouse con Spark e il catalogo runtime Lakehouse
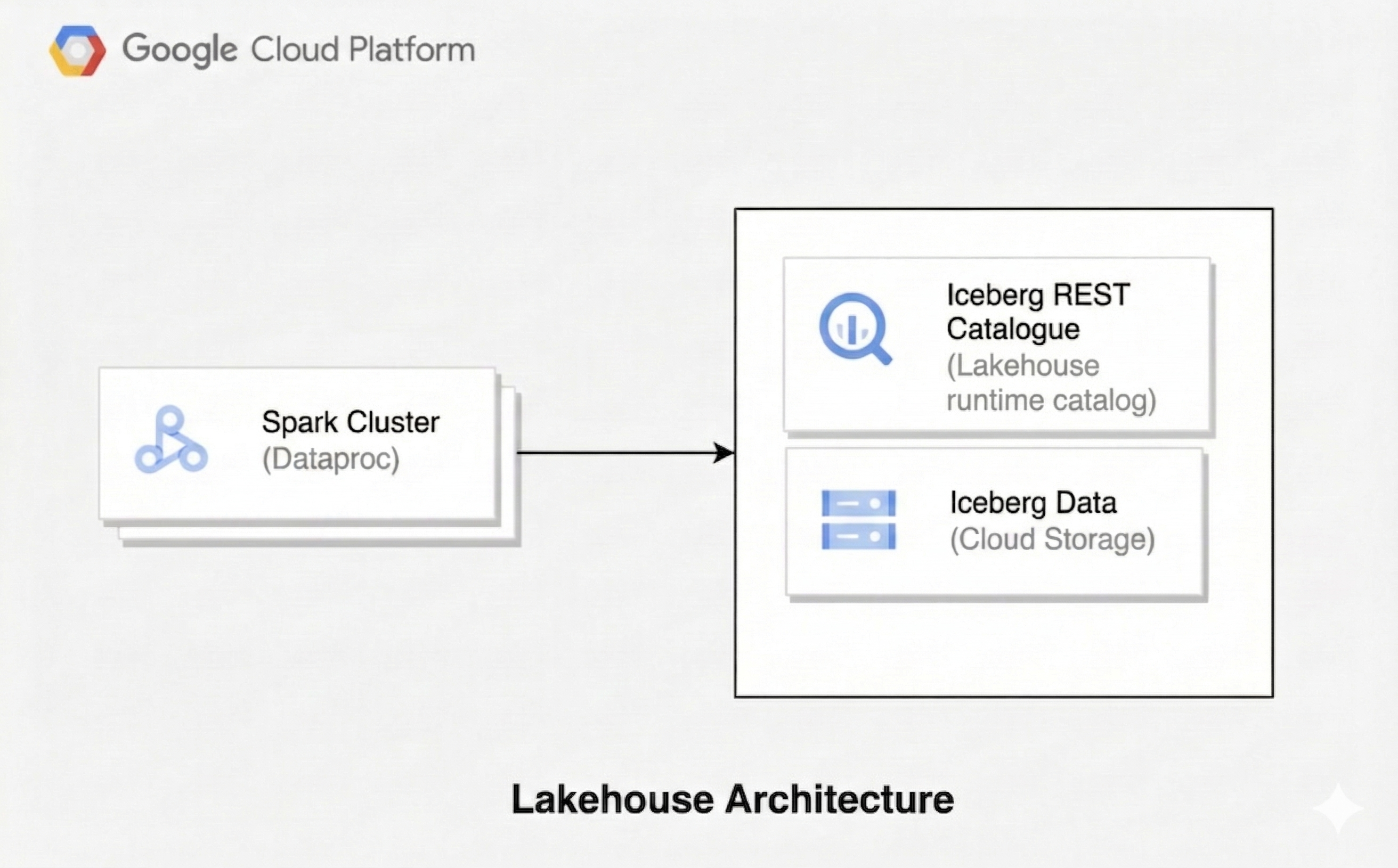
Un'architettura lakehouse combina la flessibilità di un data lake con le funzionalità di gestione dei dati di un data warehouse. Questo documento mostra come configurare un lakehouse su Google Cloud. Utilizzerai Apache Iceberg come formato della tabella, Managed Service for Apache Spark per l'elaborazione e il catalogo REST Iceberg del catalogo runtime Lakehouse per la gestione unificata dei metadati.
Questa architettura utilizza formati di tabella aperti come Iceberg per aggiungere funzionalità di data warehousing, come transazioni ed evoluzione dello schema, ai dati in Cloud Storage. Questo approccio crea un'unica fonte di verità per i tuoi dati, accessibile da vari motori.
Prima di iniziare
- Accedi al tuo Google Cloud account. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Crea un bucket Cloud Storage per archiviare i dati Iceberg.
Ruoli obbligatori
Per eseguire gli esempi in questa pagina sono necessari alcuni ruoli Identity and Access Management (IAM). A seconda delle policy dell'organizzazione, questi ruoli potrebbero essere già stati concessi. Per verificare le concessioni dei ruoli, consulta Hai bisogno di concedere ruoli?.
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Ruoli utente
Per ottenere le autorizzazioni necessarie per creare un cluster Managed Service for Apache Spark, chiedi all'amministratore di concederti i seguenti ruoli IAM:
- Dataproc Editor (
roles/dataproc.editor) sul progetto - Utente account di servizio (
roles/iam.serviceAccountUser) sul service account predefinito di Compute Engine
Ruolo service account
Per assicurarti che il account di servizio predefinito di Compute Engine disponga delle autorizzazioni necessarie
per creare un cluster Managed Service for Apache Spark,
chiedi all'amministratore di concedere il
ruolo IAM Dataproc Worker (roles/dataproc.worker) al account di servizio predefinito di Compute Engine sul progetto.
Crea un cluster Managed Service for Apache Spark
Crea un cluster Managed Service for Apache Spark con i componenti facoltativi Iceberg e Jupyter.
Per creare il cluster, esegui il seguente comando
gcloud:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Sostituisci quanto segue:
CLUSTER_NAME: un nome per il cluster.PROJECT_ID: l' Google Cloud ID progetto.REGION: la Google Cloud regione del cluster, ad esempious-central1.
Tieni presente che l'impostazione di
dataproc:dataproc.lineage.enabled=truenon è necessaria per il corretto funzionamento del catalogo REST Iceberg del catalogo runtime Lakehouse. Viene aggiunto per il monitoraggio della derivazione nell'esempio di derivazione dei dati riportato di seguito.Connettiti al cluster utilizzando un notebook Jupyter. Puoi utilizzare un notebook Vertex AI Workbench o avviare un notebook direttamente sul cluster.
Configura una sessione Spark
Nel notebook Jupyter, crea una sessione Spark configurata per utilizzare il catalogo REST Iceberg del catalogo runtime Lakehouse.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Sostituisci quanto segue:
CATALOG_NAME: un nome per il catalogo Iceberg, ad esempioiceberg_catalog.APP_NAME: il nome dell'applicazione Spark.GCS_BUCKET: il bucket Cloud Storage in cui archiviare i dati della tabella Iceberg.PROJECT_ID: l' Google Cloud ID progetto.
Gestisci i dati con Spark SQL
Dopo aver configurato la sessione Spark, utilizza Spark SQL per eseguire operazioni di gestione dei dati.
Crea uno spazio dei nomi. Nel catalogo REST Iceberg del catalogo runtime Lakehouse, uno spazio dei nomi corrisponde a un set di dati BigQuery.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Sostituisci
NAMESPACE_NAMEcon il nome dello spazio dei nomi, ad esempiospark_lakehouse.Crea una tabella di base in formato Iceberg e inserisci i dati.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()L'output è simile al seguente:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Crea una seconda tabella per i nuovi dati.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()L'output è simile al seguente:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Unisci i nuovi dati nella tabella di base.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()L'output è simile al seguente:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Aggiorna i record nella tabella di base.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()L'output è simile al seguente:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Elimina i record dalla tabella di base.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()L'output è simile al seguente:
+---+ | id| +---+ | 3| | 5| | 1| +---+
Esegui query su uno snapshot storico
Recupera una versione precedente di una tabella eseguendo query su un ID snapshot specifico. Questa operazione è nota anche come spostamento cronologico.
Recupera l'ID snapshot della versione della tabella prima delle operazioni
MERGE,UPDATEeDELETE.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Sostituisci
NAMESPACE_NAMEcon lo spazio dei nomi che hai creato.Esegui query sulla tabella utilizzando l'ID snapshot recuperato.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()L'output mostra lo stato della tabella dopo l'operazione
MERGE, ma prima di qualsiasi operazioneUPDATEoDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Scopri la derivazione dei dati
Puoi monitorare lo spostamento dei dati tra le tabelle del catalogo REST Iceberg del catalogo runtime Lakehouse
con la derivazione dei dati, che
è disponibile nelle versioni dell'immagine Managed Service for Apache Spark 2.2 e successive.
Esempio di derivazione dei dati
Crea le tabelle Iceberg di origine e di destinazione, quindi copia i dati.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)Nella Google Cloud console, vai alla pagina Cerca di Knowledge Catalog.
Cerca una delle tabelle, quindi fai clic sulla scheda
Lineage: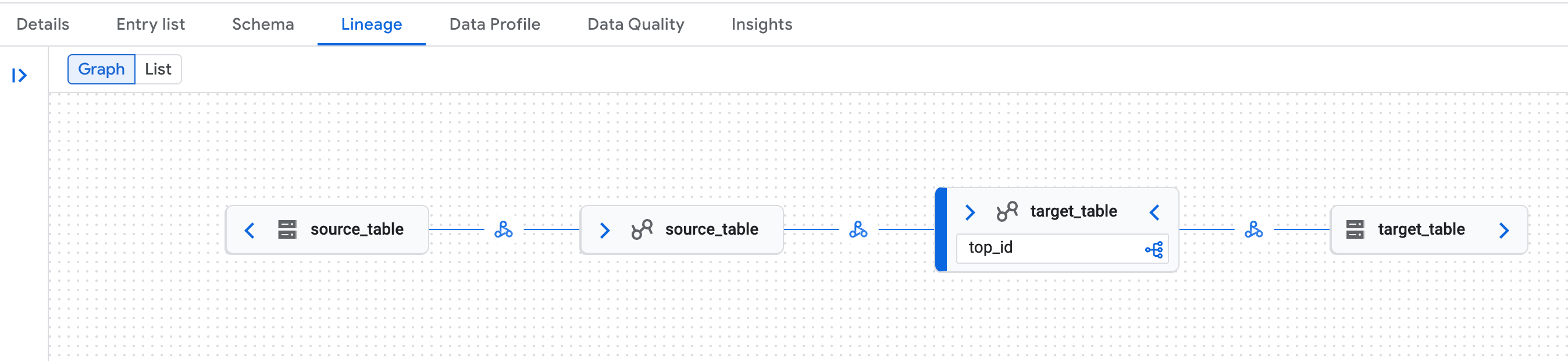
Esempio di grafico di derivazione dei dati nella pagina Knowledge Catalog della Google Cloud console. La derivazione dei dati riconosce sia le rappresentazioni logiche (tabella del catalogo runtime Lakehouse) sia quelle fisiche (Cloud Storage) delle tabelle del catalogo REST Iceberg del catalogo runtime Lakehouse.
Problema noto relativo alla derivazione dei dati
In alcuni cluster Managed Service for Apache Spark, la derivazione completa dei dati potrebbe non essere
generata a causa di un OpenLineage.
Soluzione alternativa: nella configurazione della sessione Spark, imposta la proprietà spark.sql.catalog.{catalog_name}.uri su https://biglake.googleapis.com/iceberg/v1beta/restcatalog.
Passaggi successivi
- Scopri di più sul catalogo REST Iceberg del catalogo runtime Lakehouse.
- Esplora le funzionalità di Apache Iceberg.
- Scopri come eseguire query sui dati Iceberg dal catalogo runtime Lakehouse.
- Scopri di più su derivazione dei dati e Managed Service for Apache Spark.