
Membuat lakehouse dengan Spark dan katalog runtime Lakehouse
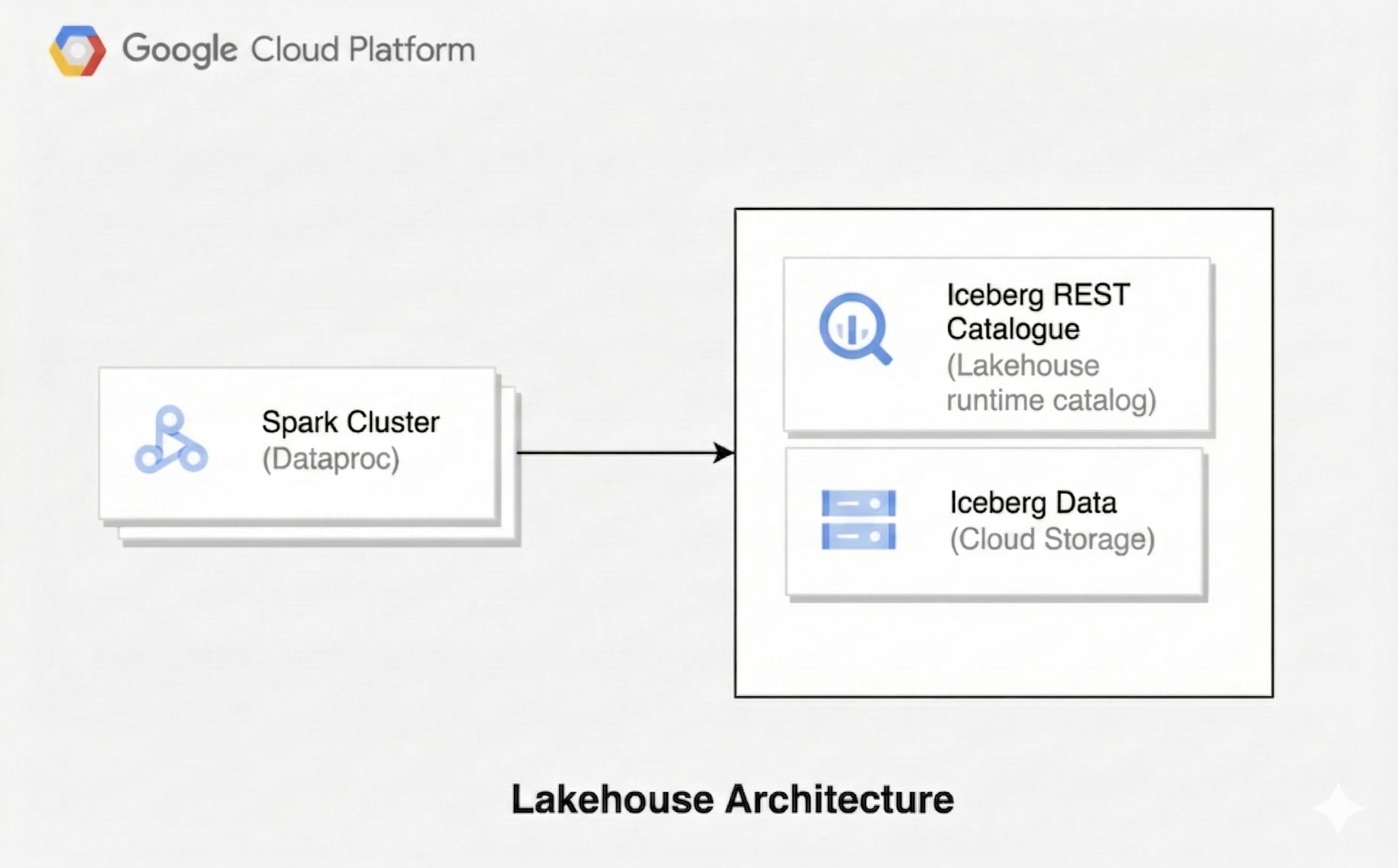
Arsitektur lakehouse menggabungkan fleksibilitas data lake dengan fitur pengelolaan data data warehouse. Dokumen ini menunjukkan cara menyiapkan lakehouse di Google Cloud. Anda menggunakan Apache Iceberg sebagai format tabel, Managed Service untuk Apache Spark untuk pemrosesan, dan Katalog REST Iceberg katalog runtime Lakehouse untuk pengelolaan metadata terpadu.
Arsitektur ini menggunakan format tabel terbuka seperti Iceberg untuk menambahkan kemampuan data warehousing, seperti transaksi dan evolusi skema, ke data di Cloud Storage. Pendekatan ini membuat satu sumber tepercaya untuk data Anda yang dapat diakses oleh berbagai mesin.
Sebelum memulai
- Login keakun Anda. Google Cloud Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Buat bucket Cloud Storage untuk menyimpan data Iceberg.
Peran yang diperlukan
Peran Identity and Access Management (IAM) tertentu diperlukan untuk menjalankan contoh di halaman ini. Bergantung pada kebijakan organisasi, peran ini mungkin sudah diberikan. Untuk memeriksa pemberian peran, lihat Apakah Anda perlu memberikan peran?.
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project,folder, dan organisasi.
Peran pengguna
Untuk mendapatkan izin yang Anda perlukan untuk membuat cluster Managed Service untuk Apache Spark, minta administrator Anda untuk memberikan peran IAM berikut:
- Editor Dataproc (
roles/dataproc.editor) di project - Pengguna Akun Layanan (
roles/iam.serviceAccountUser) di akun layanan default Compute Engine
Peran akun layanan
Untuk memastikan bahwa akun layanan default Compute Engine memiliki izin yang diperlukan untuk membuat cluster Managed Service untuk Apache Spark, minta administrator Anda untuk memberikan peran IAM Dataproc Worker (roles/dataproc.worker) ke akun layanan default Compute Engine di project.
Membuat cluster Managed Service untuk Apache Spark
Buat cluster Managed Service untuk Apache Spark dengan komponen opsional Iceberg dan Jupyter.
Untuk membuat cluster, jalankan perintah
gcloudberikut:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Ganti kode berikut:
CLUSTER_NAME: nama untuk cluster Anda.PROJECT_ID: ID Google Cloud project Anda.REGION: region untuk cluster, misalnya,us-central1. Google Cloud
Perhatikan bahwa menetapkan
dataproc:dataproc.lineage.enabled=truetidak diperlukan agar Katalog REST Iceberg katalog runtime Lakehouse berfungsi dengan benar. Kode ini ditambahkan untuk pelacakan silsilah dalam contoh silsilah data di bawah.Hubungkan ke cluster menggunakan Notebook Jupyter. Anda dapat menggunakan notebook Vertex AI Workbench atau meluncurkan notebook langsung di cluster.
Mengonfigurasi sesi Spark
Di Notebook Jupyter, buat sesi Spark yang dikonfigurasi untuk menggunakan Katalog REST Iceberg katalog runtime Lakehouse.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Ganti kode berikut:
CATALOG_NAME: nama untuk katalog Iceberg Anda, misalnya,iceberg_catalog.APP_NAME: nama aplikasi Spark Anda.GCS_BUCKET: bucket Cloud Storage untuk menyimpan data tabel Iceberg Anda.PROJECT_ID: ID Google Cloud project Anda.
Mengelola data dengan Spark SQL
Setelah mengonfigurasi sesi Spark, gunakan Spark SQL untuk melakukan operasi pengelolaan data.
Membuat namespace. Di Katalog REST Iceberg katalog runtime Lakehouse, namespace sesuai dengan set data BigQuery.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Ganti
NAMESPACE_NAMEdengan nama untuk namespace Anda, misalnya,spark_lakehouse.Buat tabel dasar dalam format Iceberg dan masukkan data.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()Outputnya mirip dengan hal berikut ini:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Buat tabel kedua untuk data baru.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()Outputnya mirip dengan hal berikut ini:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Gabungkan data baru ke dalam tabel dasar.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()Outputnya mirip dengan hal berikut ini:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Perbarui data dalam tabel dasar.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()Outputnya mirip dengan hal berikut ini:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Hapus data dari tabel dasar.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()Outputnya mirip dengan hal berikut ini:
+---+ | id| +---+ | 3| | 5| | 1| +---+
Membuat kueri snapshot historis
Ambil versi tabel sebelumnya dengan membuat kueri ID snapshot tertentu. Operasi ini juga dikenal sebagai lintas waktu.
Ambil ID snapshot versi tabel sebelum operasi
MERGE,UPDATE, danDELETE.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Ganti
NAMESPACE_NAMEdengan namespace yang Anda buat.Buat kueri tabel menggunakan ID snapshot yang diambil.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()Output menunjukkan status tabel setelah operasi
MERGE, tetapi sebelum operasiUPDATEatauDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Menemukan silsilah data
Anda dapat melacak pergerakan data antara tabel Katalog REST Iceberg katalog runtime Lakehouse
dengan silsilah data, yang
tersedia di Managed Service untuk Apache Spark 2.2 dan versi image yang lebih baru.
Contoh silsilah data
Buat tabel Iceberg sumber dan target, lalu salin data.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)Di Google Cloud konsol, buka halaman Knowledge Catalog Penelusuran.
Telusuri salah satu tabel, lalu klik tab
Lineage: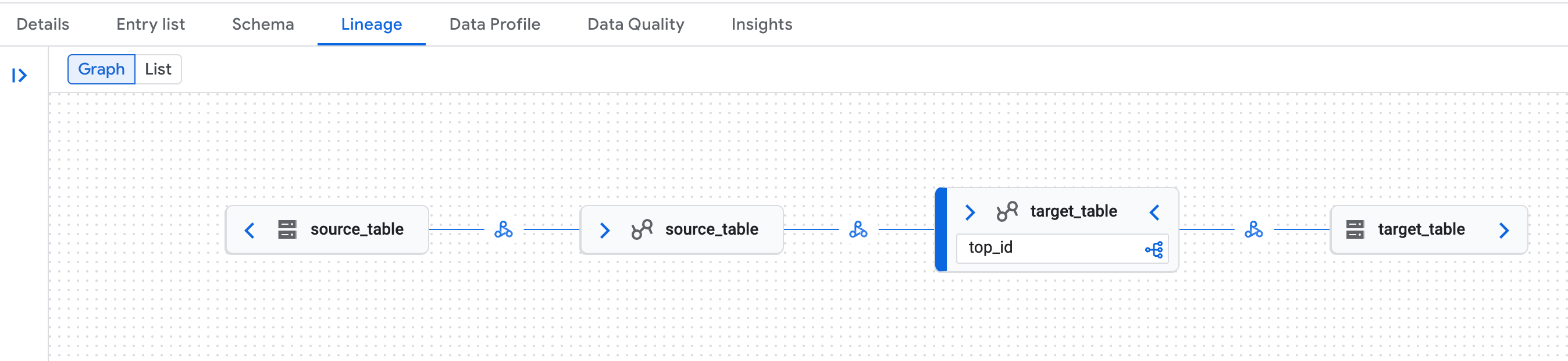
Contoh grafik silsilah data di halaman Knowledge Catalog di Google Cloud konsol. Silsilah data mengenali representasi logis (tabel katalog runtime Lakehouse) dan fisik (Cloud Storage) dari tabel Katalog REST Iceberg katalog runtime Lakehouse.
Masalah umum silsilah data
Di beberapa cluster Managed Service untuk Apache Spark, silsilah data lengkap mungkin tidak
dibuat karena masalah library OpenLineage.
Solusi: di konfigurasi sesi Spark, tetapkan properti spark.sql.catalog.{catalog_name}.uri ke https://biglake.googleapis.com/iceberg/v1beta/restcatalog.
Langkah berikutnya
- Pelajari lebih lanjut Katalog REST Iceberg katalog runtime Lakehouse.
- Pelajari fitur Apache Iceberg.
- Pelajari cara membuat kueri data Iceberg dari katalog runtime Lakehouse.
- Pelajari lebih lanjut silsilah data dan Managed Service untuk Apache Spark.