
Lakehouse mit Spark und Lakehouse-Laufzeitkatalog erstellen
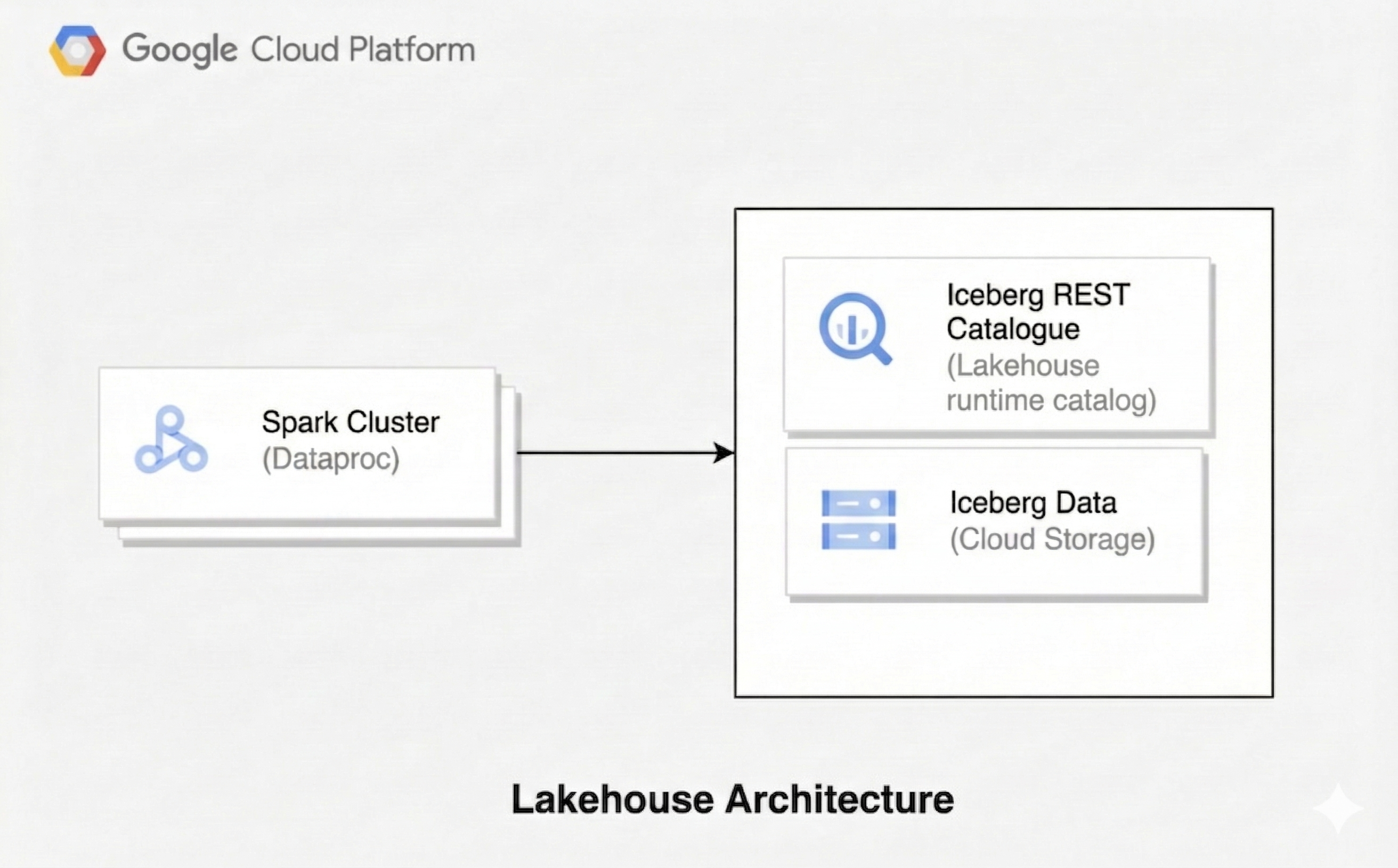
Eine Lakehouse-Architektur kombiniert die Flexibilität eines Data Lake mit den Datenverwaltungsfunktionen eines Data Warehouse. In diesem Dokument wird beschrieben, wie Sie ein Lakehouse in erstellen Google Cloud. Sie verwenden Apache Iceberg als Tabellenformat, Managed Service for Apache Spark für die Verarbeitung und den Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs für die einheitliche Metadatenverwaltung.
Diese Architektur verwendet offene Tabellenformate wie Iceberg, um Daten in Cloud Storage Data-Warehouse-Funktionen wie Transaktionen und Schema-Weiterentwicklung hinzuzufügen. Dieser Ansatz schafft eine einzige Quelle der Wahrheit für Ihre Daten, auf die verschiedene Engines zugreifen können.
Hinweis
- Melden Sie sich in Ihrem Google Cloud Konto an. Wenn Sie noch kein Konto haben Google Cloud, erstellen Sie ein Konto, um die Leistung unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Erstellen Sie einen Cloud Storage-Bucket zum Speichern von Iceberg-Daten.
Erforderliche Rollen
Bestimmte IAM-Rollen (Identity and Access Management) sind erforderlich, um die Beispiele auf dieser Seite auszuführen. Je nach Organisationsrichtlinien wurden diese Rollen möglicherweise bereits gewährt. Informationen zum Prüfen von Rollenzuweisungen finden Sie unter Müssen Sie Rollen zuweisen?.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Nutzerrollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen eines Managed Service for Apache Spark-Clusters benötigen:
- Dataproc-Bearbeiter (
roles/dataproc.editor) für das Projekt - Dienstkontonutzer (
roles/iam.serviceAccountUser) für das Compute Engine-Standarddienstkonto
Dienstkontorolle
Bitten Sie Ihren Administrator, dem Compute Engine-Standarddienstkonto die IAM-Rolle Dataproc Worker (roles/dataproc.worker) für das Projekt zuzuweisen, damit das Compute Engine-Standarddienstkonto die erforderlichen
Berechtigungen zum Erstellen eines Managed Service for Apache Spark-Clusters hat.
Managed Service for Apache Spark-Cluster erstellen
Erstellen Sie einen Managed Service for Apache Spark-Cluster mit den optionalen Komponenten Iceberg und Jupyter.
Führen Sie den folgenden
gcloud-Befehl aus, um den Cluster zu erstellen:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Ersetzen Sie Folgendes:
CLUSTER_NAME: ein Name für Ihren Cluster.PROJECT_ID: Ihre Google Cloud Projekt-ID.REGION: die Google Cloud Region für den Cluster, z. B.us-central1.
Das Festlegen von
dataproc:dataproc.lineage.enabled=trueist nicht erforderlich, damit der Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs ordnungsgemäß funktioniert. Er wird für die Lineage-Verfolgung im folgenden Beispiel für die Datenherkunft hinzugefügt.Stellen Sie über ein Jupyter-Notebook eine Verbindung zum Cluster her. Sie können ein Vertex AI Workbench-Notebook verwenden oder ein Notebook direkt im Cluster starten.
Spark-Sitzung konfigurieren
Erstellen Sie in Ihrem Jupyter-Notebook eine Spark-Sitzung, die für die Verwendung des Iceberg-REST-Katalogs des Lakehouse-Laufzeitkatalogs konfiguriert ist.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Ersetzen Sie Folgendes:
CATALOG_NAME: ein Name für Ihren Iceberg-Katalog, z. B.iceberg_catalog.APP_NAME: der Name Ihrer Spark-Anwendung.GCS_BUCKET: der Cloud Storage-Bucket zum Speichern Ihrer Iceberg-Tabellendaten.PROJECT_ID: Ihre Google Cloud Projekt-ID.
Daten mit Spark SQL verwalten
Nachdem Sie die Spark-Sitzung konfiguriert haben, können Sie mit Spark SQL Datenverwaltungsaufgaben ausführen.
Namespace erstellen Im Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs entspricht ein Namespace einem BigQuery-Dataset.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Ersetzen Sie
NAMESPACE_NAMEdurch den Namen für Ihren Namespace, z. B.spark_lakehouse.Erstellen Sie eine Basistabelle im Iceberg-Format und fügen Sie Daten ein.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()Die Ausgabe sieht etwa so aus:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Erstellen Sie eine zweite Tabelle für neue Daten.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()Die Ausgabe sieht etwa so aus:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Führen Sie die neuen Daten in die Basistabelle zusammen.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()Die Ausgabe sieht etwa so aus:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Aktualisieren Sie Datensätze in der Basistabelle.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()Die Ausgabe sieht etwa so aus:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Löschen Sie Datensätze aus der Basistabelle.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()Die Ausgabe sieht etwa so aus:
+---+ | id| +---+ | 3| | 5| | 1| +---+
Verlaufs-Snapshot abfragen
Rufen Sie eine frühere Version einer Tabelle ab, indem Sie eine bestimmte Snapshot-ID abfragen. Diese Operation wird auch als Zeitreise bezeichnet.
Rufen Sie die Snapshot-ID der Tabellenversion vor den Vorgängen
MERGE,UPDATEundDELETEab.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Ersetzen Sie
NAMESPACE_NAMEdurch den von Ihnen erstellten Namespace.Fragen Sie die Tabelle mit der abgerufenen Snapshot-ID ab.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()Die Ausgabe zeigt den Status der Tabelle nach dem Vorgang
MERGE, aber vor allen VorgängenUPDATEoderDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Datenherkunft ermitteln
Beispiel für Datenherkunft
Erstellen Sie Iceberg-Quell- und -Zieltabellen und kopieren Sie dann Daten.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)Rufen Sie in der Google Cloud Console die Seite Suchen des Knowledge Catalog auf.
Suchen Sie nach einer der Tabellen und klicken Sie dann auf den Tab
Lineage: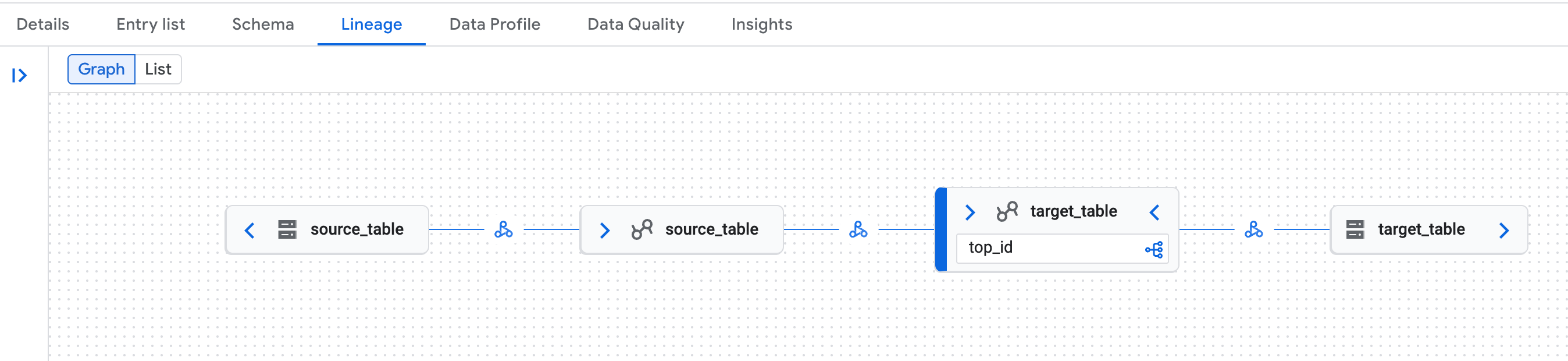
Beispiel für ein Diagramm zur Datenherkunft auf der Knowledge Catalog-Seite in der Google Cloud Console. Die Datenherkunft erkennt sowohl die logische (Tabelle des Lakehouse-Laufzeitkatalogs) als auch die physische (Cloud Storage) Darstellung von Tabellen des Iceberg-REST-Katalogs des Lakehouse-Laufzeitkatalogs.
Bekanntes Problem mit der Datenherkunft
In einigen Managed Service for Apache Spark-Clustern wird die vollständige Datenherkunft möglicherweise nicht
generiert aufgrund eines OpenLineage Bibliotheksproblems.
Problemumgehung: Legen Sie in der Spark-Sitzungskonfiguration das Attribut spark.sql.catalog.{catalog_name}.uri auf https://biglake.googleapis.com/iceberg/v1beta/restcatalog fest.
Nächste Schritte
- Weitere Informationen zum Iceberg-REST-Katalog des Lakehouse-Laufzeitkatalogs
- Funktionen von Apache Iceberg kennenlernen
- Informationen zum Abfragen von Iceberg-Daten aus dem Lakehouse-Laufzeitkatalog
- Weitere Informationen zu Datenherkunft und Managed Service for Apache Spark