
Knowledge Catalog è un catalogo di dati basato su Gemini che fornisce governance e contesto aziendale universale per l'intero patrimonio di dati. Estraendo automaticamente la semantica da dati strutturati e non strutturati, crea un grafico contestuale dinamico che basa gli agenti AI sulla verità aziendale e riduce le allucinazioni. I team di dati e gli sviluppatori di AI utilizzano Knowledge Catalog per scoprire i dati, applicare le norme e recuperare un contesto ricco sia per l'analisi che per le applicazioni autonome. Per una spiegazione dettagliata di Knowledge Catalog, guarda il video incorporato.
Dataplex Universal Catalog ora si chiama Knowledge Catalog
Per riflettere meglio la visione di unificazione della governance dei dati con le funzionalità di AI generativa, Dataplex Universal Catalog ora è Knowledge Catalog. Questa evoluzione del nome del prodotto rappresenta il passaggio da un registro di metadati convenzionale e passivo a un grafico contestuale attivo basato sull'AI.
Perché Dataplex è diventato Knowledge Catalog
Man mano che le organizzazioni accelerano l'adozione dell'AI generativa, gli agenti AI hanno bisogno di un contesto aziendale approfondito per fornire risposte accurate e basate su dati reali. Knowledge Catalog colma il divario tra la governance dei dati aziendali e i workflow degli agenti AI.
Qual è la differenza tra Dataplex e Knowledge Catalog
Gli aggiornamenti di Knowledge Catalog riflettono le nuove funzionalità basate sull'AI. A differenza dei cataloghi passivi convenzionali, Knowledge Catalog cura automaticamente i metadati, la logica di business e le relazioni tra i dati in un grafico di contesto unificato. Questo grafico fornisce la verità aziendale affidabile di cui gli agenti AI hanno bisogno per eseguire attività complesse in modo accurato. Sfrutta funzionalità come la cura automatica del contesto, query di esempio verificate e integrazioni locali e remote del Model Context Protocol (MCP).
Che cosa rimane invariato
I deployment, le API e le configurazioni Dataplex esistenti rimangono operativi. Le funzionalità principali come l'individuazione dei dati, la tracciabilità, la qualità dei dati e i glossari aziendali rimangono invariate e sono supportate. I metadati, gli aspetti e le configurazioni esistenti vengono trasferiti alla nuova esperienza Knowledge Catalog senza migrazione manuale, spostamento dei dati o tempi di inattività.
API e librerie client
Il rebranding in Knowledge Catalog non modifica
gli endpoint API, i comandi gcloud dataplex o le librerie client esistenti. Puoi continuare a utilizzare le API e le librerie client di Knowledge Catalog per interagire con Knowledge Catalog:
API REST. Consulta la documentazione dell'API REST Knowledge Catalog.
API RPC. Consulta la documentazione dell'API RPC Knowledge Catalog.
Librerie client. Inizia a utilizzare Knowledge Catalog nella lingua che preferisci utilizzando le librerie client Knowledge Catalog.
Comandi gcloud. Gestisci le risorse di Knowledge Catalog utilizzando il gruppo di comandi
gcloud dataplex. Consulta il riferimento ai comandi gcloud Dataplex.
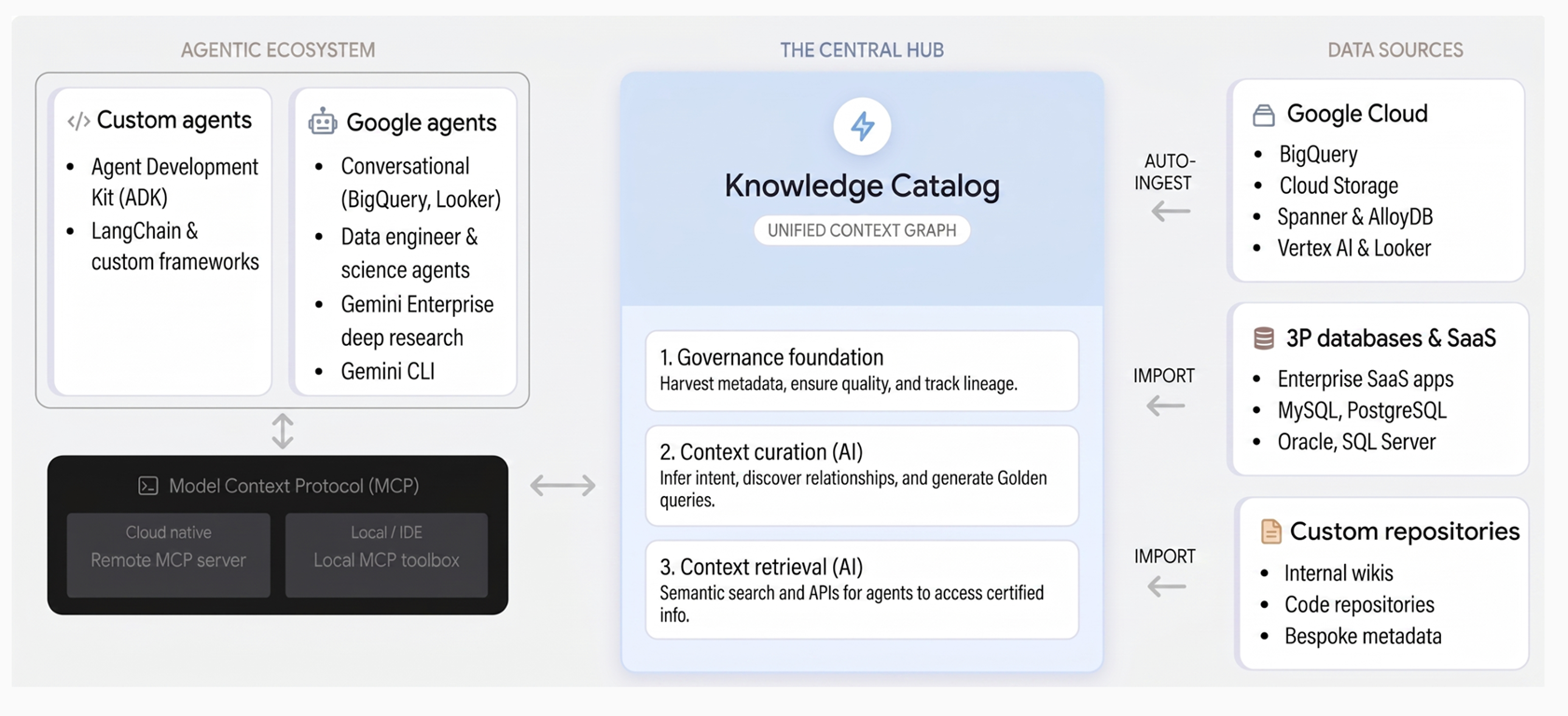
Come funziona Knowledge Catalog
Knowledge Catalog unifica la governance e il contesto attraverso tre pilastri fondamentali:
Aspetti di base della governance. Knowledge Catalog raccoglie automaticamente i metadati tecnici dai servizi Google Cloud come BigQuery, AlloyDB per PostgreSQL e Spanner, insieme a sistemi di terze parti. Stabilisce una base di dati attendibile tramite un glossario aziendale centralizzato, controlli di qualità dei dati, rilevamento di anomalie e governance basata su policy.
Selezione del contesto. Utilizzando Gemini, il servizio deduce l'intento aziendale analizzando schemi, log delle query e modelli semantici nei tuoi dati. Genera descrizioni in linguaggio naturale, scopre le relazioni e propone pattern SQL verificati sotto forma di query di esempio che acquisiscono logiche di business complesse.
Recupero del contesto. Le applicazioni e gli agenti AI possono scoprire istantaneamente gli asset e recuperare il contesto arricchito tramite la ricerca semantica e gli strumenti che supportano il Model Context Protocol (MCP). In questo modo, gli agenti possono accedere alla verità organizzativa per prendere decisioni affidabili.
Il seguente diagramma illustra l'architettura di Knowledge Catalog e come unifica la governance dei dati con i workflow di AI generativa:
Casi d'uso comuni
Knowledge Catalog aiuta data engineer, data scientist e sviluppatori di AI a risolvere le sfide relative alla gestione dei dati e allo sviluppo dell'AI:
Arricchisci i dati per l'AI. Utilizza gli approfondimenti sui dati per i dati non strutturati per estrarre automaticamente metadati ed entità da file non strutturati come i PDF in Cloud Storage. In questo modo, i dati oscuri e le conoscenze organizzative diventano accessibili ai modelli di AI.
Ridurre le allucinazioni dell'AI. Fornisci agli agenti AI query di esempio pre-verificate e guardrail semantici, consentendo loro di eseguire recuperi di dati complessi con una precisione più deterministica.
Accelerare l'individuazione dei dati. Utilizza la ricerca semantica e un grafico contestuale centralizzato per individuare asset di dati pertinenti in origini disparate per i workflow di analisi e data science.
Automatizza la creazione di prodotti di dati. Deduci le relazioni nel tuo patrimonio di dati per raggruppare gli asset in prodotti di dati autonomi con accordi sul livello del servizio (SLA) e vincoli di governance integrati.
Flussi di lavoro di esempio in Knowledge Catalog
Per scoprire come creare il tuo grafico contestuale e gestire il tuo patrimonio di dati, considera come un'azienda di vendita al dettaglio online potrebbe utilizzare le seguenti funzionalità di Knowledge Catalog:
Scopri e cataloga i dati. Il rivenditore importa automaticamente i dati delle transazioni e raccoglie i metadati da servizi come BigQuery, Pub/Sub e Cloud Storage. Google Cloud Il servizio importa anche i metadati dai database dell'inventario personalizzato per creare una visualizzazione unificata dell'intero patrimonio di dati retail. Per saperne di più, vedi Scopri i dati.
Cerca gli asset di dati. Un data scientist trova gli asset di dati dei clienti esatti di cui ha bisogno utilizzando il motore di ricerca di Knowledge Catalog con filtri sfaccettati, ricerca semantica in linguaggio naturale e operatori logici. Per maggiori informazioni, consulta Cercare asset di dati.
Arricchisci i dati con il contesto aziendale. Il team di governance dei dati definisce la terminologia retail (ad esempio "Lifetime Value" o "SKU") utilizzando glossari aziendali e utilizza approfondimenti sui dati basati sull'AI per generare automaticamente descrizioni per le nuove tabelle dei prodotti. Inoltre, applicano manualmente metadati e tag (aspetti) personalizzati strutturati in modo uniforme a tutte le loro risorse. Per saperne di più, consulta Gestire gli aspetti e arricchire i metadati e Gestire un glossario aziendale.
Comprendere le relazioni tra i dati con la tracciabilità. Il team di ingegneria monitora automaticamente la tracciabilità dei dati per vedere come i dati degli ordini vengono spostati, trasformati e utilizzati nei suoi sistemi. Utilizzano i grafici di derivazione per risolvere i problemi delle pipeline di generazione di report, eseguire l'analisi delle cause principali degli errori di pagamento e garantire la conformità. Per saperne di più, consulta la panoramica della provenienza dei dati.
Esegui la profilazione dei dati e misura la qualità. Il rivenditore utilizza la profilazione automatica dei dati per identificare pattern e anomalie nelle tabelle dei prezzi BigQuery. Definiscono ed eseguono controlli di qualità dei dati per garantire che gli indirizzi di spedizione dei clienti siano accurati, completi e affidabili per i carichi di lavoro di AI e evasione successivi. Per saperne di più, consulta Panoramica della profilazione dei dati e Panoramica della qualità dei dati automatica.
Seleziona e condividi i prodotti di dati. Il team della piattaforma dati raggruppa gli asset di vendita regionali e i relativi metadati, punteggi di qualità e tracciabilità in prodotti di dati "Customer 360" curati, che vengono scoperti e utilizzati dai team di marketing e inventario. Per ulteriori informazioni, consulta la panoramica dei prodotti di dati.
Knowledge Catalog nell'ecosistema Google Cloud
Quando crei una base di dati, è importante capire come Knowledge Catalog si integra con i servizi Google Cloud correlati:
| Servizio | Ruolo principale | Quando utilizzarlo |
|---|---|---|
| Knowledge Catalog | Contesto agentico e governance dei dati | Utilizzalo per catalogare i metadati, gestire la qualità dei dati e fornire un grounding semantico per gli agenti AI. |
| BigQuery | Data warehouse aziendale | Utilizzalo per archiviare, interrogare e analizzare set di dati di grandi dimensioni. Knowledge Catalog arricchisce i dati BigQuery con il contesto aziendale. |
| Vertex AI | Piattaforma di AI e machine learning | Utilizzalo per creare ed eseguire il deployment di modelli ML e agenti AI. Gli agenti utilizzano le API Knowledge Catalog per recuperare il contesto aziendale accurato. |
| Cloud Storage | Archiviazione dei dati non strutturati | Utilizzalo per archiviare i file non elaborati. Knowledge Catalog analizza i bucket Cloud Storage per estrarre metadati ed entità ricercabili. |
Concetti principali
Per utilizzare Knowledge Catalog in modo efficace, comprendi i seguenti concetti chiave:
Diagramma di contesto. Una mappa dinamica e unificata di come i dati si relazionano alla tua attività. Collega gli schemi tecnici alle entità aziendali e alle conoscenze non strutturate.
Query di esempio. Pattern SQL pregenerati e verificati che acquisiscono una logica di business complessa. Queste query consentono sia agli esseri umani che agli agenti AI di eseguire query sui dati in modo accurato senza reinventare unioni di tabelle complesse.
Model Context Protocol (MCP). Uno standard aperto che consente agli agenti AI di scoprire e utilizzare in modo adattivo gli strumenti disponibili. Knowledge Catalog utilizza gli strumenti MCP per fornire informazioni organizzative certificate direttamente agli agenti, offrendo server MCP sia remoti che locali per soddisfare i requisiti di accessibilità e sicurezza.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Importazioni
Knowledge Catalog acquisisce automaticamente i metadati dalle seguenti Google Cloud origini. Per alcuni servizi, come AlloyDB per PostgreSQL e Cloud SQL, devi prima attivare l'integrazione di Knowledge Catalog prima che i metadati possano essere importati:
Analytics e lakehouse
- Set di dati, tabelle, viste, modelli, routine, connessioni e set di dati collegati di BigQuery
- Scambi e schede BigQuery sharing (in precedenza Analytics Hub)
- Repository Dataform e asset di codice
- Servizi, database e tabelle Dataproc Metastore
Tabelle del catalogo REST Iceberg (incluso il catalogo runtime Lakehouse, IRC, Databricks Unity IRC, AWS Glue Data Catalog IRC e Snowflake Horizon IRC) Google Cloud
AI e machine learning
- Modelli, set di dati, gruppi di funzionalità, visualizzazioni delle funzionalità e istanze dello store online di Vertex AI
Business intelligence
- Istanze, dashboard, elementi delle dashboard, Look, progetti LookML, modelli, esplorazioni e viste di Looker (Google Cloud core) (anteprima)
Database
- Istanze, cluster e tabelle Bigtable (inclusi i dettagli delle famiglie di colonne)
- Istanze, database, tabelle e viste Spanner
Streaming e messaggistica
- Argomenti Pub/Sub
Dati non strutturati
Database operativi
- Cluster, istanze, database, schemi, tabelle e viste AlloyDB per PostgreSQL (anteprima). Knowledge Catalog recupera i metadati solo dalle istanze principali di AlloyDB per PostgreSQL e non dalle repliche di lettura. Per maggiori informazioni, consulta Gestire le risorse AlloyDB per PostgreSQL utilizzando Knowledge Catalog.
- Istanze, database, schemi, tabelle e viste Cloud SQL. Knowledge Catalog recupera i metadati solo dalle istanze Cloud SQL principali e non dalle repliche di lettura. Per saperne di più, consulta Gestire le risorse Cloud SQL utilizzando Knowledge Catalog.
Per importare metadati da un'origine di terze parti in Knowledge Catalog, puoi utilizzare i connettori Knowledge Catalog o una pipeline di connettività gestita. Per saperne di più, consulta Informazioni sui connettori di Knowledge Catalog e Panoramica della connettività gestita.
Limitazioni
Quando pianifichi l'implementazione, tieni presenti le seguenti limitazioni:
Integrazioni supportate. Sebbene Knowledge Catalog supporti i principali sistemi di terze parti, alcune estrazioni semantiche automatiche potrebbero essere limitate ai servizi Google Cloud integrati.
Limiti di quota. Le quote API standard Google Cloud si applicano alle operazioni di recupero del contesto e di estrazione dei metadati.
Passaggi successivi
Scopri di più sulla gestione dei metadati in Knowledge Catalog.
Scopri come cercare gli asset di dati.
Scopri di più sulla derivazione dei dati.
Scopri di più sulla profilazione dei dati.
Scopri di più sulla qualità dei dati automatica.