
בדף הזה מפורטות שיטות מומלצות לשימוש בפיתוח צינורות עיבוד נתונים ב-Dataflow. השימוש בשיטות המומלצות האלה מניב את היתרונות הבאים:
- שיפור הנראות והביצועים של צינורות הנתונים
- שיפור הפרודוקטיביות של המפתחים
- שיפור היכולת לבדוק את צינורות הנתונים
דוגמאות הקוד של Apache Beam שבדף הזה הן ב-Java, אבל התוכן רלוונטי ל-Apache Beam Java, Python ו-Go SDK.
שאלות שכדאי לחשוב עליהן
כשמעצבים את צינור המכירות, כדאי להתייחס לשאלות הבאות:
- איפה מאוחסנים נתוני הקלט של צינור הנתונים? כמה קבוצות של נתוני קלט יש לך?
- איך נראים הנתונים שלכם?
- מה רוצים לעשות עם הנתונים?
- לאן צריך להעביר את נתוני הפלט של צינור הנתונים?
- האם במשימת Dataflow שלך נעשה שימוש ב-Assured Workloads?
שימוש בתבניות
כדי לפתח צינור עיבוד נתונים מהר יותר, במקום לכתוב קוד Apache Beam, כדאי להשתמש בתבנית Dataflow כשזה אפשרי. היתרונות של התבניות:
- אפשר לעשות שימוש חוזר בתבניות.
- תבניות מאפשרות לכם להתאים אישית כל משימה על ידי שינוי פרמטרים ספציפיים של צינורות.
- כל מי שתעניקו לו הרשאות יוכל להשתמש בתבנית כדי לפרוס את צינור הנתונים. לדוגמה, מפתח יכול ליצור עבודה מתבנית, ומדען נתונים בארגון יכול לפרוס את התבנית הזו במועד מאוחר יותר.
אתם יכולים להשתמש בתבנית ש-Google סיפקה או ליצור תבנית משלכם. חלק מהתבניות ש-Google מספקת מאפשרות להוסיף לוגיקה בהתאמה אישית כשלב בצינור. לדוגמה, התבנית Pub/Sub to BigQuery מספקת פרמטר להפעלת פונקציה בהגדרת המשתמש (UDF) ב-JavaScript שמאוחסנת ב-Cloud Storage.
מכיוון שהתבניות ש-Google מספקת הן קוד פתוח ברישיון Apache 2.0, אתם יכולים להשתמש בהן כבסיס לצינורות חדשים. התבניות שימושיות גם כדוגמאות קוד. אפשר לראות את קוד התבנית במאגר GitHub.
Assured Workloads
השירות Assured Workloads עוזר לאכוף דרישות אבטחה ותאימות ללקוחות Google Cloud Platform. לדוגמה, אזורים באיחוד האירופי ותמיכה עם אמצעי בקרה על ריבונות עוזרים לאכוף את הדרישה למיקום נתונים ואת ההתחייבויות לריבונות הנתונים עבור לקוחות שממוקמים באיחוד האירופי. כדי לספק את התכונות האלה, חלק מהתכונות של Dataflow מוגבלות. אם אתם משתמשים ב-Assured Workloads עם Dataflow, כל המשאבים שהצינור ניגש אליהם צריכים להיות ממוקמים בפרויקט או בתיקייה של Assured Workloads בארגון שלכם. מקורות המידע האלה כוללים:
- קטגוריות של Cloud Storage
- מערכי נתונים ב-BigQuery
- נושאים ומינויים ב-Pub/Sub
- מערכי נתונים ב-Firestore
- מחברי קלט/פלט
ב-Dataflow, בכל העבודות של סטרימינג שנוצרו אחרי 7 במרץ 2024, כל נתוני המשתמשים מוצפנים באמצעות CMEK.
במשימות סטרימינג שנוצרו לפני 7 במרץ 2024, מפתחות הנתונים שמשמשים בפעולות מבוססות-מפתח, כמו חלוקה לחלונות, קיבוץ וצירוף, לא מוגנים על ידי הצפנת CMEK. כדי להפעיל את ההצפנה הזו לעבודות, צריך לנקז או לבטל את העבודה ואז להפעיל אותה מחדש. מידע נוסף זמין במאמר בנושא הצפנה של ארטיפקטים של מצב צינור הנתונים.
שיתוף נתונים בין צינורות
אין מנגנון ספציפי ל-Dataflow לתקשורת בין צינורות, לשיתוף נתונים או לעיבוד הקשר בין צינורות. אפשר להשתמש באחסון עמיד כמו Cloud Storage או במטמון בזיכרון כמו App Engine כדי לשתף נתונים בין מופעים של צינורות.
תזמון משימות
אפשר להגדיר הפעלה אוטומטית של צינורות בדרכים הבאות:
- אפשר להשתמש בצינורות עיבוד נתונים ב-Dataflow כדי ליצור לוחות זמנים חוזרים למשימות ולהבין איפה המשאבים מנוצלים במהלך ביצוע של כמה משימות.
- להשתמש ב-Cloud Scheduler.
- משתמשים ב-Dataflow Operator של Apache Airflow, אחד מתוך כמה Google Cloud Platform Operators בתהליך עבודה של Cloud Composer.
- להריץ תהליכי עבודה (cron) בהתאמה אישית ב-Compute Engine.
שיטות מומלצות לכתיבת קוד של צינורות עיבוד נתונים
בקטעים הבאים מפורטות שיטות מומלצות לשימוש כשיוצרים צינורות על ידי כתיבת קוד Apache Beam.
מבנה הקוד של Apache Beam
כדי ליצור צינורות עיבוד נתונים, נהוג להשתמש בטרנספורמציה ParDo של Apache Beam לעיבוד מקבילי.
כשמחילים ParDo טרנספורמציה, מספקים קוד בצורה של אובייקט DoFn. DoFn היא מחלקה ב-Apache Beam SDK שמגדירה פונקציית עיבוד מבוזרת.
אפשר לחשוב על קוד DoFn כעל ישויות קטנות ועצמאיות: יכול להיות שיהיו הרבה מקרים שבהם הקוד יפעל במכונות שונות, וכל אחד מהם לא ידע על האחרים. לכן, מומלץ ליצור פונקציות טהורות, שהן אידיאליות לאופי המקביל והמבוזר של רכיבי DoFn.
לפונקציות טהורות יש את המאפיינים הבאים:
- פונקציות טהורות לא תלויות במצב מוסתר או חיצוני.
- אין להם תופעות לוואי שניתן לראות.
- הם דטרמיניסטיים.
מודל הפונקציה הטהורה הוא לא נוקשה לחלוטין. אם הקוד לא תלוי בדברים שלא מובטחים על ידי שירות Dataflow, מידע על מצב או נתוני אתחול חיצוניים יכולים להיות תקפים עבור DoFn ואובייקטים אחרים של פונקציות.
כשמבנים את ParDo הטרנספורמציות ויוצרים את רכיבי DoFn, כדאי לפעול לפי ההנחיות הבאות:
- כשמשתמשים בעיבוד של כל רכיב בדיוק פעם אחת, שירות Dataflow מבטיח שכל רכיב בקלט
PCollectionיעבור עיבוד על ידי מופעDoFnבדיוק פעם אחת. - שירות Dataflow לא מבטיח כמה פעמים מופעלת
DoFn. - שירות Dataflow לא מבטיח בדיוק איך יקובצו הרכיבים המבוזרים. היא לא מבטיחה אילו רכיבים יעברו עיבוד ביחד, אם בכלל.
- שירות Dataflow לא מבטיח את המספר המדויק של מופעי
DoFnשנוצרו במהלך צינור. - שירות Dataflow עמיד בכשלים, ויכול להיות שהוא ינסה להריץ מחדש את הקוד שלכם כמה פעמים אם העובדים ייתקלו בבעיות.
- יכול להיות ששירות Dataflow ייצור עותקים לגיבוי של הקוד שלכם. יכולות להיות בעיות עם תופעות לוואי ידניות, למשל אם הקוד שלכם מסתמך על קבצים זמניים עם שמות לא ייחודיים או יוצר אותם.
- שירות Dataflow מבצע סריאליזציה של עיבוד רכיבים לכל מופע
DoFn. הקוד לא צריך להיות thread-safe, אבל כל מצב שמשותף בין כמה מופעים שלDoFnחייב להיות thread-safe.
יצירת ספריות של טרנספורמציות לשימוש חוזר
מודל התכנות של Apache Beam מאפשר לכם לעשות שימוש חוזר בטרנספורמציות. יצירת ספרייה משותפת של טרנספורמציות נפוצות יכולה לשפר את היכולת לשימוש חוזר, את יכולת הבדיקה ואת הבעלות על הקוד של צוותים שונים.
כדאי לעיין בשתי דוגמאות הקוד הבאות ב-Java, ששתיהן קוראות אירועי תשלום. בהנחה ששני צינורות העיבוד מבצעים את אותו עיבוד, הם יכולים להשתמש באותם טרנספורמציות דרך ספרייה משותפת לשלבי העיבוד שנותרו.
הדוגמה הראשונה היא ממקור Pub/Sub לא מוגבל:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
הדוגמה השנייה היא ממקור של מסד נתונים רלציוני מוגבל:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
הדרך להטמיע שיטות מומלצות לשימוש חוזר בקוד משתנה בהתאם לשפת התכנות ולכלי הבנייה. לדוגמה, אם משתמשים ב-Maven, אפשר להפריד את קוד הטרנספורמציה למודול משלו. אחר כך אפשר לכלול את המודול כמודול משנה בפרויקטים גדולים עם כמה מודולים עבור צינורות שונים, כמו בדוגמה הבאה של קוד:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
מידע נוסף זמין בדפי התיעוד הבאים של Apache Beam:
- דרישות לכתיבת קוד משתמש להמרות של Apache Beam
PTransformמדריך סגנון: מדריך סגנון לכותבים שלPTransformקולקציות חדשות לשימוש חוזר
שימוש בתורים של הודעות שלא ניתן להעביר לטיפול בשגיאות
לפעמים צינור הנתונים לא יכול לעבד רכיבים. בעיות בנתונים הן סיבה נפוצה. לדוגמה, רכיב שמכיל JSON בפורמט שגוי עלול לגרום לכשלים בניתוח.
אפשר לזהות חריגים בשיטה DoFn.ProcessElement, לרשום את השגיאה ביומן ולהסיר את הרכיב, אבל בגישה הזו הנתונים אובדים ואי אפשר לבדוק אותם מאוחר יותר כדי לטפל בהם באופן ידני או לפתור בעיות.
במקום זאת, משתמשים בתבנית שנקראת תור הודעות שלא עברו עיבוד.
מזהים חריגים בשיטה DoFn.ProcessElement ומתעדים שגיאות. במקום להשליך את הרכיב שנכשל, אפשר להשתמש בפלט מסועף כדי לכתוב את הרכיבים שנכשלו לאובייקט PCollection נפרד. הרכיבים האלה נכתבים ל-data sink לצורך בדיקה וטיפול בהמשך באמצעות טרנספורמציה נפרדת.
בדוגמה הבאה של קוד Java אפשר לראות איך מטמיעים את התבנית של תור הודעות שלא ניתן להעביר.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
אפשר להשתמש ב-Cloud Monitoring כדי להחיל מדיניות שונה של מעקב והתראות על תור ההודעות שלא ניתן להעביר (DLQ) של צינור הנתונים. לדוגמה, אפשר להציג באופן חזותי את המספר והגודל של הרכיבים שעברו עיבוד על ידי טרנספורמציית ההודעות שלא נמסרו, ולהגדיר התראות שיופעלו אם מתקיימים תנאי סף מסוימים.
טיפול במוטציות של סכימה
כדי לטפל בנתונים עם סכימות לא צפויות אבל תקינות, אפשר להשתמש בתבנית של הודעות שלא נמסרו (dead-letter), שכותבת רכיבים שנכשלו לאובייקט PCollection נפרד.
במקרים מסוימים, יכול להיות שתרצו לטפל אוטומטית באלמנטים שמשקפים סכימה שעברה מוטציה כאלמנטים תקינים. לדוגמה, אם הסכימה של רכיב משקפת מוטציה כמו הוספה של שדות חדשים, אפשר להתאים את הסכימה של data sink כדי להתאים למוטציות.
שינוי סכימה אוטומטי מתבסס על גישת הפלט של הסתעפות שמשמשת בתבנית של הודעות שלא נמסרו. עם זאת, במקרה הזה מופעלת טרנספורמציה שמשנה את סכימת היעד בכל פעם שנתקלים בסכימות מצטברות. דוגמה לגישה הזו מופיעה במאמר How to handle mutating JSON schemas in a streaming pipeline, with Square Enix בבלוג Google Cloud .
החלטה על אופן צירוף מערכי נתונים
איחוד של קבוצות נתונים הוא תרחיש נפוץ לשימוש בצינורות עיבוד נתונים. אפשר להשתמש בקלט צדדי או בטרנספורמציה CoGroupByKey כדי לבצע הצטרפות בצינור.
לכל אחת מהן יש יתרונות וחסרונות.
קלט צדדי
מספק דרך גמישה לפתרון בעיות נפוצות בעיבוד נתונים, כמו העשרת נתונים וחיפושים לפי מפתח. בניגוד לאובייקטים של PCollection, קלט צדדי ניתן לשינוי ואפשר לקבוע אותו בזמן הריצה. לדוגמה, יכול להיות שהערכים בקלט צדדי מחושבים על ידי ענף אחר בצינור או נקבעים על ידי קריאה לשירות מרוחק.
Dataflow תומך בקלט צדדי על ידי שמירת נתונים באחסון מתמיד, בדומה לדיסק משותף. ההגדרה הזו מאפשרת לכל העובדים לגשת לכל הקלט הצדדי.
עם זאת, גדלי הקלט הצדדי יכולים להיות גדולים מאוד, ויכול להיות שהם לא יתאימו לזיכרון של העובד. קריאה מנתוני קלט צדדיים גדולים עלולה לגרום לבעיות בביצועים אם העובדים צריכים לקרוא כל הזמן מאחסון מתמיד.
הטרנספורמציה CoGroupByKey היא טרנספורמציה מרכזית של Apache Beam שממזגת (משטחת) כמה אובייקטים מסוג PCollection ומקבצת רכיבים עם מפתח משותף. בניגוד לקלט צדדי, שמאפשר לכל עובד לגשת לכל נתוני הקלט הצדדי, CoGroupByKey מבצע פעולת ערבוב (קיבוץ) כדי להפיץ את הנתונים בין העובדים. CoGroupByKey לכן, הפונקציה הזו מתאימה במיוחד כשרוצים להצטרף לאובייקטים גדולים מאוד שלא נכנסים לזיכרון של העובד.PCollection
כדי להחליט אם להשתמש בקלט צדדי או ב-CoGroupByKey, כדאי לפעול לפי ההנחיות הבאות:
- משתמשים בקלט צדדי כשאחד מאובייקטי ה-
PCollectionשאתם מצטרפים אליהם קטן באופן לא פרופורציונלי ביחס לאחרים, ואובייקט ה-PCollectionהקטן יותר נכנס לזיכרון של העובד. שמירת כל הקלט הצדדי במטמון בזיכרון מאפשרת שליפה מהירה ויעילה של רכיבים. - משתמשים בקלט צדדי אם יש אובייקט
PCollectionשצריך לבצע בו הצטרפות כמה פעמים בצינור. במקום להשתמש בכמה טרנספורמציותCoGroupByKey, כדאי ליצור קלט צדדי יחיד שאפשר להשתמש בו מחדש בכמה טרנספורמציותParDo. - משתמשים ב-
CoGroupByKeyאם צריך לאחזר חלק גדול מאובייקטPCollectionשגדול משמעותית מזיכרון העובד.
מידע נוסף זמין במאמר פתרון בעיות של שגיאות חוסר זיכרון ב-Dataflow.
צמצום פעולות יקרות לכל רכיב
מופע של DoFn מעבד קבוצות של רכיבים שנקראות bundles. אלה יחידות עבודה אטומיות שמורכבות מאפס רכיבים או יותר. לאחר מכן, כל אחד מהרכיבים עובר עיבוד באמצעות השיטה
DoFn.ProcessElement, שמופעלת עבור כל רכיב. השיטה DoFn.ProcessElement
מופעלת עבור כל רכיב, ולכן כל פעולה שגוזלת זמן או משאבי מחשוב שמופעלת על ידי השיטה הזו מופעלת עבור כל רכיב שעובר עיבוד על ידי השיטה.
אם צריך לבצע פעולות יקרות רק פעם אחת עבור קבוצה של רכיבים, כדאי לכלול את הפעולות האלה בשיטה DoFn.Setup או בשיטה DoFn.StartBundle במקום ברכיב DoFn.ProcessElement. לדוגמה, הפעולות הבאות:
ניתוח קובץ תצורה ששולט בהיבט מסוים של התנהגות המופע.
DoFnצריך להפעיל את הפעולה הזו רק פעם אחת, כשמאתחלים את מופעDoFn, באמצעות השיטהDoFn.Setup.יצירת מופע של לקוח לזמן קצר שנעשה בו שימוש חוזר בכל הרכיבים בחבילה, למשל כשכל הרכיבים בחבילה נשלחים דרך חיבור רשת יחיד. מפעילים את הפעולה הזו פעם אחת לכל חבילה באמצעות השיטה
DoFn.StartBundle.
הגבלת גודל האצווה והקריאות בו-זמנית לשירותים חיצוניים
כשמתקשרים לשירותים חיצוניים, אפשר לצמצם את התקורה לכל שיחה באמצעות טרנספורמציית GroupIntoBatches. הטרנספורמציה הזו יוצרת אצוות של רכיבים בגודל שצוין.
העברת נתונים באצווה שולחת רכיבים לשירות חיצוני כמטען ייעודי (payload) אחד במקום בנפרד.
בנוסף לשימוש באפשרות 'הוספה לאצווה', כדאי להגביל את המספר המקסימלי של קריאות מקבילות (בו-זמניות) לשירות החיצוני. לשם כך, צריך לבחור מפתחות מתאימים כדי לחלק את הנתונים הנכנסים. מספר המחיצות קובע את המקסימום של ההפעלה המקבילית. לדוגמה, אם לכל רכיב מוקצה אותו מפתח, טרנספורמציה במורד הזרם לקריאה לשירות החיצוני לא מופעלת במקביל.
אפשר להשתמש באחת מהגישות הבאות כדי ליצור מפתחות לרכיבים:
- בוחרים מאפיין של מערך הנתונים לשימוש כמפתחות נתונים, כמו מזהי משתמשים.
- יוצרים מפתחות נתונים כדי לפצל רכיבים באופן אקראי על פני מספר קבוע של מחיצות, כאשר מספר ערכי המפתח האפשריים קובע את מספר המחיצות. צריך ליצור מספיק מחיצות כדי להפעיל מקביליות.
בכל מחיצה צריכים להיות מספיק אלמנטים כדי שהטרנספורמציה
GroupIntoBatchesתהיה שימושית.
בדוגמה הבאה של קוד Java אפשר לראות איך לפצל באופן אקראי רכיבים על פני עשרה מחיצות:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
זיהוי בעיות בביצועים שנגרמות משלבים מאוחדים
Dataflow יוצר גרף של שלבים שמייצג את צינור עיבוד הנתונים, על סמך ההמרות והנתונים ששימשו ליצירתו. התרשים הזה נקרא תרשים של הפעלת צינור עיבוד הנתונים.
כשפורסים את צינור הנתונים, יכול להיות ש-Dataflow ישנה את גרף הביצוע של צינור הנתונים כדי לשפר את הביצועים. לדוגמה, יכול להיות ש-Dataflow ימזג כמה פעולות יחד בתהליך שנקרא אופטימיזציה של מיזוג, כדי להימנע מההשפעה על הביצועים והעלות של כתיבת כל אובייקט PCollection ביניים בפייפליין.
במקרים מסוימים, יכול להיות ש-Dataflow יקבע בצורה שגויה את הדרך האופטימלית לאחד פעולות בצינור, מה שיגביל את היכולת של העבודה להשתמש בכל העובדים הזמינים. במקרים כאלה, אפשר למנוע את המיזוג של הפעולות.
הנה דוגמה לקוד Apache Beam. טרנספורמציה מסוג GenerateSequence יוצרת אובייקט קטן מוגבל מסוג PCollection, שעובר עיבוד נוסף על ידי שתי טרנספורמציות מסוג ParDo בהמשך השרשרת.
הטרנספורמציה Find Primes Less-than-N עלולה להיות יקרה מבחינת משאבי מחשוב, וסביר להניח שהיא תפעל לאט עבור מספרים גדולים. לעומת זאת, סביר להניח שהטרנספורמציה של Increment Number תסתיים במהירות.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
הדיאגרמה הבאה מציגה ייצוג גרפי של צינור העיבוד בממשק המעקב של Dataflow.
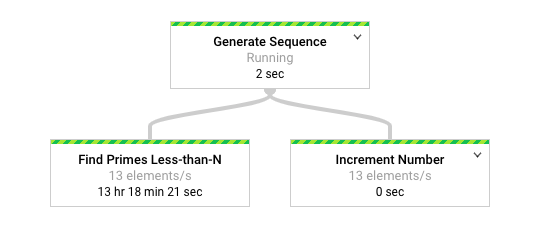
בממשק המעקב של Dataflow אפשר לראות שקצב העיבוד האיטי זהה בשני הטרנספורמציות, כלומר 13 רכיבים לשנייה. אפשר לצפות שהטרנספורמציה Increment Number תעבד את הרכיבים במהירות, אבל נראה שהיא קשורה לאותו קצב עיבוד כמו Find Primes Less-than-N.
הסיבה לכך היא ש-Dataflow מיזג את השלבים לשלב אחד, ולכן הם לא יכולים לפעול בנפרד. אפשר להשתמש בפקודה gcloud dataflow jobs describe כדי למצוא מידע נוסף:
gcloud dataflow jobs describe --full job-id --format json
בפלט שמתקבל, השלבים הממוזגים מתוארים באובייקט ExecutionStageSummary במערך ComponentTransform:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
בתרחיש הזה, מכיוון שהטרנספורמציה Find Primes Less-than-N היא השלב האיטי, אסטרטגיה מתאימה היא להפסיק את המיזוג לפני השלב הזה. שיטה אחת להפרדת השלבים היא להוסיף טרנספורמציה GroupByKey ולבטל את הקיבוץ לפני השלב, כמו שמוצג בדוגמה הבאה של קוד Java.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
אפשר גם לשלב את השלבים האלה של ביטול המיזוג להמרה מורכבת לשימוש חוזר.
אחרי שמבטלים את המיזוג של השלבים, כשמריצים את צינור הנתונים, שלב Increment Number מסתיים תוך שניות, והטרנספורמציה Find Primes Less-than-N שפועלת הרבה יותר זמן מורצת בשלב נפרד.
בדוגמה הזו מבוצעת פעולת קיבוץ וביטול קיבוץ על שלבים לא מאוחדים.
אפשר להשתמש בגישות אחרות במקרים אחרים. במקרה כזה, הטיפול בפלט כפול לא מהווה בעיה, בהתחשב בפלט הרציף של טרנספורמציית GenerateSequence.
KV
אובייקטים עם מפתחות כפולים עוברים ביטול כפילויות למפתח יחיד בקבוצה (GroupByKey) טרנספורמציה
ובטרנספורמציה של ביטול הקיבוץ
(Keys). כדי לשמור את הכפילויות אחרי פעולות של קיבוץ וביטול קיבוץ, צריך ליצור צמדי מפתח/ערך באמצעות השלבים הבאים:
- שימוש במפתח אקראי ובקלט המקורי כערך.
- קיבוץ באמצעות מפתח אקראי.
- הפלט הוא הערכים של כל מפתח.
אפשר גם להשתמש בטרנספורמציה Reshuffle כדי למנוע מיזוג של טרנספורמציות סמוכות. עם זאת, תופעות הלוואי של טרנספורמציית Reshuffle לא ניתנות להעברה בין מפעילים שונים של Apache Beam.
מידע נוסף על אופטימיזציה של מקביליות ומיזוג זמין במאמר בנושא מחזור החיים של צינורות.
שימוש במדדים של Apache Beam כדי לאסוף תובנות לגבי צינור עיבוד הנתונים
מדדים של Apache Beam הם מחלקה של כלי עזר שמפיקה מדדים לדיווח על המאפיינים של צינור עיבוד נתונים שפועל. כשמשתמשים ב-Cloud Monitoring, מדדי Apache Beam זמינים כמדדים מותאמים אישית של Cloud Monitoring.
בדוגמה הבאה מוצגים מדדים של Apache Beam Counterשמשמשים במחלקת משנה DoFn.
בדוגמת הקוד נעשה שימוש בשני מוניטורים. מונה אחד עוקב אחרי כשלים בניתוח JSON (malformedCounter), והמונה השני עוקב אחרי הודעות JSON שתקפות אבל מכילות מטען ייעודי ריק (emptyCounter). ב-Cloud Monitoring, השמות של המדדים המותאמים אישית הם custom.googleapis.com/dataflow/malformedJson ו-custom.googleapis.com/dataflow/emptyPayload. אתם יכולים להשתמש במדדים המותאמים אישית כדי ליצור ויזואליזציות ומדיניות התראות ב-Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
העברת צינור עיבוד נתונים בין פרויקטים של Google Cloud
משימות Dataflow קשורות לפרויקט ב- Google Cloud שבו הן נוצרו. אי אפשר להעביר משימה ישירות לפרויקט אחר. כדי להעביר צינור לעיבוד נתונים לפרויקט אחר, צריך לעצור את העבודה הקיימת וליצור אותה מחדש בפרויקט החדש. מדריך מפורט לתהליך הזה זמין במאמר העברת משימות של צינורות נתונים לפרויקט אחר ב-Google Cloud Platform.
מידע נוסף
בדפים הבאים מוסבר איך לבנות את צינור הנתונים, איך לבחור אילו טרנספורמציות להחיל על הנתונים ומה צריך לקחת בחשבון כשבוחרים את שיטות הקלט והפלט של צינור הנתונים.
מידע נוסף על פיתוח קוד משתמש זמין במאמר בנושא דרישות לפונקציות שהמשתמשים סיפקו.