
בדף הזה מוסבר איך למצוא ולפתור שגיאות של חוסר זיכרון (OOM) ב-Dataflow.
איך מאתרים שגיאות של חוסר בזיכרון
כדי לבדוק אם הצינור שלכם חורג ממגבלת הזיכרון, אפשר להשתמש באחת מהשיטות הבאות.
- בדף פרטי המשימות, בחלונית יומנים, מעיינים בכרטיסייה אבחון. בכרטיסייה הזו מוצגות שגיאות שקשורות לבעיות בזיכרון, ותדירות ההתרחשות של השגיאות.
- בממשק המעקב של Dataflow, משתמשים בתרשים Memory utilization כדי לעקוב אחרי קיבולת הזיכרון של העובדים והשימוש בו.
- בדף Jobs details, בחלונית Logs, בוחרים באפשרות Worker logs כדי למצוא שגיאות של חוסר זיכרון ביומני העובדים.
יכול להיות ששגיאות שקשורות לזיכרון יופיעו גם ביומני המערכת. כדי לראות את היומנים האלה, עוברים אל Logs Explorer ומשתמשים בשאילתה הבאה:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"מחליפים את JOB_ID במזהה המשימה.
במשימות Java, הכלי Java Memory Monitor מדווח מעת לעת על מדדים של איסוף אשפה (garbage collection). אם חלק מזמן המעבד שמשמש לאיסוף אשפה חורג מסף של 50% למשך תקופה ממושכת, ה-SDK harness נכשל. יכול להיות שתופיע שגיאה שדומה לדוגמה הבאה:
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...השגיאה הזו יכולה להתרחש גם אם עדיין יש זיכרון פיזי זמין, ובדרך כלל היא מצביעה על כך שהשימוש בזיכרון של צינור הנתונים לא יעיל. כדי לפתור את הבעיה, צריך לבצע אופטימיזציה של צינור המכירות.
הגדרת Java Memory Monitor מתבצעת דרך הממשק
MemoryMonitorOptions.
אם העבודה שלכם משתמשת בזיכרון רב או אם אתם מקבלים שגיאות שקשורות לזיכרון, כדאי לפעול לפי ההמלצות בדף הזה כדי לבצע אופטימיזציה של השימוש בזיכרון או כדי להגדיל את כמות הזיכרון שזמינה.
פתרון שגיאות שקשורות לחוסר בזיכרון
שינויים בצינור Dataflow עשויים לפתור שגיאות של חוסר זיכרון או לצמצם את השימוש בזיכרון. השינויים האפשריים כוללים את הפעולות הבאות:
בתרשים הבא מוצג תהליך העבודה לפתרון בעיות ב-Dataflow שמתואר בדף הזה.
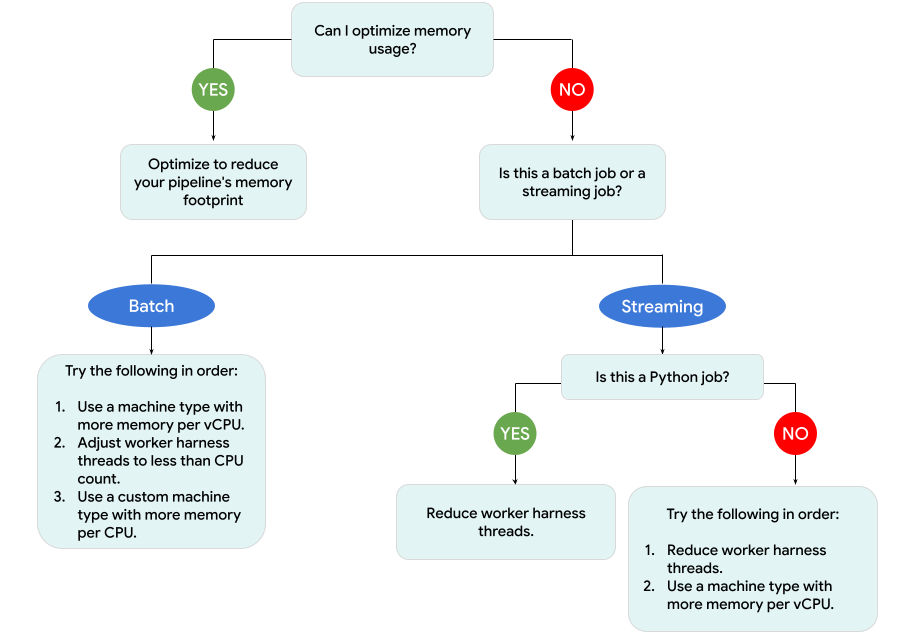
אפשר לנסות את הפתרונות הבאים:
- אם אפשר, כדאי לבצע אופטימיזציה של צינור עיבוד הנתונים כדי לצמצם את השימוש בזיכרון.
- אם העבודה היא עבודה באצווה, מנסים את השלבים הבאים לפי הסדר:
- שימוש בסוג מכונה עם יותר זיכרון לכל vCPU.
- צריך להקטין את מספר השרשורים כך שיהיה קטן ממספר ה-vCPU לכל עובד.
- משתמשים בסוג מכונה בהתאמה אישית עם יותר זיכרון לכל vCPU.
- אם העבודה היא עבודה של סטרימינג שמשתמשת ב-Python, צריך להקטין את מספר השרשורים לפחות מ-12.
- אם העבודה היא עבודה של סטרימינג שמשתמשת ב-Java או ב-Go, נסו את הפעולות הבאות:
- מצמצמים את מספר השרשורים לפחות מ-500 לעבודות שמשתמשות ב-Portable Runner, או לפחות מ-300 לעבודות שלא משתמשות ב-Portable Runner.
- משתמשים בסוג מכונה עם יותר זיכרון.
אופטימיזציה של צינור המכירות
כמה פעולות בצינור יכולות לגרום לשגיאות שקשורות לזיכרון. בקטע הזה מפורטות אפשרויות לצמצום השימוש בזיכרון של צינור עיבוד הנתונים. כדי לזהות את השלבים בצינור שצורכים הכי הרבה זיכרון, משתמשים ב-Cloud Profiler כדי לעקוב אחרי הביצועים של צינור עיבוד הנתונים.
כדי לבצע אופטימיזציה של צינור המכירות, אפשר להיעזר בשיטות המומלצות הבאות:
- שימוש במחברי קלט/פלט מובנים של Apache Beam לקריאת קבצים
- עיצוב מחדש של פעולות כשמשתמשים ב-
GroupByKeyPTransforms - הפחתת נתונים שנכנסים ממקורות חיצוניים
- שיתוף אובייקטים בין שרשורים
- שימוש בייצוגים של רכיבים שצורכים פחות זיכרון
- הקטנת הגודל של קלט צדדי
- שימוש ב-DoFn שניתן לפיצול ב-Apache Beam
שימוש במחברי קלט/פלט מובנים של Apache Beam לקריאת קבצים
לא מומלץ לפתוח קבצים גדולים בתוך DoFn. כדי לקרוא קבצים, משתמשים במחברי קלט/פלט מובנים של Apache Beam.
הקבצים שנפתחים ב-DoFn צריכים להיכנס לזיכרון. מכיוון שכמה מופעים של DoFn פועלים בו-זמנית, פתיחת קבצים גדולים ב-DoFn עלולה לגרום לשגיאות שקשורות לזיכרון.
פעולות עיצוב מחדש כשמשתמשים ב-GroupByKey PTransforms
כשמשתמשים ב-GroupByKey PTransform ב-Dataflow, הערכים שמתקבלים לכל מפתח ולכל חלון מעובדים בשרשור יחיד. הנתונים האלה מועברים כזרם משירות ה-Backend של Dataflow לעובדים, ולכן הם לא צריכים להיכנס לזיכרון של העובד. עם זאת, אם הערכים נאספים בזיכרון, יכול להיות שהלוגיקה של העיבוד תגרום לשגיאות של חריגה מהזיכרון.
לדוגמה, אם יש לכם מפתח שמכיל נתונים של חלון, ואתם מוסיפים את ערכי המפתח לאובייקט בזיכרון, כמו רשימה, יכול להיות שיופיעו שגיאות שקשורות לזיכרון. בתרחיש הזה, יכול להיות שלתהליך העבודה לא יהיה מספיק זיכרון כדי להכיל את כל האובייקטים.
מידע נוסף על GroupByKey PTransforms מופיע במאמרי העזרה של Apache Beam בנושא Python GroupByKey ו-Java GroupByKey.
הרשימה הבאה מכילה הצעות לעיצוב צינור עיבוד הנתונים כדי לצמצם את צריכת הזיכרון כשמשתמשים ב-GroupByKey PTransforms.
- כדי לצמצם את כמות הנתונים לכל מפתח ולכל חלון, מומלץ להימנע ממפתחות עם הרבה ערכים, שנקראים גם מקשי קיצור.
- כדי להקטין את כמות הנתונים שנאספים לכל חלון, משתמשים בגודל חלון קטן יותר.
- אם אתם משתמשים בערכים של מפתח בחלון כדי לחשב מספר, צריך להשתמש בטרנספורמציה
Combine. אל תבצעו את החישוב במופע יחיד שלDoFnאחרי איסוף הערכים. - לסנן ערכים או כפילויות לפני העיבוד. מידע נוסף מופיע במאמרי העזרה בנושא Python
Filterו-JavaFilter.
צמצום נתוני הכניסה ממקורות חיצוניים
אם אתם מבצעים קריאות ל-API חיצוני או למסד נתונים כדי להעשיר את הנתונים, הנתונים שמוחזרים צריכים להיכנס לזיכרון של העובד.
אם אתם משתמשים בקבוצות של קריאות, מומלץ להשתמש בGroupIntoBatches טרנספורמציה.
אם נתקלים בשגיאות שקשורות לזיכרון, צריך להקטין את גודל האצווה. מידע נוסף על קיבוץ לפעולות באצווה זמין במאמרי העזרה בנושא טרנספורמציה של Python GroupIntoBatches ושל Java GroupIntoBatches.
שיתוף אובייקטים בין שרשורים
שיתוף של אובייקט נתונים בזיכרון בין מופעים של DoFn יכול לשפר את היעילות של הגישה והשימוש במקום. אובייקטים של נתונים שנוצרו בכל שיטה של DoFn, כולל Setup, StartBundle, Process, FinishBundle ו-Teardown, מופעלים לכל DoFn. ב-Dataflow, לכל עובד יכולים להיות כמה DoFnמופעים. כדי להשתמש בזיכרון בצורה יעילה יותר, מעבירים אובייקט נתונים כ-singleton כדי לשתף אותו בין כמה רכיבי DoFn. מידע נוסף מופיע בפוסט בבלוג בנושא שימוש חוזר במטמון ב-DoFn.
שימוש בייצוגים של רכיבים שצורכים פחות זיכרון
כדאי לבדוק אם אפשר להשתמש בייצוגים של רכיבי PCollection
שצורכים פחות זיכרון. כשמשתמשים בקודים בצינור, כדאי לקחת בחשבון לא רק ייצוגים מקודדים של רכיבי PCollection, אלא גם ייצוגים מפוענחים. לרוב, אופטימיזציה מהסוג הזה יכולה להועיל למטריצות דלילות.
הקטנת הגודל של קלט צדדי
אם משתמשים ב-DoFns עם קלט צדדי, צריך לצמצם את הגודל של הקלט הצדדי. אם הקלט הצדדי הוא אוסף של רכיבים, כדאי להשתמש בתצוגות שניתן לחזור עליהן, כמו AsIterable או AsMultimap, במקום בתצוגות שמממשות את כל הקלט הצדדי בבת אחת, כמו AsList.
הפחתת מספר השרשורים
כדי להגדיל את הזיכרון שזמין לכל שרשור, אפשר להקטין את המספר המקסימלי של שרשורים שמריצים מופעים של DoFn. השינוי הזה מצמצם את המקביליות, אבל מאפשר להקצות יותר זיכרון לכל DoFn.
בטבלה הבאה מוצג מספר ברירת המחדל של השרשורים שנוצרים ב-Dataflow:
| סוג המשרה | Python SDK | ערכות Java/Go SDK |
|---|---|---|
| Batch | שרשור אחד לכל vCPU | שרשור אחד לכל vCPU |
| סטרימינג באמצעות Portable Runner (לשעבר Runner v2) | 12 שרשורים לכל vCPU | 500 threads לכל מכונת worker וירטואלית |
| סטרימינג ללא Portable Runner (לשעבר Runner v2) | 12 שרשורים לכל vCPU | 300 שרשורים לכל מכונה וירטואלית של worker |
כדי לצמצם את מספר השרשורים של Apache Beam SDK, מגדירים את אפשרות הצינור הבאה:
Java
משתמשים באפשרות --numberOfWorkerHarnessThreads של צינור עיבוד הנתונים.
Python
משתמשים באפשרות --number_of_worker_harness_threads של צינור עיבוד הנתונים.
המשך
משתמשים באפשרות --number_of_worker_harness_threads של צינור עיבוד הנתונים.
במשימות אצווה, מגדירים את הערך למספר שקטן ממספר ה-vCPU.
במשימות סטרימינג, מתחילים בהפחתת הערך למחצית מערך ברירת המחדל. אם השלב הזה לא פותר את הבעיה, ממשיכים להקטין את הערך בחצי, ובודקים את התוצאות בכל שלב. לדוגמה, כשמשתמשים ב-Python, כדאי לנסות את הערכים 6, 3, 0x0A ו-1.
שימוש בסוג מכונה עם יותר זיכרון לכל vCPU
כדי לבחור Worker עם יותר זיכרון לכל CPU וירטואלי, משתמשים באחת מהשיטות הבאות.
- משתמשים בסוג מכונה עם זיכרון גבוה במשפחת המכונות לשימוש כללי. סוגי מכונות עם כמות גדולה של זיכרון כוללים יותר זיכרון לכל vCPU בהשוואה לסוגי מכונות רגילים. שימוש בסוג מכונה עם כמות גדולה של זיכרון מגדיל את הזיכרון שזמין לכל תהליך עבודה ואת הזיכרון שזמין לכל שרשור, כי מספר ה-vCPU נשאר זהה. לכן, שימוש בסוג מכונה עם זיכרון גבוה יכול להיות דרך חסכונית לבחור תהליך עבודה עם יותר זיכרון לכל vCPU.
- כדי ליהנות מגמישות רבה יותר כשמציינים את מספר יחידות ה-vCPU ואת כמות הזיכרון, אפשר להשתמש בסוג מכונה מותאם אישית. עם סוגי מכונות בהתאמה אישית, אפשר להגדיל את הזיכרון בתוספות של 256 MB. התמחור של סוגי המכונות האלה שונה מהתמחור של סוגי מכונות רגילים.
- בכמה משפחות של מכונות אפשר להשתמש בסוגי מכונות מותאמים אישית עם זיכרון מורחב. זיכרון מורחב מאפשר יחס גבוה יותר של זיכרון לכל vCPU.
העלות גבוהה יותר. דוגמאות לסוגי מכונות בהתאמה אישית עם זיכרון מורחב כוללות את
n2-custom-1-19456-extו-n2-custom-8-317440-ext.
כדי להגדיר סוגי עובדים, משתמשים באפשרות הצינור הבאה. מידע נוסף מופיע במאמרים הגדרת אפשרויות של צינורות ואפשרויות של צינורות.
Java
משתמשים באפשרות --workerMachineType של צינור עיבוד הנתונים.
Python
משתמשים באפשרות --machine_type של צינור עיבוד הנתונים.
המשך
משתמשים באפשרות --worker_machine_type של צינור עיבוד הנתונים.
שימוש רק בתהליך אחד של Apache Beam SDK
בצינורות עיבוד נתונים של סטרימינג ב-Python ובצינורות עיבוד נתונים ב-Python שמשתמשים ב-Portable Runner, אפשר להגדיר ש-Dataflow יתחיל רק תהליך אחד של Apache Beam SDK לכל עובד.
לפני שמנסים את האפשרות הזו, כדאי לנסות קודם לפתור את הבעיה באמצעות השיטות האחרות. כדי להגדיר מכונות וירטואליות של Dataflow worker כך שיפעילו רק תהליך Python אחד שמבוסס על קונטיינר, משתמשים באפשרות צינור עיבוד הנתונים הבאה:
--experiments=no_use_multiple_sdk_containers
במקרה כזה, צינורות Python יוצרים תהליך אחד של Apache Beam SDK לכל עובד. ההגדרה הזו מונעת שכפול של האובייקטים והנתונים המשותפים כמה פעמים לכל תהליך של Apache Beam SDK. עם זאת, היא מגבילה את השימוש היעיל במשאבי החישוב שזמינים ב-worker.
צמצום מספר התהליכים של Apache Beam SDK לאחד לא בהכרח יקטין את המספר הכולל של השרשורים שהופעלו בעובד. בנוסף, אם כל השרשורים נמצאים בתהליך אחד של Apache Beam SDK, יכול להיות שהעיבוד יהיה איטי או שהצינור ייעצר. לכן, יכול להיות שתצטרכו גם לצמצם את מספר השרשורים, כפי שמתואר בקטע צמצום מספר השרשורים בדף הזה.
אפשר גם להגדיר שהעובדים ישתמשו רק בתהליך אחד של Apache Beam SDK באמצעות סוג מכונה עם vCPU אחד בלבד.
הסבר על השימוש בזיכרון ב-Dataflow
כדי לפתור בעיות שקשורות לזיכרון, כדאי להבין איך צינורות Dataflow משתמשים בזיכרון.
כשמריצים צינור עיבוד נתונים ב-Dataflow, העיבוד מתבצע באופן מבוזר בכמה מכונות וירטואליות (VM) של Compute Engine, שלרוב נקראות workers.
תהליכי Worker מעבדים פריטי עבודה משירות Dataflow ומקצים את פריטי העבודה לתהליכי Apache Beam SDK. תהליך של Apache Beam SDK יוצר מופעים של DoFns. DoFn היא מחלקה ב-Apache Beam SDK שמגדירה פונקציית עיבוד מבוזרת.
מערכת Dataflow מפעילה כמה שרשורים בכל עובד, והזיכרון של כל עובד משותף לכל השרשורים. שרשור הוא משימה אחת שניתנת להרצה ופועלת בתוך תהליך גדול יותר. מספר ברירת המחדל של השרשורים תלוי בכמה גורמים, והוא שונה בין משימות אצווה לבין משימות סטרימינג.
אם הצינור צריך יותר זיכרון מהכמות שמוגדרת כברירת מחדל וזמינה לעובדים, יכול להיות שתיתקלו בשגיאות שקשורות לחוסר זיכרון.
צינורות עיבוד נתונים של Dataflow משתמשים בזיכרון של העובדים בעיקר בשלוש דרכים:
זיכרון תפעולי של העובד
ל-workers של Dataflow נדרש זיכרון למערכות ההפעלה ולתהליכי המערכת שלהם. בדרך כלל, השימוש בזיכרון של העובד לא עולה על 1GB. השימוש בדרך כלל קטן מ-1GB.
- תהליכים שונים ב-Worker משתמשים בזיכרון כדי לוודא שצינור עיבוד הנתונים פועל בצורה תקינה. כל אחד מהתהליכים האלה עשוי לשריין כמות קטנה של זיכרון לצורך הפעולה שלו.
- כשלא משתמשים ב-Streaming Engine בצינור העברת הנתונים, תהליכי עובד נוספים משתמשים בזיכרון.
זיכרון התהליך של ה-SDK
תהליכי SDK של Apache Beam עשויים ליצור אובייקטים ונתונים שמשותפים בין השרשורים בתהליך, שנקראים בדף הזה אובייקטים ונתונים משותפים של SDK. השימוש בזיכרון מאובייקטים משותפים ומנתונים של ה-SDK נקרא זיכרון תהליך של ה-SDK. הרשימה הבאה כוללת דוגמאות לאובייקטים ולנתונים משותפים של SDK:
- מקורות קלט נוספים
- מודלים של למידת מכונה
- אובייקטים מסוג Singleton בזיכרון
- אובייקטים של Python שנוצרו באמצעות המודול
apache_beam.utils.shared - נתונים שנטענו ממקורות חיצוניים, כמו Cloud Storage או BigQuery
עבודות סטרימינג שלא משתמשות ב-Streaming Engine מאחסנות את הקלט בצד הזיכרון. בצינורות Java ו-Go, לכל עובד יש עותק אחד של קלט הצד. בצינורות Python, לכל תהליך של Apache Beam SDK יש עותק אחד של קלט צדדי.
למשימות סטרימינג שמשתמשות ב-Streaming Engine יש מגבלה של 80 MB על גודל קלט צדדי. ערכי קלט צדדיים מאוחסנים מחוץ לזיכרון של העובד.
השימוש בזיכרון מאובייקטים משותפים ומנתונים של SDK גדל באופן ליניארי עם מספר התהליכים של Apache Beam SDK. בצינורות Java ו-Go, מתחיל תהליך אחד של Apache Beam SDK לכל עובד. בצינורות Python, מתחיל תהליך אחד של Apache Beam SDK לכל vCPU. אובייקטים משותפים ונתונים של SDK נעשה בהם שימוש חוזר בשרשורים בתהליך SDK של Apache Beam.
DoFn שימוש בזיכרון
DoFn היא מחלקה ב-Apache Beam SDK שמגדירה פונקציית עיבוד מבוזרת.
כל עובד יכול להריץ DoFn מופעים בו-זמנית. כל שרשור מריץ מופע אחד של DoFn. כשמעריכים את סך השימוש בזיכרון, יכול להיות שיהיה שימושי לחשב את גודל קבוצת העבודה או את כמות הזיכרון שנדרשת כדי שהאפליקציה תמשיך לפעול. לדוגמה, אם משתמש DoFn משתמש במקסימום 5 MB של זיכרון ולתהליך יש 300 ת'רדים, אז השימוש בזיכרון DoFn יכול להגיע לשיא של 1.5 GB, או מספר הבייטים של הזיכרון כפול מספר הת'רדים. בהתאם לאופן שבו העובדים משתמשים בזיכרון, עלייה חדה בשימוש בזיכרון עלולה לגרום לכך שלא יישאר לעובדים זיכרון פנוי.
קשה להעריך כמה מופעים של DoFn נוצרים ב-Dataflow. המספר תלוי בגורמים שונים, כמו ה-SDK, סוג המכונה ומשתנים אחרים. בנוסף, יכול להיות שכמה שרשורים ישתמשו ב-DoFn ברצף. שירות Dataflow לא מבטיח כמה פעמים מופעלת DoFn, וגם לא מבטיח את המספר המדויק של מופעי DoFn שנוצרים במהלך צינור. עם זאת,
בטבלה הבאה מופיעות כמה תובנות לגבי רמת המקביליות שאפשר לצפות לה, והערכה של הגבול העליון של מספר המופעים של DoFn.
Beam Python SDK
| Batch | סטרימינג ללא מנוע סטרימינג | מנוע סטרימינג | |
|---|---|---|---|
| מקביליות |
תהליך אחד לכל vCPU שרשור אחד לכל תהליך שרשור אחד לכל vCPU |
תהליך אחד לכל vCPU 12 שרשורים לכל תהליך 12 שרשורים לכל vCPU |
תהליך אחד לכל vCPU 12 שרשורים לכל תהליך 12 שרשורים לכל vCPU |
מספר המופעים המקסימלי של DoFn בו-זמנית (כל המספרים האלה עשויים להשתנות בכל שלב). |
1 1 |
1 12 |
1 12 |
Beam Java/Go SDK
| Batch | מכשיר סטרימינג ומנוע סטרימינג ללא Portable Runner | מנוע סטרימינג עם Portable Runner | |
|---|---|---|---|
| מקביליות |
תהליך אחד לכל מכונת worker וירטואלית שרשור אחד לכל vCPU |
תהליך אחד לכל מכונת worker וירטואלית 300 שרשורים לכל תהליך 300 threads לכל מכונה וירטואלית של worker |
תהליך אחד לכל מכונת worker וירטואלית 500 שרשורים לכל תהליך 500 threads לכל מכונת worker וירטואלית |
מספר המופעים המקסימלי של DoFn בו-זמנית (כל המספרים האלה עשויים להשתנות בכל שלב). |
1 1 |
1 300 |
1 500 |
לדוגמה, כשמשתמשים ב-Python SDK עם n1-standard-2
Dataflow worker, התנאים הבאים חלים:
- משימות באצווה: Dataflow מפעיל תהליך אחד לכל vCPU (שניים במקרה הזה). כל תהליך משתמש בשרשור אחד, וכל שרשור יוצר מופע אחד של
DoFn. - משימות סטרימינג עם מנוע סטרימינג: Dataflow מפעיל תהליך אחד לכל CPU וירטואלי (שני תהליכים בסך הכול). עם זאת, כל תהליך יכול ליצור עד 12 שרשורים, שלכל אחד מהם יש מופע DoFn משלו.
כשמעצבים צינורות מורכבים, חשוב להבין את DoFnמחזור החיים.
חשוב לוודא שהפונקציות של DoFn ניתנות לסריאליזציה, ולהימנע משינוי הארגומנט של הרכיב ישירות בתוכן שלהן.
אם יש לכם צינור עיבוד נתונים רב-לשוני, ויותר מ-SDK אחד של Apache Beam פועל בתהליך העבודה, התהליך משתמש בדרגת המקביליות הנמוכה ביותר האפשרית של שרשור לכל תהליך.
ההבדלים בין Java, Go ו-Python
התהליכים והזיכרון מנוהלים ב-Java, ב-Go וב-Python בצורה שונה. לכן, הגישה שצריך לנקוט כשמנסים לפתור בעיות שקשורות לשגיאות חוסר זיכרון משתנה בהתאם לשפה שבה משתמשים בצינור עיבוד הנתונים: Java, Go או Python.
צינורות עיבוד נתונים של Java ו-Go
בצינורות עיבוד נתונים של Java ו-Go:
- כל תהליך עובד מתחיל תהליך Apache Beam SDK אחד.
- אובייקטים ונתונים משותפים של SDK, כמו קלט צדדי ומטמון, משותפים בין כל השרשורים של העובד.
- הזיכרון שמשמש את האובייקטים והנתונים המשותפים של ה-SDK בדרך כלל לא משתנה בהתאם למספר המעבדים הווירטואליים במכונת העובד.
צינורות עיבוד נתונים של Python
בצינורות עיבוד נתונים של Python:
- כל עובד מתחיל תהליך אחד של Apache Beam SDK לכל vCPU.
- אובייקטים ונתונים משותפים של SDK, כמו קלט צדדי ומטמונים, משותפים בין כל השרשורים בכל תהליך של Apache Beam SDK.
- המספר הכולל של השרשורים בתהליך העבודה גדל באופן לינארי בהתאם למספר המעבדים הווירטואליים. כתוצאה מכך, הזיכרון שמשמש לאובייקטים ולנתונים משותפים של SDK גדל באופן ליניארי עם מספר ליבות ה-CPU הווירטואליות.
- השרשורים שמבצעים את העבודה מפוזרים בין התהליכים. יחידות עבודה חדשות מוקצות לתהליך ללא פריטי עבודה, או לתהליך עם הכי פחות פריטי עבודה שהוקצו לו באותו זמן.