
בדף הזה מוסבר על מחזור החיים של צינור, מקוד הצינור ועד לעבודת Dataflow.
בדף הזה נסביר את המושגים הבאים:
- מהו תרשים ביצוע ואיך צינור עיבוד נתונים של Apache Beam הופך לעבודת Dataflow
- איך Dataflow מטפל בשגיאות
- איך Dataflow מבצע באופן אוטומטי הקבלה וחלוקה של לוגיקת העיבוד בצינור (pipeline) לעובדים שמבצעים את העבודה
- אופטימיזציות של משימות ש-Dataflow עשוי לבצע
תרשים ביצוע
כשמריצים את צינור הנתונים של Dataflow, Dataflow יוצר גרף ביצוע מהקוד שבונה את אובייקט Pipeline, כולל כל הטרנספורמציות ופונקציות העיבוד המשויכות להן, כמו אובייקטים של DoFn. זהו תרשים הביצוע של צינור הנתונים, והשלב נקרא זמן בניית התרשים.
במהלך בניית הגרף, Apache Beam מריץ באופן מקומי את הקוד מנקודת הכניסה הראשית של קוד צינור עיבוד הנתונים, ועוצר בקריאות לשלב של מקור, יעד או טרנספורמציה, והופך את הקריאות האלה לצמתים בגרף.
לכן, קטע קוד בנקודת הכניסה של צינור עיבוד נתונים (שיטת Java ו-Go main
או הרמה העליונה של סקריפט Python) מופעל באופן מקומי במחשב שמריץ את צינור עיבוד הנתונים. אותו קוד שהוגדר בשיטה של אובייקט DoFn מופעל בתהליכי העבודה של Dataflow.
לדוגמה, הדוגמה WordCount שכלולה בערכות ה-SDK של Apache Beam מכילה סדרה של טרנספורמציות לקריאה, לחילוץ, לספירה, לעיצוב ולכתיבה של המילים הנפרדות באוסף של טקסט, יחד עם ספירת המופעים של כל מילה. בתרשים הבא מוצג תהליך ההרחבה של טרנספורמציות בצינור WordCount לגרף ביצוע:
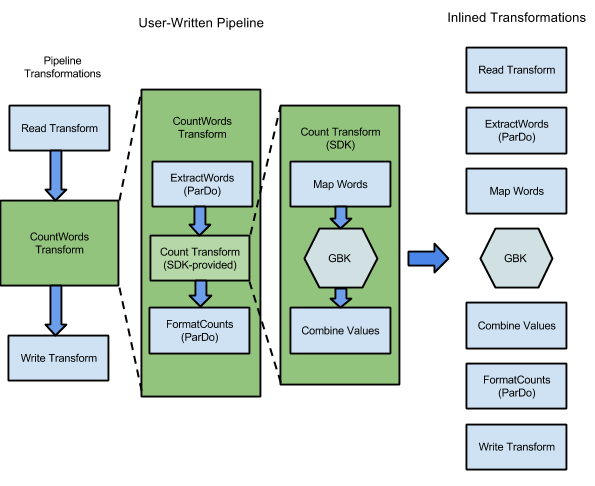
איור 1: תרשים של ביצוע לדוגמה של WordCount
תרשים הביצוע שונה לעיתים קרובות מהסדר שבו ציינתם את ההמרות כשבניתם את צינור העיבוד. ההבדל הזה נובע מכך ששירות Dataflow מבצע אופטימיזציות ומיזוגים שונים בגרף הביצוע לפני שהוא פועל על משאבי ענן מנוהלים. שירות Dataflow מכבד את התלות בנתונים בזמן ההפעלה של צינור הנתונים. עם זאת, יכול להיות ששלבים שלא תלויים בנתונים של שלבים אחרים יפעלו בכל סדר.
כדי לראות את תרשים הביצוע הלא אופטימלי ש-Dataflow יצר עבור צינור עיבוד הנתונים, בוחרים את הג'וב בממשק המעקב של Dataflow. מידע נוסף על הצגת משימות זמין במאמר שימוש בממשק המעקב של Dataflow.
במהלך בניית הגרף, Apache Beam מאמת שכל המשאבים שהצינור מפנה אליהם, כמו קטגוריות של Cloud Storage, טבלאות של BigQuery ונושאים או מינויים של Pub/Sub, קיימים ונגישים. האימות מתבצע באמצעות קריאות רגילות ל-API של השירותים הרלוונטיים, ולכן חשוב שלחשבון המשתמש שמשמש להרצת צינור יש קישוריות תקינה לשירותים הנדרשים והרשאה לקרוא לממשקי ה-API של השירותים. לפני שליחת צינור הנתונים לשירות Dataflow, Apache Beam גם בודק אם יש שגיאות אחרות, ומוודא שגרף צינור הנתונים לא מכיל פעולות לא חוקיות.
גרף הביצוע מתורגם לפורמט JSON, וגרף הביצוע בפורמט JSON מועבר לנקודת הקצה של שירות Dataflow.
לאחר מכן, שירות Dataflow מאמת את גרף ההפעלה של ה-JSON. כשמאמתים את הגרף, הוא הופך לעבודה בשירות Dataflow. אתם יכולים לראות את העבודה, את תרשים הביצוע שלה, את הסטטוס ואת פרטי היומן באמצעות ממשק המעקב של Dataflow.
Java
שירות Dataflow שולח תגובה למכונה שבה מריצים את תוכנית Dataflow. התשובה הזו מוכלת באובייקט DataflowPipelineJob, שמכיל את jobId של משימת Dataflow.
אפשר להשתמש בjobId כדי לעקוב אחרי המשימה, לנטר אותה ולפתור בה בעיות באמצעות ממשק המעקב של Dataflow וממשק שורת הפקודה של Dataflow.
מידע נוסף מופיע בהפניית API של DataflowPipelineJob.
Python
שירות Dataflow שולח תגובה למכונה שבה מריצים את תוכנית Dataflow. התשובה הזו מוכלת באובייקט DataflowPipelineResult, שמכיל את job_id של משימת Dataflow.
אפשר להשתמש ב-job_id כדי לעקוב אחרי המשימה, לנטר אותה ולפתור בה בעיות באמצעות ממשק המעקב של Dataflow וממשק שורת הפקודה של Dataflow.
המשך
שירות Dataflow שולח תגובה למכונה שבה מריצים את תוכנית Dataflow. התשובה הזו מוכלת באובייקט dataflowPipelineResult, שמכיל את jobID של משימת Dataflow.
אפשר להשתמש ב-jobID כדי לעקוב אחרי המשימה, לנטר אותה ולפתור בה בעיות באמצעות ממשק המעקב של Dataflow וממשק שורת הפקודה של Dataflow.
בנוסף, בניית הגרף מתבצעת כשמריצים את צינור הנתונים באופן מקומי, אבל הגרף לא מתורגם ל-JSON ולא מועבר לשירות. במקום זאת, הגרף מופעל באופן מקומי באותו מחשב שבו הפעלתם את תוכנית Dataflow. מידע נוסף זמין במאמר הגדרת PipelineOptions להרצה מקומית.
טיפול בשגיאות ובחריגים
יכול להיות שצינור הנתונים יזרוק חריגים במהלך עיבוד הנתונים. חלק מהשגיאות האלה הן זמניות, כמו קושי זמני בגישה לשירות חיצוני. שגיאות אחרות הן קבועות, כמו שגיאות שנגרמות בגלל נתוני קלט פגומים או כאלה שלא ניתן לנתח, או מצביעים על ערך null במהלך החישוב.
Dataflow מעבד רכיבים בחבילות שרירותיות, ומנסה שוב לעבד את החבילה כולה אם מתרחשת שגיאה ברכיב כלשהו בחבילה. כשמריצים במצב אצווה, המערכת מנסה שוב ארבע פעמים להוריד חבילות שכוללות פריט שנכשל. הצינור נכשל לחלוטין אם חבילה אחת נכשלת ארבע פעמים. כשמפעילים את הצינור במצב סטרימינג, המערכת מנסה שוב ושוב לטפל בחבילה שכוללת פריט שנכשל, ולכן יכול להיות שהצינור ייעצר לתמיד.
כשמעבדים במצב אצווה, יכול להיות שיופיע מספר גדול של כשלים פרטניים לפני שמשימת צינור נתונים נכשלת לחלוטין. זה קורה כשחבילה נתונה נכשלת אחרי ארבעה ניסיונות חוזרים. לדוגמה, אם צינור העברת הנתונים מנסה לעבד 100 חבילות, יכול להיות ש-Dataflow ייצור כמה מאות כשלים נפרדים עד שחבילה אחת תגיע לתנאי של ארבעה כשלים ליציאה.
שגיאות בהפעלת העובדים, כמו כשל בהתקנת חבילות בעובדים, הן זמניות. במקרה כזה, המערכת תנסה שוב ושוב ללא הפסקה, והצינור עלול להיתקע באופן קבוע.
הקצאה מקבילית והפצה
שירות Dataflow מבצע באופן אוטומטי הקבלה וחלוקה של לוגיקת העיבוד בצינור העיבוד לעובדים שמוקצים לביצוע העבודה. Dataflow משתמש בהפשטות במודל התכנות כדי לייצג פונקציות של עיבוד מקביל. לדוגמה, הטרנספורמציות ParDo בצינור גורמות ל-Dataflow להפיץ באופן אוטומטי קוד עיבוד, שמיוצג על ידי אובייקטים DoFn, לכמה עובדים כדי להריץ אותו במקביל.
יש שני סוגים של הרצת משימות במקביל:
מקבילות אופקית מתרחשת כשנתוני צינור מחולקים ומעובדים בכמה מכונות worker בו-זמנית. סביבת זמן הריצה של Dataflow מבוססת על מאגר של עובדים מבוזרים. לצינור יש פוטנציאל גבוה יותר להרצה מקבילית כשהמאגר מכיל יותר עובדים, אבל להגדרה הזו יש גם עלות גבוהה יותר. תיאורטית, אין מגבלה עליונה על מקביליות אופקית. עם זאת, כדי לבצע אופטימיזציה של השימוש במשאבים בכל הצי, Dataflow מגביל את מאגר העובדים ל-4,000 עובדים.
מקביליות אנכית מתרחשת כשנתוני צינור העיבוד מפוצלים ומעובדים על ידי כמה ליבות CPU באותו תהליך עובד. כל עובד מופעל על ידי מכונה וירטואלית ב-Compute Engine. מכונה וירטואלית יכולה להריץ כמה תהליכים כדי להגיע לניצול מלא של כל ליבות ה-CPU שלה. למכונה וירטואלית עם יותר ליבות יש פוטנציאל גבוה יותר של מקביליות אנכית, אבל ההגדרה הזו גורמת לעלויות גבוהות יותר. מספר גבוה יותר של ליבות מוביל לעיתים קרובות לשימוש מוגבר בזיכרון, ולכן מספר הליבות בדרך כלל מותאם לגודל הזיכרון. בגלל המגבלה הפיזית של ארכיטקטורות מחשב, הגבול העליון של מקביליות אנכית נמוך בהרבה מהגבול העליון של מקביליות אופקית.
מקביליות מנוהלת
כברירת מחדל, Dataflow מנהל באופן אוטומטי את המקביליות של העבודות. Dataflow עוקב אחרי נתוני זמן הריצה של המשימה, כמו שימוש במעבד ובשימוש בזיכרון, כדי לקבוע איך לשנות את קנה המידה של המשימה. בהתאם להגדרות של העבודה, Dataflow יכול להרחיב את העבודות באופן אופקי, שנקרא הרחבה אוטומטית אופקית, או באופן אנכי, שנקרא הרחבה אנכית. שינוי קנה מידה אוטומטי במקביל לאופטימיזציה של עלות העבודה וביצועי העבודה.
כדי לשפר את ביצועי העבודה, Dataflow גם מבצע אופטימיזציה של צינורות עיבוד נתונים באופן פנימי. אופטימיזציות אופייניות הן אופטימיזציה של מיזוג ואופטימיזציה של שילוב. על ידי מיזוג שלבים בצינור עיבוד הנתונים, Dataflow מבטל עלויות מיותרות שקשורות לתיאום שלבים במערכת מבוזרת ולהרצה של כל שלב בנפרד.
גורמים שמשפיעים על מקביליות
הגורמים הבאים משפיעים על רמת המקביליות בעבודות Dataflow.
מקור הקלט
אם מקור קלט לא מאפשר מקביליות, שלב ההטמעה של מקור הקלט עלול להפוך לצוואר בקבוק במשימת Dataflow. לדוגמה, כשמבצעים המרה של נתונים מקובץ טקסט דחוס יחיד, Dataflow לא יכול לבצע הקבלה של נתוני הקלט. מכיוון שאי אפשר לחלק באופן שרירותי את רוב פורמטי הדחיסה לשברים במהלך ההטמעה, Dataflow צריך לקרוא את הנתונים באופן רציף מתחילת הקובץ. החלק הלא מקבילי של צינור העיבוד מאט את קצב העברת הנתונים הכולל של צינור העיבוד. הפתרון לבעיה הזו הוא להשתמש במקור קלט שניתן להרחבה.
במקרים מסוימים, מיזוג השלבים גם מקטין את המקביליות. אם מקור הקלט לא מאפשר מקביליות, ו-Dataflow ממזג את שלב קליטת הנתונים עם השלבים הבאים ומקצה את השלב הממוזג הזה לשרשור יחיד, יכול להיות שצינור הנתונים כולו יפעל לאט יותר.
כדי למנוע את התרחיש הזה, מוסיפים שלב Redistribute אחרי שלב ההטמעה של מקור הקלט. מידע נוסף מופיע בקטע מניעת מיזוג במסמך הזה.
ברירת מחדל של פיצול נתונים וצורה של נתונים
הפיצול (fanout) שמוגדר כברירת מחדל בשלב טרנספורמציה יחיד עלול להפוך לצוואר בקבוק ולהגביל את המקביליות. לדוגמה, טרנספורמציה של ParDo 'פיצול גבוה' עלולה לגרום למיזוג להגביל את היכולת של Dataflow לבצע אופטימיזציה של השימוש בעובדים. בפעולה כזו, יכול להיות שיש לכם אוסף קלט עם יחסית מעט רכיבים, אבל הפונקציה ParDo מייצרת פלט עם פי מאות או אלפי רכיבים, ואחריה עוד פונקציה ParDo. אם שירות Dataflow ממזג את הפעולות האלה של ParDo, המקביליות בשלב הזה מוגבלת למספר הפריטים בקולקציית הקלט, גם אם PCollection הביניים מכיל הרבה יותר רכיבים.
פתרונות אפשריים מפורטים בקטע מניעת מיזוג במאמר הזה.
צורת נתונים
הצורה של הנתונים, בין אם מדובר בנתוני קלט או בנתוני ביניים, יכולה להגביל את ההרצה המקבילית.
לדוגמה, אם שלב GroupByKey במפתח טבעי, כמו עיר, מופיע אחרי שלב map או Combine, Dataflow ממזג את שני השלבים. אם מרחב המפתחות קטן, למשל חמש ערים, ומפתח אחד הוא חם מאוד, למשל עיר גדולה, רוב הפריטים בפלט של שלב GroupByKey מופצים לתהליך אחד. התהליך הזה הופך לצוואר בקבוק ומאט את העבודה.
בדוגמה הזו, אפשר לחלק מחדש את התוצאות של שלב GroupByKey למרחב גדול יותר של מפתחות מלאכותיים במקום להשתמש במפתחות הטבעיים. Insert a
Redistribute step between the GroupByKey step and the map or Combine
step. בשלב Redistribute, יוצרים את מרחב המפתחות המלאכותי, למשל באמצעות פונקציית hash, כדי להתגבר על המקביליות המוגבלת שנובעת מצורת הנתונים.
מידע נוסף מופיע בקטע מניעת מיזוג במסמך הזה.
דיכוי פלט
יעד הוא טרנספורמציה שכותבת למערכת אחסון נתונים חיצונית, כמו קובץ או מסד נתונים. בפועל, יעד נתונים ממומש כאובייקט DoFn רגיל, ומשמש להעברת נתונים מ-PCollection למערכות חיצוניות.
במקרה הזה, PCollection מכיל את התוצאות הסופיות של הצינור. שרשורים שקוראים לממשקי API של sink יכולים לפעול במקביל כדי לכתוב נתונים למערכות החיצוניות. כברירת מחדל, אין תיאום בין השרשורים. בלי שכבת ביניים שתאגור את בקשות הכתיבה ותשלוט בזרימת הנתונים, המערכת החיצונית עלולה להיות עמוסה מדי ולצמצם את קצב העברת הנתונים. הגדלת המשאבים על ידי הוספת מקביליות עשויה להאט עוד יותר את צינור העיבוד.
הפתרון לבעיה הזו הוא לצמצם את המקביליות בשלב הכתיבה.
אפשר להוסיף שלב GroupByKey ממש לפני שלב הכתיבה. השלב GroupByKey
מחלק את נתוני הפלט לקבוצות קטנות יותר של אצווה כדי לצמצם את מספר הקריאות הכולל של RPC ואת מספר החיבורים למערכות חיצוניות. לדוגמה, אפשר להשתמש ב-GroupByKey כדי ליצור מרחב גיבוב של 50 מתוך מיליון נקודות נתונים.
החיסרון בגישה הזו הוא שהיא יוצרת מגבלה קשיחה על מקביליות. אפשרות נוספת היא להטמיע השהיה מעריכית לפני ניסיון חוזר (exponential backoff) ביעד כשכותבים נתונים. האפשרות הזו יכולה לספק הגבלת קצב מינימלית של הלקוח.
מעקב אחרי מקביליות
כדי לעקוב אחרי מקביליות, אפשר להשתמש במסוף Google Cloud כדי לראות אם יש משימות שמתעכבות. מידע נוסף מופיע במאמרים בנושא פתרון בעיות של משימות שמתעכבות בעבודות אצווה ופתרון בעיות של משימות שמתעכבות בעבודות סטרימינג.
אופטימיזציה של מיזוג
אחרי שגרף הביצוע של צינור הנתונים בפורמט JSON עובר אימות, שירות Dataflow עשוי לשנות את הגרף כדי לבצע אופטימיזציות.
האופטימיזציות יכולות לכלול מיזוג של כמה שלבים או טרנספורמציות בתרשים הביצוע של צינור הנתונים לשלבים בודדים. מיזוג השלבים מונע את הצורך בשירות Dataflow לממש כל PCollection ביניים בצינור עיבוד הנתונים, מה שיכול להיות יקר מבחינת זיכרון ותקורה של עיבוד.
למרות שכל הטרנספורמציות שאתם מציינים בבניית צינור הנתונים מבוצעות בשירות, כדי להבטיח את הביצוע היעיל ביותר של צינור הנתונים, יכול להיות שהטרנספורמציות יבוצעו בסדר שונה או כחלק מטרנספורמציה גדולה יותר. שירות Dataflow מתחשב בתלות של נתונים בין השלבים בתרשים הביצוע, אבל יכול להיות שהשלבים יבוצעו בכל סדר אחר.
דוגמה ל-Fusion
בתרשים הבא מוצג איך אפשר לבצע אופטימיזציה של גרף הביצוע מהדוגמה WordCount שכלולה ב-Apache Beam SDK for Java, ולמזג אותו באמצעות שירות Dataflow כדי להשיג ביצוע יעיל:
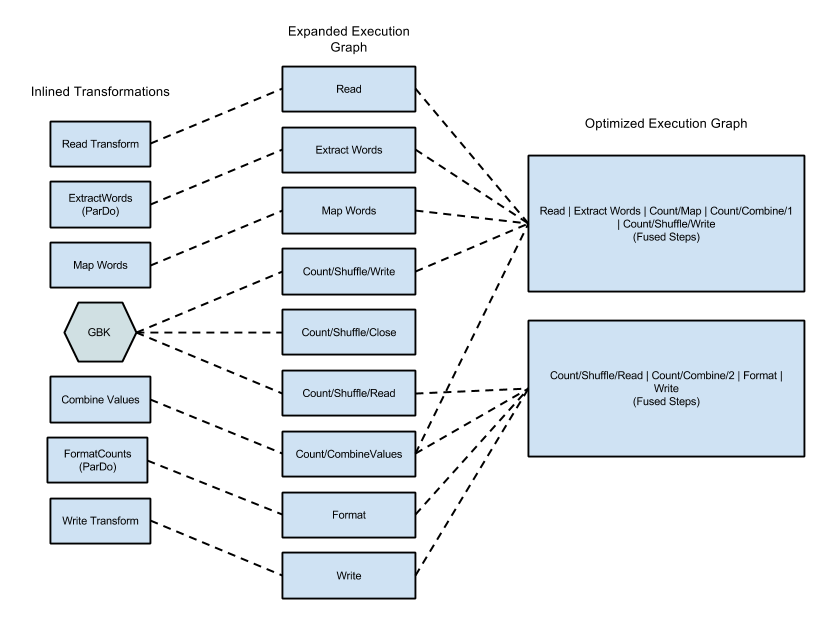
איור 2: דוגמה לתרשים ביצוע אופטימלי של WordCount
מניעת מיזוג
במקרים מסוימים, יכול להיות ש-Dataflow ינחש בצורה שגויה את הדרך האופטימלית לאחד פעולות בצינור, מה שיגביל את היכולת של Dataflow להשתמש בכל העובדים הזמינים. במקרים כאלה, אפשר להשתמש בטרנספורמציה Redistribute כדי לתת ל-Dataflow רמז לחלוקה מחדש של הנתונים.
כדי להוסיף טרנספורמציה של Redistribute, קוראים לאחת מהשיטות הבאות:
Redistribute.arbitrarily: מציין שהנתונים כנראה לא מאוזנים. Dataflow בוחר את האלגוריתם הטוב ביותר לחלוקה מחדש של הנתונים.
Redistribute.byKey: מציין שסביר להניח ש-PCollectionשל צמדי מפתח/ערך לא מאוזן, וצריך לבצע חלוקה מחדש על סמך המפתחות. בדרך כלל, Dataflow ממקם את כל הרכיבים של מפתח יחיד באותו Thread עובד. עם זאת, אין ערובה לכך שהמפתחות ימוקמו באותו מקום, והרכיבים מעובדים בנפרד.
אם צינור הנתונים מכיל טרנספורמציה Redistribute, בדרך כלל Dataflow מונע מיזוג של השלבים לפני הטרנספורמציה Redistribute ואחריה, ומבצע ערבוב של הנתונים כדי שהמקביליות של השלבים בהמשך הטרנספורמציה Redistribute תהיה אופטימלית יותר.
מיזוג צגים
אפשר לגשת לגרף המותאם ולשלבים הממוזגים במסוף Google Cloud , באמצעות ה-CLI של gcloud או באמצעות ה-API.
המסוף
כדי לראות את השלבים המאוחדים בתרשים ב-Console, פותחים את התרשים Stage workflow בכרטיסייה Execution details של משימת Dataflow.
כדי לראות את השלבים שמוזגו לשלב מסוים, לוחצים על השלב הממוזג בגרף. בחלונית פרטי השלב, בשורה Component steps (שלבי הרכיב) מוצגים השלבים המאוחדים. לפעמים חלקים של טרנספורמציה מורכבת אחת מאוחדים לכמה שלבים.
gcloud
כדי לגשת לגרף האופטימלי ולשלבים הממוזגים באמצעות ה-CLI של gcloud, מריצים את הפקודה הבאה gcloud:
gcloud dataflow jobs describe --full JOB_ID --format json
מחליפים את JOB_ID במזהה של משימת Dataflow.
כדי לחלץ את החלקים הרלוונטיים, מעבירים את הפלט של הפקודה gcloud ל-jq:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
כדי לראות את התיאור של השלבים הממוזגים בקובץ התגובה של הפלט, בתוך המערך
ComponentTransform, צריך לעיין באובייקט
ExecutionStageSummary.
API
כדי לגשת לתרשים הממוטב ולשלבים הממוזגים באמצעות ה-API, צריך לקרוא ל-project.locations.jobs.get.
כדי לראות את התיאור של השלבים הממוזגים בקובץ התגובה של הפלט, בתוך המערך
ComponentTransform, צריך לעיין באובייקט
ExecutionStageSummary.
אופטימיזציה משולבת
פעולות צבירה הן מושג חשוב בעיבוד נתונים בקנה מידה גדול.
צבירה מאחדת נתונים שרחוקים זה מזה מבחינה מושגית, ולכן היא שימושית מאוד לצורך קורלציה. מודל התכנות של Dataflow מייצג פעולות צבירה כטרנספורמציות GroupByKey, CoGroupByKey ו-Combine.
פעולות הצבירה של Dataflow משלבות נתונים בכל מערך הנתונים, כולל נתונים שאולי מפוזרים בין כמה עובדים. במהלך פעולות צבירה כאלה, לרוב הכי יעיל לשלב כמה שיותר נתונים באופן מקומי לפני שמשלבים נתונים בין מופעים. כשמחילים טרנספורמציה של GroupByKey או טרנספורמציה מצטברת אחרת, שירות Dataflow מבצע באופן אוטומטי שילוב חלקי באופן מקומי לפני פעולת הקיבוץ הראשית.
כשמבצעים שילוב חלקי או רב-רמות, שירות Dataflow מקבל החלטות שונות בהתאם לסוג הנתונים שצינור הנתונים עובד איתם – נתונים באצווה או נתונים בסטרימינג. בנתונים מוגבלים, השירות מעדיף יעילות ויבצע כמה שיותר שילובים מקומיים. בנתונים לא מוגבלים, השירות מעדיף זמן אחזור קצר יותר, ויכול להיות שהוא לא יבצע שילוב חלקי כי הוא עלול להגדיל את זמן האחזור.