
データを統合すると、複数のデータソースに基づくグラフ、テーブル、コントロールを作成できます。データポータルまたは Looker レポートでは、最大 5 つのデータソースのデータを統合できます。
たとえば、異なる BigQuery テーブル(例: 顧客情報と注文詳細)のデータを統合して、データポータルで 1 つのテーブルを作成して情報を視覚化できます。別の例として、Google 広告アカウントと Google アナリティクス アカウントのデータを組み合わせて時系列で表示して、マーケティング キャンペーンのパフーマンスの全体像を把握することも可能です。
統合とデータソースの違い
データを統合すると、「統合」と呼ばれるリソースが作成されます。統合は、レポートのグラフとコントロールにデータを提供するという点で、データソースと似ています。ただし、統合とデータソースにはいくつかの重要な違いがあります。
- 結合は、複数のデータソースから情報を取得します。
- 統合は、作成元のレポートに常に埋め込まれます。他のレポートで統合を再利用することはできません。ただし、レポートをコピーすると、新しいレポートに統合もコピーされるため、統合データがグラフに引き続き反映されます。
- 基になるデータソースの指標は、統合では数値ディメンションとなり、集計されません。詳細については、統合のヒントと高度なコンセプトのドキュメント ページをご覧ください。
- 統合では、独自のデータの更新速度や認証情報を設定できません。この設定は基となるデータソースから継承されます。
統合の仕組み
データベースのプログラミングでは、異なるテーブルのデータを統合するために SQL の JOIN ステートメントを使用しますが、データポータルでは、コードを記述せずにデータを統合できます。代わりに統合エディタを使用するため、コードを記述することなくデータを統合することができます(以下のスクリーンショット参照)。
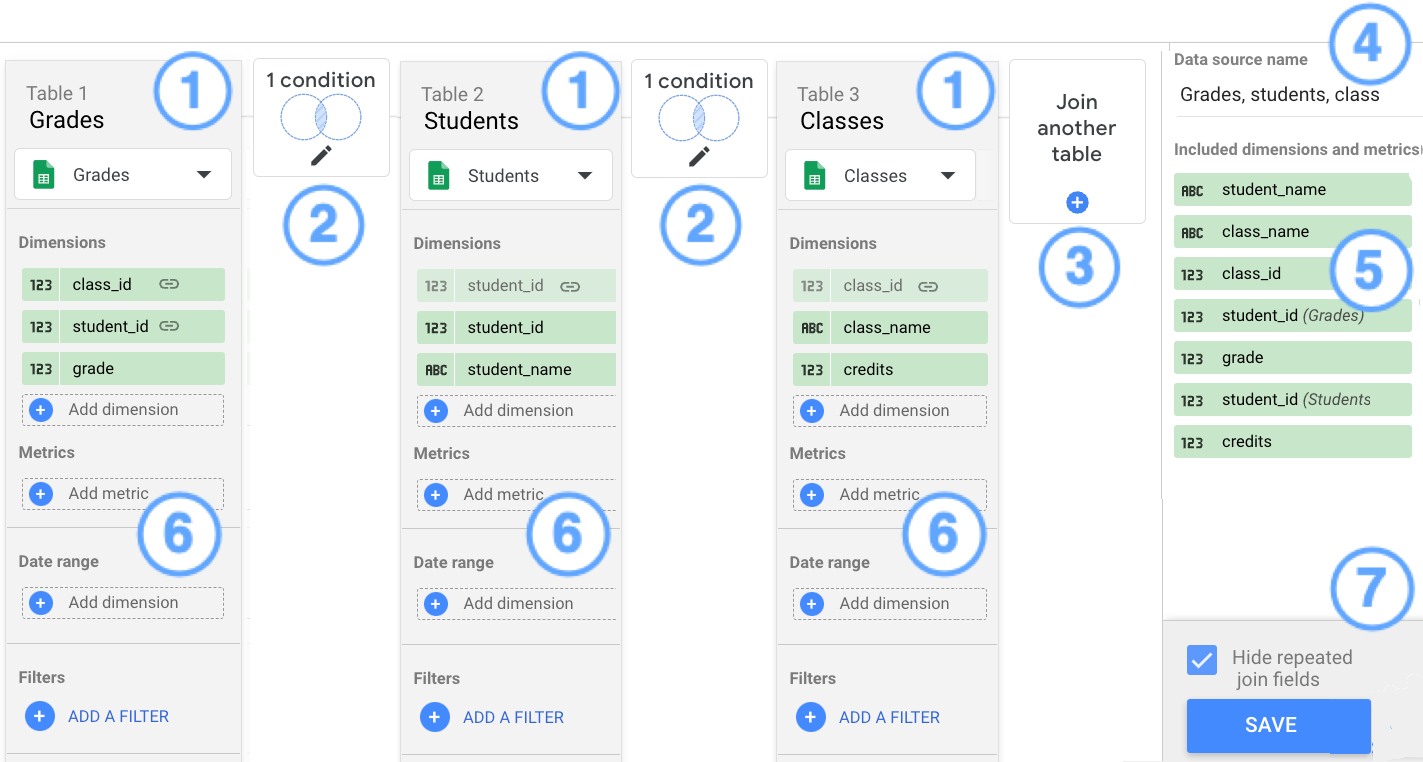
凡例:
- テーブル
- 結合の設定
- [別のテーブルを結合] ボタン
- 統合名
- 含まれているディメンションと指標
- 指標、期間、フィルタを追加する
- [繰り返し結合フィールドを非表示にする] オプションと [保存] ボタン
テーブル
統合は複数のテーブルで構成されます。統合を編集または作成すると、管理画面にテーブルが表示されます。各テーブルには、基になるデータソースから抽出された一連のフィールドが含まれています。1 つの統合に最大 5 つのテーブルを含めることができます。
テーブルを結合する前に、データポータルは各テーブルの行を、そのテーブルに含まれるディメンションに基づいてグループ化して集計します。選択したディメンションに各レコードの固有識別子が含まれていない場合、この事前グループ化の段階で同一の行が折りたたまれます。この折りたたみにより、同じデータに対して SQL 結合クエリを直接実行した場合よりも行数が少なくなることがあります。行が早すぎる段階で折りたたまれないようにするには、ブレンド内の各テーブルのディメンション リストに固有識別子フィールド(主キーや固有の行 ID など)を追加します。
テーブルにデータを追加するには、[ディメンションを追加] または [指標を追加] をクリックします。
結合条件で使用されるフィールドは、リンクアイコン ![]() 付きで表示されます。
付きで表示されます。
結合の設定
「結合の設定」で、テーブルのペアを結合して統合します。結合の設定は、演算子(テーブルのペアから一致するレコードと一致しないレコードの組み合わせ方法を定義する)と、条件(テーブルの相互関連を定義するフィールドのセット)で構成されています。
たとえば、次のスクリーンショットでは、「Grades(成績)」テーブルが「Students(学生)」テーブルの student_id フィールドと、「Classes(クラス)」テーブルの class_id フィールドに結合されています。どちらの「結合の設定」でも、左外部演算子が使用されています。
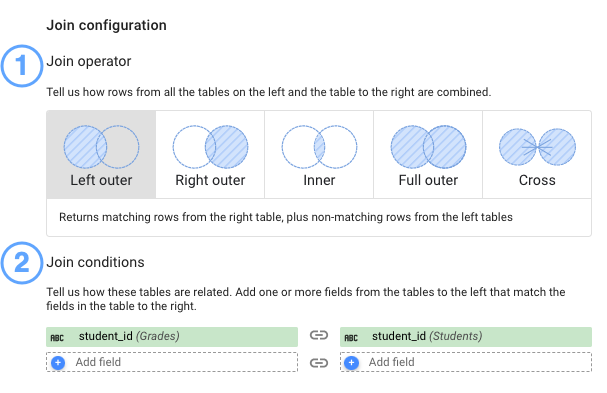
結合演算子
結合演算子は、統合内のテーブルの一致する行と一致しない行の結合方法を定義します。データポータルは、次の結合演算子をサポートしています。
- 内部結合: 左右両方のテーブルの条件が一致した行のみを返します。
- 左外部結合: 右側のテーブルの条件が一致した行と、左側のテーブルのすべての行を返します。
- 右外部結合: 左側のテーブルの条件が一致した行と、右側のテーブルのすべての行を返します。
- 完全外部結合: 左右両方のテーブルからすべての行を返します。
- クロス結合: 左右両方のテーブルから考えられるすべての行の組み合わせを返します。
結合演算子について詳しくは、BigQuery のドキュメントをご覧ください。
結合条件
「結合条件」とは、各テーブルにある 1 つ以上のフィールドのことで、テーブルのレコードを結合するために使用されます。たとえば、Google アナリティクスと Google 広告のグラフの統合で、抽出された両方のテーブルにキャンペーン名が存在する場合、データポータルはそのフィールドを使用してデータを結合できます。
統合のテーブルごとに、条件に使用するフィールドを選択します。すべてのテーブルに同じフィールドを使用する必要はありません。また、各フィールドのデータが同じであれば、フィールドの名前が同じである必要もありません。たとえば、顧客、注文、商品アイテムを 1 つのグラフで視覚化するとします。これらのテーブルには次のようなフィールドがあります。
Customers テーブル
customer_IDcustomer_name
Orders テーブル
cust_idorder_numberorder_total
Items テーブル
order_numberSKU
これらのテーブルを統合するには、customer_ID フィールドと cust_id フィールドを結合条件として使用して顧客テーブルと注文テーブルを結合します。order_number を結合条件として注文テーブルを商品アイテム テーブルと結合します。
含まれているディメンションと指標
統合の結合条件で使用されるフィールドと、統合に追加したディメンションまたは指標は、[含まれるディメンションと指標] セクションに一覧表示されます。これらのフィールドは、統合に基づくグラフで使用できます。
繰り返し結合フィールドを非表示にする
[繰り返し結合フィールドを非表示にする] オプションでは、結合条件で使用されている重複フィールドが除外されます。繰り返し結合フィールドを含めるには、このオプションをオフにします。
たとえば、結合構成で student_id フィールドと class_id フィールドを使用して、Grades、Students、Classes の 3 つのテーブルを結合するとします。[重複する結合フィールドを非表示にする] オプションが選択されている場合、ブレンドには student_id と class_id のインスタンスが 1 つだけ含まれます。
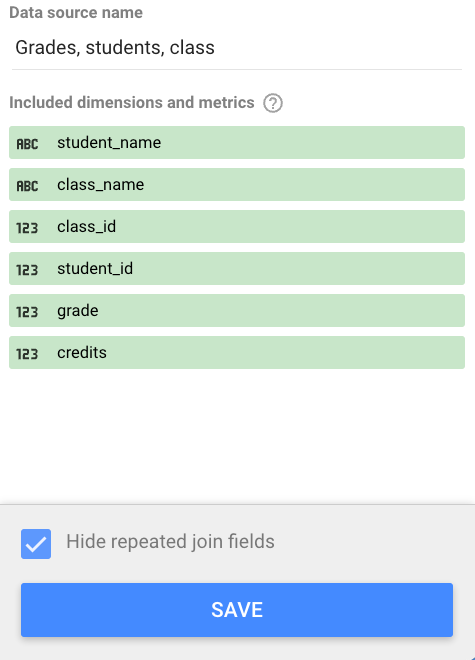
同じ統合設定で、[重複する結合フィールドを非表示にする] オプションをオフにすると、統合に student_id と class_id の複数のインスタンスと、そのフィールドが表示されるテーブルの名前(class_id(Grades)、class_id(Classes)、student_id(Grades)、student_id(Students)など)が含まれるようになります。

期間とフィルタ
1 つ以上のテーブルに期間またはフィルタを適用することで、統合するデータの範囲を制限できます。
統合の例
クラス、生徒、成績の統合の例は、データ統合の典型的なユースケースを解決する方法を示しています。