
BigQuery est l'entrepôt de données analytiques de Google. Entièrement géré, il permet de traiter plusieurs pétaoctets de données à faible coût. Le connecteur BigQuery de Data Studio vous permet d'accéder aux données de vos tables BigQuery dans Data Studio.
Avant de commencer
Pour accéder aux données BigQuery dans Data Studio, vous devez fournir un compte de facturation Google Cloud. BigQuery est un produit payant, dont les coûts d'utilisation peuvent vous être facturés lorsque vous y accédez via Data Studio. En savoir plus sur les tarifs de BigQuery
Se connecter à BigQuery
Vous pouvez connecter Data Studio à une table, une vue ou une requête personnalisée dans Google BigQuery.
Procédure de connexion
Cliquez sur Créer, puis sélectionnez Rapport.
L'éditeur de rapports s'affiche, et le panneau Ajouter des données au rapport s'ouvre.
Pour créer une source de données intégrée, sélectionnez le connecteur BigQuery.
- Pour sélectionner une source de données réutilisable existante, cliquez sur l'onglet Mes sources de données, puis sélectionnez une source de données que vous avez créée précédemment ou qui a été partagée avec vous (de n'importe quel type).
Configurez la connexion de la source de données à vos données BigQuery. Vous pouvez vous connecter à une table ou vue BigQuery ou à l'aide d'une requête SQL personnalisée.
Cliquez sur Ajouter.
Quelques instants plus tard, une table connectée à la source de données s'affiche sur la toile du rapport.
Différences entre les sources de données intégrées et réutilisables
Les sources de données peuvent être intégrées ou réutilisables. Les rapports peuvent inclure des sources de données intégrées et réutilisables.
Les sources de données que vous créez lorsque vous modifiez un rapport sont intégrées à celui-ci. Pour modifier une source de données intégrée, vous devez effectuer cette opération au sein du rapport en question. Les sources de données intégrées facilitent le travail en collaboration sur les rapports et les sources de données. Toute personne autorisée à modifier le rapport peut également modifier la source de données et sa connexion. Lorsque vous partagez ou copiez le rapport, l'opération s'applique également à toutes les sources de données intégrées.
Les sources de données que vous créez à partir de la page d'accueil sont réutilisables. Vous pouvez ainsi les réutiliser dans différents rapports. Les sources de données réutilisables vous permettent de créer et de partager un modèle de données cohérent dans votre organisation. Seules les personnes avec lesquelles vous partagez la source de données réutilisable peuvent la modifier. La connexion à la source de données ne peut être modifiée que par le propriétaire des identifiants de la source de données.
En savoir plus sur les sources de données
Vous êtes un nouvel utilisateur de Data Studio ?
Utilisez le panneau des propriétés pour modifier les données et le style du tableau. Utilisez la barre d'outils pour ajouter des graphiques, des commandes et d'autres composants à votre rapport.
Se connecter à une table ou une vue BigQuery
Une table BigQuery contient des enregistrements individuels organisés en lignes. Chaque enregistrement est composé de colonnes (également appelées champs). Une vue BigQuery est une table virtuelle définie par une requête SQL exécutée dans la console BigQuery.
Pour vous connecter à une table ou à une vue, vous devez fournir les informations suivantes :
- Un projet BigQuery
- Un ensemble de données
- Une table ou une vue
Projet
Les projets servent à organiser vos ressources BigQuery et à fournir les informations requises pour la facturation si vos rapports dépassent les quotas sans frais de BigQuery. Vous pouvez utiliser le même projet pour la facturation et la gestion des données, ou deux projets distincts. En savoir plus sur les projets Google Cloud
Choisissez l'une des options suivantes pour sélectionner votre projet :
- PROJETS RÉCENTS
- MES PROJETS
- PROJETS PARTAGÉS
Projets récents
L'option PROJETS RÉCENTS affiche les projets auxquels vous avez récemment accédé dans la console Google Cloud . Vous pouvez également saisir l'ID du projet manuellement. Le projet que vous choisissez est utilisé à la fois pour la facturation et pour l'accès aux données. Après avoir sélectionné un projet, vous sélectionnerez un ensemble de données.
Mes projets
L'option MES PROJETS vous permet de sélectionner n'importe quel projet auquel vous avez accès. Vous pouvez également saisir l'ID du projet manuellement. Le projet que vous choisissez est utilisé à la fois pour la facturation et pour l'accès aux données. Après avoir sélectionné un projet, vous sélectionnerez un ensemble de données.
Si vous avez accès à de nombreux projets, il est possible qu'ils n'apparaissent pas tous dans la liste. Lorsque le nombre maximal d'éléments autorisés dans la liste est atteint, vous pouvez ajouter le projet non listé directement en l'indiquant dans le champ de saisie.
Projets partagés
L'option PROJETS PARTAGÉS vous permet d'accéder à un projet qui a été partagé avec vous. Vous pouvez sélectionner des projets différents pour les données et la facturation.
Ensembles de données
Les ensembles de données permettent d'organiser vos données et d'en contrôler l'accès. Sélectionnez un ensemble de données dans la liste ou recherchez-en un en saisissant son nom.
Ensembles de données publics
Les ensembles de données publics BigQuery sont des échantillons publics où l'ensemble de données est partagé, sans que le projet ne le soit. Pour interroger ces données, vous devez spécifier votre propre projet de facturation : il sera utilisé pour facturer les coûts de traitement appliqués aux données partagées.
Table
Vous pouvez associer une source de données Data Studio à une seule table ou vue.
Se connecter à une table partitionnée par date
Data Studio peut utiliser les tables BigQuery partitionnées par date. Lorsque vous vous connectez à une table partitionnée sur un champ DATE, DATETIME ou TIMESTAMP, Data Studio peut utiliser ce champ comme dimension associée à la plage de dates pour les graphiques basés sur cette source de données.
En savoir plus sur l'association de Data Studio à des tables BigQuery partitionnées par date
Se connecter à BigQuery à l'aide d'une requête SQL personnalisée
L'option REQUÊTE PERSONNALISÉE vous permet de vous connecter à vos données en écrivant du code SQL. La syntaxe de requête personnalisée respecte le dialecte SQL standard. Pour utiliser l'ancien dialecte SQL de BigQuery, sélectionnez l'option Utiliser l'ancien SQL.
Utilisez l'interface utilisateur BigQuery pour rédiger et tester votre requête, puis copiez-la et collez-la dans le champ de requête personnalisée de Data Studio.
Projet de facturation
L'option Projet de facturation vous permet de fournir un projet de facturation pour votre requête personnalisée en recherchant l'ID du projet ou en le saisissant manuellement. Si votre organisation dispose de nombreux projets BigQuery, vous devrez peut-être utiliser la méthode de saisie manuelle pour localiser le projet.
Pour utiliser un projet pour la facturation et un autre pour vos données, sélectionnez ou saisissez le projet de facturation dans l'interface utilisateur, puis incluez le projet de données dans la clause SELECT...FROM de la requête personnalisée.
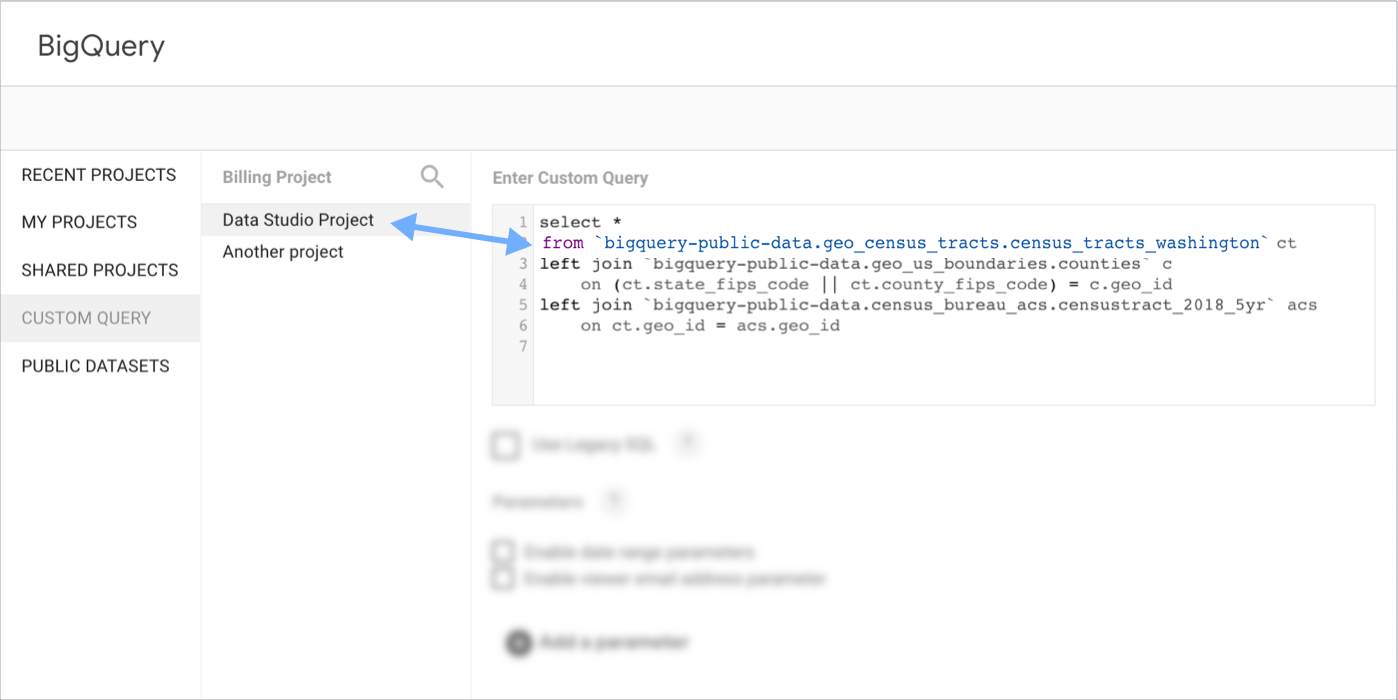
Paramètres de requête
Les paramètres vous permettent de créer des rapports plus réactifs et personnalisables. Vous pouvez transmettre les paramètres d'une source de données BigQuery à la requête sous-jacente. Pour utiliser un paramètre dans votre requête personnalisée, suivez les consignes de syntaxe pour exécuter des requêtes paramétrées dans BigQuery.
Découvrez comment utiliser des paramètres dans les requêtes personnalisées.
Limites des requêtes personnalisées
Data Studio utilise votre SQL personnalisé comme instruction SELECT interne pour chaque requête générée vers la base de données. En fait, votre requête personnalisée génère une nouvelle table virtuelle, que Data Studio interroge ensuite avec son propre code SQL "externe" généré. Par conséquent, les requêtes personnalisées dans Data Studio sont soumises aux restrictions suivantes :
Les requêtes SQL personnalisées ne peuvent avoir qu'une seule instruction
Par exemple, la requête suivante ne fonctionnera pas, car elle comporte plusieurs instructions SQL :
DECLARE cost_per_tb_in_dollar FLOAT64 DEFAULT 4.2;
SELECT total_bytes_billed / (1024 * 1024)* cost_per_tb_in_dollar)/(1024*1024))) FROM billing-table;
Utiliser des noms de champ non ambigus dans les jointures
Les requêtes de jointure personnalisées ne peuvent pas gérer les noms de colonnes en double. Les graphiques qui utilisent une source de données basée sur une requête personnalisée incluant des champs en double retournent une erreur de configuration de l'utilisateur semblable à celle-ci :
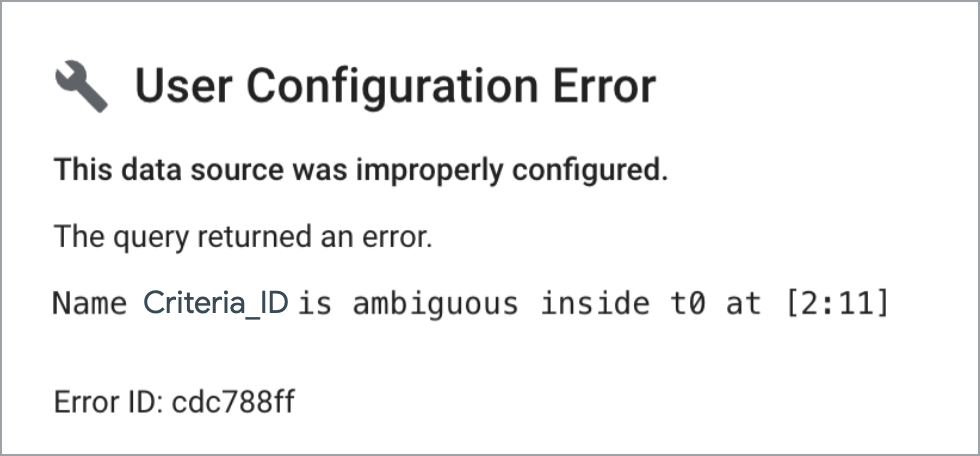
Pour éviter ce problème, veillez à utiliser des noms de champ non ambigus dans vos requêtes personnalisées.
Par exemple, supposons que vous souhaitiez joindre deux tables avec des schémas identiques, en les joignant au niveau du champ Criteria_ID présent dans les deux tables.
SELECT * FROM (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_1'
) As table_1
LEFT JOIN (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_2'
) As table_2
ON
table_1.Criteria_ID = table_2.Criteria_ID
Cette requête inclut les noms de colonnes en double suivants :
Criteria_IDParent_IDName
Pour éviter l'erreur Field is ambiguous, vous pouvez renommer explicitement les champs en double à l'aide du mot clé AS :
SELECT *
FROM (
SELECT
Criteria_ID AS Criteria_ID_1,
Parent_ID AS Parent_ID_1,
Name AS NAME_1
FROM
'table_1' ) AS table_1
LEFT JOIN (
SELECT
Criteria_ID AS Criteria_ID_2,
Parent_ID AS Parent_ID_2,
Name AS NAME_2
FROM
'table_2' ) AS table_2
ON
table_1.Criteria_ID_1 = table_2.Criteria_ID_2;
Si vous ne devez renommer que quelques champs, vous pouvez tout sélectionner, sauf ceux que vous souhaitez renommer, par exemple :
SELECT * EXCEPT (city), city AS city_1 FROM 'table_1'
Délai avant expiration de la requête
Les requêtes personnalisées dans Data Studio peuvent expirer au bout de trois à cinq minutes. Si vos requêtes personnalisées expirent, essayez les approches suivantes pour résoudre le problème :
- Simplifiez la requête pour qu'elle s'exécute plus rapidement.
- Exécutez la requête dans votre base de données et stockez les résultats dans une table distincte. Connectez-vous ensuite à cette table dans votre source de données.
Tables sur plusieurs jours
BigQuery accepte les requêtes appliquées à plusieurs tables, où chaque table contient les données d'une seule journée. Le format utilisé est le suivant : YYYYMMDD. Lorsque Data Studio trouve une table au format YYYYMMDD, elle est marquée comme une table sur plusieurs jours, et seul le nom préfixe_AAAAMMJJ sera affiché dans la sélection de la table.
Lorsque vous créez un graphique pour visualiser cette table, Data Studio crée automatiquement une plage de dates par défaut correspondant aux 28 derniers jours et interroge de manière appropriée les 28 dernières tables. Pour configurer ce paramètre, modifiez le rapport, sélectionnez le graphique, puis ajustez les propriétés de la plage de dates dans l'onglet DONNÉES du graphique.
Afficher le code SQL envoyé à BigQuery
Vous pouvez afficher l'ensemble du code SQL BigQuery généré par Data Studio depuis l'interface utilisateur de l'historique des requêtes BigQuery.
Métrique "Nombre d'enregistrements"
Les sources de données BigQuery fournissent automatiquement une métrique Nombre d'enregistrements par défaut. Elle vous permet de répartir vos dimensions afin d'afficher le nombre d'enregistrements agrégé dans vos graphiques.
Prise en charge de VPC Service Controls
Data Studio peut être connecté à des projets BigQuery protégés par des périmètres VPC Service Controls (VPC-SC) avec des niveaux d'accès basés sur l'adresse IP du lecteur. Le connecteur BigQuery transmet l'adresse IP du lecteur du rapport à BigQuery, qui peut ensuite appliquer tous les niveaux d'accès basés sur l'adresse IP configurés.
Visualiser des polygones GEOGRAPHY BigQuery
Vous pouvez afficher des polygones GEOGRAPHY dans votre rapport à l'aide d'une visualisation Google Maps. Pour accéder à un tutoriel, consultez Visualiser des polygones GEOGRAPHY BigQuery avec Data Studio.
Analyser les requêtes Data Studio avec des libellés de job
Toutes les requêtes envoyées par Data Studio à BigQuery sont associées au libellé de job BigQuery requestor:looker_studio. Vous pouvez utiliser cette étiquette de job pour identifier les requêtes BigQuery associées à Data Studio. Pour en savoir plus sur les libellés dans BigQuery, consultez la page de documentation BigQuery Afficher les libellés.
Si vous êtes le propriétaire de la source de données BigQuery, vous pouvez également afficher les détails du job en cliquant sur l'icône Fourni par BigQuery.
Pour en savoir plus sur le suivi des performances et des coûts des graphiques et rapports Data Studio, consultez la page de documentation BigQuery Analyser les données avec Data Studio.
Boîte de dialogue BigQuery
Si vous disposez d'identifiants de propriétaire pour la source de données BigQuery, Data Studio affichera une icône BigQuery en haut à droite de chaque graphique utilisant BigQuery. Pointez sur le graphique, puis cliquez sur l'icône BigQuery pour ouvrir la boîte de dialogue BigQuery. Elle affiche un lien vers la page d'informations sur le job BigQuery. La page d'informations du job BigQuery inclut les informations suivantes :
- Requête SQL pour le graphique
- Données renvoyées par la requête SQL
- Répartition des étapes de la requête par phase
- Statistiques sur les requêtes, telles que la durée d'exécution totale et les emplacements utilisés
Améliorer les performances avec l'API BigQuery Storage Read
Pour les requêtes qui utilisent des résultats paginés, l'activation de l'API BigQuery Storage Read peut améliorer les temps de requête. Data Studio utilise automatiquement l'API Storage Read lorsque cela permet d'améliorer les temps d'exécution des requêtes.
Pour activer l'API BigQuery Storage Read, accordez les autorisations suivantes à votre utilisateur BigQuery connecté à Data Studio :
bigquery.readsessions.createbigquery.readsessions.getData
Quotas et limites générales
En général, les sources de données BigQuery sont soumises aux mêmes quotas et limites de débit que BigQuery lui-même.
Nombre maximal de lignes
Le nombre maximal de lignes qui peuvent s'afficher à l'aide du connecteur BigQuery est de deux millions. Lorsqu'il y a plus de deux millions de lignes de données, Data Studio l'indique, mais ne précise pas le nombre de lignes.
Nombre maximal de tables
Pour les connexions BigQuery, le connecteur Data Studio limite le nombre de tables par ensemble de données à 5 000. Si cette limite est dépassée, l'UI peut cesser de répondre lorsque Data Studio charge la liste des tables pour l'ensemble de données.
Si vous atteignez cette limite, vous pouvez utiliser l'une des solutions de contournement suivantes :
- Utiliser une requête personnalisée : connectez-vous à BigQuery à l'aide d'une requête SQL personnalisée au lieu de vous connecter à une table. Par exemple :
SELECT * FROM project.dataset.table. - Se connecter depuis BigQuery : dans la console BigQuery, utilisez les options Exporter ou Explorer les données, puis sélectionnez Ouvrir avec Looker Studio.
- Gérer les ensembles de données : réorganisez les tables en ensembles de données plus petits contenant moins de 5 000 tables, ou créez un ensemble de données de reporting dédié contenant uniquement les tables ou vues nécessaires.
Fonctions MEDIAN et PERCENTILE
Pour les sources de données BigQuery, MEDIAN et PERCENTILE sont implémentés à l'aide de la fonction BigQuery APPROX_QUANTILES. L'application de MEDIAN ou PERCENTILE aux données provenant de BigQuery peut renvoyer des résultats légèrement différents de ceux obtenus en appliquant MEDIAN ou PERCENTILE aux mêmes données provenant d'autres types de sources de données.
Clés de chiffrement gérées par le client (CMEK)
Le connecteur BigQuery n'est pas compatible avec les clés de chiffrement gérées par le client (CMEK). Si votre projet Google Cloud est soumis à une règle d'organisation qui nécessite une clé CMEK, Data Studio ne peut pas interroger les données et renvoie une erreur CONDITION_NOT_MET.
Type de données TIME
Data Studio n'est pas compatible avec le type de données TIME BigQuery. Tous les champs TIME de votre ensemble de données sont convertis en champs TEXT dans Data Studio. Pour visualiser les données temporelles dans vos rapports, vous pouvez utiliser l'une des solutions de contournement suivantes pour convertir les données TIME en type de données DATETIME :
Solution de contournement 1 : Utiliser une requête personnalisée
Utilisez une requête personnalisée BigQuery comme source de données dans Data Studio. Combinez le champ TIME avec une date "fictive" pour créer une valeur DATETIME compatible avec Data Studio.
Requête SQL personnalisée
SELECT
*,
-- Combine a dummy date (1970-01-01) with your TIME field
DATETIME(DATE "1970-01-01", your_time_field) AS time_as_datetime
FROM
`your_project.your_dataset.your_table`
- Résultat : Data Studio traite
time_as_datetimecomme un type de données Date et heure. - Personnalisation : pour masquer la date fictive et n'afficher que la partie "heure", modifiez le Format d'affichage du champ time_as_datetime dans votre rapport, puis sélectionnez un format tel que Heure ou Minute, ou indiquez un format personnalisé tel que h:mm:ss. En savoir plus sur les formats d'affichage des champs
Solution de contournement 2 : Utiliser un champ calculé
Si vous ne souhaitez pas modifier votre requête SQL, vous pouvez gérer la conversion directement dans Data Studio à l'aide d'un champ calculé. Cet exemple suppose que le champ TIME BigQuery contient des données au format "heure:minute:seconde" (par exemple, 23:59:59).
Formule de champ calculé
PARSE_DATETIME("%H:%M:%S", CAST(your_time_field AS TEXT))
- Résultat : la fonction
PARSE_DATETIMEconvertit la chaîne en objet Date et heure. La fonctionCASTgarantit queyour_time_fieldest traité commeTEXT. Comme aucune date n'est spécifiée dans la chaîne, Data Studio définit automatiquement la partie de la date sur 1er janvier 1970 par défaut. En savoir plus sur la fonction PARSEDATE - Personnalisation : comme dans la solution de contournement pour les requêtes personnalisées, vous pouvez ensuite modifier le format d'affichage du champ dans l'onglet Configurer du graphique pour vous assurer que seules les informations temporelles pertinentes apparaissent dans vos graphiques.