
Cloud Data Fusion 資料沿襲
您可以使用 Cloud Data Fusion 資料歷程功能執行下列操作:
找出不良資料事件的根本原因。
在變更資料前執行影響分析。
建議在知識目錄中整合資產沿襲。詳情請參閱「在 Knowledge Catalog 中查看歷程」。
您也可以在 Cloud Data Fusion Studio 中,使用「中繼資料」選項,查看資料集和欄位層級的資料歷程,並顯示所選時間範圍的資料歷程。
資料集層級歷程會顯示資料集與管道之間的關係。
欄位層級歷程會顯示對來源資料集中的一組欄位執行的作業,以便在目標資料集中產生對應欄位。
從 Cloud Data Fusion 6.9.2.4 以上版本開始,如果您未在 Cloud Data Fusion 中追蹤歷程,建議使用 patch 方法,在執行個體中關閉欄位層級歷程記錄發布功能:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
更改下列內容:
PROJECT_ID: Google Cloud 專案 IDREGION: Google Cloud 專案的位置INSTANCE_ID:Cloud Data Fusion 執行個體 ID
教學課程情境
在本教學課程中,您會使用兩個管道:
Shipment Data Cleansing管道會從小型範例資料集讀取原始運送資料,並套用轉換來清理資料。Delayed Shipments USA管道接著會讀取清理後的運送資料並進行分析,找出美國境內延遲超過門檻的運送案件。
這些教學課程管道示範了原始資料經過清理後,傳送至下游處理的典型案例。透過 Cloud Data Fusion 歷程功能,您可完整掌握資料的來龍去脈,包含原始資料、清理後的運送資料及分析輸出內容。
目標
- 執行範例管道來產生歷程資料
- 探索資料集和欄位層級歷程
- 將握手資訊從上游管道傳遞至下游管道
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
啟用 Cloud Data Fusion、Cloud Storage、Dataproc 和 BigQuery API。
啟用 API 時所需的角色
如要啟用 API,您需要服務使用情形管理員 IAM 角色 (
roles/serviceusage.serviceUsageAdmin),其中包含serviceusage.services.enable權限。瞭解如何授予角色。- 建立 Cloud Data Fusion 執行個體。
- 點選下列連結,將這些小型範例資料集下載到本機:
開啟 Cloud Data Fusion UI
使用 Cloud Data Fusion 時,需要同時操作 Google Cloud 控制台 和獨立的 Cloud Data Fusion UI。在 Google Cloud 控制台中,您可以建立 Google Cloud 控制台專案,以及建立和刪除 Cloud Data Fusion 執行個體;在 Cloud Data Fusion UI 中,您可以透過「沿革」等頁面,存取 Cloud Data Fusion 功能。
在 Google Cloud 控制台中,開啟「Instances」(執行個體) 頁面。
在執行個體所屬的「動作」欄中,按一下「查看執行個體」連結。Cloud Data Fusion 使用者介面會在新的瀏覽器分頁中開啟。
在「整合」窗格中,按一下「Studio」,開啟 Cloud Data Fusion「Studio」頁面。
部署及執行管道
匯入原始運送資料。在「Studio」頁面中,按一下「Import」,或依序點選「+」>「Pipeline」>「Import」,然後選取並匯入「開始前」下載的「Shipment Data Cleansing」管道。
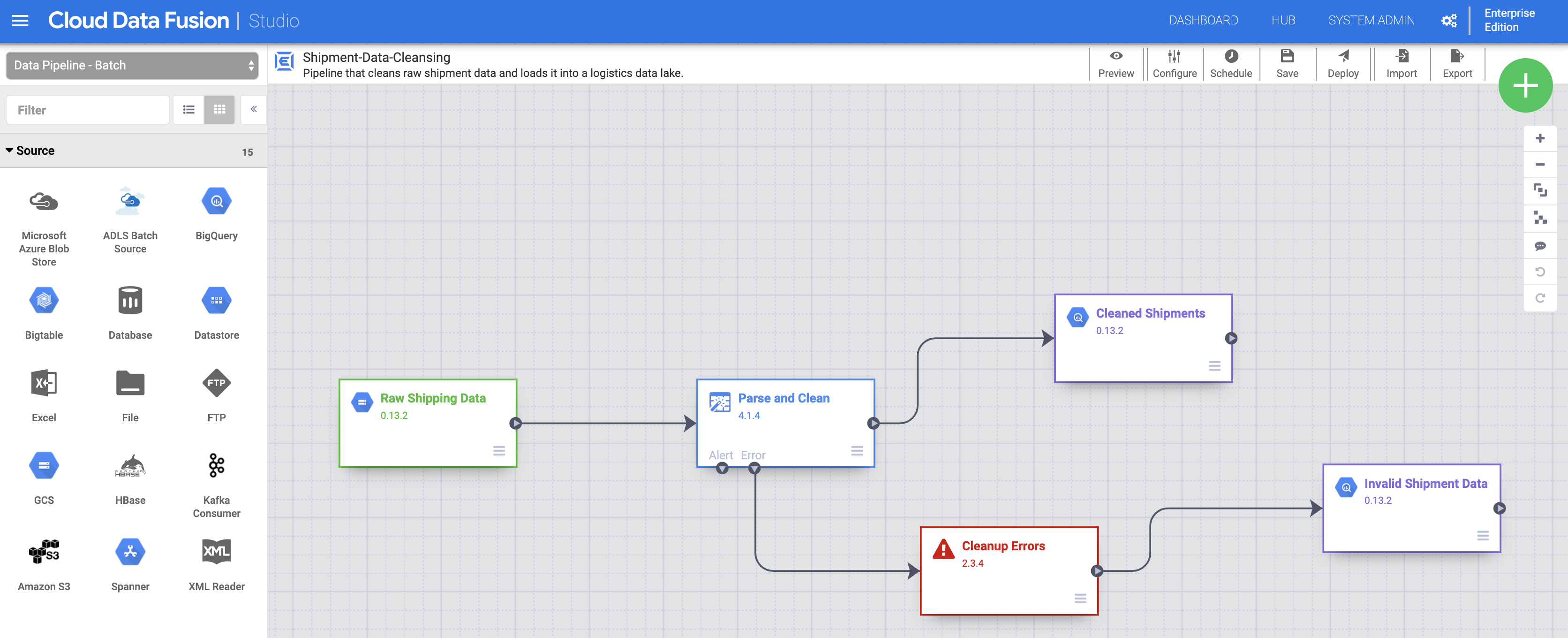
部署管道。點選「Studio」頁面右上方的「Deploy」。部署完成後即會開啟「Pipeline」頁面。
執行管道。點選「Pipeline」頁面頂端中央的「Run」。
匯入、部署及執行「Delayed Shipments」資料和管道。 「Shipping Data Cleansing」的狀態顯示「Succeeded」後,請按照上述步驟,處理在「事前準備」中下載的「Delayed Shipments USA」資料。返回「Studio」頁面匯入資料,然後從「Pipeline」頁面部署及執行第二個管道。第二個管道成功完成後,請繼續執行剩餘步驟。
探索資料集
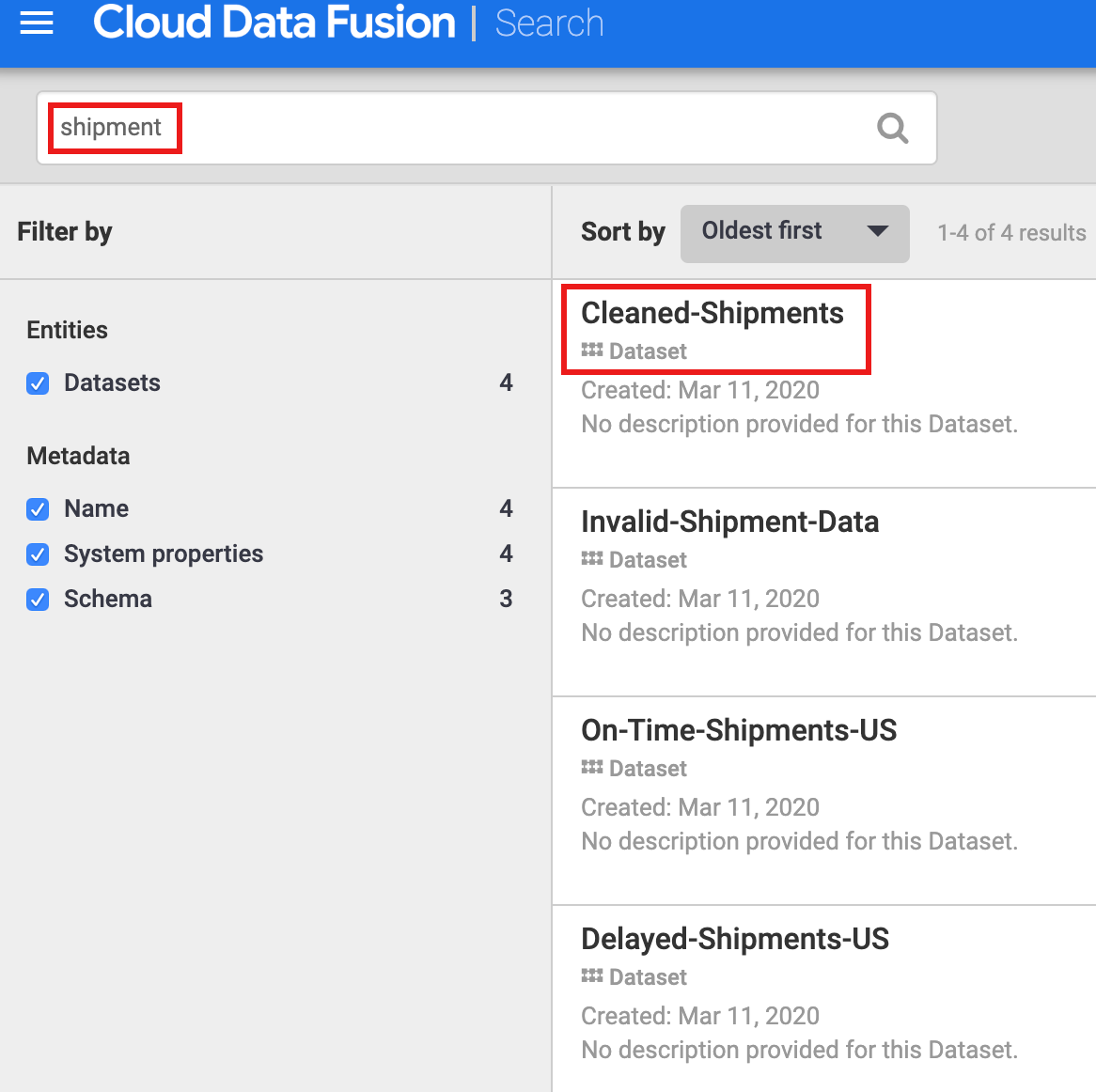
您必須先發掘資料集,才能探索其歷程。在 Cloud Data Fusion UI 的左側導覽面板選取「Metadata」,開啟中繼資料「Search」頁面。由於「Shipment Data Cleansing」資料集將「Cleaned-Shipments」指定為參考資料集,請在搜尋框中插入「shipment」。搜尋結果會包含這個資料集。
使用標記發掘資料集
透過中繼資料搜尋,您可發掘「Cloud Data Fusion」管道使用、處理或產生的資料集。管道是在結構化架構上執行,這個架構會自動產生及收集技術與作業中繼資料。技術中繼資料包括資料集名稱、類型、結構定義、欄位、建立時間和處理資訊。Cloud Data Fusion 中繼資料搜尋和歷程功能會運用這些技術資訊。
Cloud Data Fusion 也支援使用標記和鍵/值屬性等業務中繼資料 (可做為搜尋條件使用),為資料集加上註解。舉例來說,如要為「Raw Shipping Data」資料集新增及搜尋業務標記註解,請按照下列步驟操作:
在「Shipment Data Cleansing」管道頁面,點選「Raw Shipping Data」節點的「Properties」按鈕,開啟「Cloud Storage Properties」頁面。
按一下「查看中繼資料」,開啟「搜尋」頁面。
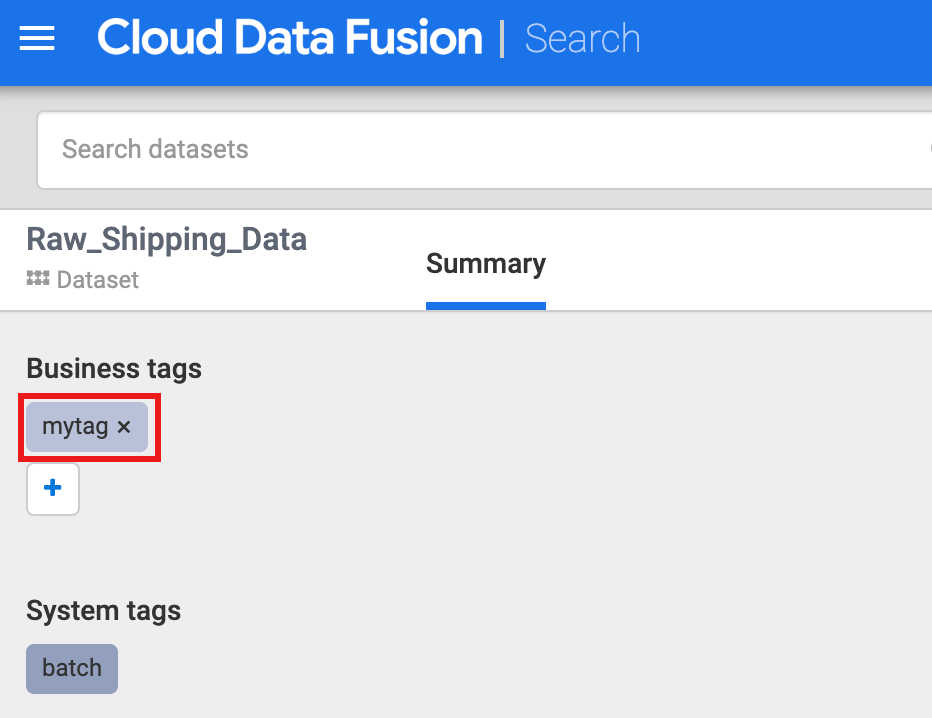
在「商家標記」下方點選「+」,然後插入標記名稱 (可使用英數字元和底線),並按下 Enter 鍵。
查看歷程
資料集層級歷程
在「Search」頁面點選「Cleaned-Shipments」資料集名稱 (來自「Discover datasets」),然後按一下「Lineage」分頁標籤。歷程圖顯示,這個資料集是由「Shipments-Data-Cleansing」管道產生,而該管道使用了「Raw_Shipping_Data」資料集。
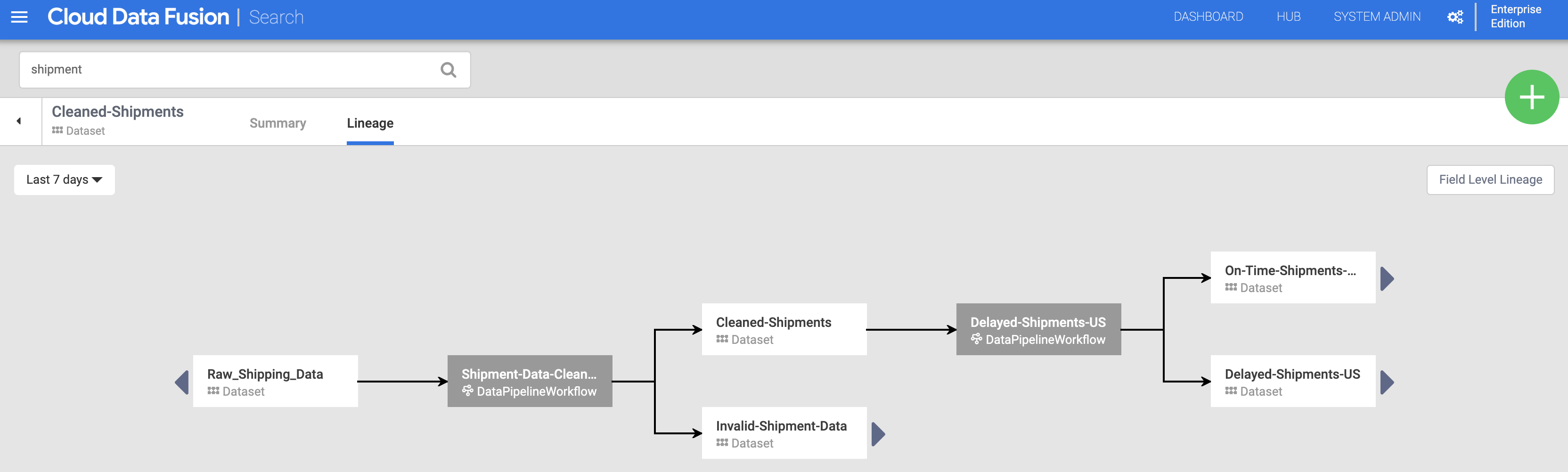
使用左右箭頭,即可在任何先前或後續的資料集沿襲中來回瀏覽。在本例中,圖表會顯示 Cleaned-Shipments 資料集的完整歷程。
欄位層級歷程
Cloud Data Fusion 欄位層級歷程會呈現資料集欄位之間的關係,以及對一組欄位執行轉換而產生對應欄位的過程。如同資料集層級歷程,欄位層級歷程會隨時間變動,結果也因時間而異。
接續資料集層級歷程步驟,點選「Cleaned Shipments」資料集層級歷程圖右上方的「Field Level Lineage」按鈕,即可顯示欄位層級歷程圖。
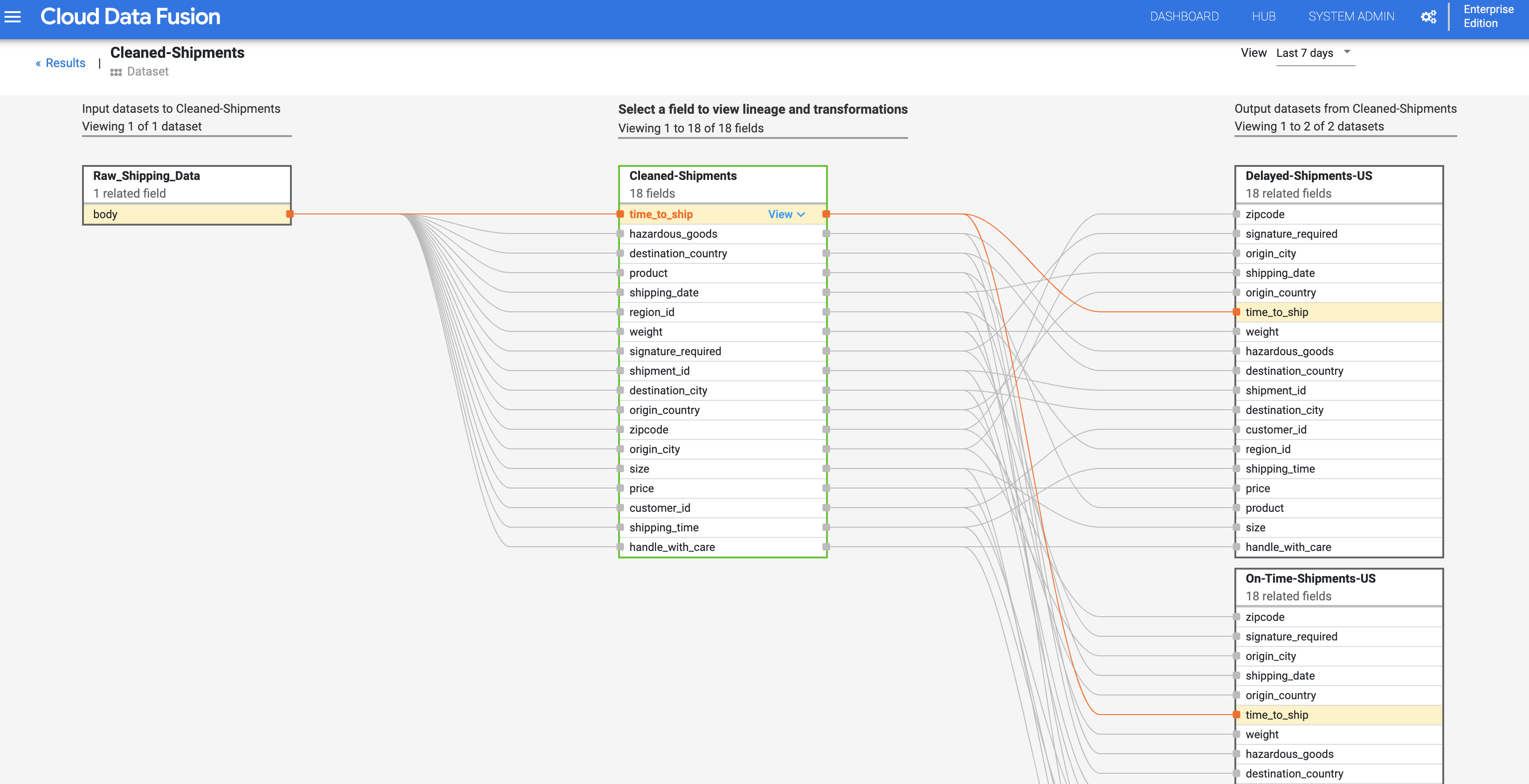
欄位層級歷程圖會呈現欄位之間的關聯,選取欄位即可查看歷程。依序選取「View」和「Pin field」,查看該欄位的歷程。
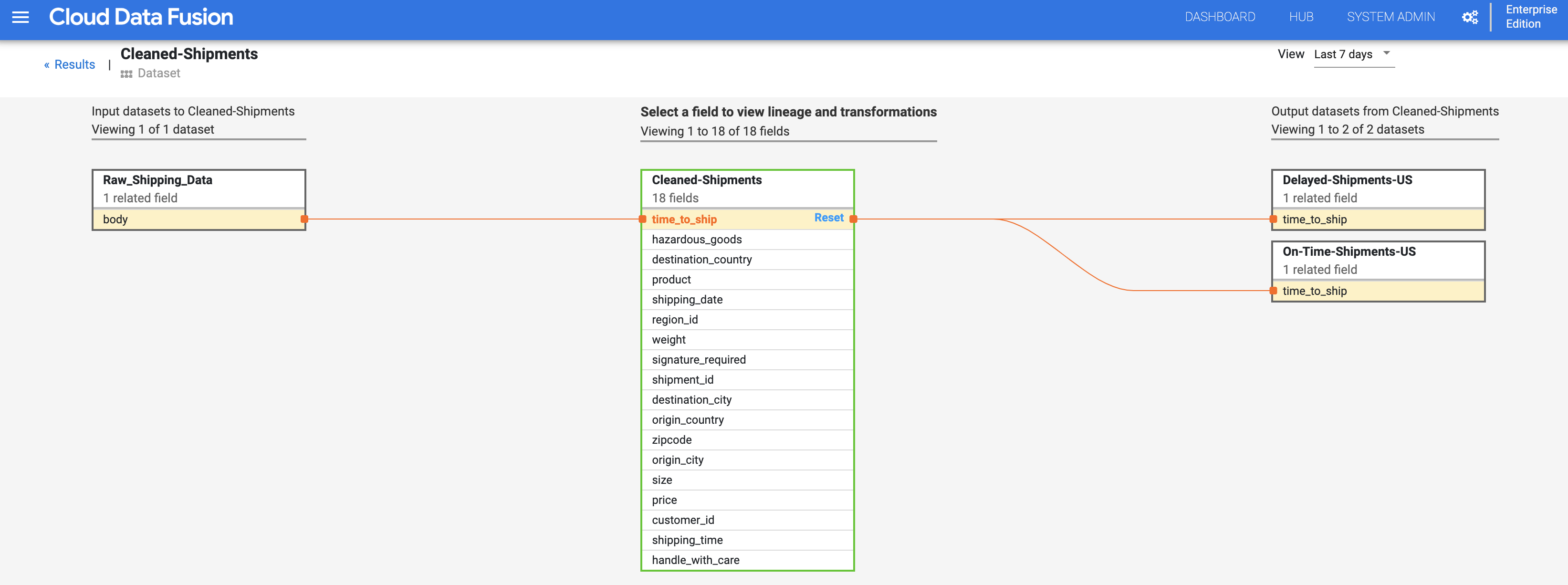
依序選取「查看」>「查看影響」,執行影響分析。
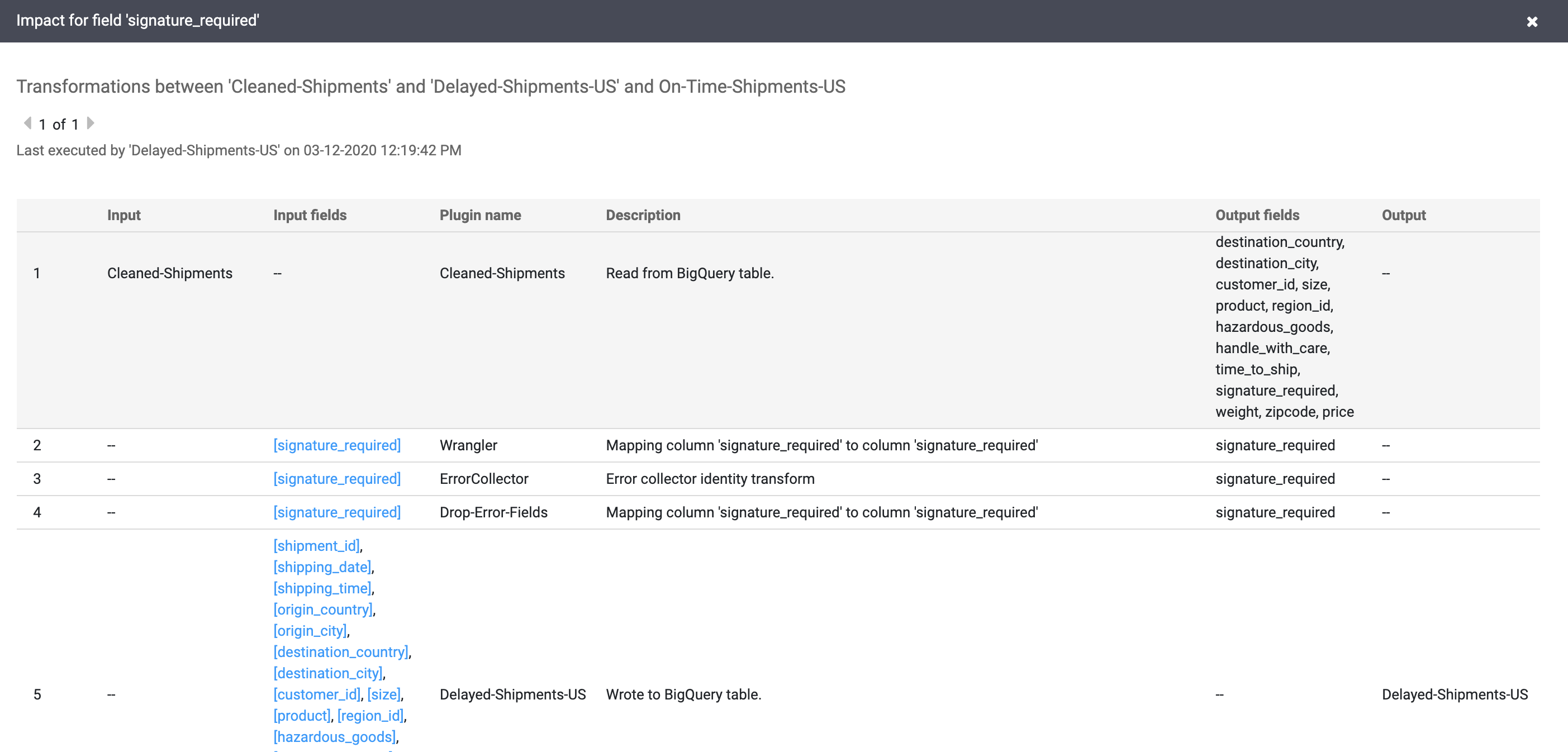
原因和影響連結會以人類可讀的分類帳格式,呈現欄位上下游執行的轉換作業。這些資訊對報表和治理作業至關重要。
清除所用資源
為避免因為本教學課程所用資源,導致系統向 Google Cloud 帳戶收取費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
完成本教學課程後,請清理您在Google Cloud 上建立的資源,這樣這些資源就不會占用配額,您日後也無須為其付費。下列各節將說明如何刪除或關閉這些資源。
刪除教學課程資料集
本教學課程會在專案中建立含有數個資料表的 logistics_demo 資料集。
您可以從 BigQuery 網頁版 UI 刪除 Google Cloud 控制台中的資料集。
刪除 Cloud Data Fusion 執行個體
請按照說明刪除 Cloud Data Fusion 執行個體。
刪除專案
如要避免付費,最簡單的方法就是刪除您為了本教學課程所建立的專案。
刪除專案的方法如下:
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。