
本文档介绍了 Compute Engine 实例意外关停和重新启动的常见原因,以及如何阻止这些情况。
实例关停和重新启动可能是由系统事件或管理活动引起的。系统事件关停和重新启动由 Google 系统或实例的操作系统生成。管理员活动关停和重新启动由用户或服务账号生成的 API 调用生成。系统会记录所有关停和重新启动,但从实例内发起的重新启动除外。
准备工作
-
如果您尚未设置身份验证,请进行设置。身份验证用于验证您的身份,以便访问 Google Cloud 服务和 API。如需从本地开发环境运行代码或示例,您可以通过选择以下选项之一向 Compute Engine 进行身份验证:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
安装 Google Cloud CLI。 安装完成后,运行以下命令来初始化 Google Cloud CLI:
gcloud init如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
- Set a default region and zone.
诊断实例关停和重启
如需诊断实例自发关停或重新启动的原因,您必须查询实例的日志。如需快速确定未来虚拟机关停或重新启动的原因,请构建包含日志的信息中心。查询日志后,请查看
method和principalEmail字段,以确定是哪个事件以及哪个用户或服务启动了关停或重新启动。查询 Cloud Audit Logs
查询 Cloud Audit Logs,以显示可能导致关停或重新启动的系统事件和管理活动列表。
控制台
在 Google Cloud 控制台中,前往 Logs Explorer 页面。
在查询字段中,输入以下查询:
resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")将
VM_NAME替换为关停或重新启动的虚拟机的名称。如果您查找的事件是在一小时之前发生的,请点击时钟符号并输入自定义范围来设置自定义时间范围。
点击运行查询。结果会显示在查询结果部分中。
点击每个结果旁边的展开箭头 以显示详细信息。
请参阅查看 Cloud Audit Logs,详细了解与关停和重启关联的
method和principalEmail字段,以及您可以采取哪些措施来阻止它们。
gcloud
使用
gcloud logging read命令查看 Cloud Audit Logs:gcloud logging read --freshness=TIME 'resource.type="gce_instance" "VM_NAME" logName:("logs/cloudaudit.googleapis.com%2Fsystem_event" OR "logs/cloudaudit.googleapis.com%2Factivity")'替换以下内容:
TIME:您要查询的时间。例如,1h会查询过去一小时内的日志条目。如需了解日期和时间格式,请参阅 gcloud topic datetimes。VM_NAME:关停或重新启动的虚拟机的名称。
结果显示。
请参阅查看 Cloud Audit Logs,详细了解与关停和重启关联的
method和principalEmail字段,以及您可以采取哪些措施来阻止它们。
查看 Cloud Audit Logs
查看 Cloud Audit Logs 的
method和principalEmail字段,以确定虚拟机关停或重新启动的原因。查看 Cloud Audit Logs 的
method字段,并将其与下表中列出的方法进行比较。方法 关停类型 说明 compute.instances.repair.recreateInstance系统事件 如果您的虚拟机属于托管式实例组 (MIG),则 MIG 会重新创建虚拟机(如果虚拟机的状态从
RUNNING更改),并且 MIG 不会发起状态更改。不是由 MIG 发起的实例状态更改包括:
compute.instances.hostError系统事件 主机错误 (
compute.instances.hostError) 意味着托管计算实例的物理机或数据中心基础设施存在硬件或软件问题,导致实例崩溃。如果主机错误涉及彻底的硬件故障或其他硬件问题,可能会阻止实例实时迁移。如果您的实例设置为自动重启(这是默认设置),Compute Engine 会在检测到错误后的 3 分钟内重启您的实例。重启可能最多需要 5.5 分钟,具体取决于问题。有时,计算实例可能会在主机错误信号发出之前无响应。您可以通过设置主机错误恢复超时时长,缩短 Compute Engine 等待重启或终止实例的时间。如需了解详情,请参阅设置可用性政策。
物理硬件故障和软件故障可能会不时发生,但这种情况很少见。为了保护您的应用和服务免受这些可能具有中断性的系统事件的影响,请查看以下资源:
Google 还提供 App Engine 等代管式服务以及 App Engine 柔性环境。
compute.instances.automaticRestart系统事件 如果虚拟机的
automaticRestart主机维护政策设置为true,则此事件会在发生hostError事件或terminateOnHostMaintenance事件后发生。在日志中,hostError或terminateOnHostMaintenance日志条目位于此日志之前。如果要更改虚拟机的主机维护政策,请参阅更新实例对应的选项。
compute.instances.guestTerminate系统事件 虚拟机的操作系统发起关停。 compute.instances.terminateOnHostMaintenance系统事件 如果您将虚拟机的
onHostMaintenance主机维护政策设置为TERMINATE,则在发生维护事件时,如果 Google 必须将虚拟机实例迁移到另一台主机上,那么 Compute Engine 会停止虚拟机。如果您想要更改虚拟机的
onHostMaintenance政策,请参阅更新实例对应的选项。compute.instances.preempted系统事件 Compute Engine 抢占了您的 Spot 虚拟机或旧版抢占式虚拟机:
- 当 Compute Engine 抢占 Spot 虚拟机时,Compute Engine 会根据 终止操作停止或删除 Spot 虚拟机。Spot 虚拟机没有最长运行时。
- 当 Compute Engine 抢占抢占式虚拟机时,Compute Engine 会在最长 24 小时的运行时间后停止虚拟机。为了避免这些限制,请改用 Spot 虚拟机。
Spot 虚拟机和抢占式虚拟机是过剩的 Compute Engine 容量,因此 Compute Engine 可能在任何其他位置需要该容量时抢占它们。您可以按照最佳做法来帮助缓解抢占的影响。或者,如果您需要具有用户控制运行时的虚拟机,请改为创建标准虚拟机。
compute.instances.stop管理员活动 用户或服务账号停止虚拟机。
继续下一步,以确定停止虚拟机的用户或服务账号。如需了解如何重启虚拟机,请参阅重启已停止的实例。
compute.instances.delete管理员活动或系统事件 用户或服务账号删除了您的虚拟机,或者虚拟机已配置为自动删除。
具体而言,
compute.instances.delete方法的日志可能会指示您的虚拟机的以下任一请求:- 用户或服务账号直接删除虚拟机的请求仅由用户或服务账号的
compute.instances.delete方法指示。 自动删除虚拟机的请求由
system@google.com中的compute.instances.delete方法表示,但说明自动删除原因的方法可能会出现在 Cloud Audit Logs中,也可能不会。例如,如果 Spot 虚拟机已配置为在抢占期间自动删除,并且被抢占,您会看到来自
system@google.com的compute.instances.delete方法,但也可能会或不会看到compute.instances.preempted方法。在
compute.instances.delete方法之前或之后发生的对虚拟机的请求可能会或可能不会显示在 Cloud Audit Logs 中。例如,如果虚拟机在删除前不久因主机维护而停止,您会看到
compute.instances.delete方法,但也可能会或不会看到compute.instances.terminateOnHostMaintenance方法。
继续下一步,以确定删除虚拟机的用户或服务账号。如需了解如何创建新虚拟机,请参阅创建和启动虚拟机。
compute.instances.insert管理员活动 创建虚拟机的用户或服务账号。
继续下一步,以确定创建虚拟机的用户或服务账号。如需了解如何创建新虚拟机,请参阅创建和启动虚拟机。
compute.instances.reset管理员活动 用户或服务账号重置虚拟机。
继续下一步,以确定停止虚拟机的用户或服务账号。
查看 Cloud Audit Logs 的
principalEmail字段,以确定发起关停或重新启动的用户或服务。下表包含发起关停或重新启动的常见 Google 代管式服务。邮箱 说明 system@google.com系统事件导致关停或重新启动。 project-number@cloudservices.gserviceaccount.com服务代理发起了关停。
如需确定服务在其中发起关停的项目,请查看服务代理的
project-number。如需确定发出请求的 Google 服务,请查看
protoPayload.requestMetadata.callerSuppliedUserAgent字段。如果某用户触发了关停或重新启动,则其电子邮件地址会显示在
principalEmail字段中。例如cloudysanfrancisco@gmail.com。管理员可以通过更改用户账号的 Identity and Access Management 权限来阻止用户更改项目虚拟机的状态。如需了解详情,请参阅授予、更改和撤消对资源的访问权限。
监控虚拟机生命周期事件
您可以通过构建 Cloud Monitoring 信息中心来监控虚拟机生命周期事件(包括关停、重启和主机错误)。
通过此信息中心,您可以直观呈现本文档的“查看审核日志”部分中详细说明的系统事件和管理员活动。
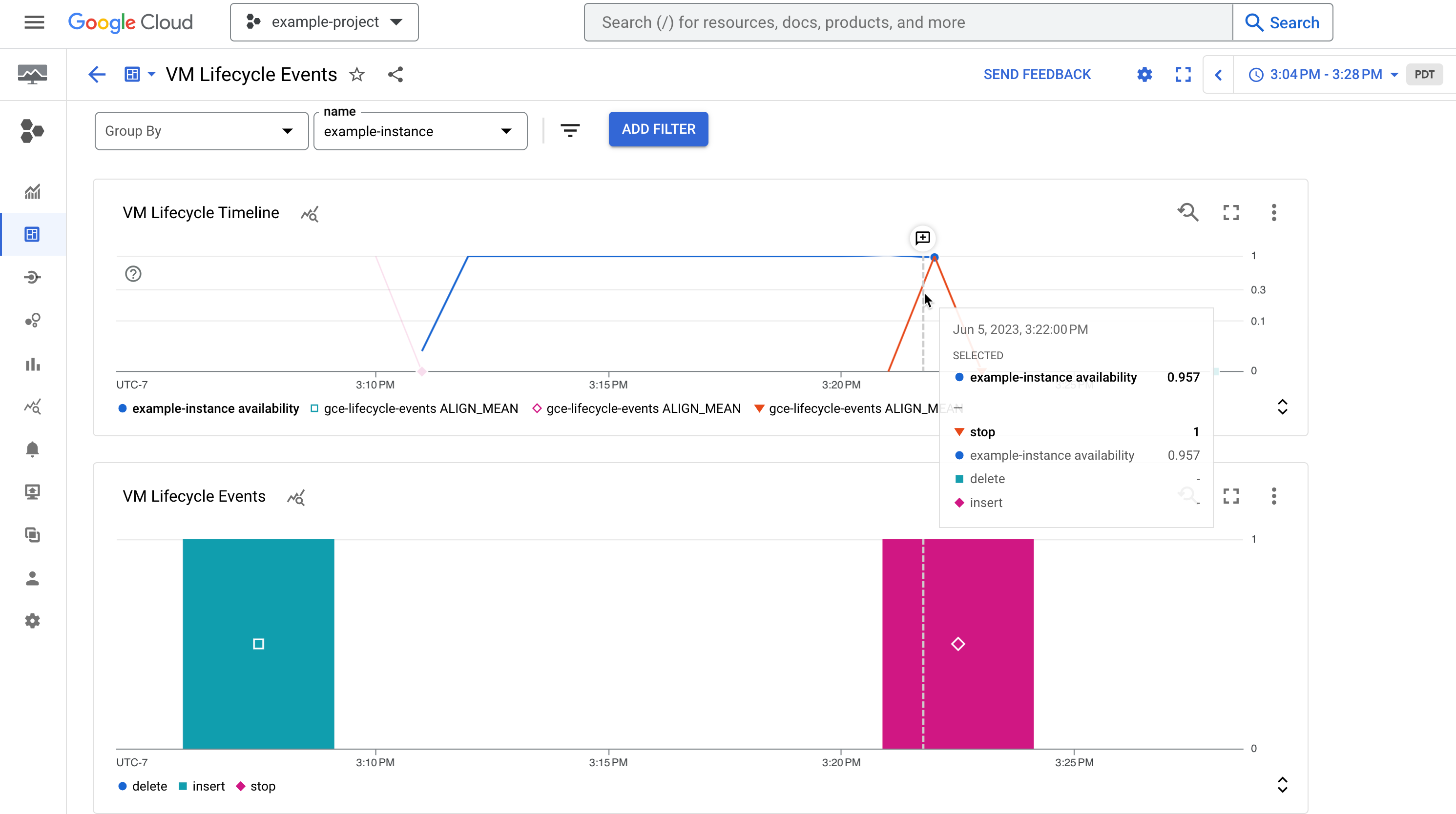 图 1。一个示例信息中心,显示了实例的可用性及其生命周期事件(例如已停止的实例)。
图 1。一个示例信息中心,显示了实例的可用性及其生命周期事件(例如已停止的实例)。创建基于日志的指标
如需捕获虚拟机生命周期事件,请创建用户定义的基于日志的指标。此指标使用审核日志来统计特定虚拟机生命周期事件发生的次数。
如需获得创建指标所需的权限,请让您的管理员为您授予项目的 Logs Writer (
roles/logging.logWriter) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。通过执行以下操作创建用户定义的基于日志的指标:
在 Google Cloud 控制台中,前往基于日志的指标页面。
点击创建指标。
在共享类型部分,执行以下操作:
- 选择
Counter。 - 将发行版保留为未选中的默认设置。
在详细信息部分,输入以下信息:
- 基于日志的指标名称:
vm-lifecycle-events。您必须使用此确切名称,信息中心才能正常运行。 - 说明:(可选)输入此指标的说明。
- 单位:
1
在过滤条件选择部分中,指定以下内容:
- 从选择项目或日志存储桶菜单中,选择项目日志
- 在构建过滤条件中,输入:
resource.type = "gce_instance" AND log_id("cloudaudit.googleapis.com/activity") OR log_id("cloudaudit.googleapis.com/system_event") operation.first="true"
在标签部分中,点击添加标签。
指定以下内容:
- 标签名称:
method - 标签类型:
STRING - 字段名称:
protoPayload.methodName - 正则表达式:
(recreateInstance|hostError|automaticRestart|guestTerminate|terminateOnHostMaintenance|preempted|insert|stop|delete|reset|start)
- 标签名称:
点击完成。
点击创建指标。
使用信息中心
在实例发生系统事件或管理员活动之前,信息中心内不会显示任何数据。如需测试信息中心是否正常工作,请执行管理员活动,例如
stop和start操作:- 对任何现有实例执行
stop和start操作,或创建新的虚拟机以进行测试。
如需获得使用信息中心所需的权限,请让您的管理员为您授予项目的 Monitoring Dashboard Viewer (
roles/monitoring.dashboardViewer) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。在 Google Cloud 控制台中,打开信息中心。
在信息中心列表标签页中,打开
GCE VM Lifecycle Events Monitoring信息中心。从名称下拉菜单中选择虚拟机。
将时序范围缩小到相关时间范围。
如需了解更多过滤信息中心的方法,请参阅添加临时过滤条件。
信息中心包含两个图表,其中显示了实例上发生的系统事件和管理员活动的时间轴:
虚拟机生命周期时间轴图表显示以下内容:
compute.googleapis.com/instance/uptime指标,指示虚拟机是否在给定时间点运行,其中 1 表示启动,0 表示关闭。请注意,此指标反映的是用户活动和系统事件影响下的使用期限,并不表示 Compute Engine 服务等级协议 (SLA)。vm-lifecycle-events基于日志的指标,用于计算在给定时间点对实例执行的生命周期操作数(例如stop或start)
“事件”图表显示的是基于日志的相同
vm-lifecycle-events指标,但采用放大视图,便于阅读。请注意,尽管 X 轴是对齐的,但两个图表之间的颜色并不同步。
调查跨项目的大规模虚拟机关停
如果共享 VPC 宿主项目的计费处于非活动状态或已停用,则 Compute Engine 可能会关停连接到共享 VPC 宿主项目的多个虚拟机。
如需确定您的虚拟机是否已被大规模关停请求关停,请查找由
cloud-cluster-manager@prod.google.com启动的停止操作。启动受影响的实例会返回类似于以下内容的错误:
Starting instance(s) INSTANCE_NAME...failed. ERROR: (gcloud.compute.instances.start) The default network interface [nic0] is frozen.如需解决此问题,请执行以下操作:
使用
gcloud compute instances describe命令确定虚拟机使用的共享 VPC:gcloud compute instances describe VM_NAME \ --format="flattened(networkInterfaces[].network)"
输出类似于以下内容:
networkInterfaces[0].network: https://www.googleapis.com/compute/v1/projects/SHARED_VPC_PROJECT/global/networks/FROZEN_NETWORK
如果结算功能已停用,请在共享 VPC 的宿主项目中进行验证。
resource.type="project" protoPayload.request.@type="type.googleapis.com/google.internal.cloudbilling.billingaccount.v1.DisableResourceBillingRequest" protoPayload.response.resourceBillingInfo.billingAccountAssignmentType="DISABLED"如果适用,请在宿主项目上启用结算功能。
为了帮助防止再次出现此问题,请参阅保护项目与其结算账号之间的关联。
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2026-02-14。
-