
Ce tutoriel explique comment activer la réplication asynchrone sur disque persistant Hyperdisk Balanced dans deux Google Cloud régions en tant que solution de reprise après sinistre (DR) et comment lancer les instances de DR en cas de sinistre.
Les instances de cluster de basculement Microsoft SQL Server (FCI) sont une seule instance SQL Server à disponibilité élevée déployée sur plusieurs nœuds de cluster de basculement Windows Server (WSFC). À tout moment, l'un des nœuds du cluster héberge activement l'instance SQL. En cas de panne zonale ou de problème de VM, WSFC transfère automatiquement la propriété des ressources de l'instance à un autre nœud du cluster, ce qui permet aux clients de se reconnecter Les instances FCI SQL Server nécessitent que les données soient stockées sur des disques partagés pour pouvoir être accessibles sur tous les nœuds WSFC.
Pour vous assurer que le déploiement de SQL Server peut résister à une panne régionale, répliquez les données de disque de la région principale dans une région secondaire en activant la réplication asynchrone. Ce tutoriel explique comment utiliser des disques Hyperdisk Balanced High Availability en mode écriture simultanée pour activer la réplication asynchrone dans deux Google Cloud régions en tant que solution de reprise après sinistre pour les instances FCI SQL Server. Il explique également comment lancer les instances de DR en cas de sinistre. Dans ce document, un sinistre est un événement qui entraîne l'échec ou l'indisponibilité d'un cluster de base de données principal, car la région du cluster devient indisponible, peut-être en raison d'une catastrophe naturelle.
Ce tutoriel est destiné aux architectes, aux administrateurs et aux ingénieurs de bases de données.
Objectifs
- Activer la réplication asynchrone Hyperdisk pour tous les nœuds du cluster FCI SQL Server exécutés sur Google Cloud.
- Simuler un sinistre et exécuter un processus complet de reprise après sinistre pour valider la configuration de reprise après sinistre.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud:
Obtenez une estimation des coûts en fonction de votre utilisation prévue,
utilisez le simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
Pour ce tutoriel, vous avez besoin d'un Google Cloud projet. Vous pouvez en créer un ou sélectionner un projet existant :
-
Dans la Google Cloud console, sur la page de sélection du projet, sélectionnez ou créez un Google Cloud projet.
Rôles requis pour sélectionner ou créer un projet
- Sélectionner un projet : la sélection d'un projet ne nécessite pas de rôle IAM spécifique Vous pouvez sélectionner n'importe quel projet pour lequel un rôle vous a été attribué.
-
Créer un projet : pour créer un projet, vous avez besoin du rôle Créateur de projet
(
roles/resourcemanager.projectCreator), qui contient l'autorisationresourcemanager.projects.create. Découvrez comment attribuer des rôles.
-
Vérifiez que la facturation est activée pour votre Google Cloud projet.
-
Dans la Google Cloud console, activez Cloud Shell.
-
Configurez le cluster SQL Server dans la région principale en suivant les étapes de ce guide Configurer un cluster FCI SQL Server avec le mode écriture simultanée Hyperdisk Balanced High Availability. Une fois le cluster configuré, revenez à ce tutoriel pour activer la reprise après sinistre dans la région secondaire.
Autorisations appropriées dans votre projet Google Cloud et SQL Server pour effectuer des sauvegardes et des restaurations.
Reprise après sinistre dans Google Cloud
La reprise après sinistre dans Google Cloud implique de maintenir un accès continu aux données lorsqu'une région est défaillante ou devient inaccessible. Il existe plusieurs options de déploiement pour le site de DR, qui dépendent des exigences liées à l'objectif de reprise après sinistre (RPO) et à l'objectif de temps de récupération (RTO). Ce tutoriel présente l'une des options permettant de répliquer les disques associés à la machine virtuelle de la région principale vers la région de DR.
Reprise après sinistre à l'aide de la réplication asynchrone Hyperdisk
La réplication asynchrone Hyperdisk est une option de stockage qui permet une copie de stockage asynchrone pour la réplication de disques entre deux régions. Dans le cas peu probable d'une panne régionale, la réplication asynchrone Hyperdisk vous permet de basculer vos données vers une région secondaire et de redémarrer votre charge de travail dans cette région.
La réplication asynchrone Hyperdisk réplique les données d'un disque associé à une charge de travail en cours d'exécution, appelé disque principal, vers un disque distinct situé dans une autre région. Le disque qui reçoit les données répliquées est appelé disque secondaire. La région dans laquelle le disque principal est exécuté est appelée région principale, et la région dans laquelle le disque secondaire est exécuté est appelée région secondaire. Pour garantir que les instances répliquées de tous les disques associés à chaque nœud SQL Server contiennent des données correspondant à un même point dans le temps, les disques sont ajoutés à un groupe de cohérence. Les groupes de cohérence vous permettent d'effectuer des reprises après sinistre et des tests de reprise après sinistre sur plusieurs disques.
Architecture de reprise après sinistre
Pour la réplication asynchrone Hyperdisk, le schéma suivant illustre une architecture minimale prenant en charge la haute disponibilité de la base de données dans une région principale (R1) et la réplication de disques de la région principale vers la région secondaire (R2).
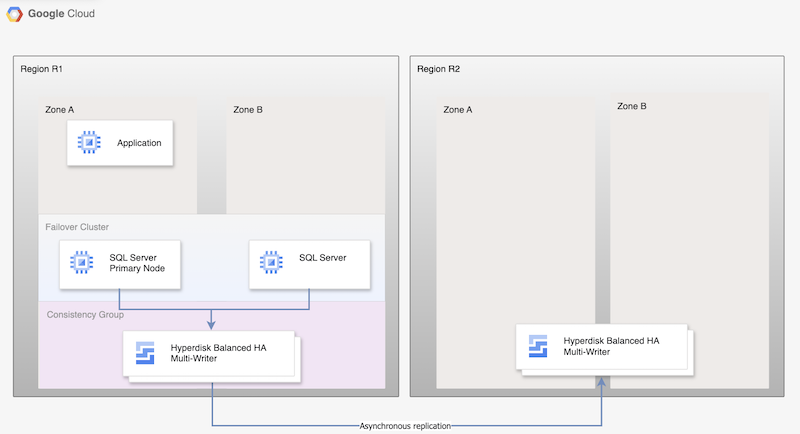
Figure 1 : Architecture de reprise après sinistre avec Microsoft SQL Server et réplication asynchrone Hyperdisk
Cette architecture fonctionne comme suit :
- Deux instances de Microsoft SQL Server (une instance principale et une instance de secours) font partie d'un cluster FCI et se trouvent dans la région principale (R1), mais dans des zones différentes (zones A et B). Les deux instances partagent un disque Hyperdisk Balanced High Availability, ce qui permet d'accéder aux données à partir des deux VM. Pour obtenir des instructions, consultez la section Configurer un cluster FCI SQL Server avec le mode écriture simultanée Hyperdisk Balanced High Availability.
- Les disques des deux nœuds SQL sont ajoutés aux groupes de cohérence et répliqués dans la région de reprise après sinistre R2. Compute Engine réplique de manière asynchrone les données de R1 vers R2.
- La réplication asynchrone ne réplique que les données sur les disques vers R2 et ne réplique pas les métadonnées de la VM. Lors de la reprise après sinistre, de nouvelles VM sont créées et les disques répliqués existants sont associés aux VM afin de mettre les nœuds en ligne.
Processus de reprise après sinistre
Le processus de reprise après sinistre définit les étapes opérationnelles que vous devez suivre après qu'une région est devenue indisponible pour reprendre la charge de travail dans une autre région. Un processus de base de reprise après sinistre sur une base de données comprend les étapes suivantes :
- La première région (R1) qui exécute l'instance de base de données principale devient indisponible.
- L'équipe en charge des opérations reconnaît officiellement le sinistre et décide si un basculement est nécessaire.
- Si un basculement est nécessaire, vous devez arrêter la réplication entre les disques principal et secondaire. Une nouvelle VM est créée à partir des instances répliquées des disques et mise en ligne.
- La base de données de la région de reprise après sinistre R2 est validée et mise en ligne. La base de données de R2 devient la nouvelle base de données principale, ce qui permet la connectivité.
- Les utilisateurs reprennent le traitement sur la nouvelle base de données principale et accèdent à l'instance principale dans la région R2.
Bien que ce processus de base définisse à nouveau une base de données principale opérationnelle, il n'établit pas une architecture complète de haute disponibilité, car la nouvelle base de données principale n'est pas répliquée.
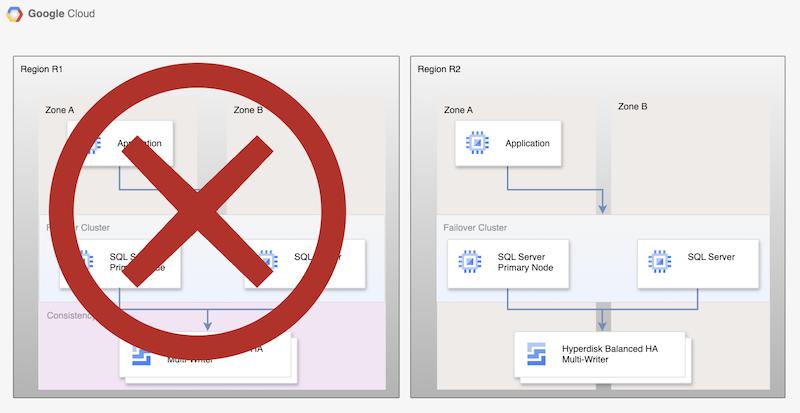
Figure 2 : Déploiement de SQL Server après la reprise après sinistre avec réplication asynchrone sur disque persistant
Revenir à une région récupérée
Lorsque la région principale (R1) est de nouveau en ligne, vous pouvez planifier et exécuter le processus de restauration. Le processus de restauration comprend toutes les étapes décrites dans ce tutoriel, mais dans ce cas, R2 est la région source et R1 est la région de récupération.
Choisir une édition SQL Server
Ce tutoriel s'applique aux versions suivantes de Microsoft SQL Server :
- SQL Server 2016 Enterprise et Standard Edition
- SQL Server 2017 Enterprise et Standard Edition
- SQL Server 2019 Enterprise et Standard Edition
- SQL Server 2022 Enterprise et Standard Edition
Ce tutoriel utilise l'instance de cluster de basculement SQL Server avec le disque Hyperdisk Balanced High Availability.
Si vous n'avez pas besoin des fonctionnalités SQL Server Enterprise features vous pouvez utiliser l'édition Standard de SQL Server :
Avec les versions 2016, 2017 2019 et 2022 de SQL Server, Microsoft SQL Server Management Studio est déjà installé dans l'image. Vous n'avez pas besoin de l'installer séparément. Dans un environnement de production, nous vous recommandons toutefois d'installer une instance de Microsoft SQL Server Management Studio sur une VM distincte dans chaque région. Si vous configurez un environnement à haute disponibilité, vous devez effectuer une installation de Microsoft SQL Server Management Studio dans chaque zone afin de garantir que le service reste disponible si une autre zone devient indisponible.
Configurer la reprise après sinistre pour Microsoft SQL Server
Ce tutoriel utilise l'image sql-ent-2022-win-2022 pour Microsoft SQL Server Enterprise.
Pour obtenir la liste complète des images, consultez la section Images d'OS.
Configurer un cluster à haute disponibilité comprenant deux instances
Pour configurer la réplication de disque pour SQL Server entre deux régions, vous devez d'abord créer un cluster à haute disponibilité à deux instances dans une région.
Une instance sert d'instance principale, tandis que l'autre sert d'instance de secours. Pour effectuer cette étape, suivez les instructions de la section
Configurer un cluster FCI SQL Server avec le mode écriture simultanée Hyperdisk Balanced High Availability.
Ce tutoriel utilise us-central1 comme région principale R1.
Si vous avez suivi la procédure décrite dans
Configurer un cluster FCI SQL Server avec le mode écriture simultanée Hyperdisk Balanced High Availability,
vous avez créé deux instances SQL Server dans la même région (us-central1). Vous avez déployé une instance SQL Server principale (node-1) dans
us-central1-a, et une instance de secours (node-2) dans us-central1-b.
Activer la réplication asynchrone des disques
Une fois toutes les VM créées et configurées, activez la réplication de disque entre les deux régions en procédant comme suit :
Créez un groupe de cohérence pour les nœuds SQL Server et le nœud hébergeant les rôles de témoin et de contrôleur de domaine. L'une des limites des groupes de cohérence est qu'ils ne peuvent pas couvrir plusieurs zones. Vous devez donc ajouter chaque nœud à un groupe de cohérence distinct.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
Ajoutez les disques des VM principales et de secours aux groupes de cohérence correspondants.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Créez des disques secondaires vides dans la région secondaire.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Démarrez la réplication des disques. Les données sont répliquées à partir du disque principal vers le disque vide nouvellement créé dans la région de reprise après sinistre.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
À ce stade, les données doivent se répliquer entre les régions.
L'état de réplication de chaque disque doit indiquer Active.
Simuler une reprise après sinistre
Dans cette section, vous allez tester l'architecture de reprise après sinistre configurée dans ce tutoriel.
Simuler une interruption et exécuter un basculement de reprise après sinistre
Lors d'un basculement, vous créez des VM dans la région de DR et leur associez les disques répliqués. Pour simplifier le basculement, vous pouvez utiliser un autre cloud privé virtuel (VPC) dans la région de DR pour la reprise afin d'utiliser la même adresse IP.
Avant de démarrer le basculement, assurez-vous que node-1 est le nœud principal du groupe de disponibilité AlwaysOn que vous avez créé. Lancez le contrôleur de domaine et le nœud SQL Server principal pour éviter tout problème de synchronisation des données, car les deux nœuds sont protégés par deux groupes de cohérence distincts.
Pour simuler une panne, procédez comme suit :
Créez un VPC de reprise.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Arrêtez la réplication de données.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Arrêtez les VM sources dans la région principale.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Renommez les VM existantes pour éviter les doublons dans le projet.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
Créez des VM dans la région de DR à l'aide des disques secondaires. Ces VM auront l'adresse IP de la VM source.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
Vous avez simulé une interruption de service et effectué un basculement vers la région de reprise après sinistre. Vous pouvez maintenant vérifier si l'instance secondaire fonctionne correctement.
Vérifier la connectivité SQL Server
Une fois les VM créées, vérifiez que les bases de données ont bien été récupérées et que le serveur fonctionne comme prévu. Pour tester la base de données, exécutez une requête à partir de la base de données récupérée.
- Connectez-vous à la VM SQL Server à l'aide du Bureau à distance.
- Ouvrez SQL Server Management Studio.
- Dans la boîte de dialogue Se connecter au serveur, vérifiez que le nom du serveur est défini sur
node-1et sélectionnez Se connecter. Dans le menu Fichier, sélectionnez Fichier > Nouveau > Requête avec la connexion actuelle.
USE [bookshelf]; SELECT * FROM Books;
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , suivez les étapes de cette section pour supprimer les ressources que vous avez créées.
Supprimer le projet
- Dans la Google Cloud console, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez Arrêter pour supprimer le projet.
Étape suivante
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.