
Questo tutorial descrive come eseguire il backup diretto di un database Microsoft SQL Server 2022 in un bucket Cloud Storage e ripristinarlo in un secondo momento. Introdotta in SQL Server 2022, la funzionalità nativa di backup di SQL Server offre una strategia semplice ed economica per ilripristino di emergenzay e la migrazione dei dati basati sul cloud.
La funzionalità nativa di backup di SQL Server utilizza i comandi BACKUP TO URL e
RESTORE FROM URL che supportano l'archiviazione di oggetti compatibile con S3, incluso Cloud Storage. In questo modo non è necessario
uno spazio di archiviazione locale intermedio, semplificando il workflow di backup e riducendo
l'overhead operativo.
Questo tutorial è rivolto ad amministratori e database engineer.
Obiettivi
Questo tutorial mostra come completare le seguenti attività per raggiungere il tuo obiettivo:- Crea un nuovo bucket Cloud Storage
- Configura un connettore SQL Server
- Eseguire il backup del database
- Ripristina il database dal backup
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per saperne di più, consulta Esegui la pulizia.
Prima di iniziare
Per questo tutorial, è necessario un progetto Google Cloud . Puoi crearne uno nuovo o selezionarne uno già esistente:
-
Nella console Google Cloud , nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud .
Ruoli richiesti per selezionare o creare un progetto
- Seleziona un progetto: la selezione di un progetto non richiede un ruolo IAM specifico. Puoi selezionare qualsiasi progetto per il quale ti è stato concesso un ruolo.
-
Crea un progetto: per creare un progetto, devi disporre del ruolo Autore progetto
(
roles/resourcemanager.projectCreator), che contiene l'autorizzazioneresourcemanager.projects.create. Scopri come concedere i ruoli.
-
Verifica che la fatturazione sia abilitata per il tuo progetto Google Cloud .
-
Nella console Google Cloud , attiva Cloud Shell.
-
Assicurati che Microsoft SQL Server 2022 o versioni successive sia installato e in esecuzione.
Assicurati che sia il progetto Google Cloud sia SQL Server dispongano delle autorizzazioni necessarie per eseguire le attività di backup e ripristino.
Assicurati che l'utente o il account di servizio associato alle chiavi di accesso disponga delle autorizzazioni per creare e visualizzare oggetti nel bucket Cloud Storage.
Assicurati che l'account utente SQL Server utilizzato per eseguire il backup disponga delle autorizzazioni di backup del database e del log di backup.
Crea un bucket Cloud Storage
Puoi creare un bucket Cloud Storage utilizzando la console Google Cloud o il comando gcloud storage.
Per creare un bucket Cloud Storage utilizzando
il comando gcloud storage, segui questi
passaggi.
Selezionare il tuo progetto Google Cloud .
gcloud config set project PROJECT_ID
Crea il bucket. Per creare il bucket, esegui il comando
gcloud storage buckets createnel seguente modo.gcloud storage buckets create gs://BUCKET_NAME --location=BUCKET_LOCATION
Sostituisci quanto segue:
BUCKET_NAME: con un nome univoco per il bucket.BUCKET_LOCATION: con la posizione del bucket.
Configura l'interoperabilità S3 e crea una chiave di accesso
Per consentire a SQL Server di comunicare con Cloud Storage utilizzando il protocollo S3, devi abilitare l'interoperabilità e generare una chiave di accesso seguendo questi passaggi:
Vai alle impostazioni di Cloud Storage nella console Google Cloud .
Seleziona la scheda Interoperabilità.
Nella sezione Chiavi di accesso del tuo account utente, fai clic su Crea una chiave.
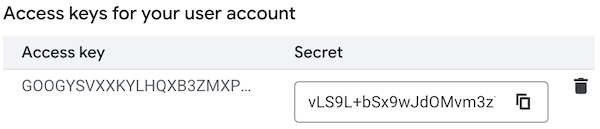
Salva in modo sicuro la chiave di accesso e il secret generati. Ti serviranno nel passaggio successivo.
Aggiungi le credenziali a SQL Server
Per consentire a SQL Server di autenticarsi con il bucket Cloud Storage, devi creare un oggetto credenziale in SQL Server per archiviare la chiave di accesso e il secret di Cloud Storage. Per farlo, esegui questo comando T-SQL in SQL Server Management Studio (SSMS).
CREATE CREDENTIAL CREDENTIAL_NAME
WITH
IDENTITY = 'S3 Access Key',
SECRET = 'ACCESS_KEY:SECRET';
Sostituisci quanto segue:
CREDENTIAL_NAME: con un nome per le credenziali.ACCESS_KEY: con la chiave di accesso creata nella sezione precedente.SECRET: con il secret creato nella sezione precedente.
IDENTITY = 'S3 Access Key' è fondamentale perché indica a SQL Server di utilizzare il nuovo connettore S3. Il secret deve essere formattato come la chiave di accesso, seguito da due punti e poi dalla chiave segreta.
Esempio:
CREATE CREDENTIAL sql_backup_credentials
WITH
IDENTITY = 'S3 Access Key',
SECRET = 'GOOGGE3SVF7OQE5JRMLQ7KWB:b31Pl8Tx1ARJfdGOsbgMFQNbk3nPdlT2UCYzs1iC';
Esegui il backup dei dati in Cloud Storage
Con le credenziali a posto, ora puoi eseguire il backup del database direttamente nel bucket Cloud Storage utilizzando il comando BACKUP DATABASE con l'opzione TO URL. Aggiungi il prefisso s3://storage.googleapis.com all'URL per utilizzare il connettore S3, come segue.
BACKUP DATABASE DATABASE_NAME
TO URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME.bak'
WITH
CREDENTIAL = 'CREDENTIAL_NAME',
FORMAT,
STATS = 10,
MAXTRANSFERSIZE = 10485760,
COMPRESSION;
Sostituisci quanto segue:
CREDENTIAL_NAMEIl nome della credenziale creata nel passaggio 3. Ad esempio,sql_backup_credentials.BUCKET_NAMEIl nome del bucket che hai creato nel passaggio 1.FOLDER_NAMEIl nome della cartella in cui vuoi archiviare il file di backup.BACKUP_FILE_NAMEIl nome del file di backup.
Le descrizioni dei parametri di backup utilizzati nel comando sono le seguenti:
FORMAT: sovrascrive i file di backup esistenti e crea un nuovo set di media.STATS: indica lo stato di avanzamento del backup.COMPRESSION: comprime il backup, il che può ridurre le dimensioni del file e il tempo di caricamento.MAXTRANSFERSIZE: consigliato per evitare errori di I/O con file di backup di grandi dimensioni.
Per saperne di più, consulta la sezione Backup di SQL Server su URL per l'archiviazione di oggetti compatibile con S3.
Per i database molto grandi, puoi dividere il backup in più file nel seguente modo.
BACKUP DATABASE DATABASE_NAME
TO
URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME_0.bak',
URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME_1.bak'
-- ... more files
WITH
CREDENTIAL = 'CREDENTIAL_NAME',
FORMAT,
STATS = 10,
MAXTRANSFERSIZE = 10485760,
COMPRESSION;
Ripristinare i dati da Cloud Storage
Puoi ripristinare il database direttamente da un file di backup archiviato in Cloud Storage utilizzando il comando RESTORE DATABASE come segue.
RESTORE DATABASE DATABASE_NAME
FROM URL = 's3://storage.googleapis.com/BUCKET_NAME/FOLDER_NAME/BACKUP_FILE_NAME.bak'
WITH
CREDENTIAL = 'CREDENTIAL_NAME';
Sostituisci quanto segue:
CREDENTIAL_NAMEIl nome della credenziale creata nel passaggio 3. Ad esempio,sql_backup_credentials.BUCKET_NAMEIl nome del bucket che hai creato nel passaggio 1.FOLDER_NAMEIl nome della cartella in cui vuoi archiviare il file di backup.BACKUP_FILE_NAMEIl nome del file di backup.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial:
Elimina il progetto
- Nella console Google Cloud , vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona quello che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.