
Managed Airflow (第 3 代) | Managed Airflow (第 2 代) | Managed Airflow (舊版第 1 代)
本頁面提供常見工作流程問題的疑難排解步驟和資訊。
許多 DAG 執行問題都是環境效能不佳所致。 您可以按照「最佳化調整環境效能和成本效益」指南,將環境調整至最佳狀態。
部分 DAG 執行問題可能是 Airflow 排程器無法正常或最佳運作所致。請按照排程器疑難排解說明解決這些問題。
排解工作流程問題
如何開始進行疑難排解:
查看 Airflow 記錄。
如要提高 Airflow 的記錄層級,請覆寫下列 Airflow 設定選項。
區段 鍵 值 logginglogging_level預設值為 INFO。設為DEBUG可在記錄訊息中取得更多詳細資訊。查看監控資訊主頁。
查看 Cloud Monitoring。
在 Google Cloud 控制台中,前往環境的元件頁面查看是否有錯誤。
在 Airflow 網頁介面中查看 DAG 的圖表檢視,檢查是否有失敗的工作執行個體。
區段 鍵 值 webserverdag_orientationLR、TB、RL或BT。
使用 Gemini Cloud Assist 調查 Airflow 工作失敗原因
Gemini Cloud Assist 調查是一項根本原因分析 (RCA) 工具,能夠從複雜的分散式雲端環境中,排解基礎架構和應用程式的問題。這項工具可協助您在 Google Cloud瞭解、診斷及解決問題,透過調查,您可以縮短排解問題的時間,同時提高整體可用性,從此應對事件簡單不費力。
在 Managed Airflow 中,您可以從 DAG UI 啟動 Gemini Cloud Assist 調查,瞭解 Airflow 工作失敗的原因。Managed Airflow 會自動填入問題說明和時間範圍等詳細資料,並將您的環境納入相關資源。
開始及查看調查
如要針對失敗的 Airflow 工作啟動新的 Gemini Cloud Assist 調查,或查看現有調查,請按照下列步驟操作:
前往 Google Cloud 控制台的「Environments」(環境) 頁面。
選取環境即可查看詳細資料。
在「Environment details」(環境詳細資料) 頁面中,前往「DAGs」分頁。
按一下 DAG 名稱。
在「DAG details」(DAG 詳細資料) 頁面中,前往「Run history」(執行記錄) 分頁標籤,然後按一下有失敗工作的 DAG 執行作業。
在失敗的 Airflow 工作「狀態」欄中,按一下 「調查」:
- 如要調查新工作,請按一下「調查」。
- 如果工作已有調查項目,請按一下「查看調查項目」,查看現有調查項目。或者,您也可以按一下「新調查」,展開另一項調查。
調查範例
這個範例說明如何調查失敗的工作。
在「Monitoring」(監控) >「DAG Statistics」(DAG 統計資料) 資訊主頁上,觀察失敗的 DAG 執行作業:
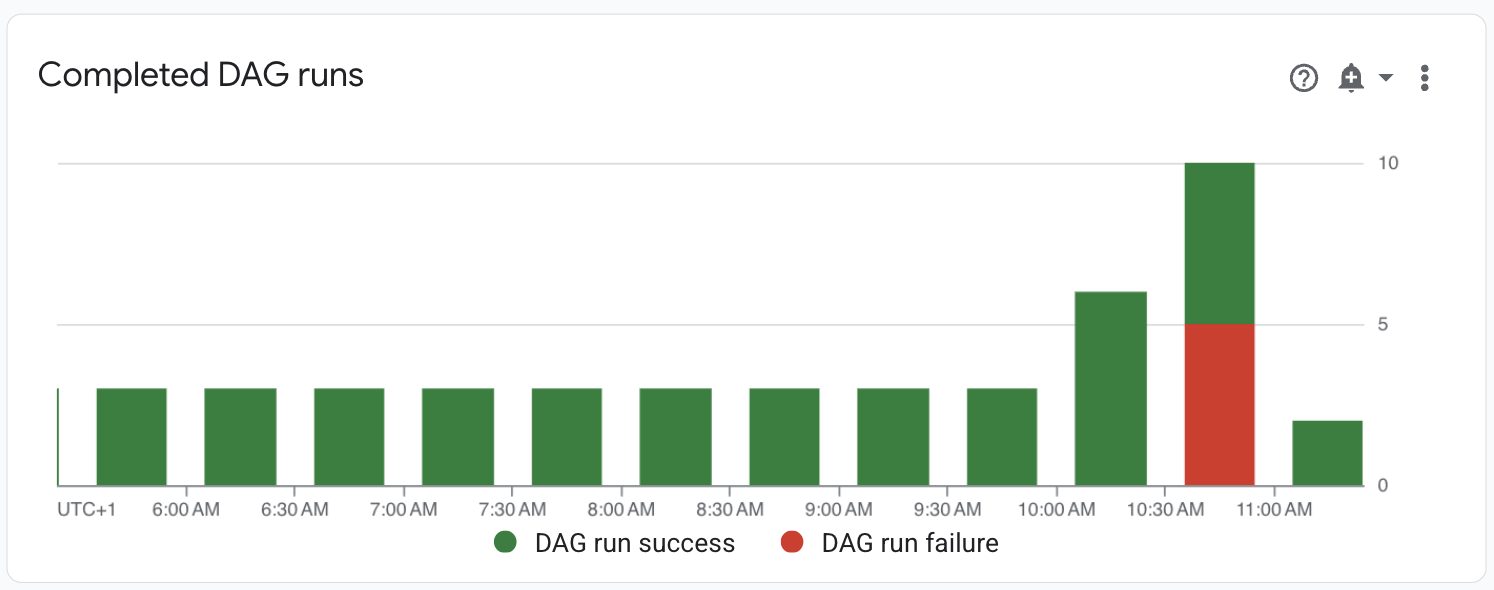
圖 1. 已完成的 DAG 執行作業圖表 (按一下可放大) 前往「DAGs」。「失敗的執行作業 (1 小時)」欄顯示 DAG 在過去一小時內有多次執行失敗。
create_large_txt_file_print_logs按一下 DAG 名稱。
圖 2. 列出 DAG 執行統計資料的 DAG 清單 (按一下可放大) 按一下其中一個失敗的 DAG 執行作業,然後按一下失敗的 Airflow 工作項目旁的「調查」,開始調查。
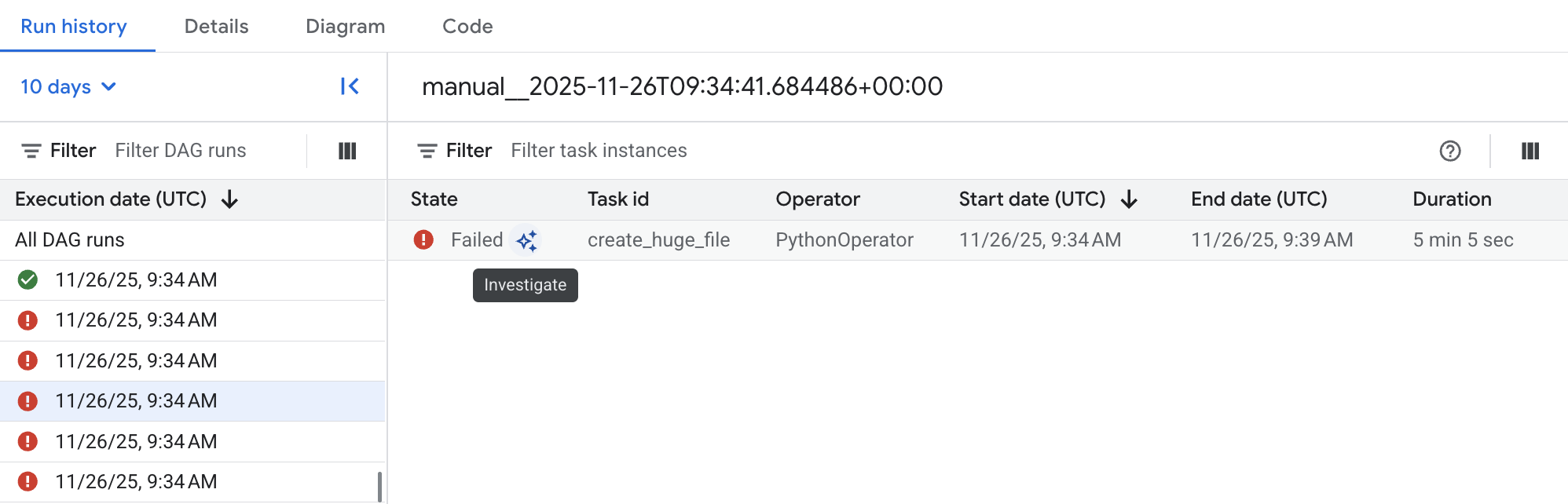
圖 3. 失敗 DAG 中的工作清單 (按一下可放大) 等待調查完成。
「相關觀察項目」清單會詳細列出調查過程。在這個特定範例中,工作失敗但未產生記錄,不過 Gemini Cloud Assist 能夠在 Airflow 排程器記錄中找出失敗原因,也就是工作因成為無效程序而終止。
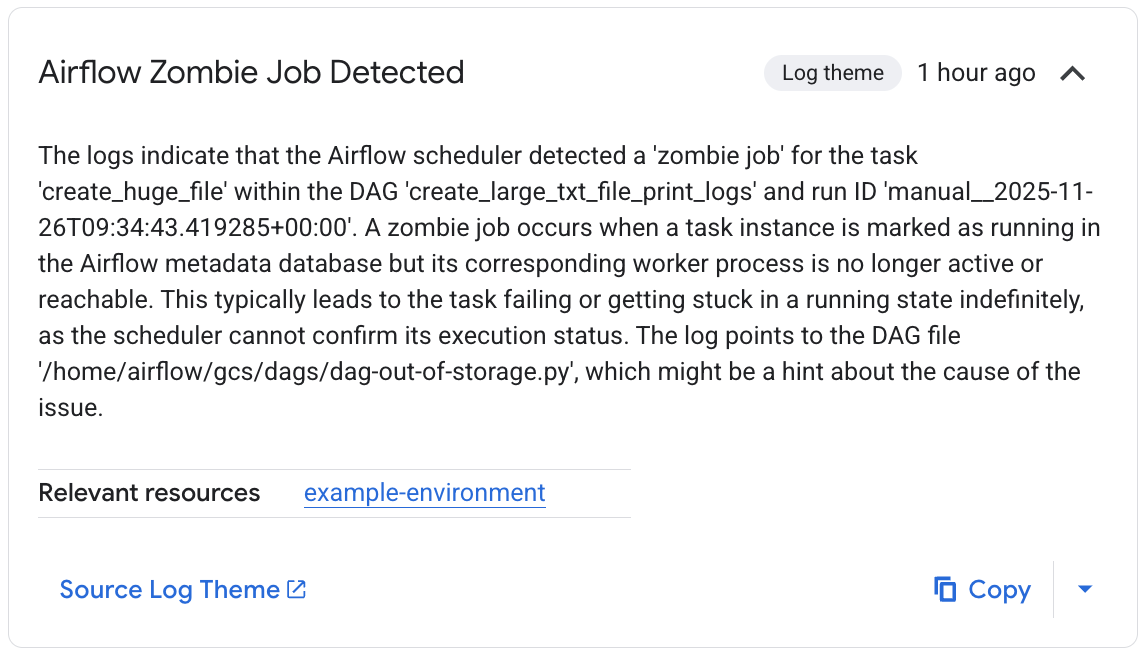
圖 4. 偵測到殭屍作業觀察結果 (按一下即可放大) 最後,Gemini Cloud Assist 會彙整調查結果,並提供假設和修正問題的建議。在這個範例中,工作失敗是因為 Airflow 工作站沒有足夠的資源來處理工作。觀察結果顯示,工作人員 Pod 多次重新啟動時發生 OOM 錯誤,且排程器隨後終止工作,視為殭屍工作。

圖 5. Airflow Worker Pod 資源耗盡假設 (按一下即可放大)
針對運算子錯誤進行偵錯
如何針對運算子錯誤進行偵錯:
- 檢查是否有與特定工作相關的錯誤。
- 查看 Airflow 記錄。
- 查看 Cloud Monitoring。
- 查看運算子專屬記錄。
- 修正錯誤。
- 將 DAG 上傳至
/dags資料夾。 - 在 Airflow 網頁介面中,清除 DAG 的狀態記錄。
- 繼續或執行 DAG。
排解工作執行問題
Airflow 是分散式系統,包含排程器、執行器、工作站等許多實體,這些實體會透過工作佇列和 Airflow 資料庫彼此通訊,並傳送信號 (例如 SIGTERM)。下圖顯示 Airflow 元件之間的互連概況。

在 Airflow 這類分散式系統中,可能會發生網路連線問題,或基礎架構可能發生間歇性問題;這可能會導致工作失敗並重新排定執行時間,或工作可能無法順利完成 (例如殭屍工作,或卡在執行階段的工作)。Airflow 具有處理這類情況的機制,並會自動恢復正常運作。以下各節說明 Airflow 執行工作時發生的常見問題。
工作失敗但未產生任何記錄
工作執行個體可能會因多種原因而失敗,且不會發出記錄。 舉例來說,這可能是因為 DAG 剖析錯誤、DAG 同步處理延遲,或是在工作執行期間 Airflow 工作站 Pod 遭到逐出 (請參閱「工作因 Pod 遭到逐出而失敗」)。
DAG 剖析逾時或錯誤
如果 DAG 檔案有程式設計錯誤,或剖析 DAG 檔案的時間過長,可能會導致 Airflow 排程器可以排定工作,但 Airflow 工作站無法執行。如果發生這種情況,系統可能會將工作標示為 Failed,但不會記錄任何執行記錄。
問題
Cloud Logging 中的 Airflow 工作站記錄包含下列訊息:
airflow.exceptions.AirflowException: Dag "example-dag" could not be found; either it does not exist or it failed to parse.airflow.exceptions.AirflowTaskTimeout: Timeout, PID: 12345(這則訊息可能不含 DAG 名稱或檔案路徑)。ERROR - Failed to import: /home/airflow/gcs/dags/example-dag.py(不含詳細追溯)。
如有 DAG 匯入錯誤,您可能會在 Airflow UI 中看到這些錯誤,或在Google Cloud 控制台的「環境詳細資料」頁面看到
Broken DAG訊息。
解決方案
檢查 Airflow 工作站記錄,瞭解是否有與 DAG 剖析相關的錯誤。如果看到
AirflowTaskTimeout錯誤,表示 DAG 剖析可能逾時。Airflow 工作站的剖析逾時是由dagbag_import_timeout控制。如果 DAG 剖析時間過長,請檢查環境叢集是否發生 CPU 爭用情形。如果工作站的 CPU 不足: 增加 Airflow 工作站的 CPU。 或者,如「最佳化環境」一文所述,減少 worker_concurrency。
如果 CPU 使用率偏低,請最佳化 DAG 定義,縮短剖析時間,例如避免使用頂層程式碼。
如果看到
Failed to import錯誤,或 Airflow UI 或Google Cloud 控制台發生錯誤,請按照「排解 DAG 處理器問題」一文所述,檢查 DAG 處理器記錄檔中的詳細追蹤記錄,或執行下列 gcloud CLI 指令,查看 DAG 匯入錯誤:gcloud composer environments run ENVIRONMENT_NAME \ --location LOCATION \ dags list-import-errors如果 DAG 在剖析期間呼叫外部服務,請考慮在這些呼叫周圍新增
try...except區塊,以處理暫時性錯誤。如果無法進行 DAG 剖析最佳化,請增加
dagbag_import_timeout。 覆寫這個 Airflow 設定選項,將值設為高於預設的 30 秒,例如 120 秒。
DAG 檔案同步延遲
在環境的 bucket 中上傳或更新 DAG 檔案時,這些檔案需要一段時間才能同步至 Airflow 工作站和排程器。所有排程器和工作站都會獨立進行這項同步作業。如果您在上傳或更新 DAG 檔案後不久觸發 DAG 執行,且 DAG 檔案尚未同步至接收工作的 worker,工作就會失敗且沒有記錄,您可能會在 worker 記錄中看到 airflow.exceptions.AirflowException: Dag "example-dag" could not be
found...。
同步作業通常需要 1 到 2 分鐘,但如果 bucket 中的 dags/ 或 plugins/ 資料夾包含大量或大型檔案,則可能需要更長時間。
解決方案
上傳或更新 DAG 或外掛程式後,請等待至少 2 分鐘,再觸發或啟用 DAG。
工作停滯在「已排入佇列」狀態
在 2.6.3 之前的 Airflow 版本中,工作有時會永久停留在 queued 狀態。如果 Airflow 資料庫中的工作標示為已加入佇列,但 Celery 中實際並不存在,就可能發生這種情況。這種情況可能會導致 Airflow 工作站無法通過執行中的探測器並重新啟動,進而導致工作失敗,並顯示「找不到記錄檔」錯誤。
這個問題已在 Airflow 2.6.3 以上版本中解決。如果您使用較舊的 Airflow 版本,可以將環境升級至使用 Airflow 2.6.3 以上版本的映像檔版本。
如要解決這個問題,您可以手動清除處於佇列狀態的工作。在 Airflow UI 中,依序前往「Browse」>「Task Instances」,找出處於 queued 狀態的工作例項,並將其狀態設為 failed。
工作突然中斷
在執行工作期間,Airflow 工作人員可能會因與工作本身無關的問題而突然終止,請參閱「常見根本原因」,查看這類情況的清單和可能的解決方法。以下各節將說明可能源自這些根本原因的其他症狀:
無效工作
Airflow 會偵測工作與執行工作的程序之間,是否出現以下兩種不符情況:
無效工作是指應該執行但未執行的工作。如果工作程序已終止或沒有回應、Airflow worker 因負載過重而未及時回報工作狀態,或是執行工作的 VM 已關機,就可能發生這種情況。Airflow 會定期尋找這類工作,並視工作設定而定,讓工作失敗或重試。
找出無效工作
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("airflow-scheduler") textPayload:"Detected zombie job"殭屍工作是指不應執行的工作。Airflow 會定期找出這類工作並終止。
如要進一步瞭解如何排解 Zombie 工作的問題,請參閱「常見根本原因」。
SIGTERM 信號
Linux、Kubernetes、Airflow 排程器和 Celery 會使用 SIGTERM 信號,終止負責執行 Airflow 工作站或 Airflow 工作的程序。
環境中傳送 SIGTERM 信號的原因可能有很多:
工作已成為無效工作,必須停止。
排程器發現重複的工作,並將「終止執行個體」和 SIGTERM 信號傳送至工作,以停止工作。
在水平自動調度 Pod 資源中,GKE 控制層會傳送 SIGTERM 信號,移除不再需要的 Pod。
排程器可以將 SIGTERM 信號傳送至 DagFileProcessorManager 程序。排程器會使用這類 SIGTERM 信號管理 DagFileProcessorManager 程序生命週期,因此可以放心忽略。
範例:
Launched DagFileProcessorManager with pid: 353002 Sending Signals.SIGTERM to group 353002. PIDs of all processes in the group: [] Sending the signal Signals.SIGTERM to group 353002 Sending the signal Signals.SIGTERM to process 353002 as process group is missing.local_task_job 中,活動訊號回呼與結束回呼之間的競爭狀況,會監控任務執行作業情況。如果心跳偵測到工作標示為成功,則無法區分工作本身是否成功,或 Airflow 是否已設定將工作視為成功。不過,這項作業會終止工作執行器,不會等待執行器結束。
您可以放心忽略這類 SIGTERM 信號。這項工作已處於成功狀態,DAG 執行作業整體不會受到影響。
一般結束與成功狀態下終止工作之間的唯一差異,就是記錄項目
Received SIGTERM.。
圖 7. 活動訊號和結束回呼之間的競爭狀況 (按一下可放大) Airflow 元件使用的資源 (CPU、記憶體) 超出叢集節點允許的範圍。
GKE 服務會執行維護作業,並將 SIGTERM 信號傳送至即將升級的節點上執行的 Pod。
如果工作執行個體以 SIGTERM 終止,您可以在執行工作的 Airflow 工作站記錄中,看到下列記錄項目:
{local_task_job.py:211} WARNING - State of this instance has been externally set to queued. Terminating instance. {taskinstance.py:1411} ERROR - Received SIGTERM. Terminating subprocesses. {taskinstance.py:1703} ERROR - Task failed with exception
可能的解決方案:
如果執行工作的 VM 記憶體不足,就會發生這個問題。這與 Airflow 設定無關,而是與 VM 可用的記憶體容量有關。
在 Managed Airflow (第 2 代) 中,您可以為 Airflow worker 指派更多 CPU 和記憶體資源。
您可以降低
[celery]worker_concurrencyconcurrency Airflow 設定選項的值。這個選項會決定特定 Airflow 工作站要同時執行的工作數量。
如要進一步瞭解如何最佳化調整環境,請參閱「最佳化調整環境效能和成本效益」。
Airflow 工作遭 Negsignal.SIGKILL 中斷
有時工作使用的記憶體可能超出 Airflow 工作站的分配量。
在這種情況下,Negsignal.SIGKILL 可能會中斷作業。系統會傳送這項信號,避免進一步耗用記憶體,進而影響其他 Airflow 工作執行。您可能會在 Airflow 工作站的記錄中看到下列記錄項目:
{local_task_job.py:102} INFO - Task exited with return code Negsignal.SIGKILL
Negsignal.SIGKILL 也可能以程式碼 -9 的形式顯示。
可能的解決方案:
降低 Airflow 工作站的
worker_concurrency。增加 Airflow 工作站可用的記憶體量。
在 Managed Airflow 中,使用 KubernetesPodOperator 或 GKEStartPodOperator 隔離工作並自訂資源分配,即可管理耗用大量資源的工作。
將工作最佳化,減少記憶體用量。
資源壓力過大導致工作失敗
徵兆:執行工作時,負責執行 Airflow 工作的 Airflow 工作站子程序突然中斷。Airflow 工作人員記錄中顯示的錯誤可能類似以下內容:
...
File "/opt/python3.8/lib/python3.8/site-packages/celery/app/trace.py", line 412, in trace_task R = retval = fun(*args, **kwargs) File "/opt/python3.8/lib/python3.8/site-packages/celery/app/trace.py", line 704, in __protected_call__ return self.run(*args, **kwargs) File "/opt/python3.8/lib/python3.8/site-packages/airflow/executors/celery_executor.py", line 88, in execute_command _execute_in_fork(command_to_exec) File "/opt/python3.8/lib/python3.8/site-packages/airflow/executors/celery_executor.py", line 99, in _execute_in_fork
raise AirflowException('Celery command failed on host: ' + get_hostname())airflow.exceptions.AirflowException: Celery command failed on host: airflow-worker-9qg9x
...
解決方法:
在 Managed Airflow (第 2 代) 中,提高 Airflow worker 的記憶體限制。
如果環境也會產生無效工作,請參閱「排解無效工作問題」。
如需記憶體不足問題的偵錯教學課程,請參閱「偵錯記憶體不足和儲存空間不足的 DAG 問題」。
Pod 遭逐出,因此工作失敗
Google Kubernetes Engine Pod 須遵守 Kubernetes Pod 生命週期和 Pod 逐出程序。工作量暴增是 Managed Airflow 中 Pod 遭到終止的最常見原因。
如果特定 Pod 相對節點的設定資源耗用預期值,過度使用節點資源,就可能遭到驅逐。舉例來說,如果 Pod 中執行多項耗用大量記憶體的工作,且這些工作加總的負載導致 Pod 執行的節點超出記憶體耗用量上限,就可能發生驅逐作業。
如果 Airflow 工作站 Pod 遭到撤銷,該 Pod 上執行的所有工作例項都會中斷,並在稍後由 Airflow 標示為失敗。
記錄會經過緩衝處理。如果工作站 Pod 在緩衝區清除前遭到移除,就不會產生記錄。如果工作失敗但未產生記錄,表示 Airflow 工作站因記憶體不足 (OOM) 而重新啟動。即使未發出 Airflow 記錄,Cloud Logging 中仍可能存在部分記錄。
如要查看記錄:
前往 Google Cloud 控制台的「Environments」(環境) 頁面。
在環境清單中,按一下環境名稱。 「環境詳細資料」頁面隨即開啟。
前往「記錄」分頁。
如要查看個別 Airflow 工作人員的記錄檔,請依序點選「所有記錄」>「Airflow 記錄」>「工作人員」。
症狀:
前往 Google Cloud 控制台的「Workloads」(工作負載) 頁面。
如有顯示
airflow-worker的 PodEvicted,請按一下各個已撤銷的 pod,然後查看視窗頂端是否有顯示The node was low on resource: memory訊息。
解決方法:
檢查
airflow-workerPod 的記錄,找出可能的驅逐原因。如要進一步瞭解如何從個別 Pod 擷取記錄,請參閱「排解已部署工作負載的問題」。確認 DAG 中的工作皆為冪等且可重試。
避免將不必要的檔案下載到 Airflow worker 的本機檔案系統。
Airflow 工作人員的本機檔案系統容量有限。 Airflow 工作站的儲存空間可介於 1 GB 到 10 GB 之間。 儲存空間用盡時,GKE 控制層會逐出 Airflow 工作站 Pod。這會導致遭逐出工作人員執行的所有工作失敗。
有問題的作業範例:
- 下載檔案或物件,並在本機 Airflow 工作人員中儲存。請改為將這些物件直接儲存在合適的服務中,例如 Cloud Storage 值區。
- 從 Airflow 工作站存取
/data資料夾中的大型物件。Airflow 工作人員會將物件下載至本機檔案系統。 請改為實作 DAG,以便在 Airflow 工作人員 Pod 外部處理大型檔案。
常見根本原因
Airflow 工作站記憶體用盡
每個 Airflow 工作人員最多可同時執行 [celery]worker_concurrency 個工作執行個體。如果這些工作執行個體的累計記憶體用量超過 Airflow worker 的記憶體限制,系統會終止隨機程序,以釋出資源。
探索 Airflow 工作站記憶體不足事件
resource.type="k8s_node"
resource.labels.cluster_name="GKE_CLUSTER_NAME"
log_id("events")
jsonPayload.message:"Killed process"
jsonPayload.message:("airflow task" OR "celeryd")有時,Airflow 工作人員的記憶體不足,可能會導致在 SQL Alchemy 工作階段期間,傳送至資料庫、DNS 伺服器或 DAG 呼叫的任何其他服務的封包格式錯誤。在這種情況下,連線的另一端可能會拒絕或捨棄來自 Airflow 工作人員的連線。例如:
"UNKNOWN:Error received from peer
{created_time:"2024-11-31T10:09:52.217738071+00:00", grpc_status:14,
grpc_message:"failed to connect to all addresses; last error: UNKNOWN:
ipv4:<ip address>:443: handshaker shutdown"}"
解決方法:
最佳化工作,減少記憶體用量,例如避免使用頂層程式碼。
減少
[celery]worker_concurrency。增加 Airflow worker 的記憶體,以配合
[celery]worker_concurrency變更。在 2.6.0 之前的 Managed Airflow (第 2 代) 版本中,如果這個值較低,請使用目前的公式更新
[celery]worker_concurrency。
Airflow 工作站已遭撤銷
在 Kubernetes 上執行工作負載時,Pod 逐出是正常現象。 如果 Pod 儲存空間不足,或為了釋出資源給優先順序較高的工作負載,GKE 會逐出 Pod。
瞭解 Airflow 工作站撤銷次數
resource.type="k8s_pod"
resource.labels.cluster_name="GKE_CLUSTER_NAME"
resource.labels.pod_name:"airflow-worker"
log_id("events")
jsonPayload.reason="Evicted"解決方法:
- 如果儲存空間不足導致驅逐,您可以減少儲存空間用量,或在不需要暫存檔案時立即移除。或者,您也可以增加可用儲存空間,或在具有
KubernetesPodOperator的專屬 Pod 中執行工作負載。
Airflow 工作人員已終止
Airflow 工作站可能會從外部移除。如果目前執行的工作在正常終止期間未完成,系統會中斷這些工作,且可能會偵測為殭屍程序。
瞭解 Airflow 工作站 Pod 終止作業
resource.type="k8s_cluster" resource.labels.cluster_name="GKE_CLUSTER_NAME" protoPayload.methodName:"pods.delete" protoPayload.response.metadata.name:"airflow-worker"
可能的情境和解決方案:
修改環境時 (例如升級或安裝套件),系統會重新啟動 Airflow 工作站:
探索 Composer 環境修改內容
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("cloudaudit.googleapis.com%2Factivity")您可以在沒有執行重要工作時執行這類作業,或啟用工作重試功能。
維護作業期間,各種元件可能會暫時無法使用。
瞭解 GKE 維護作業
resource.type="gke_nodepool" resource.labels.cluster_name="GKE_CLUSTER_NAME" protoPayload.metadata.operationType="UPGRADE_NODES"
您可以指定維護期間,盡量減少
與重要工作執行作業重疊。
在 2.4.5 之前的 Managed Airflow (第 2 代) 版本中,終止的 Airflow 工作人員可能會忽略 SIGTERM 信號,並繼續執行工作:
瞭解 Composer 自動調度資源如何縮減規模
resource.type="cloud_composer_environment" resource.labels.environment_name="ENVIRONMENT_NAME" log_id("airflow-worker-set") textPayload:"Workers deleted"您可以升級至較新的 Managed Airflow 版本,修正這個問題。
Airflow 工作站負載過高
Airflow 工作站可用的 CPU 和記憶體資源量受環境設定限制。如果資源用量接近上限,可能會導致資源爭用,並在工作執行期間發生不必要的延遲。在極端情況下,如果資源長期不足,可能會導致殭屍工作。
解決方法:
- 監控工作站的 CPU 和記憶體用量,並進行調整,避免超過 80%。
Cloud Logging 查詢,可找出 Pod 重新啟動或逐出的原因
Managed Airflow 環境會使用 GKE 叢集做為運算基礎架構層。本節提供實用查詢,有助於找出 Airflow 工作站或 Airflow 排程器重新啟動或遭逐出的原因。
您可以透過下列方式調整後續顯示的查詢:
您可以在 Cloud Logging 中指定所需的時間軸。例如過去 6 小時、3 天,或自訂時間範圍。
您必須在 CLUSTER_NAME 中指定環境叢集的名稱。
如要將搜尋範圍限制在特定 Pod,請加入 POD_NAME。
探索重新啟動的容器
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"will be restarted"
resource.labels.cluster_name="CLUSTER_NAME"
限制結果只顯示特定 Pod 的替代查詢:
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"will be restarted"
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
瞭解因記憶體不足事件而關閉的容器
resource.type="k8s_node"
log_id("events")
(jsonPayload.reason:("OOMKilling" OR "SystemOOM")
OR jsonPayload.message:("OOM encountered" OR "out of memory"))
severity=WARNING
resource.labels.cluster_name="CLUSTER_NAME"
限制結果只顯示特定 Pod 的替代查詢:
resource.type="k8s_node"
log_id("events")
(jsonPayload.reason:("OOMKilling" OR "SystemOOM")
OR jsonPayload.message:("OOM encountered" OR "out of memory"))
severity=WARNING
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
找出已停止執行的容器
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"ContainerDied"
severity=DEFAULT
resource.labels.cluster_name="CLUSTER_NAME"
限制結果只顯示特定 Pod 的替代查詢:
resource.type="k8s_node"
log_id("kubelet")
jsonPayload.MESSAGE:"ContainerDied"
severity=DEFAULT
resource.labels.cluster_name="CLUSTER_NAME"
"POD_NAME"
Airflow 資料庫負載過高
各種 Airflow 元件會使用資料庫彼此通訊,尤其是儲存工作例項的活動訊號。資料庫資源不足會導致查詢時間變長,並可能影響工作執行。
有時,Airflow 工作站的記錄檔會出現下列錯誤:
(psycopg2.OperationalError) connection to server at <IP address>,
port 3306 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally before or while
processing the request.
解決方法:
- 請避免在頂層 DAG 程式碼中使用大量
Variables.get指令。 請改用 Jinja 範本擷取 Airflow 變數的值。 - 在頂層 DAG 程式碼的 Jinja 範本中,盡量減少使用 xcom_push 和 xcom_pull 指令。
- 建議您升級至較大的環境規模 (中型或大型)。
- 減少排程器數量
- 降低 DAG 剖析頻率。
- 監控資料庫 CPU 和記憶體用量。
Airflow 資料庫暫時無法使用
Airflow 工作站可能需要一段時間才能偵測並妥善處理間歇性錯誤,例如暫時性連線問題。這可能會超過預設的殭屍偵測門檻。
瞭解 Airflow 活動訊號逾時
resource.type="cloud_composer_environment"
resource.labels.environment_name="ENVIRONMENT_NAME"
log_id("airflow-worker")
textPayload:"Heartbeat time limit exceeded"解決方法:
增加無效工作的逾時時間,並覆寫 Airflow 設定選項
[scheduler]scheduler_zombie_task_threshold的值:區段 鍵 值 附註 schedulerscheduler_zombie_task_threshold新逾時時間 (秒) 預設值為 300
執行期間發生錯誤,導致工作失敗
終止執行個體
Airflow 會使用終止執行個體機制關閉 Airflow 工作。這個機制適用於下列情況:
- 排程器終止未準時完成的工作。
- 工作逾時或執行時間過長。
Airflow 終止工作例項時,您可以在執行該工作的 Airflow 工作站記錄中,看到下列記錄項目:
INFO - Subtask ... WARNING - State of this instance has been externally set
to success. Terminating instance.
INFO - Subtask ... INFO - Sending Signals.SIGTERM to GPID <X>
INFO - Subtask ... ERROR - Received SIGTERM. Terminating subprocesses.
可能的解決方案:
檢查工作程式碼是否有錯誤,導致工作執行時間過長。
增加 Airflow worker 的 CPU 和記憶體,加快工作執行速度。
提高
[celery_broker_transport_options]visibility_timeoutAirflow 設定選項的值。因此,排程器會等待較長的時間,才會將工作視為殭屍工作。如果工作耗時且持續數小時,這個選項就特別實用。如果值太低 (例如 3 小時),排程器會將執行 5 或 6 小時的工作視為「掛斷」(殭屍工作)。
提高
[core]killed_task_cleanup_timeAirflow 設定選項的值。值越大,Airflow 工作站完成工作所需的時間就越長。如果值太低,Airflow 工作可能會突然中斷,沒有足夠時間順利完成工作。
DAG 執行作業未在預期時間內結束
症狀:
有時 DAG 執行作業不會結束,因為 Airflow 工作停滯,且 DAG 執行作業持續時間超出預期。在正常情況下,Airflow 工作不會無限期處於佇列或執行狀態,因為 Airflow 具有逾時和清除程序,可避免這種情況。
修正方式:
使用 DAG 的
dagrun_timeout參數。例如:dagrun_timeout=timedelta(minutes=120)。因此,每個 DAG 執行作業都必須在 DAG 執行作業逾時時間內完成。如要進一步瞭解 Airflow 工作狀態,請參閱 Apache Airflow 說明文件。使用工作執行逾時參數,為根據 Apache Airflow 運算子執行的工作定義預設逾時。
在工作執行期間或執行完畢後,查詢例外狀況會擲回與 Postgres 伺服器的連線中斷
如果符合下列條件,通常會發生 Lost connection to Postgres server during query 例外狀況:
- 您的 DAG 使用
PythonOperator或自訂運算子。 - 您的 DAG 會查詢 Airflow 資料庫。
如果從可呼叫函式發出多個查詢,回溯可能會錯誤地指向 Airflow 程式碼中的 self.refresh_from_db(lock_for_update=True) 行,這是工作執行後的第一個資料庫查詢。例外狀況的實際原因發生在此之前,也就是 SQLAlchemy 工作階段未正確關閉時。
SQLAlchemy 工作階段的範圍限定於執行緒,且是在可呼叫函式中建立,工作階段稍後可在 Airflow 程式碼中繼續。如果單一工作階段內的查詢之間有明顯延遲,Postgres 伺服器可能已關閉連線。在 Managed Airflow 環境中,連線逾時時間約為 10 分鐘。
解決方法:
- 使用
airflow.utils.db.provide_session修飾符。這個裝飾器會在session參數中提供有效的 Airflow 資料庫工作階段,並在函式結尾正確關閉工作階段。 - 請勿使用單一長期執行的函式。請改為將所有資料庫查詢作業移至個別函式,這樣就會有多個函式使用
airflow.utils.db.provide_session裝飾器。在這種情況下,系統會在擷取查詢結果後自動關閉工作階段。
連線至 Airflow 中繼資料庫時發生暫時性中斷
Managed Airflow 會在分散式基礎架構上執行,也就是說,不時可能會出現暫時性問題,導致 Airflow 工作執行中斷。
在這種情況下,您可能會在 Airflow 工作人員的記錄中看到下列錯誤訊息:
"Can't connect to Postgres server on 'airflow-sqlproxy-service.default.svc.cluster.local' (111)"
或
"Can't connect to Postgres server on 'airflow-sqlproxy-service.default.svc.cluster.local' (104)"
這類間歇性問題也可能是因為對 Managed Airflow 環境執行的維護作業所致。
這類錯誤通常是間歇性的,如果 Airflow 工作是冪等的,且您已設定重試,就不會受到影響。您也可以考慮定義維護期間。
造成這類錯誤的另一個原因,可能是環境叢集缺少資源。在這種情況下,您可以按照「擴大環境規模」或「最佳化環境」的說明,擴大環境規模或進行最佳化。
DAG 執行作業標示為成功,但沒有執行的工作
如果 DAG 執行作業 execution_date 早於 DAG 的 start_date,您可能會看到沒有任何任務執行作業,但仍標示為成功的 DAG 執行作業。

原因
這可能發生於下列情況:
DAG 的
execution_date與start_date時區不同,就會導致不符。舉例來說,使用pendulum.parse(...)設定start_date時,可能會發生這種情況。DAG 的
start_date設為動態價值,例如airflow.utils.dates.days_ago(1)
解決方案
請確認
execution_date和start_date使用相同的時區。指定靜態
start_date並與catchup=False合併,避免使用過去的開始日期執行 DAG。
最佳做法
更新或升級作業對 Airflow 工作執行的影響
更新或升級作業會中斷目前執行的 Airflow 工作,除非工作是以可延遲模式執行。
建議您在預期對 Airflow 工作執行作業的影響最小時執行這些作業,並在 DAG 和工作中設定適當的重試機制。
請勿同時排定以程式輔助產生的 DAG
從 DAG 檔案以程式輔助方式產生 DAG 物件,是撰寫許多只有些微差異的類似 DAG 的有效方法。
請務必不要立即排定所有這類 DAG 的執行時間。如果同時排定多項工作,Airflow 工作站很可能沒有足夠的 CPU 和記憶體資源來執行所有工作。
為避免以程式輔助方式排定 DAG 時發生問題,請注意下列事項:
- 提高工作站並行數並擴大規模,讓環境能同時執行更多工作。
- 產生 DAG 時,請確保排程平均分配在一段時間內,避免同時排定數百項任務,讓 Airflow worker 有時間執行所有排定的任務。
控管 DAG、工作和相同 DAG 的平行執行作業的執行時間
如要控管特定 DAG 的單一 DAG 執行作業持續時間,可以使用 dagrun_timeout DAG 參數。舉例來說,如果您預期單一 DAG 執行作業 (無論執行作業是否成功完成) 的持續時間不得超過 1 小時,請將這個參數設為 3600 秒。
您也可以控管單一 Airflow 工作可持續的時間長度。如要這麼做,可以使用 execution_timeout。
如要控管特定 DAG 的有效 DAG 執行次數,可以使用 [core]max-active-runs-per-dag
Airflow 設定選項。
如要確保在特定時間只執行一個 DAG 執行個體,請將 max-active-runs-per-dag 參數設為 1。
避免 Airflow 資料庫的網路流量增加
環境的 GKE 叢集與 Airflow 資料庫之間的網路流量大小,取決於 DAG 數量、DAG 中的工作數量,以及 DAG 存取 Airflow 資料庫中資料的方式。下列因素可能會影響網路用量:
查詢 Airflow 資料庫。如果 DAG 執行大量查詢,就會產生大量流量。範例:先檢查工作狀態,再繼續執行其他工作、查詢 XCom 表格、傾印 Airflow 資料庫內容。
大量工作。排定的工作越多,產生的網路流量就越多。這項考量因素適用於 DAG 中的工作總數和排程頻率。Airflow 排程器排定 DAG 執行作業時,會查詢 Airflow 資料庫並產生流量。
Airflow 網頁介面會查詢 Airflow 資料庫,因此會產生網路流量。大量使用含有圖表、工作和圖表的頁面可能會產生大量網路流量。