
העברה מ-Aerospike ל-Bigtable
במאמר הזה מוסבר איך להעביר נתונים מ-Aerospike ל-Bigtable. במאמר הזה מוסבר איך להשתמש בכלים בקוד פתוח, כמו ספריית המתאמים, כדי לבצע את ההעברה.
לפני שמתחילים בהעברה, כדאי לעיין במאמר Bigtable למשתמשי Aerospike.
סקירה כללית על מיגרציה
אתם יכולים להעביר את הנתונים מ-Aerospike ל-Bigtable עם השבתה מינימלית או ללא השבתה בכלל.
התרשים הבא מציג את שלבי ההעברה:
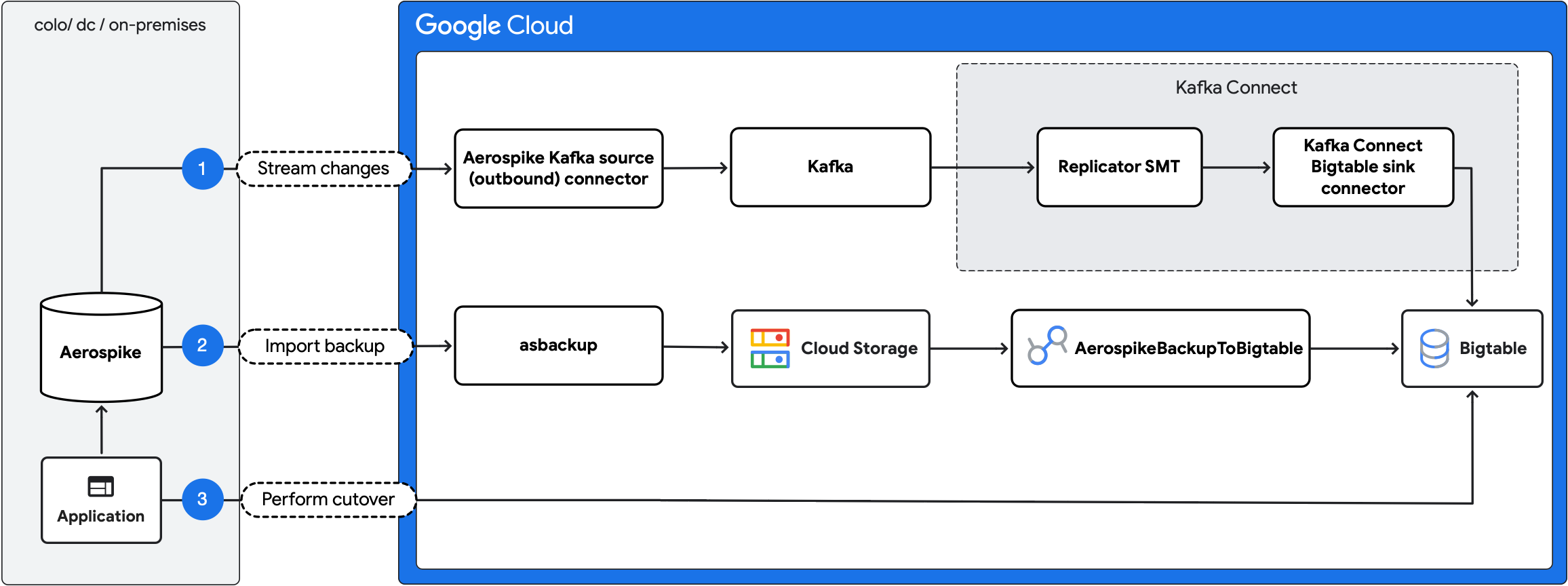
- הזרמת שינויים שוטפים: שכפול של עדכונים שוטפים מ-Aerospike ל-Bigtable באמצעות מחבר המקור (יוצא) של Aerospike Kafka ומחבר היעד של Kafka Connect Bigtable.
- ייבוא גיבוי: יצירת גיבוי של Aerospike וייבוא שלו ל-Bigtable באמצעות משימת
AerospikeBackupToBigtableDataflow. - ביצוע מעבר חד למערכת אחרת (cutover): העברת תעבורת הנתונים של האפליקציה אל Bigtable.
היקף המיגרציה ותאימות
מכיוון ש-Bigtable פועל על בסיס בייטים גולמיים ולא על בסיס סלים מוקלדים, תהליך ההעברה כולל מיפוי של היכולות והתכונות של Aerospike למבנים תואמים של Bigtable. ספריית המתאמים מספקת את הכלים הדרושים כדי להשיג תאימות מבנית ולטפל בפערים, כמו סריאליזציה של אובייקטים. עם זאת, אי אפשר להעביר תכונות מסוימות, כמו פונקציות שהוגדרו על ידי המשתמש (UDF), בגלל הבדלים מהותיים בין המערכות.
בטבלה הבאה מפורט סיכום של אופן הטיפול ביכולות של Aerospike בתהליך ההעברה.
| תכונה | תמיכה | תיאור |
|---|---|---|
| ארכיטקטורת זיכרון היברידית (HMA) של Aerospike | נתמך | הועברו לרמת האחסון SSD או לרמת האחסון בזיכרון. מהדורת Bigtable Enterprise Plus מספקת גישה לאחסון בזיכרון לעומסי עבודה שרגישים לזמן האחזור ודורשים זמני תגובה של פחות ממילי-שנייה, בדומה לביצועים של Aerospike. |
סקלרים (Int, Float, String, Bool) |
נתמך | הועבר לתאים ב-Bigtable. |
| רשימות ומפות | נתמך | למפות חייבים להיות מפתחות מחרוזת. ספריות המתאמים מבצעות סריאליזציה של רשימות ומפות לעמודות נפרדות. |
| אינדקסים משניים | יש תמיכה חלקית | לא מועבר ישירות. צריך להטמיע מחדש את התכונה כאינדקסים משניים אסינכרוניים. |
| אורך חיים (TTL) ברמת הרשומה | נתמך | מוגדר ברמת משפחת העמודות או מודמה לכל תא ב-Bigtable. |
| UDFs | לא נתמך | צריך להעביר את הלוגיקה המותאמת אישית בצד השרת לאפליקציה בצד הלקוח. |
| HyperLogLog | לא נתמך | לא נתמך בתהליך ההעברה. |
| GeoJSON | לא נתמך | לא נתמך בתהליך ההעברה. |
| Record keys | לא נתמך | רשומות מפתח לא מועברות ישירות. במקום זאת, בתהליך ההעברה נעשה שימוש בתקציר הרשומה כמפתח השורה. |
לפני שמתחילים
לפני שמתחילים בהעברה, כדאי לבצע את השלבים הבאים כדי לצמצם את הסיכון ולהבטיח מעבר חלק:
- אימות הנתונים: מוודאים שהפריסה של Aerospike לא מסתמכת על סוגי נתונים, אינדקסים משניים או פונקציות UDF שלא נתמכים. כאמצעי הגנה, אתם יכולים לייבא קבוצת משנה מייצגת של הנתונים ל-Bigtable ולאמת את עיצוב הסכימה.
- הקצאת תשתית: הגדרת השירותים שנדרשים לצינור העברת הנתונים: Bigtable, Kafka ו-Kafka Connect.
- תכנון קיבולת: הקצאת קיבולת מספקת ל-Bigtable כדי לטפל בעומס העבודה הצפוי. בוחרים אזור שקרוב לאשכול Aerospike הקיים. המאמר הסבר על הביצועים של Bigtable כולל הנחיות להערכת המשאבים הנדרשים.
- רמת אחסון: לעומסי עבודה שדורשים זמני תגובה של פחות מאלפית השנייה, כדאי להשתמש ברמת האחסון בזיכרון של Bigtable. בדרגה הזו הנתונים נשמרים ב-RAM כדי לספק את הביצועים הכי טובים לאפליקציות שדורשות הרבה פעולות קריאה או רגישות לזמן האחזור. מידע נוסף מופיע במאמר בנושא סקירה כללית על רמת ביניים בזיכרון.
- הגדרת גישה ורשת: הקצאת תפקידים מתאימים של ניהול זהויות והרשאות גישה (IAM) ווידוא קישוריות לרשת.
- הפעלת מעקב ודיווח שגיאות: הגדרת יכולת צפייה בסביבה החדשה, כולל רישום ביומן, מדדים והתראות.
- השוואה לביצועים בסיסיים: תיעוד של ביצועי המערכת הנוכחיים כדי לספק נקודת השוואה לאימות הביצועים אחרי ההעברה.
- יצירת גיבויים: יצירת גיבוי מלא של נתוני Aerospike.
- הפעלת העברה לצורך בדיקה: מומלץ לאמת את ההגדרה בסביבת פיתוח לפני שמנסים לבצע העברה בסביבת ייצור.
העברת נתונים
כדי להעביר את הנתונים מ-Aerospike ל-Bigtable, צריך לבצע את השלבים הבאים.
הפעלת שינוי השידור
כשמפעילים את זרם השינויים של Aerospike, מחבר המקור (יוצא) של Aerospike Kafka מתחיל לפרסם את העדכונים של רשומת Aerospike בנושא Kafka. מוודאים של-Kafka יש מספיק קיבולת אחסון כדי לשמור את השינויים במאגר זמני, ומגדירים את המחבר כך שיפיק נתונים בפורמט JSON.
הדוגמה הבאה היא של הגדרת מחבר Kafka:
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
כדי לתקשר עם Kafka באמצעות מחבר המקור של Aerospike Kafka (יוצא), נדרש שכפול בין מרכזי נתונים (XDR) של Aerospike, שמשכפל באופן אסינכרוני שינויים באשכולות באמצעות קישורים עם חביון גבוה יותר. XDR זמין רק במהדורת Aerospike Enterprise. אם אתם משתמשים במהדורת הקהילה של Aerospike, אתם צריכים לעבור למהדורת Enterprise או לבצע העברה אופליין באמצעות AerospikeBackupToBigtable Dataflow job בלבד.
הגדרת XDR לדוגמה ב-Aerospike נראית כך:
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
ייצוא נתונים מ-Aerospike
אחרי שמתחילים את שינוי הסטרימינג, צריך ליצור גיבוי של מערך הנתונים הקיים ב-Aerospike. אפשר להשתמש בכלי שורת הפקודה asbackup כדי ליצור גיבויים מאשכול מסדי נתונים של Aerospike. יכול להיות שחלק מהעדכונים יופיעו גם בגיבוי וגם בפיד השינויים. זה צפוי ולא משפיע על ההעברה. כדי לאפשר ייבוא מקביל במהלך השחזור, צריך לפצל את הגיבויים לכמה קבצים.
ייבוא נתונים ל-Bigtable
כדי לייבא נתונים שגובו ל-Bigtable:
- מעלים את הגיבוי לקטגוריה של Cloud Storage.
- מריצים את משימת
AerospikeBackupToBigtableDataflow כדי לייבא את הגיבוי ל-Bigtable. אם הגיבוי מפולח לכמה קבצים, העיבוד של הקבצים מתבצע במקביל. כדי להתמודד עם עומס הכתיבה המוגבר ולשמור על תפוקה אופטימלית, צריך להקצות משאבים נוספים של Bigtable.
החלת העדכונים ברשומה על Bigtable
אחרי שמייבאים את הגיבוי ל-Bigtable, צריך להחיל את העדכונים של הרשומות שנשמרו בזיכרון המטמון ב-Kafka על Bigtable באמצעות Kafka Connect Bigtable sink connector.
תרגום הודעות לפורמט תואם
כלי ההעברה של Aerospike כוללים את Replicator SMT, שפועל בתוך Kafka Connect. הכלי לשכפול מתרגם הודעות שפורסמו על ידי מחבר המקור של Aerospike Kafka (דואר יוצא) לפורמט שתואם ליעד שכותב את הרשומות ל-Bigtable. התרגום נדרש כי מקור הנתונים מצפה לקבל נתונים בפורמט ספציפי ששונה מהפורמט שבו Aerospike מעביר שינויים בסטרימינג.
הטבלה הבאה עוזרת להעריך את משאבי המכונה שנדרשים כדי להשיג נפח נתונים מסוים:
| מבנה הרשומה | תפוקה | זמן אחזור p99 |
|---|---|---|
| ללא שינוי | עד 3,700 רשומות בשנייה לכל vCPU | 300 אלפיות השנייה |
| Nested | עד 2,600 רשומות בשנייה לכל vCPU | 300 אלפיות השנייה |
ההערכות האלה מבוססות על ההנחה שגודל הרשומות בפורמט JSON הוא 1KB. זמן הניתוח עולה ככל שמבני ההודעות מורכבים יותר, כלומר ניתוח של אובייקטים מוטמעים שמאוחסנים ברשומות של Aerospike לוקח יותר זמן.
אפשר להשתמש במדד consumer_lag כדי לבדוק כמה הודעות נמצאות בתור לעיבוד ולמדוד את השהיית השכפול. כשהיעד מעבד את ההודעות שנותרו בנושא, הפיגור של הצרכן יורד עד שהוא מתייצב קרוב לאפס. בשלב הזה, היעד מעבד את העדכונים של Aerospike כמעט בזמן אמת, ואתם מוכנים למעבר. אפשר להשתמש בsink-record-active-count כדי לאמת את מספר ההודעות שכבר עברו עיבוד.
הטמעה של הודעות באמצעות מחבר Kafka Connect Bigtable sink
מחבר היעד Kafka Connect Bigtable מעביר הודעות מ-Kafka ל-Bigtable. כשמגדירים את המחבר, צריך להגדיר את insert.mode ל-REPLACE_IF_NEWEST כדי לוודא שהרשומה שנכתבת לשורת היעד ב-Bigtable היא העדכנית ביותר. מידע נוסף זמין במאמר הגדרת מחבר יעד של Kafka Connect Bigtable.
בטבלה הבאה מפורטות הנחיות לגבי זמן האחזור שנוסף ומשאבי המחשוב שנדרשים לסוגים שונים של עומסי עבודה:
| מבנה הרשומה | תפוקה | זמן אחזור p99 |
|---|---|---|
| ללא שינוי | עד 3,700 רשומות בשנייה לכל vCPU | 74 אלפיות השנייה |
| Nested | עד 3,700 רשומות בשנייה לכל vCPU | 100 אלפיות השנייה |
ההערכות האלה מבוססות על ההנחה שגודל הרשומות בפורמט JSON הוא 1KB. זמן האחזור שמדווח הוא זמן העיבוד ב-sink. צריך להניח שיש תקורה נוספת של כ-600 אלפיות השנייה ליצירת בקשת כתיבה ל-Bigtable.
מעבר ל-Bigtable
מעבירים את האפליקציה לשימוש ב-Bigtable כמסד הנתונים הראשי.
כדי להבטיח עקביות של קריאה וכתיבה, צריך להשבית את האפליקציה באופן זמני עד שהשהיית השכפול תגיע לאפס. כך אפשר לוודא שלא יאבדו מוטציות ושהנתונים ישקפו את המצב העדכני ביותר.
לדוגמה, יכול להיות שמוטציה שהוחלה ב-Aerospike ממש לפני המעבר לא תשוכפל עדיין ל-Bigtable, ולכן יתקבלו קריאות של נתונים לא עדכניים. כדי למנוע את התרחיש הזה, צריך להשאיר את האפליקציה במצב אופליין עד שהמדדים consumer_lag ו-sink-record-active-count יגיעו ל-0. אחרי שכל השינויים בהמתנה יתעדכנו, מפעילים מחדש את האפליקציה עם Bigtable כמאגר הנתונים הראשי.
בעוד שמיגרציה פעילה יכולה למנוע זמן השבתה, היא מגיעה עם המגבלות הבאות:
- מוטציות שמוחלות ב-Bigtable לא משוכפלות בחזרה ל-Aerospike.
- יכול להיות ששינויים שמקורם ב-Aerospike יופיעו ב-Bigtable באיחור.
- מוטציות מושהות מ-Aerospike יכולות לדרוס עדכונים חדשים יותר ב-Bigtable.
אימות הפריסה
אחרי הפריסה, בודקים את ביצועי האפליקציה על ידי עיון במדדים כמו שיעורי שגיאות, זמן אחזור ועלות. אפשר גם לבצע בדיקות תקינות נתונים.
מעקב וניראות
במהלך ההעברה, כדאי לעקוב אחרי המדדים הבאים:
- Total lag: מחושב כ-Kafka consumer lag ועוד
sink-record-active-count. המדדים האלה מציינים את הפער בין Bigtable לבין Aerospike. נדרש ערך יציב של השהיה לפני שמנתבים מחדש את התנועה אל Bigtable. - ניצול המעבד (CPU) והזיכרון: מעקב אחרי ניצול המעבד והזיכרון של כל רכיבי צינור הנתונים של זרם השינויים.
- קיבולת האחסון של Kafka: מעקב אחר הקיבולת של פריסות Kafka בניהול עצמי. אם נפח האחסון יתמלא, לא תהיה אפשרות לשמור אירועים חדשים בזיכרון הזמני, ולכן ההעברה תיכשל.
- שיעורי שגיאות באפליקציה: מעקב אחרי שיעורי השגיאות והפלט של השגיאות בכל רכיבי צינור הנתונים של זרם השינויים.
מגבלות
בקטעים הבאים מפורטות המגבלות שצריך לקחת בחשבון כשמעבירים נתונים מ-Aerospike ל-Bigtable.
עקביות בנתונים במהלך ההעברה
כשמשתמשים בכלי asbackup כדי ליצור את הגיבוי של Aerospike, יכול להיות שרשומות ששונו במהלך תהליך הגיבוי לא ייכללו בו, כי תהליך הגיבוי לא תומך בגיבויים אטומיים. המגבלה הזו לא משפיעה על הנכונות כי כל השינויים מופיעים בזרם השינויים.
במהלך ייבוא הגיבוי ל-Bigtable, כל שורה נכתבת עם חותמת זמן של זמן העדכון האחרון (LUT) של 0.
העדכונים מזרם השינויים מוחלים על הגיבוי המיובא. שורות שנכתבות מהסטרימינג משתמשות בערך LUT כחותמת הזמן של השורה ב-Bigtable. ההגדרה של יעד הנתונים גורמת לכך שעדכון עם חותמת זמן חדשה יותר יחליף עדכון עם חותמת זמן ישנה יותר. כך אפשר לוודא שכל שינוי שמופעל מחדש מהזרם יחליף את השורה המתאימה.
שימוש ב-LUT
תהליך ההעברה משתמש ב-Aerospike XDR כדי לשכפל שינויים, ומסתמך על LUT לפתרון קונפליקטים. טבלאות LUT מבוססות על שעון המערכת של הצומת, ולכן יכול להיות שהן לא מונוטוניות לחלוטין. כתוצאה מכך, יכול להיות שלרשומה לא פעילה יהיה מדי פעם LUT חדש יותר, והיא תדרוס רשומה עדכנית יותר. בנוסף, יכול להיות שהמחבר של מקור Aerospike Kafka (יוצא) לא ישמור על הסדר המדויק של ההודעות בזמן הפרסום ב-Kafka. כתוצאה מכך, טבלת ה-LUT משמשת כסמן הגרסה הסמכותי, ומבטיחה שרק רשומות עם טבלת ה-LUT העדכנית ביותר יוחלו על Bigtable.
אם רשומה מתעדכנת אחרי שמתחילים את שינוי הנתונים אבל לפני שיוצרים את הגיבוי, יכול להיות שהגיבוי יכלול את הגרסה החדשה יותר, בזמן ששינוי הנתונים יכלול גרסה ישנה יותר. יכול להיות שהגרסה הישנה יותר תחליף באופן זמני את הגרסה החדשה יותר. עם זאת, כשהאירוע הבא בזרם עם ה-LUT הנכון מגיע, הגרסה האחרונה משוחזרת. כדי למנוע חוסר עקביות, כדאי להמתין עד שהשכפול יתייצב וההודעה הכי ישנה שלא עברה עיבוד בצינור העיבוד תהיה חדשה יותר מהגיבוי, לפני שמבצעים את המעבר.
אימות נתונים
בצינור ההעברה לא מתבצעת בדיקת סכום ביקורת של נתונים במעבר. אם אתם צריכים לבצע בדיקות של תקינות הנתונים מקצה לקצה, אתם צריכים להטמיע אימות.
פתרון בעיות
בקטעים הבאים מתוארות שגיאות נפוצות שעשויות להתרחש במהלך תהליך ההעברה, ומוסבר איך לפתור אותן.
שגיאות בייבוא גיבוי
במהלך הייבוא של הגיבוי של Aerospike אל Bigtable, יכול להיות שתיתקלו בשגיאות הבאות:
| סוג השגיאה | מטרה | פתרון |
|---|---|---|
| קובץ גיבוי פגום | קבצי הגיבוי לא קריאים או שהם מכילים רשומות פגומות. משימת הייבוא נכשלת. | בודקים את הקבצים המושפעים כדי לזהות בעיות בשלמות שלהם. אם אי אפשר לשחזר את הגיבוי, צריך ליצור גיבוי חדש ולחזור על הייבוא. |
| כשלים בכתיבה ב-Bigtable | בעיות בקישוריות או בשירות של Bigtable. הייבוא לא נכשל. | רשומות שנכשלו מיוצאות לקובץ פלט שגיאות בפורמט JSON. צריך להחיל אותן מחדש באופן ידני או לנסות שוב את עבודת הייבוא המלאה. |
| נתונים לא נתמכים | הגיבוי מכיל רשומות שלא ניתן לייבא ל-Bigtable. הייבוא לא נכשל. | נתונים שלא נתמכים, כמו פונקציות שהוגדרו על ידי המשתמש (UDF), מדווחים כאזהרות ביומני העבודות. בודקים את היומנים כדי לוודא שאין רשומות שלא נתמכות. |
אחרי שהייבוא של הגיבוי מסתיים והרשומות הלא תקינות מטופלות, אפשר להמשיך ולהחיל את זרם השינויים.
שגיאות בשינוי השידור
במהלך היישום של שינוי הנתונים, יכולות להתרחש שגיאות ברמות הבאות:
- שגיאות Replicator SMT: SMT נכשל בהמרת הנתונים שנוצרו על ידי Aerospike.
- שגיאות ביעד: אי אפשר להחיל אירועים על Bigtable.
בשני המקרים, אירועים שנכשלו מופנים מחדש לנושא ייעודי ב-Kafka. אפשר לרשום את האירועים ביומן לצורך ביקורת או לעבד אותם באמצעות לוגיקה מותאמת אישית לשחזור.
המאמרים הבאים
- איך מעצבים את הסכימה של Bigtable
- כאן Google Cloud אפשר לקרוא איך להתחיל בהעברה.
- להבין אילו אסטרטגיות יש להעברת מערכי נתונים גדולים.