
Erstellen Sie einen kosteneffizienten Google Kubernetes Engine-Cluster (GKE) und eine Arbeitslast, die für die Ressourcenverwaltung an einem einzelnen Standort optimiert ist. In diesem Leitfaden werden die folgenden Vorlagen beschrieben, mit denen Sie eine einfache Webanwendung bereitstellen können:
GKE-Cluster-Vorlage für eine einzelne Region: Erstellen Sie die grundlegende Infrastruktur, die für eine Anwendung in einer einzelnen Region erforderlich ist. Mit dieser Vorlage wird ein sicherer, privater GKE-Cluster eingerichtet, der für die Ressourcenverwaltung optimiert ist.
GKE-Arbeitslast für eine einzelne Region (Vorschau): Stellen Sie ein Helm-Diagramm bereit, das die Konfiguration für eine einfache Webanwendung enthält. Die Arbeitslast ist so konfiguriert, dass sie basierend auf der CPU-Last skaliert wird und die Verfügbarkeit der Anwendung bei freiwilligen Unterbrechungen gewährleistet.
Sie können die Cluster- und Arbeitslastvorlagen beispielsweise verwenden, um die folgenden geschäftlichen Anforderungen zu erfüllen:
| Beispiel | Geschäftliche Anforderung | Implementierung |
|---|---|---|
| Interne Line-of-Business-Anwendung | Für eine interne Anwendung sind eine strenge Datenresidenz in einer bestimmten Region, Kosteneffizienz für die vorhersehbare interne Nutzung und hohe Zuverlässigkeit erforderlich. | Verwenden Sie die Bereitstellung in einer einzelnen Region, um die Datenlokalität zu gewährleisten. Mit Autoscaling können Sie Ressourcen effizient für die Nachfrage interner Nutzer verwalten. |
| Regionales E-Commerce-Back-End | Eine E-Commerce-Plattform erfordert eine Hochverfügbarkeit in einer bestimmten Region, um einen kontinuierlichen Dienst zu gewährleisten, Skalierbarkeit, um Verkehrsspitzen bei Verkaufsveranstaltungen zu bewältigen, und robuste Sicherheit für Kundentransaktionen und -daten. | Eine multizonale Clusterkonfiguration bietet regionale Hochverfügbarkeit. Verwenden Sie die Konfiguration für den sicheren Start, um die Sicherheit für sensible Kundendaten zu erhöhen. |
| Regionale Plattform für Datenverarbeitung und -analyse | Eine Plattform zum Verarbeiten und Analysieren großer Datensätze erfordert Datenlokalität für Compliance und Leistung, kostenoptimierte Rechenleistung für intermittierende Batchjobs und sicheren Zugriff auf Daten. | Die Bereitstellung in einer einzelnen Region sorgt dafür, dass die Daten innerhalb der geografischen Grenzen bleiben. Skalieren Sie Ressourcen für große Verarbeitungsaufgaben und Leerlaufzeiten. |
Architektur
Die folgende Abbildung zeigt die Komponenten und Verbindungen in der Vorlage:
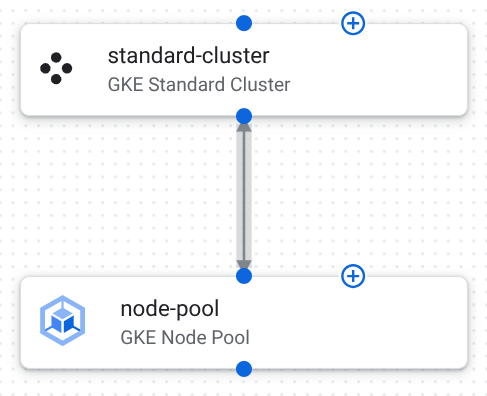
Im Folgenden werden die Komponentenkonfigurationen in dieser Vorlage beschrieben:
GKE Standard-Cluster: Ein kostengünstiger Cluster in einer einzelnen Region, in dem Ihre Arbeitslast ausgeführt wird.
In der folgenden Tabelle wird die Clusterkonfiguration in dieser Vorlage beschrieben:
Konfiguration Zweck locationist aufus-central1gesetzt.Beschränkt Clusterressourcen auf ein einzelnes geografisches Gebiet, sorgt für Datenlokalität und minimiert Kosten und Latenz für die regionenübergreifende Datenübertragung. initial_node_countist auf1gesetzt.Definiert einen anfänglichen Knoten, der im Standardknotenpool des Clusters erstellt werden soll, wenn der Cluster zum ersten Mal bereitgestellt wird. In regionalen Clustern ist dies die Anzahl der Knoten pro Zone. release_channelist auf{"channel":"REGULAR"}gesetzt.Sorgt dafür, dass Ihr GKE-Cluster stabile und vorhersehbare Updates erhält, und bietet ein Gleichgewicht zwischen neuen Funktionen und Zuverlässigkeit. enable_intranode_visibilityist auftruegesetzt.Aktiviert die Sichtbarkeit für den intranodalen Traffic in VPC-Flusslogs, die für die Netzwerküberwachung, Fehlerbehebung und Sicherheitsanalyse erforderlich ist. control_plane_endpoints_configist auf{"dns_endpoint_config":{"allow_external_traffic":true}}gesetzt.Die GKE-Steuerungsebene ist so konfiguriert, dass sie öffentlich zugänglich ist, damit Sie den Cluster außerhalb Ihres VPC-Netzwerks (Virtual Private Cloud) verwalten können. GKE-Knotenpool: Eine Gruppe von Worker-Knoten, auf denen die Container der Anwendung ausgeführt werden.
In der folgenden Tabelle werden die Knotenpoolkonfigurationen in dieser Vorlage beschrieben:
Konfiguration Zweck locationist aufus-central1gesetzt.Gibt die Region an, in der dieser Knotenpool erstellt wird. Ähnlich wie beim Standort des Clusters sorgt dies dafür, dass sich die Knotenpoolressourcen in einem einzelnen geografischen Gebiet befinden. autoscalingist auf{"max_node_count":3, "min_node_count":1}gesetzt.Konfiguriert den Cluster Autoscaler für diesen Knotenpool. Sorgt dafür, dass der Knotenpool immer mindestens einen Knoten enthält, und legt die Obergrenze auf drei Knoten fest, um Kosten und Ressourcenverbrauch zu kontrollieren. node_configist auf{"machine_type":"e2-medium", "oauth_scopes":["https://www.googleapis.com/auth/cloud-platform"], "shielded_instance_config":{"enable_secure_boot":true}}gesetzt.Gruppiert Konfigurationen für die Knoten in diesem Pool. Der Maschinentyp bietet ein ausgewogenes Verhältnis von CPU und Arbeitsspeicher und eignet sich für Arbeitslasten für allgemeine Zwecke. Definiert den Zugriff, der dem Dienstkonto gewährt wird. Aktiviert den sicheren Start für die Shielded VM-Instanzen, um sie vor Malware auf Bootebene zu schützen.
Helm-Diagrammkonfiguration
In der folgenden Tabelle sind die Helm-Diagrammkonfigurationen aufgeführt, die für die Bereitstellung und Skalierung einer einfachen Webanwendung in GKE angepasst wurden.
| Konfiguration | Zweck |
|---|---|
replicaCount: 2 |
Erstellt zwei anfängliche Replikate, um ein anfängliches Maß an Redundanz zu schaffen. |
image.repository: gcr.io/google-samples/hello-app |
Verwendet ein Docker-Image eines einfachen Webservers. |
resources.requests: {"cpu": "100m", "memory": "128Mi"} |
Gibt die Mindestmenge an CPU und Arbeitsspeicher an, die für jeden Pod reserviert sind, und sorgt so für verfügbare Ressourcen und eine effiziente Planung. |
hpa: {"enabled": true, "minReplicas": 2, "maxReplicas": 10, "targetCPUUtilizationPercentage": 60} |
Aktiviert den Horizontal Pod Autoscaler, um die Anzahl der Pods basierend auf der CPU-Auslastung automatisch zwischen 2 und 10 anzupassen und so Leistung und Kosteneffizienz zu gewährleisten. |
service: {"type": "ClusterIP", "port": 80} |
Konfiguriert den Dienst für den internen Zugriff innerhalb des Clusters über den Standard-HTTP-Port. |
pdb: {"enabled": true, "minAvailable": 1} |
Aktiviert ein Budget für Pod-Störungen, um sicherzustellen, dass bei freiwilligen Unterbrechungen mindestens ein Replikat verfügbar bleibt und so eine Hochverfügbarkeit gewährleistet wird. |
Webanwendung erstellen
Verwenden Sie die Vorlagen GKE-Cluster und Arbeitslast für eine einzelne Region, um Ihre Webanwendung bereitzustellen.
Webinfrastruktur bereitstellen
Konfigurieren und stellen Sie die Vorlage GKE-Cluster für eine einzelne Region bereit, um die grundlegende Infrastruktur zu erstellen, in der Ihre Webarbeitslast ausgeführt wird.
Duplizieren und stellen Sie die Vorlage GKE-Cluster für eine einzelne Region als Anwendung bereit.
Im ausgewählten Bereitstellungsprojekt wird ein GKE-Cluster erstellt.
Konfigurieren Sie die Komponenten. Hier finden Sie weitere Informationen:
Klicken Sie auf Bereitstellen. Die Bereitstellung der Anwendung dauert einige Minuten.
Klicken Sie im Bereich Anwendungsdetails auf den Tab Ausgaben.
Suchen Sie die cluster_id für Ihre Anwendung. Sie benötigen diese Informationen, wenn Sie Ihr Helm-Diagramm bereitstellen.
Webarbeitslast bereitstellen
Verwenden Sie die Vorlage GKE-Arbeitslast für eine einzelne Region, um Ihre Webarbeitslast im erstellten Cluster bereitzustellen. Sie stellen ein Helm-Diagramm bereit, das die Konfiguration Ihrer Webarbeitslast enthält.
Klicken Sie auf der Seite Google-Katalog in der Vorlage GKE-Arbeitslast für eine einzelne Region auf Neue Anwendung erstellen.
Geben Sie im Feld Name einen eindeutigen Namen für Ihre Anwendung ein.
Führen Sie im Bereich GKE-Bereitstellungsziel folgende Schritte aus:
Wählen Sie in der Projektliste das Projekt aus, in dem Sie den GKE-Cluster aus Ihrer Anwendung GKE-Cluster für eine einzelne Region bereitgestellt haben.
Wählen Sie in der Liste Region die Region aus, in der Sie den GKE-Cluster bereitgestellt haben.
Wählen Sie in der Liste Cluster den bereitgestellten GKE-Cluster aus.
Geben Sie in der Liste Namespace den Namespace ein, in dem Sie Ihren GKE-Cluster bereitgestellt haben. Wenn Sie den Namen nicht geändert haben, geben Sie
defaultein.Klicken Sie auf Anwendung erstellen.
Die Anwendung wird erstellt und die Konfigurationsdateien werden angezeigt.
Führen Sie im Bereich Helm-Diagramm folgende Schritte aus:
Prüfen Sie die Konfigurationsdetails.
Optional: Passen Sie die Konfiguration an Ihre individuellen Anforderungen an.
Klicken Sie auf Bereitstellen, um das Helm-Diagramm in Ihrem Cluster bereitzustellen.
Eine detaillierte Anleitung finden Sie unter Anwendungen bereitstellen.
Nach einigen Minuten wird die Helm-Diagrammkonfiguration in Ihrem GKE-Cluster bereitgestellt.
Nächste Schritte
- Informationen zum Duplizieren und Anpassen von Vorlagen finden Sie in der Kurzanleitung Google-Vorlage anpassen und bereitstellen.
- Definieren Sie Ihre eigenen Konfigurationen, indem Sie Anwendungsvorlagen entwerfen.
- Im Google Cloud Architektur-Framework finden Sie allgemeine Best Practices für die Architektur.