
Build a generative AI chat application that uses retrieval-augmented generation (RAG) to provide grounded and accurate responses based on your organization's data. This guide describes the Generative AI RAG with Cloud SQL application template, which you can customize to fit your unique needs and deploy as an application.
For example, you might implement this template to address the following business needs:
| Example | Business need | Implementation |
|---|---|---|
| Customer support chatbot | Companies need to provide instant customer support. | Host the chat interface on Cloud Run. Vertex AI processes embeddings and generates responses based on technical documentation stored as vectors in Cloud SQL. |
| Internal HR assistant | Employees need to find information about benefits, company policies, and internal procedures. | Host the HR assistant on Cloud Run. When employees query the tool, Vertex AI retrieves relevant policy information from Cloud SQL to generate accurate, source-grounded answers. |
| Legal document researcher | Legal teams need to quickly find relevant case law or contract clauses across large document repositories. | Host the research portal on Cloud Run. Vertex AI summarizes relevant precedents and identifies specific language in contracts using legal documents stored as vectors in Cloud SQL. |
| Semantic product search | Ecommerce companies want to facilitate product searches using natural language descriptions rather than exact keywords. | Host the search interface on Cloud Run. Vertex AI processes user descriptions to return the most semantically relevant products from product catalogs stored as vectors in Cloud SQL. |
Architecture
The following image shows the components and connections in the application:
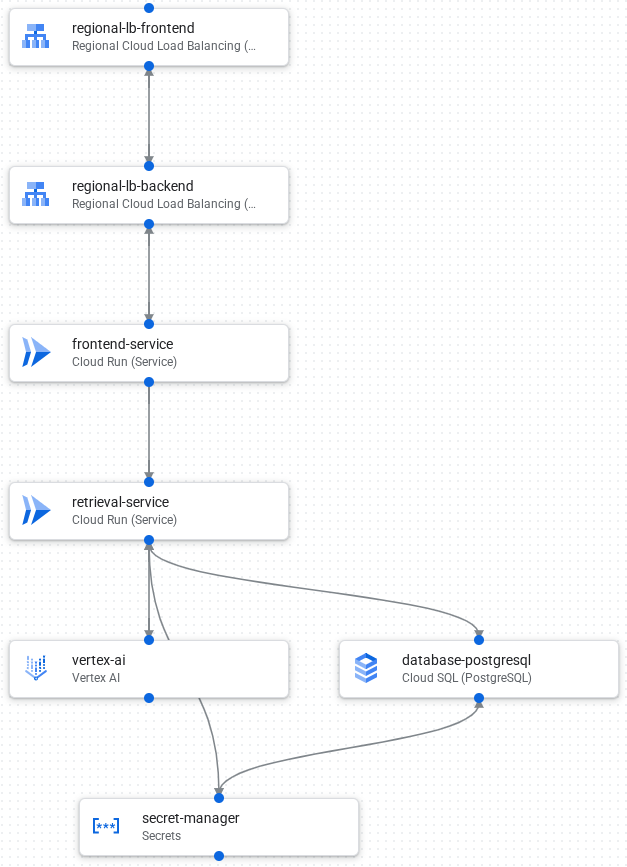
The following is the request processing flow of the application:
- Load data to a PostgreSQL database in Cloud SQL.
- Vertex AI creates embeddings of text fields and stores them as vectors in the database.
- A Cloud Load Balancing frontend receives external requests and distributes traffic to the Cloud Load Balancing backend.
- The Cloud Load Balancing backend distributes traffic to the Cloud Run frontend service.
- The frontend service communicates with a retrieval service for a generative AI call.
- The retrieval service uses Secret Manager to securely access API keys and credentials that are required to access Vertex AI and Cloud SQL.
- The retrieval service converts the request to an embedding and searches for similar vectors in the Cloud SQL database.
- The retrieval service sends results from the search, along with the original prompt, to Vertex AI to create a response.
What's next
- To learn how to duplicate and customize this template, see Quickstart: Customize and deploy a Google template.
- Define your own configurations by designing application templates.
- Identify general architectural best practices with the Google Cloud Architecture Framework.