
To create an AI application, provision a secure, private Google Kubernetes Engine (GKE) cluster optimized for AI workloads, and then deploy your workload using a helm chart. This guide describes the following templates, which you can customize to deploy an AI application:
AI Pre-trained Inference GKE cluster: create the foundational infrastructure required for high-performance model serving. This template sets up a secure, private GKE cluster optimized for AI inference.
AI Pre-trained Inference GKE workload (Preview): deploy a helm chart that includes the configuration for an AI workload. Use the helm chart to deploy a pre-trained Gemma model using the vLLM serving engine. The workload is configured for efficient GPU resource requests and a Horizontal Pod Autoscaler (HPA) to scale based on GPU cache usage.
For example, you might deploy the cluster and workload templates to address the following business needs:
| Example | Business need | Implementation |
|---|---|---|
| Real-time video analysis | A security firm needs to process video streams from hundreds of cameras to detect anomalies or specific objects in real-time. | Deploy video processing models on the GPU-enabled node pool. GPUs can process the high-throughput, low-latency demands of concurrent video streams. |
| Specialized document processing | An insurance company needs to automatically extract information from thousands of daily claim forms, which contain varied layouts and handwriting. | Use the GKE cluster to host custom models, and ensure that data never leaves the secure environment during processing. |
| High-volume recommendation engine | An ecommerce platform needs to serve personalized product recommendations to users during peak holiday shopping events. | Use the Google Kubernetes Engine Gateway API to route high volumes of user traffic to the recommendation models. The Gateway API can handle sudden traffic spikes without latency degradation. |
Architecture
The following image shows the components and connections in the template:
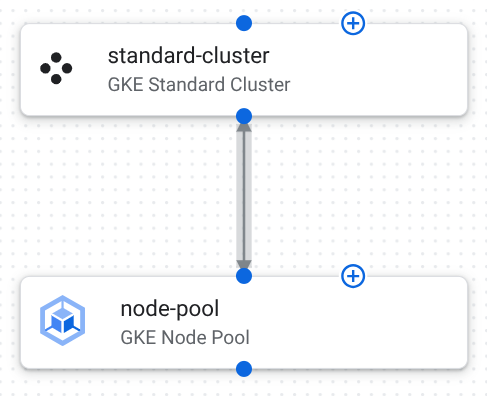
The following describes the component configurations in this template:
GKE Standard cluster: a secure and private cluster where your AI workload runs.
The following table describes the cluster configuration in this template:
Configuration Purpose node_locationsis set to["us-central1-a", "us-central1-b", "us-central1-c"].Ensures high availability and resilience by spreading the cluster's nodes across three zones in the us-central1region.enable_intranode_visibilityis set totrue.Enables visibility for pod-to-pod traffic in the same node in VPC Flow Logs. This visibility is required for network monitoring, troubleshooting, and security analysis. gateway_api_configis enabled using{"channel":"CHANNEL_STANDARD"}.The GKE Inference Gateway API helps you manage ingress traffic to your Kubernetes services. The API helps you configure fine-grained routing, advanced load balancing, and centralized policy attachment. private_cluster_config.enable_private_endpointis set tofalse.private_cluster_config.enable_private_nodesistrue.control_plane_endpoints_config.dns_endpoint_config.allow_external_trafficis set totrue.Ensures that the worker nodes where your AI models run have private IP addresses. This isolates your nodes from the public internet. The GKE control plane is configured to be publicly accessible to let you manage the cluster outside your Virtual Private Cloud (VPC) network. release_channelis set to{"channel":"REGULAR"}.Ensures that your GKE cluster receives stable and predictable updates, providing a balance between new features and reliability. GKE node pool: a group of worker nodes that run the application's containers.
The following table describes the node pool configurations in this template:
Configuration Purpose autoscaling.min_node_countis set to0.autoscaling.max_node_countis set to3(default is100).The node pool can scale down completely when there are no AI workloads running, reducing costs during idle periods. The upper limit for scaling helps control costs and resource consumption. The node_config.guest_acceleratorparameter is added.gpu_driver_installation_config.gpu_driver_version:is set to"LATEST".gpu_sharing_configis enabled withTIME_SHARING.max_shared_clients_per_gpu:is set to2.Specifies the use of NVIDIA L4 GPUs for AI inference tasks. The necessary GPU drivers are automatically installed. Multiple smaller workloads can share a single GPU. node_config.machine_typeis changed to"g2-standard-8".The machine type is specifically designed to complement the L4 GPUs. vCPUs (8) and memory (32 GB) are created to support the GPU and run your AI inference applications. node_config.oauth_scopesincludeshttps://www.googleapis.com/auth/cloud-platform.The node's service account has broad access to Google Cloud services, enabling API interaction for tasks like logging, monitoring, and pulling container images. node_config.shielded_instance_config.enable_secure_bootis set totrue.Secure Boot helps protect your nodes from boot-level malware by verifying the cryptographic signatures of the bootloader and kernel before they execute.
Helm chart configuration
The following table lists the helm chart configurations, which have been customized for deploying and scaling an AI inference service on GKE.
| Configuration | Purpose |
|---|---|
replicaCount: 1 |
Creates a single initial replica. |
image.repository: vllm/vllm-openai |
Uses a vLLM image, an optimized library for Large Language Model (LLM) inference, exposed using an OpenAI-compatible API. |
model.id: google/gemma-7b-it |
Defines the Gemma 7B instruction-tuned model as the model to be served. |
model.hfSecret: hf-secret |
Indicates that the model requires authentication using a Kubernetes Secret for secure credential management. |
resources.limits and requests for nvidia.com/gpu: "1" |
Ensures that each pod gets a dedicated GPU. |
nodeSelector.cloud.google.com/gke-accelerator: nvidia-l4 |
Ensures that your AI model pods are scheduled exclusively on GKE Standard nodes equipped with NVIDIA L4 GPUs, which are ideal for cost-effective and high-performance inference. |
hpa.enabled: true |
Enables Horizontal Pod Autoscaler, which lets the application automatically scale the number of pods (between minReplicas: 1 and maxReplicas: 10) based on targetCPUUtilizationPercentage: 80%. Ensures performance during peak loads and cost efficiency during low usage. |
tensorParallelSize: 1 |
Indicates that the model is not split across multiple GPUs within a single pod. |
maxModelLen: 512 |
Controls the maximum sequence length that the Gemma 7B model can process. |
service.type: ClusterIP |
The service is configured for internal access within the cluster. |
pdb.enabled: true and minAvailable: 1 |
A Pod Disruption Budget is enabled to ensure high availability. At least one replica of your AI model remains available during voluntary disruptions like node maintenance. |
Create your AI application
Use the AI Pre-trained Inference GKE cluster and workload templates to deploy your AI application.
Deploy your AI infrastructure
Configure and deploy the AI Pre-trained Inference GKE cluster template to create the foundational infrastructure where your AI workload runs.
Duplicate and deploy the AI Pre-trained Inference GKE cluster template as an application.
A GKE cluster is created in the deployment project that you choose.
Configure the components. For more information, see the following:
Click Deploy. The application deploys after several minutes.
In the Application details panel, click the Outputs tab.
Identify the cluster_id for your application. You'll use this information when you deploy your helm chart.
Deploy your AI workload
Use the AI Pre-trained Inference GKE workload template to deploy your AI workload into the cluster you created. You'll deploy a helm chart that includes your AI workload configuration.
From the Google catalog page, on the AI Pre-trained Inference GKE workload template, click Create new application.
In the Name field, enter a unique name for your application.
In the GKE Deployment Target area, do the following:
From the Project list, select the project where you deployed the GKE cluster from your AI Pre-trained Inference GKE cluster application.
From the Region list, select the region where you deployed the GKE cluster.
From the Clusters list, select the deployed GKE cluster.
From the Namespace list, enter the namespace where you deployed your GKE cluster. If you didn't change the name, enter
default.Click Create application.
The application is created and the configuration files are displayed.
In the Helm chart panel, do the following:
Review the configuration details.
Optional: customize the configuration to meet your unique needs.
To deploy the helm chart to your cluster, click Deploy.
For detailed steps, see Deploy applications.
After several minutes, the helm chart configuration deploys to your GKE cluster.
What's next
- To learn how to duplicate and customize templates, see Quickstart: Customize and deploy a Google template.
- Define your own configurations by designing application templates.
- Identify general architectural best practices with the Google Cloud Architecture Framework.