
תמלול קולי מאפשר לכם להמיר את נתוני האודיו בסטרימינג לטקסט מתומלל בזמן אמת. ההצעות של Agent Assist מבוססות על טקסט, ולכן צריך להמיר נתוני אודיו לפני שאפשר להשתמש בהם. אפשר גם להשתמש באודיו בסטרימינג עם תמליל ב-Customer Experience Insights כדי לאסוף נתונים בזמן אמת על שיחות עם נציגים (לדוגמה, Topic Modeling).
יש שתי דרכים לתמלל אודיו בסטרימינג לשימוש ב-Agent Assist: באמצעות התכונה SIPREC, או באמצעות ביצוע קריאות gRPC עם נתוני אודיו כמטען ייעודי (payload). בדף הזה מתואר תהליך התמלול של נתוני אודיו בסטרימינג באמצעות קריאות gRPC.
תמלול קולי פועל באמצעות הזרמת דיבור לזיהוי דיבור. ב-Speech-to-Text יש כמה מודלים של זיהוי, רגילים ומשופרים. Agent Assist לא מגביל את המודלים שבהם אפשר להשתמש עם תמלול קולי, אבל תמלול קולי נתמך ברמת הזמינות הכללית רק כשמשתמשים בו עם מודל הטלפוניה או עם Chirp 3. כדי לקבל תמליל באיכות אופטימלית, מומלץ להשתמש במודל Chirp 3, בכפוף לזמינות אזורית.
דרישות מוקדמות
- יצירת פרויקט ב-Google Cloud.
- הפעלת Dialogflow API.
- כדי לוודא שיש לחשבון שלכם גישה למודלים משופרים של Speech-to-Text, צריך לפנות לנציג Google.
יצירת פרופיל שיחה
כדי ליצור פרופיל שיחה, משתמשים במסוף Agent Assist או מתקשרים ישירות לשיטת create במשאב ConversationProfile.
לגבי תמלול קולי, מומלץ להגדיר את ConversationProfile.stt_config כברירת המחדל InputAudioConfig כששולחים נתוני אודיו בשיחה.
![]()
קבלת תמלילים במהלך השיחה
כדי לקבל תמלילים בזמן הריצה של השיחה, צריך ליצור משתתפים לשיחה ולשלוח נתוני אודיו לכל משתתף.
יצירת משתתפים
יש שלושה סוגים של משתתפים.
פרטים נוספים על התפקידים מופיעים במאמרי העזרה. מבצעים קריאה ל-create ב-participant ומציינים את role. רק משתמשים עם מינוי ל-END_USER או משתתפים בשיחה ב-HUMAN_AGENT יכולים להתקשר אל StreamingAnalyzeContent, שנדרש כדי לקבל תמליל.
שליחת נתוני אודיו וקבלת תמליל
אפשר להשתמש ב-StreamingAnalyzeContent כדי לשלוח את האודיו של המשתתף ל-Google ולקבל תמליל, עם הפרמטרים הבאים:
הבקשה הראשונה בשידור חייבת להיות
InputAudioConfig. (השדות שמוגדרים כאן מבטלים את ההגדרות התואמות ב-ConversationProfile.stt_config.) אל תשלחו קלט אודיו עד לבקשה השנייה.- הערך של
audioEncodingצריך להיותAUDIO_ENCODING_LINEAR_16אוAUDIO_ENCODING_MULAW. -
model: זהו מודל הדיבור לטקסט שבו רוצים להשתמש כדי לתמלל את האודיו. מגדירים את השדה הזה לערךchirp_3. הווריאנט לא משפיע על איכות התמלול, ולכן אפשר לא לציין ווריאנט של מודל דיבור או לבחור באפשרות שימוש בטוב ביותר שזמין. - כדי לקבל את איכות התמלול הטובה ביותר, צריך להגדיר את הערך של
singleUtteranceל-false. לא צפויEND_OF_SINGLE_UTTERANCEאםsingleUtteranceהואfalse, אבל אפשר להסתמך עלisFinal==trueבתוךStreamingAnalyzeContentResponse.recognition_resultכדי לסגור את הסטרים באופן חלקי. - פרמטרים אופציונליים נוספים: הפרמטרים הבאים הם אופציונליים. כדי לקבל גישה לפרמטרים האלה, צריך לפנות לנציג Google.
-
languageCode:language_codeשל האודיו. ערך ברירת המחדל הואen-US. -
alternativeLanguageCodes: התכונה הזו זמינה רק ברמת GA עבור מודל Chirp 3. שפות נוספות שאולי מזוהות באודיו. Agent Assist משתמש בשדהlanguage_codeכדי לזהות באופן אוטומטי את השפה בתחילת האודיו, וזו השפה שמוגדרת כברירת מחדל בכל תורות השיחה הבאות. בשדהalternativeLanguageCodesאפשר לציין עוד אפשרויות ש-Agent Assist יכול לבחור מתוכן. -
phraseSets: שם המשאב של התאמת מודל Speech-to-TextphraseSet.- כדי להגדיר התאמה למודל Chirp 3, מוסיפים ביטויים מוטבעים שמופרדים על ידי שורות חדשות, בלי פסיקים.
- כדי להשתמש בהתאמת מודל עם מודלים אחרים כמו
telephonyלתמלול קולי, קודם צריך ליצור אתphraseSetבאמצעות Speech-to-Text API ולציין כאן את שם המשאב.
-
- הערך של
אחרי ששולחים את הבקשה השנייה עם מטען ייעודי (payload) של אודיו, אמורים להתחיל לקבל נתונים מסוימים
StreamingAnalyzeContentResponsesמהסטרימינג.- אפשר לסגור חצי מהסטרימינג (או להפסיק את השליחה בשפות מסוימות כמו Python) כשרואים ש-
is_finalמוגדר ל-trueב-StreamingAnalyzeContentResponse.recognition_result. - אחרי שסוגרים את הסטרימינג באופן חלקי, השרת ישלח בחזרה את התגובה שמכילה את התמליל הסופי, יחד עם הצעות אפשריות של Dialogflow או של Agent Assist.
- אפשר לסגור חצי מהסטרימינג (או להפסיק את השליחה בשפות מסוימות כמו Python) כשרואים ש-
אפשר למצוא את התמליל הסופי במיקומים הבאים:
StreamingAnalyzeContentResponse.message.content.- אם מפעילים התראות ב-Pub/Sub, אפשר לראות את התמליל גם ב-Pub/Sub.
צריך להתחיל שידור חדש אחרי שהשידור הקודם נסגר.
- שליחה מחדש של אודיו: נתוני אודיו שנוצרו אחרי
speech_end_offsetשל התגובה עםis_final=trueעד לזמן ההתחלה של הסטרימינג החדש צריכים להישלח מחדש אלStreamingAnalyzeContentכדי לקבל את איכות התמלול הטובה ביותר.
- שליחה מחדש של אודיו: נתוני אודיו שנוצרו אחרי
בתרשים הבא מוצג אופן הפעולה של הזרם.
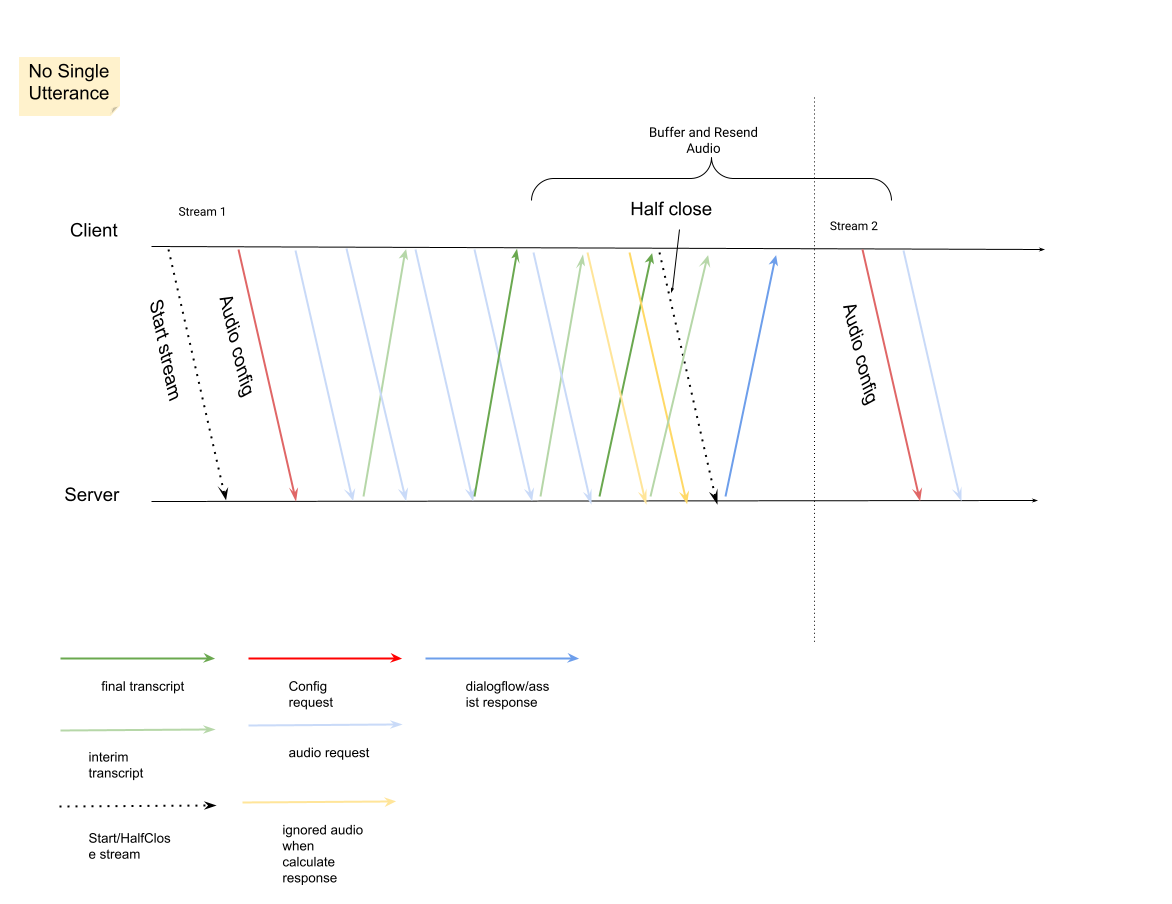
דוגמה לקוד של בקשת זיהוי סטרימינג
בדוגמת הקוד הבאה אפשר לראות איך לשלוח בקשה לסטרימינג של תמלול.
Python
כדי לבצע אימות ב-Agent Assist, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
כדי לראות את קובצי ה-Python של conversation_management ושל participant_management:
עוברים למאגר GitHub של מסמכי Python.
לוחצים על מעבר לקובץ ומזינים את שם הקובץ:
conversation_managementאוparticipant_management.לוחצים על Enter.
שיטות מומלצות
זמן שליחת ההודעה הוא הזמן שבו מתחילה אמירה. אפשר להשתמש בזמן שליחת ההודעה כדי לקבוע את הסדר שבו מרכז שירות הלקוחות מציג או מנתח הודעות קוליות.