
התכונה 'Knowledge Assist גנרטיבי' מספקת תשובות לשאלות של הנציג על סמך מידע במסמכים שאתם מספקים. אתם יכולים לציין את שם הדומיין או להעלות מסמכים עבור סוכן של מאגר נתונים מבוסס-זרימה או סוכן של מאגר נתונים מבוסס-פלייבוק. התכונה 'Knowledge Assist גנרטיבי' מסכמת את המידע הזה עם השיחה המתנהלת ומטא-נתונים זמינים של הלקוח, כדי לספק תשובה רלוונטית יותר לסוכן בזמן אמת.
לפני שמתחילים
אם אתם לא בעלי הפרויקט, אתם צריכים את התפקידים הבאים כדי ליצור סוכן של מאגר נתונים:
- Dialogflow API Admin
- Discovery Engine Admin
יצירת סוכן מאגר נתונים מבוסס-זרימה
מפעילים את AI Applications API במסוף Vertex AI.
כדי ליצור את הסוכן, פועלים לפי השלבים שמפורטים במאמר בנושא סוכני מאגר נתונים מבוססי-Flow.
יצירת סוכן מאגר נתונים מבוסס-פלייבוק
מפעילים את AI Applications API במסוף Vertex AI.
כדי ליצור את הסוכן, פועלים לפי השלבים שמפורטים במאמר סוכני מאגר נתונים שמבוססים על תוכנית פעולה.
כדי לחבר את הסוכן למאגר נתונים, צריך ליצור כלי למאגר נתונים. למידע נוסף, אפשר לעיין בדוגמאות לשימוש בכלי של מאגר נתונים של תוכניות פעולה.
מענה לשאלות מהסוכנים האנושיים
הנציג של מאגר הנתונים שמבוסס על תרשים זרימה או על מדריך הפעלה יכול לענות על השאלות של הנציגים האנושיים שלכם על סמך המסמכים שסיפקתם.
שלב 1: יצירת פרופיל שיחה
יוצרים פרופיל שיחה באמצעות מסוף Agent Assist או ממשק ה-API.
יצירה דרך המסוף
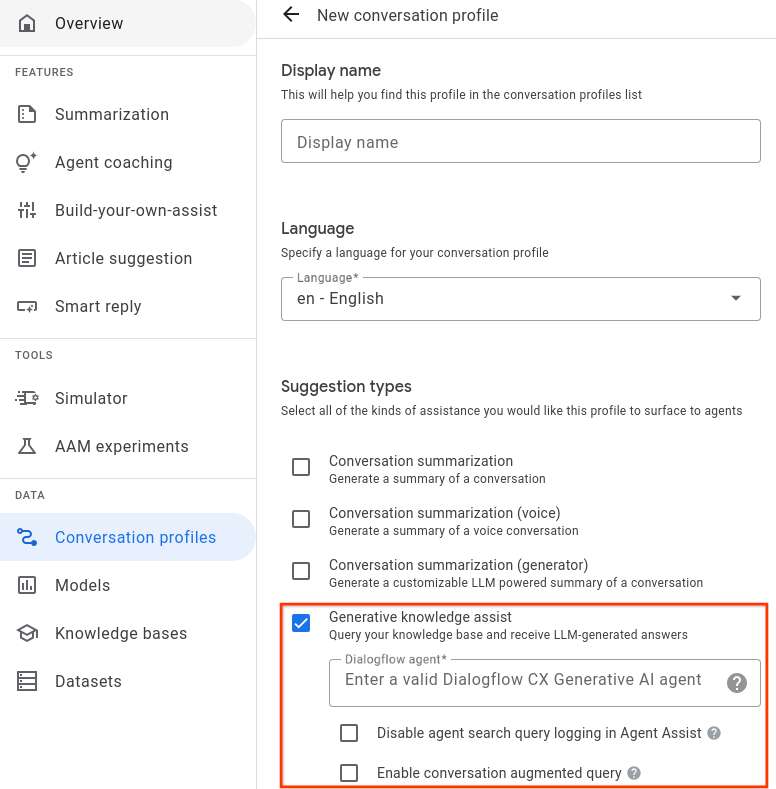
- צריך להפעיל את סוג ההצעה Knowledge Assist ולקשר אותה לסוכן ממאגר הנתונים מבוסס-הזרימה או מבוסס-הפלייבוק מהשלב הקודם.
- אופציונלי: מסמנים את התיבה השבתת רישום ביומן של שאילתות חיפוש של סוכנים כדי לציין אם רוצים ש-Google תאסוף ותאחסן שאילתות חיפוש עם צנזורה לצורך שיפור איכות פוטנציאלי.
- אפשר לסמן את התיבה הפעלת שאילתה משופרת לשיחה כדי לציין אם רוצים להתחשב בהקשר של השיחה בין הנציג האנושי לבין המשתמש כשיוצרים את התשובה לשאילתת החיפוש.
יצירה מ-API
בשלבים הבאים מוסבר איך ליצור ConversationProfile עם אובייקט HumanAgentAssistantConfig. אפשר לבצע את הפעולות האלה גם באמצעות מסוף Agent Assist.
כדי ליצור פרופיל שיחה, קוראים לשיטת היצירה במשאב ConversationProfile.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:- PROJECT_ID: מזהה הפרויקט
- LOCATION_ID: המזהה של המיקום
- AGENT_ID: מזהה הסוכן של מאגר הנתונים מבוסס-הזרימה או מבוסס-ההפעלה מהשלב הקודם
{ "displayName": "my-conversation-profile-display-name", "humanAgentAssistantConfig": { "humanAgentSuggestionConfig": { "featureConfigs": [ { "suggestionFeature": { "type": "KNOWLEDGE_SEARCH" }, "queryConfig": { "dialogflowQuerySource": { "humanAgentSideConfig": { "agent": "projects/PROJECT_ID/locations/LOCATION_ID/agents/AGENT_ID" } } }, "disableAgentQueryLogging": false, "enableConversationAugmentedQuery": false, } ] } } }
כשיוצרים פרופיל שיחה במסוף של Agent Assist, התכונה 'עזרה גנרטיבית בידע' מופעלת אוטומטית ב-Agent Assist.
שלב 2: שימוש בסוכן של מאגר נתונים
אפשר גם להשתמש ב-API של
SearchKnowledge
כדי לקבל תשובות מהסוכן של מאגר הנתונים. אפשר גם להשתמש בהגדרות הבאות כחלק מבקשת SearchKnowledge:
-
querySource: מגדירים את השדה הזה כדי לציין אם הסוכן הקליד את השאילתה או שהתכונה 'Knowledge Assist' הציעה אותה באופן אוטומטי. -
exactSearch: מגדירים את השדה הזה כדי לציין אם לחפש את שאילתת הקלט המדויקת בלי לשכתב את השאילתה. -
endUserMetadata: מגדירים את השדה הזה כדי לכלול מידע נוסף על משתמש הקצה, שישפר את התשובה שנוצרה. פרטים נוספים זמינים בדף ההתאמה האישית של ביצועי הסוכן במאגר הנתונים. -
searchConfig: מגדירים את השדה הזה כדי לקבל שליטה נוספת על שיפור וסינון של מסמכי מידע. פרטים נוספים זמינים בדף ההגדרה של חיפוש ביצועים של סוכן מאגר נתונים.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_ID: מזהה הפרויקט
- LOCATION_ID: המזהה של המיקום
- CONVERSATION_PROFILE_ID: מזהה פרופיל השיחה מהשלב הקודם
- SESSION_ID: מזהה סשן החיפוש היסטוריית החיפושים של אותה סשן יכולה להשפיע על תוצאת החיפוש. אפשר להשתמש במזהה השיחה הבא כמזהה הסשן.
- CONVERSATION_ID: השיחה (בין נציג תמיכה אנושי לבין משתמש הקצה) שבה מופעלת בקשת החיפוש
- MESSAGE_ID: ההודעה האחרונה בשיחה כשהבקשה לחיפוש מופעלת
הנה דוגמה לבקשת JSON:
{ "parent": "projects/PROJECT_ID/locations/LOCATION_ID" "query": { "text": "What is the return policy?" } "conversationProfile": "projects/PROJECT_ID/locations/LOCATION_ID/conversationProfiles/CONVERSATION_PROFILE_ID" "sessionId": "SESSION_ID "conversation": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID" "latestMessage": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID/messages/MESSAGE_ID "querySource": AGENT_QUERY "exactSearch": false "searchConfig": { "filterSpecs": { "filter": "category: ANY(\"persona_B\")" } } "endUserMetadata": { "deviceOwned": "Google Pixel 7" } }
אפשר גם לציין את שמות המשאבים conversation ו-latest_message אם החיפוש של הסוכן מתבצע במהלך שיחה עם משתמש. אם מפעילים את האפשרות enable_conversation_augmented_query ורוצים לשפר את חוויית התשובה לשאילתה באמצעות ההקשר של השיחה בין הסוכן למשתמש, צריך למלא את שני השדות האלה.
סימולטור
בודקים את הסוכן של מאגר הנתונים שמבוסס על תרשים זרימה או על ספר הפעלה בסימולטור של Agent Assist.
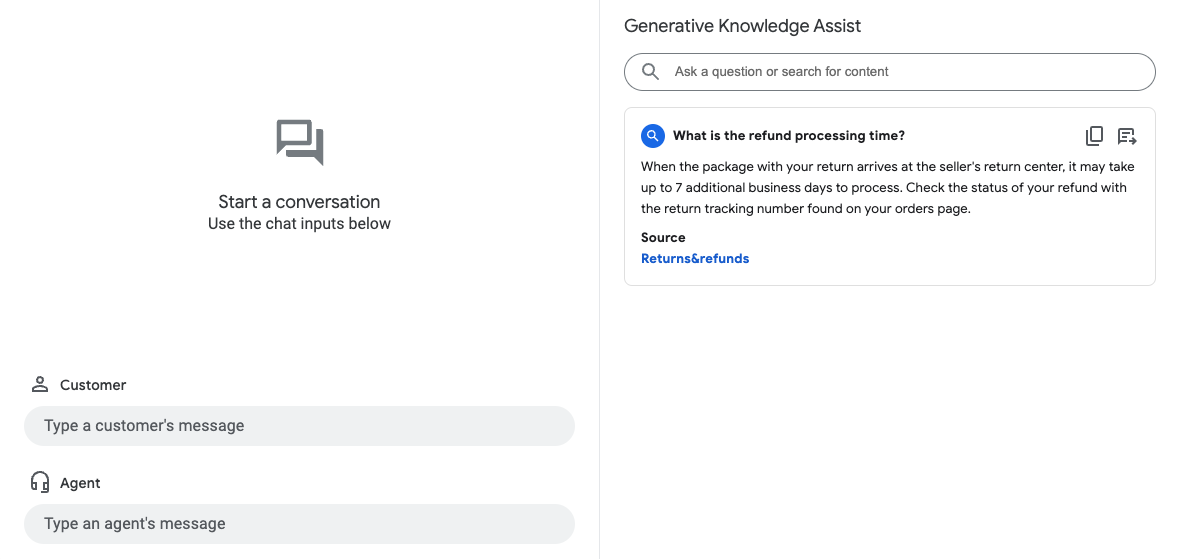
בדוגמה הקודמת, הסוכן של מאגר הנתונים מבוסס-הזרימה עונה על שאילתת המשתמש What is the refund
processing time? עם המידע הבא:
- תשובה שנוצרה על ידי AI גנרטיבי: אחרי שהחבילה עם המוצר שרוצים להחזיר מגיעה למרכז ההחזרות של המוכר, יכול להיות שיחלפו עד 7 ימי עסקים נוספים עד שההחזרה תעובד. אפשר לבדוק את סטטוס ההחזר הכספי באמצעות מספר המעקב של ההחזרה שמופיע בדף ההזמנות.
- כותרת של מסמך הידע הרלוונטי: החזרות והחזרים כספיים.
שליחת משוב
הוראות לשליחת משוב מופיעות במאמר שליחת משוב ל-Agent Assist.
מענה לשאלות של סוכן
הנה דוגמה לבקשת JSON לשליחת משוב על מענה לשאלות של סוכן:
{ "name": "projects/PROJECT_ID/locations/LOCATION_ID/answerRecords/ANSWER_RECORD_ID", "answerFeedback": { "displayed": true "clicked": true "correctnessLevel": "FULLY_CORRECT" "agentAssistantDetailFeedback": { "knowledgeSearchFeedback": { "answerCopied": true "clickedUris": [ "url_1", "url_2", "url_3", ] } } } }
מטא-נתונים
אם מגדירים מטא-נתונים למסמך ידע, גם Knowledge Assist גנרטיבי פרואקטיבי וגם Knowledge Assist גנרטיבי יחזירו את המטא-נתונים של המסמך יחד עם התשובה.
לדוגמה, אפשר להשתמש במטא-נתונים כדי לסמן אם מסמך הידע הוא מאמר פרטי פנימי או מאמר ציבורי חיצוני. גם בסימולטור של Agent Assist וגם במודולים של ממשק המשתמש, התכונות 'Knowledge Assist גנרטיבית' ו'Knowledge Assist גנרטיבית פרואקטיבית' מציגות באופן אוטומטי ערך של מטא-נתונים של מסמך עבור מפתחות מסוימים.
gka_source_label: הערך מוצג ישירות בכרטיס ההצעה.-
gka_source_tooltip: כשהערך הואstructtype, אם מציבים את הסמן מעל קישור המקור, הוא מתרחב והערך מוצג בתיבת מידע.
אם יש לכם את המטא-נתונים הבאים למסמך מידע, בכרטיס ההצעה יופיע המקור External Doc ובתיאור הכלי יופיע doc_visibility: public doc.
מטא-נתונים:
None
{
"title": "Public Sample Doc",
"gka_source_label": "External Doc",
"gka_source_tooltip": {
"doc_visibility": "public doc"
}
}
מטא-נתונים של משתמשי קצה
כדי לשפר את התשובה שנוצרה על ידי סוכן מאגר הנתונים ולהתאים אותה אישית, אפשר לצרף מטא-נתונים של משתמשי קצה. כדי להשתמש בתכונה 'Knowledge Assist גנרטיבי', אפשר לצרף מטא-נתונים של משתמשי קצה לשדה end_user_metadata או להטמיע אותם לשיחה באמצעות IngestContextReferences API. אתם יכולים להשתמש במטא-נתונים של משתמשי קצה שנקלטים גם ב'Knowledge Assist גנרטיבי' וגם ב'Knowledge Assist גנרטיבי פרואקטיבי'.
דוגמה 1: צירוף מטא-נתונים של משתמש קצה
{
"query": {
"text": "test query"
},
"conversationProfile": "projects/PROJECT_ID/locations/LOCATION_ID/conversationProfiles/CONVERSATION_PROFILE_ID",
"sessionId": "SESSION_ID",
"conversation": "projects/PROJECT_ID/locations/LOCATION_ID/conversations/CONVERSATION_ID",
"querySource": "AGENT_QUERY",
"endUserMetadata": {
"Name": "Jack",
"Age": 33,
"City": "Tokyo"
}
}
דוגמה 2: קליטת מטא-נתונים של משתמשי קצה
{
"conversation": "projects/PROJECT_ID/locations/global/conversations/CONVERSATION_ID",
"contextReferences": {
"gka_end_user_metadata": {
"contextContents": [{
"content": "{\"Name\":\"Jack\",\"Age\":33,\"city\":\"Tokyo\"}",
"contentFormat": "JSON"
}],
"updateMode": "OVERWRITE",
"languageCode": "en-US"
}
}
}
לפרטים נוספים על מטא-נתונים של משתמשי קצה ב-Datastore, אפשר לעיין במידע על התאמה אישית של Dialogflow.