
המדריך הזה למתחילים הוא מבוא לקבלת מסקנות ממודלים בהתאמה אישית ב-Vertex AI.
יעדי למידה
רמת הניסיון ב-Vertex AI: מתחילים
זמן קריאה משוער: 15 דקות
מה תלמדו:
- היתרונות בשימוש בשירות מנוהל להסקת מסקנות.
- איך מתבצעות מסקנות באצווה ב-Vertex AI.
- איך הסקת מסקנות אונליין פועלת ב-Vertex AI.
למה כדאי להשתמש בשירות הסקת מסקנות מנוהל?
נניח שקיבלתם משימה ליצור מודל שמקבל כקלט תמונה של צמח ומנבא את הסוג שלו. אפשר להתחיל באימון מודל במחברת, ולנסות היפרפרמטרים וארכיטקטורות שונים. אחרי שמסיימים לאמן את המודל, אפשר להפעיל את השיטה predict במסגרת למידת המכונה שבחרתם ולבדוק את איכות המודל.
תהליך העבודה הזה מצוין לניסויים, אבל אם רוצים להשתמש במודל כדי לקבל מסקנות לגבי הרבה נתונים, או לקבל מסקנות עם זמן אחזור נמוך תוך כדי תנועה, צריך משהו יותר מ-notebook. לדוגמה, נניח שאתם מנסים למדוד את המגוון הביולוגי של מערכת אקולוגית מסוימת, ובמקום שבני אדם יזהו ויספרו באופן ידני מיני צמחים בטבע, אתם רוצים להשתמש במודל למידת מכונה הזה כדי לסווג קבוצות גדולות של תמונות. אם אתם משתמשים ב-notebook, יכול להיות שתיתקלו במגבלות זיכרון. בנוסף, הסקת מסקנות לגבי כל הנתונים האלה צפויה להיות משימה ארוכה מדי שעלולה להסתיים בטיימאאוט במחברת.
או מה אם תרצו להשתמש במודל הזה באפליקציה שבה משתמשים יכולים להעלות תמונות של צמחים ולקבל זיהוי מיידי שלהם? צריך מקום לאירוח המודל מחוץ למחברת, כדי שהאפליקציה תוכל להפעיל אותו להסקת מסקנות. בנוסף, לא סביר שתהיה תעבורה עקבית למודל, ולכן כדאי להשתמש בשירות שיכול לבצע התאמה אוטומטית לעומס כשצריך.
בכל המקרים האלה, שירות ניהול מסקנות יפחית את החיכוך שקשור לאירוח ולשימוש במודלים של למידת מכונה. המדריך הזה מספק מבוא להסקת מסקנות ממודלים של ML ב-Vertex AI. הערה: יש אפשרויות נוספות להתאמה אישית, תכונות ודרכים ליצור אינטראקציה עם השירות שלא מפורטות כאן. המדריך הזה מספק סקירה כללית. למידע נוסף, אפשר לעיין במסמכי התיעוד בנושא מסקנות של Vertex AI.
סקירה כללית על שירות ההסקה המנוהל
Vertex AI תומך בהסקת מסקנות באצווה ובאונליין.
הסקת מסקנות באצווה היא בקשה לא סנכרונית. האפשרות הזו מתאימה אם אתם לא צריכים תשובה מיידית ורוצים לעבד נתונים שנצברו בבקשה אחת. בדוגמה שמופיעה במבוא, זה יהיה תרחיש השימוש של אפיון המגוון הביולוגי.
אם רוצים לקבל מסקנות עם זמן אחזור נמוך מנתונים שמועברים למודל תוך כדי תנועה, אפשר להשתמש בהסקת מסקנות אונליין. בדוגמה שמופיעה במבוא, זהו תרחיש השימוש שבו רוצים להטמיע את המודל באפליקציה שעוזרת למשתמשים לזהות מינים של צמחים באופן מיידי.
העלאת מודל למרשם המודלים של Vertex AI
כדי להשתמש בשירות ההסקה, השלב הראשון הוא העלאת מודל ה-ML המאומן אל מרשם המודלים של Vertex AI. זהו מאגר שבו אפשר לנהל את מחזור החיים של המודלים.
יצירת משאב של מודל
כשמאמנים מודלים באמצעות שירות האימון המותאם אישית של Vertex AI, אפשר לייבא את המודל באופן אוטומטי למרשם אחרי שמשימת האימון מסתיימת. אם דילגתם על השלב הזה, או אם אימנתם את המודל מחוץ ל-Vertex AI, אתם יכולים להעלות אותו באופן ידני באמצעות Google Cloud המסוף או Vertex AI SDK ל-Python על ידי ציון מיקום ב-Cloud Storage עם ארטיפקטים של המודל השמור. הפורמט של הארטיפקטים של המודל יכול להיות savedmodel.pb, model.joblib וכו', בהתאם למסגרת ה-ML שבה אתם משתמשים.
כשמעלים ארטיפקטים למרשם המודלים של Vertex AI, נוצר משאב Model שמופיע במסוף Google Cloud :
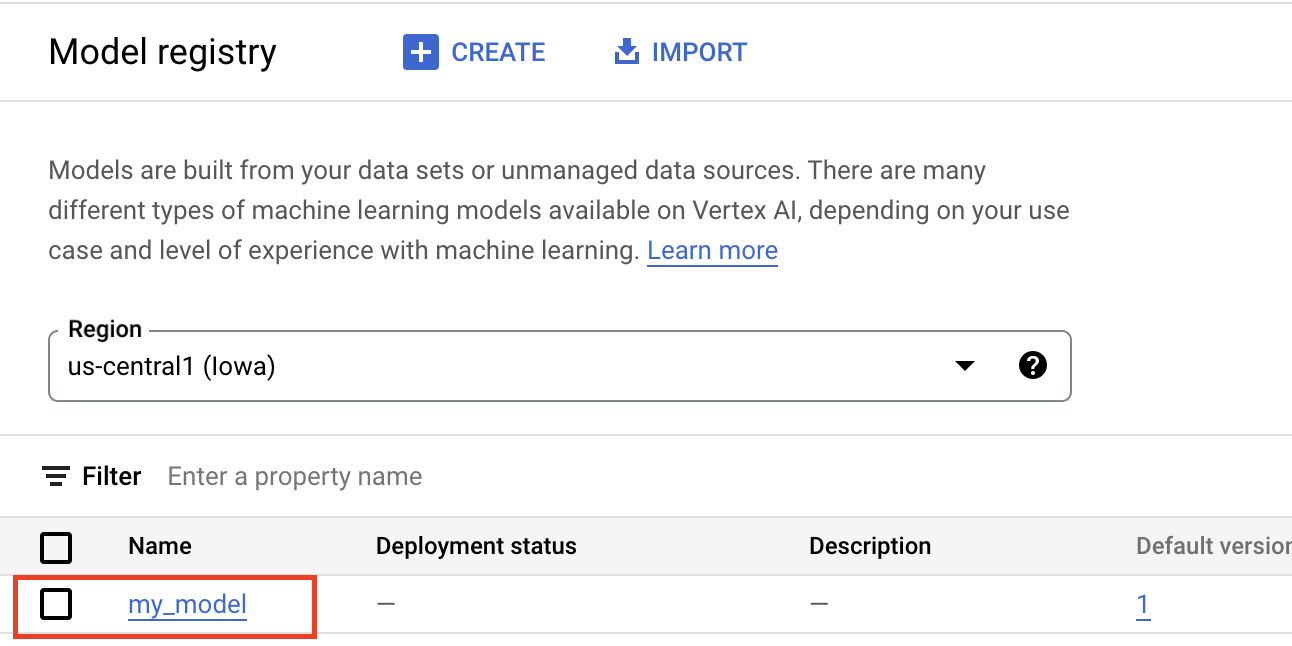
בחירת מאגר
כשמייבאים מודל למרשם המודלים של Vertex AI, צריך לשייך אותו למאגר כדי ש-Vertex AI יוכל להציג בקשות הסקה.
מאגרי תגים מוכנים מראש
Vertex AI מספק קונטיינרים מוכנים מראש שאפשר להשתמש בהם להסקת מסקנות. הקונטיינרים המוכנים מראש מאורגנים לפי מסגרת למידת מכונה וגרסת המסגרת, ומספקים שרתי היסק מסוג HTTP שאפשר להשתמש בהם כדי להציג היסקים עם מינימום הגדרות. הם מבצעים רק את פעולת ההסקה של מסגרת למידת המכונה, ולכן אם אתם צריכים לבצע עיבוד מקדים של הנתונים, אתם צריכים לעשות זאת לפני שאתם שולחים את בקשת ההסקה. באופן דומה, כל עיבוד שאחרי צריך להתבצע אחרי ששולחים את בקשת ההסקה. דוגמה לשימוש בקונטיינר מוכן מראש מופיעה ב-notebook Serving PyTorch image models with prebuilt containers on Vertex AI.
מאגרי תגים בהתאמה אישית
אם תרחיש השימוש שלכם דורש ספריות שלא נכללות במאגרי התגים המוכנים מראש, או אם יש לכם טרנספורמציות של נתונים בהתאמה אישית שאתם רוצים לבצע כחלק מבקשת ההסקה, אתם יכולים להשתמש במאגר תגים בהתאמה אישית שאתם יוצרים ומעלים ל-Artifact Registry. אפשר להתאים אישית יותר את כלי התגים המותאמים אישית, אבל הוא חייב להריץ שרת HTTP. באופן ספציפי, הקונטיינר צריך להאזין לבדיקות מצב פעילות (liveness), לבדיקות תקינות ולבקשות היקש ולהגיב להן. ברוב המקרים, מומלץ להשתמש במאגר מוכן מראש אם אפשר, כי זאת האפשרות הפשוטה יותר. דוגמה לשימוש בקונטיינר בהתאמה אישית מופיעה ב-notebook PyTorch Image Classification Single GPU using Vertex Training with Custom Container
שגרות הסקה בהתאמה אישית
אם התרחיש לדוגמה שלכם מחייב טרנספורמציות מותאמות אישית של עיבוד מקדים ועיבוד פוסט, ואתם לא רוצים את התקורה של בנייה ותחזוקה של קונטיינר בהתאמה אישית, אתם יכולים להשתמש בשגרות הסקה בהתאמה אישית. באמצעות שגרות היסק בהתאמה אישית, אתם יכולים לספק את טרנספורמציות הנתונים שלכם כקוד Python. מאחורי הקלעים, Vertex AI SDK ל-Python ייצור קונטיינר בהתאמה אישית שתוכלו לבדוק באופן מקומי ולפרוס ב-Vertex AI. דוגמה לשימוש בשגרות הסקה בהתאמה אישית מופיעה במחברת Custom inference routines with Sklearn.
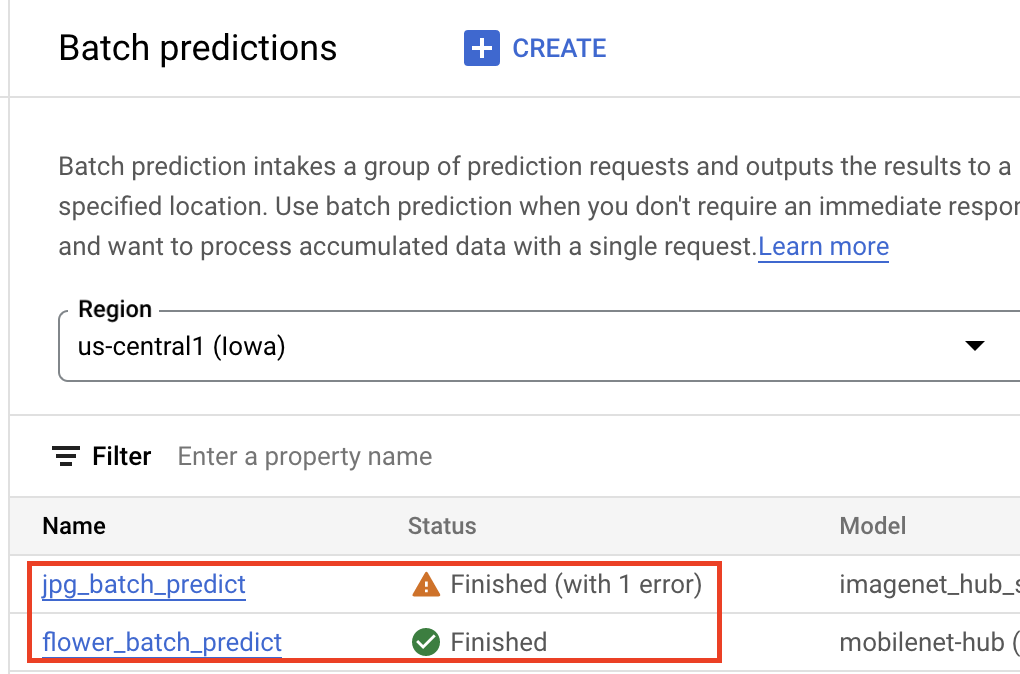
קבלת מסקנות בכמות גדולה
אחרי שהמודל שלכם נמצא במרשם המודלים של Vertex AI, אתם יכולים לשלוח משימת הסקת מסקנות באצווה ממסוף Google Cloud או מ-Vertex AI SDK ל-Python. תצטרכו לציין את המיקום של נתוני המקור, וגם את המיקום ב-Cloud Storage או ב-BigQuery שבו אתם רוצים לשמור את התוצאות. אפשר גם לציין את סוג המכונה שרוצים שהעבודה הזו תפעל עליה, ואת כל המאיצים האופציונליים. מכיוון ששירות ההסקה מנוהל באופן מלא, מערכת Vertex AI מקצה באופן אוטומטי משאבי מחשוב, מבצעת את משימת ההסקה ומוחקת את משאבי המחשוב אחרי שמשימת ההסקה מסתיימת. אפשר לעקוב אחרי הסטטוס של משימות ההסקה באצווה במסוף Google Cloud .
קבלת מסקנות אונליין
אם רוצים לקבל מסקנות אונליין, צריך לבצע את השלב הנוסף של פריסת המודל בנקודת קצה של Vertex AI.
הפעולה הזו משייכת את הארטיפקטים של המודל למשאבים פיזיים כדי להפעיל את המודל עם זמן אחזור נמוך, ויוצרת משאב DeployedModel.
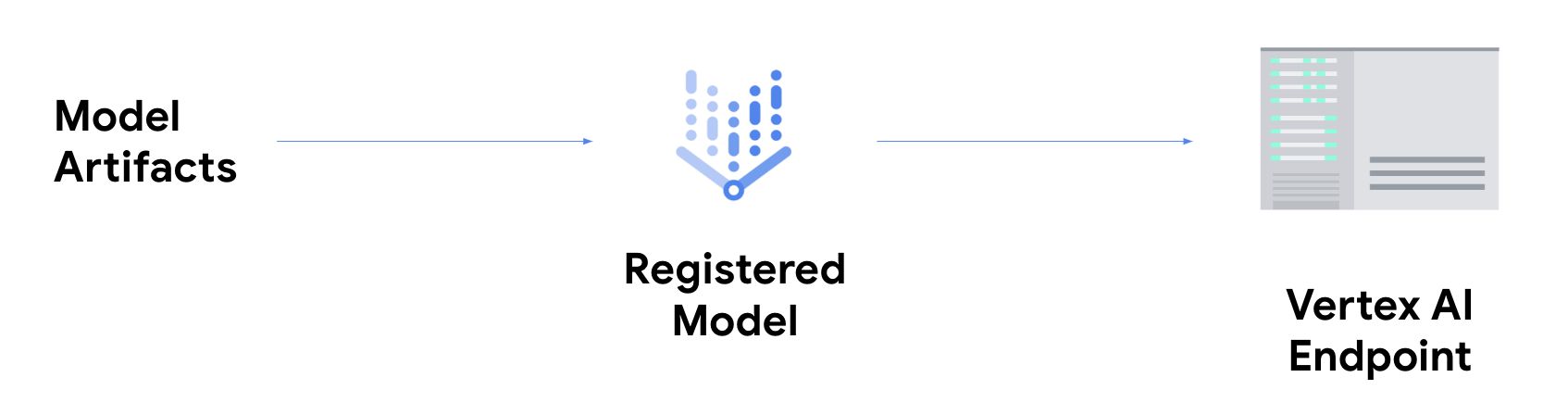
אחרי שמבצעים פריסה של המודל לנקודת קצה, הוא מקבל בקשות כמו כל נקודת קצה אחרת של REST, כלומר אפשר להפעיל אותו מפונקציית Cloud Run, מצ'אטבוט, מאפליקציית אינטרנט וכו'. שימו לב שאפשר לפרוס כמה מודלים לנקודת קצה אחת, ולפצל את התנועה ביניהם. הפונקציונליות הזו שימושית, למשל, אם רוצים להשיק גרסה חדשה של מודל אבל לא רוצים להפנות את כל התנועה למודל החדש באופן מיידי. אפשר גם לפרוס את אותו מודל לכמה נקודות קצה.
מקורות מידע לקבלת מסקנות ממודלים בהתאמה אישית ב-Vertex AI
מידע נוסף על אירוח מודלים והפעלתם ב-Vertex AI זמין במקורות המידע הבאים או במאגר הדוגמאות של Vertex AI ב-GitHub.
- סרטון בנושא חיזויים
- אימון מודל TensorFlow והצגתו באמצעות קונטיינר מוכן מראש
- הפעלת מודלים של תמונות ב-PyTorch באמצעות קונטיינרים מוכנים מראש ב-Vertex AI
- הצגת מודל דיפוזיה יציבה באמצעות קונטיינר מוכן מראש
- שגרות הסקה בהתאמה אישית עם Sklearn