
TPU v4
本文說明 Cloud TPU v4 的架構和支援的設定。
系統架構
每顆 TPU v4 晶片包含 2 個 TensorCore。每個 TensorCore 都有四個矩陣乘法單元 (MXU)、一個向量單元和一個純量單元。下表列出 v4 TPU Pod 的主要規格。
| 規格 | 值 |
|---|---|
| 每顆晶片的尖峰運算效能 | 每秒 275 兆次浮點運算 (bf16 或 int8) |
| HBM2 容量和頻寬 | 32 GiB,每秒 1200 GB |
| 測得的最小/平均/最大功率 | 90/170/192 W |
| TPU Pod 大小 | 4096 個晶片 |
| 互連網路拓撲 | 3D 網格 |
| 每個 Pod 的尖峰運算效能 | 每秒 110 萬兆次浮點運算 (bf16 或 int8) |
| 每個 Pod 的全縮減頻寬 | 1.1 PB/秒 |
| 每個 Pod 的對分頻寬 | 24 TB/秒 |
下圖說明 TPU v4 晶片。

如要進一步瞭解 TPU v4 的架構詳細資料和效能特徵,請參閱「TPU v4:適用於機器學習的光學可重構超級電腦,支援嵌入式硬體」。
3D 網格和 3D 環面
v4 TPU 會直接連線至 3D 空間中最鄰近的晶片,形成 3D 網格的網路連線。如果拓撲 AxBxC 為 2A=B=C 或 2A=2B=C,且每個維度都是 4 的倍數,則可將連線配置為 3D 環面。例如 4x4x8、4x8x8 或 12x12x24。一般來說,3D 環面設定的效能會優於 3D 網格設定。詳情請參閱「扭曲環面拓撲」。
TPU v4 相較於 v3 的效能優勢
本節將說明在 TPU v4 上執行範例訓練指令碼的記憶體效率方式,以及 TPU v4 相較於 TPU v3 的效能提升幅度。
記憶體系統
非一致性記憶體存取 (NUMA) 是適用於多個 CPU 的電腦記憶體架構。每個 CPU 都能直接存取一組高速記憶體。CPU 和記憶體稱為 NUMA 節點。NUMA 節點會連接至彼此直接相鄰的其他 NUMA 節點。一個 NUMA 節點的 CPU 可以存取另一個 NUMA 節點的記憶體,但這種存取方式比存取 NUMA 節點內的記憶體慢。
在多 CPU 機器上執行的軟體可將 CPU 需要的資料放在 NUMA 節點中,進而提高記憶體輸送量。如要進一步瞭解 NUMA,請參閱維基百科的「Non Uniform Memory Access」。
您可以將訓練指令碼繫結至 NUMA 節點 0,充分發揮 NUMA 本機性的優勢。
如要啟用 NUMA 節點繫結:
安裝 numactl 指令列工具。numactl 可讓您執行程序,並採用特定 NUMA 排程或記憶體放置政策。
$ sudo apt-get update $ sudo apt-get install numactl
將指令碼程式碼繫結至 NUMA 節點 0。將 your-training-script 替換為訓練指令碼的路徑。
$ numactl --cpunodebind=0 python3 your-training-script
在下列情況下啟用 NUMA 節點繫結:
- 如果工作負載高度依賴 CPU 工作負載 (例如圖片分類、建議工作負載),無論架構為何。
- 如果使用的 TPU 執行階段版本沒有 -pod 後置字元 (例如
tpu-vm-tf-2.10.0-v4)。
其他記憶體系統差異:
- v4 TPU 晶片的整個晶片共有 32 GiB 的統合式 HBM 記憶體空間,可增進晶片上兩個 TensorCore 的協調效率。
- 採用最新記憶體標準和速度,提升 HBM 效能。
- 改善 DMA 效能設定檔,內建支援以 512B 粒度進行高效能步進。
TensorCores
- MXU 數量加倍,時脈頻率更高,最高可達 275 TFLOPS。
- 轉置與排序頻寬是前代的 2 倍。
- Common Memory (Cmem) 的載入/儲存記憶體存取模型。
- MXU 權重載入頻寬更快,且支援 8 位元模式,可縮減批次大小並縮短推論延遲時間。
晶片間互連
每個晶片有六個互連連結,可實現網路直徑較小的網路拓撲。
其他
- x16 PCIE 第 3 代介面,可連線至主機 (直接連線)。
- 改良安全性模型。
- 提升能源效率。
設定
TPU v4 Pod 由 4096 個晶片組成,並以可重新設定的高速連結互連。TPU v4 的彈性網路可讓您以多種方式連結相同大小配量中的晶片。建立 TPU 配量時,您會指定所需的 TPU 版本和 TPU 資源數量。
您可以使用 3 元組 AxBxC 指定 TPU 拓撲,其中 A<=B<=C,且 A、B、C 皆 <= 4,或皆為 4 的整數倍數。A、B 和 C 值分別代表三個維度的晶片數量。
對於 2A=B=C 或 2A=2B=C 的拓撲,也有針對全對全通訊最佳化的拓撲變體,例如 4×4×8、8×8×16 和 12×12×24。這些拓撲稱為「扭曲環面拓撲」。
下圖顯示一些常見的 TPU v4 拓撲。
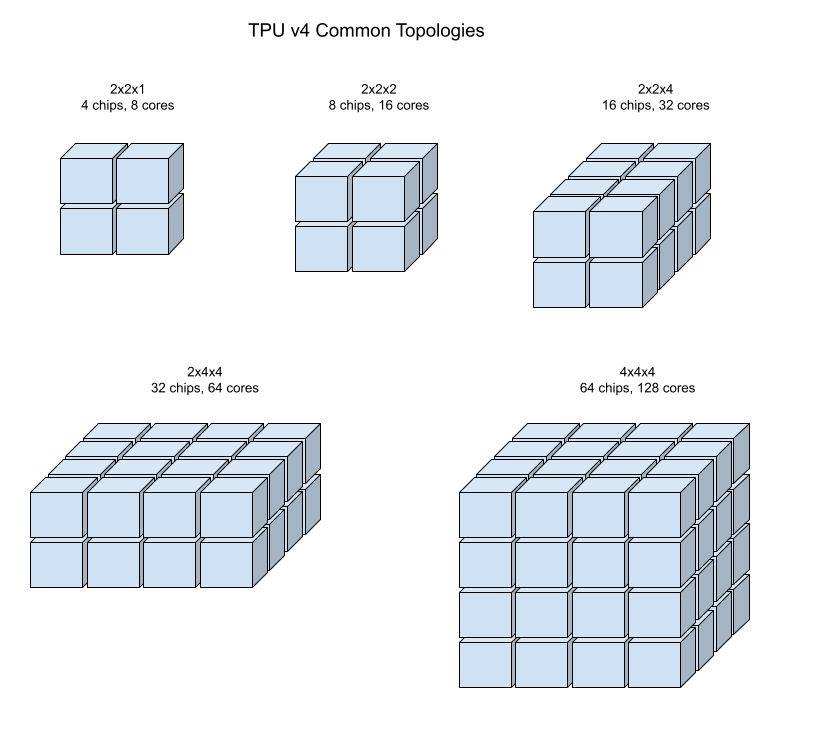
較大的切片可由一或多個 4x4x4 的晶片「立方體」建構而成。
如要進一步瞭解如何管理 TPU,請參閱「管理 TPU」。 如要進一步瞭解 Cloud TPU 的系統架構,請參閱「系統架構」。
扭曲環面拓撲
對於某些 3D 切片形狀,您可以使用扭曲環面拓撲。這些拓撲可提供高得多的二分頻寬。舉例來說,相較於非扭曲的 4x4x8 切片,4x4x8 扭曲拓撲的理論二分頻寬可增加 70%。頻寬增加後,使用全域通訊模式的工作負載就能獲得助益。對於大多數模型,扭曲拓撲可提升效能,而TPU 嵌入工作負載越大,效益就越顯著。TPU 軟體支援切片上的扭曲拓撲,其中每個維度的大小等於或兩倍於最小維度。例如 4x4x8、4×8×8 或 12x12x24。透過 Cloud TPU API,TPU v4 和 TPU v5p 支援扭曲拓撲。
對於只使用資料平行處理策略的工作負載,扭曲拓撲的效能可能會稍微好一點。使用大型語言模型 (LLM) 時,扭曲拓撲的效能會因所用的平行處理類型 (例如資料平行處理或模型平行處理) 而異。如要找出模型的最佳效能,請使用扭曲拓撲訓練 LLM,並與未使用扭曲拓撲訓練的 LLM 進行比較。FSDP MaxText 模型的幾項實驗顯示,使用扭曲拓撲時,模型 FLOPS 使用率 (MFU) 提升了 1 到 2 個百分點。
扭曲拓撲的主要優點是將非對稱環面拓撲 (例如 4×4×8) 變更為對稱拓撲。對稱拓撲提供以下優點:
- 負載平衡功能改善
- 更高的二分頻寬
- 封包路徑較短
這些優勢可提升許多全球通訊模式的效能。
舉例來說,請參考這個 4×2 環面拓撲,其中 TPU 在配量中標示為 X 和 Y 座標:
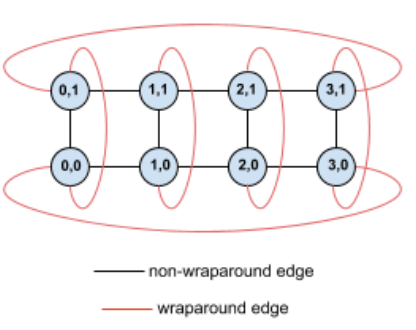
為求明確,圖表會將連線顯示為無向邊。實際上,每個邊緣都是 TPU 之間的雙向連線。這個格線一側與對側之間的邊緣是環繞邊緣。
扭曲這個拓撲會建立對稱的 4×2 扭曲環面拓撲:
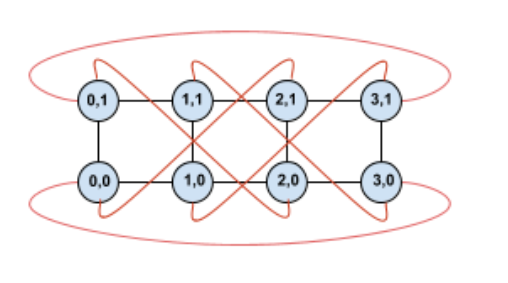
這個扭曲的圖表與未扭曲的圖表之間的差異在於 Y 軸的環繞邊緣。這些環繞邊緣不會連線至具有相同 X 座標的另一個 TPU,而是會連線至座標 X+2 mod 4 的 TPU。
這項原則適用於不同大小和數量的尺寸。 如果每個維度的大小等於或兩倍於最小維度的大小,則產生的網路會是對稱網路。
下表列出部分支援的扭曲拓撲,以及與未扭曲拓撲相比,這些拓撲在理論上可增加的二分頻寬。
| 拓撲 | 與非扭曲環面相比,理論上的二分頻寬增加 |
|---|---|
| 4×4×8 | 約 70% |
| 8x8x16 | |
| 12×12×24 | |
| 4×8×8 | 約 40% |
| 8×16×16 |
TPU v4 拓撲變體
有些拓撲包含相同數量的晶片,但排列方式可能不同。舉例來說,您可以使用下列拓撲設定具有 512 個晶片 (1024 個 TensorCore) 的 TPU 配量:4x4x32、4x8x16 或 8x8x8。含有 2048 個晶片 (4096 個 TensorCore) 的 TPU 配量提供更多拓撲選項:4x4x128、4x8x64、4x16x32 和 8x16x16。
與特定晶片數量相關聯的預設拓撲,最類似於立方體。這個形狀可能是資料平行機器學習訓練的最佳選擇。對於具有多種平行處理類型的工作負載 (例如模型和平行資料,或模擬的空間分割),其他拓撲可能很有用。如果拓撲與使用的平行處理相符,這些工作負載的效能最佳。舉例來說,在 X 維度上放置 4 向模型平行處理,在 Y 和 Z 維度上放置 256 向資料平行處理,即可符合 4x16x16 拓撲。
如果模型有多個平行處理維度,將平行處理維度對應至 TPU 拓撲維度,可獲得最佳效能。這些通常是資料和平行模型大型語言模型 (LLM)。舉例來說,如果 TPU v4 配量的拓撲為 8x16x16,則 TPU 拓撲維度為 8、16 和 16。使用 8 向或 16 向模型平行處理 (對應至其中一個實體 TPU 拓撲維度) 的效能較佳。由於與任何 TPU 拓撲維度都不一致,因此 4 向模型平行處理對於這個拓撲來說並非最佳選擇,但如果晶片數量相同,4x16x32 拓撲就會是最佳選擇。
TPU v4 配置包含兩組,分別是拓撲小於 64 個晶片 (小型拓撲),以及拓撲大於 64 個晶片 (大型拓撲)。
小型 v4 拓撲
Cloud TPU 支援下列晶片數少於 64 個的 TPU v4 配量,也就是 4x4x4 立方體。您可以使用 TensorCore 型名稱 (例如 v4-32) 或拓撲 (例如 2x2x4) 建立這些小型 v4 拓撲:
| 名稱 (根據 TensorCore 數量) | 晶片數量 | 拓撲 |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
大型 v4 拓撲
TPU v4 配量以 64 個晶片為增量單位,且所有三個維度的形狀都是 4 的倍數。維度必須遞增排序。下表列出幾個範例。其中幾種拓撲是「自訂」拓撲,只能使用 --type 和 --topology 標記建立,因為晶片排列方式不只一種。
| 名稱 (根據 TensorCore 數量) | 晶片數量 | 拓撲 |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
自訂拓撲:必須使用 --type 和 --topology 標記 |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
自訂拓撲:必須使用 --type 和 --topology 標記 |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |