
Monitorar VMs do Cloud TPU
Neste guia, explicamos como usar o Google Cloud Monitoring para monitorar as VMs do Cloud TPU. O Google Cloud Monitoring coleta automaticamente métricas e registros do Cloud TPU e do Compute Engine host. Esses dados podem ser usados para monitorar a integridade do Cloud TPU e do Compute Engine.
Com as métricas, é possível monitorar uma quantidade numérica ao longo do tempo, como a utilização da CPU, o uso da rede ou a duração da inatividade de um TensorCore. Os registros capturam eventos em um momento específico. As entradas de registro são gravadas pelo próprio código, pelos serviços do Google Cloud, por aplicativos de terceiros e pela infraestrutura do Google Cloud . Também é possível gerar métricas com base nos dados presentes em uma entrada de registro criando uma métrica com base em registros. Além disso, você também pode definir políticas de alertas com base em valores de métricas ou entradas de registro.
Neste guia, saiba mais sobre o Google Cloud Monitoring e aprenda a fazer o seguinte:
- Conferir métricas do Cloud TPU.
- Configurar políticas de alertas de métricas do Cloud TPU.
- Consultar registros do Cloud TPU.
- Criar métricas com base em registros para configurar alertas e visualizar painéis.
Para monitorar TPUs, também é possível usar o Planejador de capacidade (pré-lançamento). Com ele, você pode conferir os dados de previsão e de uso de TPU do projeto, da pasta ou da organização. Esses dados são atualizados a cada 24 horas e podem ser usados para analisar tendências de uso e planejar necessidades futuras de capacidade. Para mais informações, consulte Visão geral do Planejador de capacidade.
Este documento presume que você tem alguns conhecimentos básicos sobre o Google Cloud Monitoring. Você precisa ter uma VM do Compute Engine e os recursos do Cloud TPU criados antes de começar a geração e o trabalho com o Google Cloud Monitoring. Consulte o Guia de início rápido do Cloud TPU para mais detalhes.
Métricas
As métricas doGoogle Cloud são geradas automaticamente pelas VMs do Compute Engine e pelo ambiente de execução do Cloud TPU. Estas métricas são geradas pelas VMs do Cloud TPU:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
Pode levar até 180 segundos entre o momento em que um valor de métrica é gerado e sua exibição no Metrics Explorer.
Para uma lista completa de métricas geradas pelo Cloud TPU, consulte Métricas doGoogle Cloud Cloud TPU.
Uso da memória
A métrica memory/usage é gerada para o recurso TPU Worker
e monitora a memória usada pela VM de TPU em bytes. Essa métrica é amostrada a cada 60 segundos.
Contagem de bytes recebidos na rede
A métrica network/received_bytes_count é gerada para o recurso TPU Worker
e monitora o número de bytes cumulativos de dados que a VM de TPU recebeu
pela rede em um determinado momento.
Contagem de bytes enviados na rede
A métrica network/sent_bytes_count é gerada para o recurso TPU Worker
e monitora o número de bytes cumulativos que a VM de TPU enviou pela rede
em um determinado momento.
Uso da CPU
A métrica cpu/utilization é gerada para o recurso TPU Worker
e monitora a utilização atual da CPU no worker de TPU, representada como uma porcentagem,
com amostragem a cada minuto. Em geral, os valores estão entre 0,0 e 100,0,
mas podem exceder 100,0.
Duração da inatividade do TensorCore
A métrica tpu/tensorcore/idle_duration é gerada para o recurso TPU Worker
e monitora o número de segundos de inatividade
do TensorCore de cada chip de TPU. Essa métrica está disponível para cada chip em todas as TPUs em uso. Se um TensorCore
estiver em uso, o valor da duração de inatividade será redefinido como zero. Quando o TensorCore não estiver mais em uso,
o valor da duração de inatividade vai começar a aumentar.
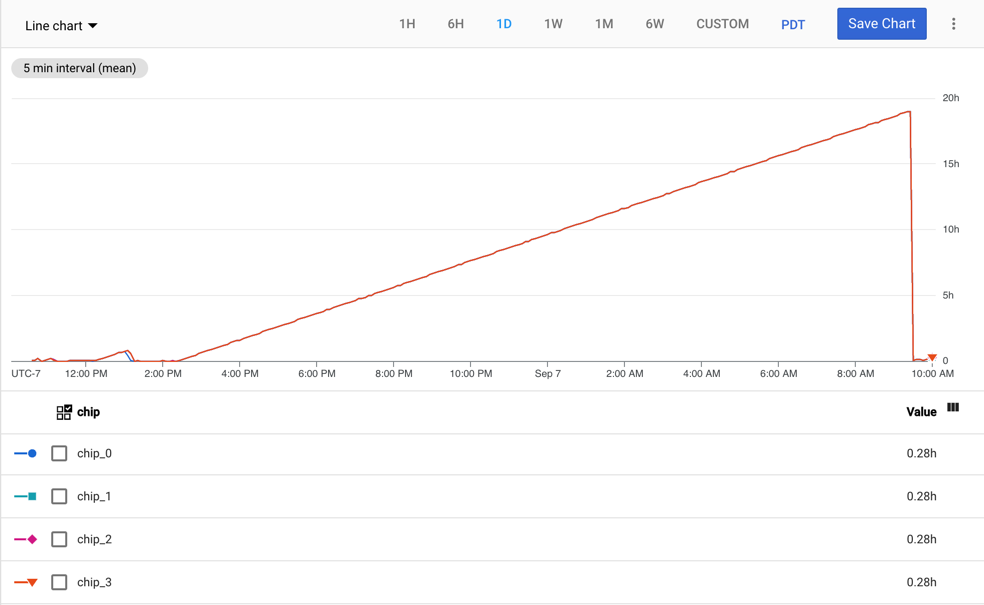
O gráfico a seguir mostra a métrica tpu/tensorcore/idle_duration para
uma VM de TPU v2-8, que tem um worker. Cada worker tem quatro chips. Neste exemplo, todos os
quatro chips têm os mesmos valores para tpu/tensorcore/idle_duration.
Portanto, os gráficos são sobrepostos.
Utilização do TensorCore
A métrica accelerator/tensorcore_utilization é gerada para o recurso GCE TPU
Worker
e monitora a porcentagem atual do TensorCore em uso. Essa métrica é calculada dividindo o número de operações do TensorCore
realizadas em um período de amostragem pelo número máximo de operações
que podem ser realizadas no mesmo período. Um valor maior significa
melhor utilização. A métrica de uso do TensorCore está disponível
na v4 e em gerações mais recentes da TPU.
Utilização da largura de banda de memória
A métrica accelerator/memory_bandwidth_utilization é gerada para o recurso GCE TPU Worker
e monitora a porcentagem atual da largura de
banda da memória do acelerador em uso. Essa métrica é calculada dividindo a largura de
banda da memória usada durante um período de amostragem pela largura de banda máxima
aceita no mesmo período. Um valor maior significa melhor utilização. A métrica
de utilização de largura de banda da memória está disponível na v4 e em gerações mais recentes da TPU.
Ciclo de trabalho do acelerador
A métrica accelerator/duty_cycle é gerada para o recurso GCE TPU Worker
e monitora a porcentagem de tempo durante o período de amostragem em que o TensorCore
do acelerador fez processamentos ativos. Os valores estão no intervalo
de 0 a 100. Um valor maior significa melhor uso do TensorCore. Essa métrica é
calculada quando uma carga de trabalho de machine learning é executada na VM de TPU. A métrica
de ciclo de trabalho do acelerador
está disponível no JAX 0.4.14
e em versões mais recentes,
no PyTorch 2.1
e em versões mais recentes
e no TensorFlow 2.14.0
e em versões mais recentes.
Memória total do acelerador
A métrica accelerator/memory_total é gerada para o recurso GCE TPU Worker
e monitora a memória total do acelerador alocada em bytes.
Essa métrica é calculada quando uma carga de trabalho de machine learning é executada na
VM de TPU. A métrica de total de memória do acelerador está disponível no
JAX 0.4.14
e em versões mais recentes,
no PyTorch 2.1
e em versões mais recentes e
no TensorFlow 2.14.0
e em versões mais recentes.
Memória do acelerador usada
A métrica accelerator/memory_used é gerada para o recurso GCE TPU Worker
e monitora a memória total do acelerador usada em bytes. Essa métrica é
calculada quando uma carga de trabalho de machine learning é executada na VM de TPU. A métrica
de memória do acelerador usada
está disponível no JAX 0.4.14
e em versões mais recentes,
no PyTorch 2.1
e em versões mais recentes
e no TensorFlow 2.14.0
e em versões mais recentes.
Como conferir métricas
É possível conferir as métricas usando o Metrics Explorer no console do Google Cloud .
No Metrics Explorer, clique em Selecionar métrica e pesquise TPU Worker ou GCE TPU Worker,
dependendo da métrica que você quer conferir.
Selecione um recurso para mostrar todas as métricas disponíveis para ele.
Se a opção Ativo estiver habilitada, somente as métricas com dados de
série temporal nas últimas 25 horas serão listadas. Desative a opção Ativo para listar todas as métricas.
Como criar alertas
É possível criar políticas de alertas para que o Cloud Monitoring envie um alerta quando uma condição for atendida.
As etapas nesta seção mostram um exemplo de como adicionar uma política de alertas para a métrica Duração de inatividade do TensorCore. Sempre que essa métrica exceder 24 horas, o Cloud Monitoring vai enviar um e-mail para o endereço registrado.
- Acesse o console do Monitoring.
- No painel de navegação, clique em Alertas.
- Clique em Editar canais de notificação.
- Em E-mail, clique em Adicionar. Digite um endereço de e-mail, um nome de exibição e clique em Salvar.
- Na página Alertas, clique em Criar política.
- Clique em Selecionar métrica e escolha Duração de inatividade do Tensorcore. Depois, clique em Aplicar.
- Clique em Avançar e em Limite.
- Em Gatilho de alerta, selecione Qualquer violação de série temporal.
- Em Posição do limite, selecione Acima do limite.
- Em Valor do limite, digite
86400000. - Clique em Avançar.
- Em Canais de notificação, selecione seu canal de notificação por e-mail e clique em OK.
- Digite um nome para a política de alertas.
- Clique em Avançar e em Criar política.
Quando a duração de inatividade do TensorCore excede 24 horas, um e-mail é enviado ao endereço especificado.
Logging
As entradas de registro são gravadas pelos serviços do Google Cloud , por serviços de terceiros, por frameworks de ML ou pelo código. É possível conferir os registros usando a Análise de registros ou a API Logs. Para mais informações sobre o Google Cloud Logging, consulte Google Cloud Logging.
Os registros do worker de TPU contêm informações sobre um worker específico
do Cloud TPU em uma zona específica, como a quantidade de memória disponível
no worker do Cloud TPU (system_available_memory_GiB).
Os registros de recursos auditados contêm informações sobre quando uma
API específica do Cloud TPU
foi chamada e quem fez a chamada. Por exemplo, você pode encontrar informações
sobre chamadas para as APIs CreateNode, UpdateNode e DeleteNode.
Os frameworks de ML podem gerar registros para saída padrão e erro padrão. Esses registros são controlados por variáveis de ambiente e lidos pelo script de treinamento.
O código pode gravar registros no Google Cloud Logging. Para mais informações, consulte Gravar registros padrão e Gravar registros estruturados.
Geração de registros da porta serial
O Cloud TPU depende da geração de registros da porta serial para solução de problemas, monitoramento e depuração. O padrão é ativar a geração de registros da porta serial. Se essa geração não estiver ativada, o processo de criação de VMs de TPU vai falhar e gerar a mensagem de erro a seguir.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
Essa mensagem indica que a restrição constraints/compute.disableSerialPortLogging
foi violada.
Para evitar esse erro, verifique se a geração de registros da porta serial está permitida
nos projetos de TPU. A prática recomendada é substituir a
política da organização no nível do projeto.
Para saber como ativar a geração de registros da porta serial, consulte Como ativar e desativar a geração de registros de saída da porta serial.
Registros de consultas do Google Cloud
Quando você exibe registros no console do Google Cloud , a página executa uma consulta padrão.
Para conferir a consulta, clique no botão Show query. Você pode
modificar a consulta padrão ou criar uma nova. Para mais informações, consulte
Criar consultas na Análise de registros.
Registros de recursos auditados
Para acessar os registros de recursos auditados, faça o seguinte:
- Acesse a Análise de registros do Google Cloud .
- Clique no menu suspenso Todos os recursos.
- Clique em Recurso auditado e em Cloud TPU.
- Escolha a API Cloud TPU relevante.
- Clique em Aplicar. Os registros são exibidos nos resultados da consulta.
Clique em qualquer entrada de registro para exibir as informações. Cada entrada de registro tem vários campos, como:
- logName: o nome do registro.
- protoPayload -> @type: o tipo do registro.
- protoPayload -> resourceName: o nome do Cloud TPU.
- protoPayload -> methodName: o nome do método chamado (somente registros de auditoria).
- protoPayload -> request -> @type: o tipo de solicitação.
- protoPayload -> request -> node: detalhes sobre o nó do Cloud TPU.
- protoPayload -> request -> node_id: o nome da TPU.
- severity: a gravidade do registro.
Registros do worker da TPU
Para conferir os registros do worker de TPU, faça o seguinte:
- Acesse a Análise de registros do Google Cloud .
- Clique no menu suspenso Todos os recursos.
- Clique em Worker de TPU.
- Selecione uma zona.
- Selecione o Cloud TPU relevante.
- Clique em Aplicar. Os registros são exibidos nos resultados da consulta.
Clique em qualquer entrada de registro para exibir as informações. Cada entrada de registro tem um campo chamado
jsonPayload. Expanda jsonPayload para conferir vários campos, como:
- accelerator_type: o tipo do acelerador.
- consumer_project: o projeto em que o Cloud TPU está.
- evententry_timestamp: o horário em que o registro foi gerado.
- system_available_memory_GiB: a memória disponível no worker do Cloud TPU (0 ~ 350 GiB).
Como criar métricas com base em registros
Esta seção descreve como criar métricas com base em registros que são usadas para configurar painéis e alertas de monitoramento. Para saber como criar métricas com base em registros de maneira programática, consulte Como criar métricas com base em registros de maneira programática usando a API REST do Cloud Logging.
O exemplo a seguir usa o subcampo system_available_memory_GiB para demonstrar como criar uma métrica com base em registros para monitorar a memória disponível de um worker do Cloud TPU.
- Acesse a Análise de registros do Google Cloud .
Na caixa de consulta, insira a consulta a seguir para extrair todas as entradas de registro em que system_available_memory_GiB está definido para o worker principal do Cloud TPU:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Clique em Criar métrica para abrir o Editor de métricas.
Em Tipo de métrica, escolha Distribuição.
Digite um nome, uma descrição opcional e uma unidade de medida para a métrica. Neste exemplo, digite matrix_unit_utilization_percent e MXU utilization nos campos Nome e Descrição, respectivamente. O filtro é pré-preenchido com o script que você inseriu na Análise de registros.
Clique em Criar métrica.
Clique em Exibir no Metrics Explorer para conferir a nova métrica. Pode levar alguns minutos para que as métricas sejam exibidas.
Como criar métricas com base em registros usando a API REST do Cloud Logging
Também é possível criar métricas com base em registros usando a API Cloud Logging. Para mais informações, consulte Como criar uma métrica de distribuição.
Como criar painéis e alertas usando métricas com base em registros
Os painéis são úteis para visualizar métricas (previsão de cerca de dois minutos de atraso). Os alertas são úteis para enviar notificações em caso de erros. Para mais informações, consulte estes tópicos:
- Painéis de monitoramento e geração de registros
- Gerenciar painéis personalizados
- Criar políticas de alertas com base em métricas
Como criar painéis
Para criar um painel no Cloud Monitoring para a métrica Duração de inatividade do TensorCore, faça o seguinte:
- Acesse o console do Monitoring.
- No painel de navegação, clique em Painéis.
- Clique em Criar painel e em Adicionar widget.
- Escolha o tipo de gráfico que você quer adicionar. Neste exemplo, escolha Linha.
- Digite um título para o widget.
- Clique no menu suspenso Selecionar métrica e digite Duração de inatividade do TensorCore no campo de filtro.
- Na lista de métricas, selecione Worker de TPU -> TPU -> Duração de inatividade do TensorCore.
- Para filtrar o conteúdo do painel, clique no menu suspenso Filtrar.
- Em Rótulos de recursos, selecione project_id.
- Escolha um comparador e digite um valor no campo Valor.
- Clique em Aplicar.