
TPU7x (Ironwood)
本頁面說明 TPU7x 的架構和可用設定,這是 Google Cloud上最新的 TPU。TPU7x 是 Ironwood 系列的第一個版本,也是第七代 TPU。 Google CloudIronwood 世代的設計目標是支援大規模 AI 訓練和推論。
每個 Pod 都有 9,216 個晶片,因此 TPU7x 與 TPU v5p 有許多相似之處。TPU7x 可為大規模密集和 MoE 模型、預先訓練、取樣和解碼密集型推論作業提供高效能。
如要使用 TPU7x,可以透過 Google Kubernetes Engine (GKE) 或 Compute Engine 進行。如要進一步瞭解如何透過 GKE 使用 TPU,請參閱「GKE 中的 TPU 簡介」。
您也可以搭配使用 TPU7x 和 GKE 與 TPU Cluster Director。TPU 叢集導向器可透過「所有容量」模式預訂使用,讓您完全存取所有預訂容量 (無保留),並全面掌握 TPU 硬體拓撲、使用率和健康狀態。詳情請參閱「所有容量模式總覽」。
系統架構
每顆 TPU7x 晶片包含 2 個 TensorCore 和 4 個 SparseCore。下表列出 TPU7x 與前幾代相比的主要規格和值。
| 規格 | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| 每個 Pod 的晶片數量 | 8960 | 256 | 9216 |
| 每顆晶片的尖峰運算效能 (BF16) (TFLOPs) | 459 | 918 | 2307 |
| 每顆晶片的尖峰運算效能 (FP8) (TFLOPs) | 459 | 918 | 4614 |
| 每個晶片的 HBM 容量 (GiB) | 95 | 32 | 192 |
| 每個晶片的 HBM 頻寬 (GBps) | 2765 | 1638 | 7380 |
| vCPU 數量 (4 個晶片的 VM) | 208 | 180 | 224 |
| RAM (GB) (4 晶片 VM) | 448 | 720 | 960 |
| 每個晶片的 TensorCore 數量 | 2 | 1 | 2 |
| 每個晶片的 SparseCore 數量 | 4 | 2 | 4 |
| 每個晶片的雙向晶片間互連 (ICI) 頻寬 (GBps) | 1200 | 800 | 1200 |
| 每個晶片的資料中心網路 (DCN) 頻寬 (Gbps) | 50 | 100 | 100 |
下圖說明 Ironwood 的架構:
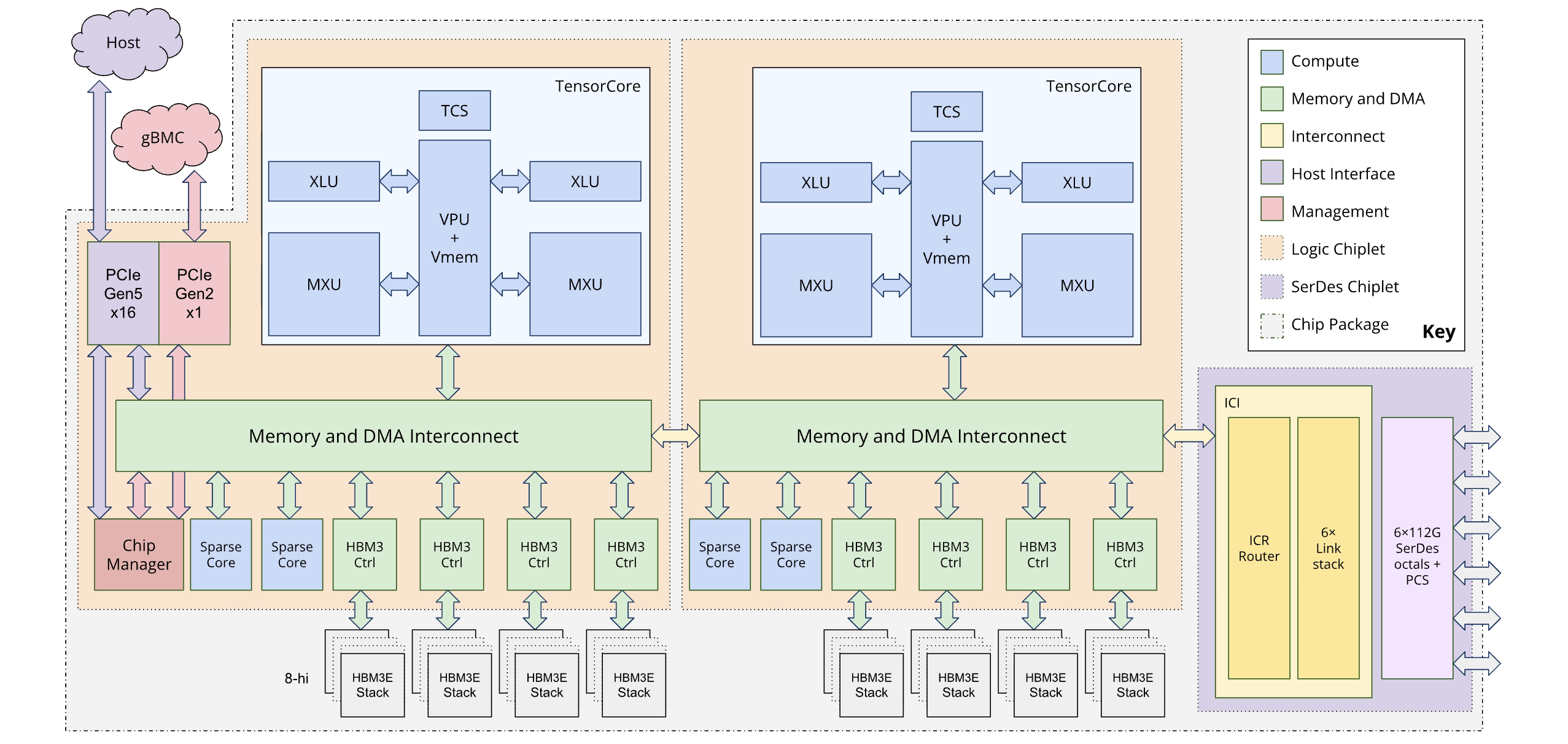
記憶體階層
TPU7x 採用多層記憶體系統,因此管理這些層之間的資料移動對效能至關重要:
- 高頻寬記憶體 (HBM):每顆晶片都配備 192 GB 的 HBM,頻寬約為 7.37 TB/s。HBM 容量大,因此可使用大型批量,進而提升處理量。不過,儘管 HBM 體積龐大,仍可能成為瓶頸,特別是對於受記憶體限制的向量運算或效率不彰的資料存取模式。
- 向量記憶體 (VMEM):VMEM 是較小的晶片上 SRAM (靜態隨機存取記憶體),與矩陣乘法單元 (MXU) 的頻寬遠高於 HBM。這項記憶體可做為自訂核心的高速暫存區。這個緩衝區的大小是可調整的參數。最佳化緩衝區空間是調整自訂 Pallas 核心的關鍵,因為這些核心的區塊大小通常會受到可用 VMEM 的限制。
- 主機記憶體和 PCIe:每組四個 TPU 晶片都會透過 PCIe 網路連線至 CPU 主機。雖然這個連線的頻寬遠低於 HBM,但主機的主要記憶體可用於卸載啟用或最佳化工具狀態,藉此釋放 HBM,這項技術特別適合用於管理大型模型中的記憶體壓力。
如要進一步瞭解如何有效管理 TPU7x 記憶體階層層級之間的資料移動,請參閱「Ironwood 效能最佳化」。
雙晶片架構
Ironwood 程式設計模型可讓您存取兩個 TPU 晶片,而非前幾代 (TPU v4 和 v5p) 使用的單一邏輯核心 (也稱為 MegaCore) 架構。這項變更可提高晶片的製造效率和成本效益。雖然這代表架構的轉移,但新設計可確保您能以最少的變更重複使用現有軟體模型。
Ironwood TPU 由兩個不同的晶片組成,每個晶片都有專屬的記憶體空間。這與 MegaCore 架構的統一記憶體空間不同。
晶片組合:每個晶片都是獨立單元,內含一個 TensorCore、兩個 SparseCore 和 96 GB 的高頻寬記憶體 (HBM)。
高速互連:這兩個晶片透過晶粒對晶粒 (D2D) 介面連接,速度比一維晶片間互連 (ICI) 連結快六倍。晶片間通訊是透過集體作業管理。
程式設計模型和架構曝光
Ironwood 的程式設計模型與 TPU v4 之前的 TPU 世代 (例如 TPU v3) 相似。新架構會透過下列方式公開:
每個晶片有兩個裝置:JAX 等架構會將每個 Ironwood 晶片公開為兩個獨立的「裝置」,每個晶片各有一個。
晶片規格:您可以指定要用於運算的晶片。JAX 會在拓撲規格中新增第四個維度,以區分晶片。這個設計可讓您重複使用現有軟體模型,並盡量減少變更。
如要進一步瞭解如何透過雙晶片架構達到最佳效能,請參閱「Ironwood 雙晶片架構的效能建議」。
支援的設定
TPU7x 晶片會直接連線至 3D 空間中最鄰近的晶片,形成 3D 網格的網路連線。大於 64 個晶片的 Slice 由一或多個 4x4x4 的晶片「立方體」組成。
TPU7x 晶片採用 3D 環面互連拓撲。這種拓撲可讓切片最多擴充至 9216 個晶片。每個軸的雙向頻寬為 200 GBps,用於 Pod 內晶片之間的通訊。
下表列出 TPU7x 支援的常見 3D 切片形狀:
| 拓撲 | TPU 晶片 | 主機 | VM | 方塊 | 範圍 |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | 單一主機 |
| 2x2x2 | 8 | 2 | 2 | 1/8 | 多主機 |
| 2x2x4 | 16 | 4 | 4 | 1/4 | 多主機 |
| 2x4x4 | 32 | 8 | 8 | 1/2 | 多主機 |
| 4x4x4 | 64 | 16 | 16 | 1 | 多主機 |
| 4x4x8 | 128 | 32 | 32 | 2 | 多主機 |
| 4x8x8 | 256 | 64 | 64 | 4 | 多主機 |
| 8x8x8 | 512 | 128 | 128 | 8 | 多主機 |
| 8x8x16 | 1024 | 256 | 256 | 16 | 多主機 |
| 8x16x16 | 2048 | 512 | 512 | 32 | 多主機 |
TPU7x VM
每個 TPU7x 虛擬機器 (VM) 包含 4 個晶片。每個 VM 都能存取兩個 NUMA 節點。如要進一步瞭解 NUMA 節點,請參閱維基百科的「非統一記憶體存取」一文。
所有 TPU7x 節點都使用完整主機的 4 晶片 VM。TPU7x VM 的技術規格如下:
- 每個 VM 的 vCPU 數量:224
- 每個 VM 的 RAM:960 GB
- 每個 VM 的 NUMA 節點數量:2
Hyperdisk
根據預設,TPU7x 的 VM 開機磁碟為 Hyperdisk Balanced。您可以將更多磁碟連接至 TPU VM,以增加儲存空間。TPU7x 支援下列磁碟類型:
- Hyperdisk Balanced
- Hyperdisk ML
如要進一步瞭解 Hyperdisk,請參閱 Hyperdisk 總覽。如要進一步瞭解 Cloud TPU 的儲存空間選項,請參閱「Cloud TPU 資料的儲存空間選項」。
後續步驟
- 透過 GKE 使用 TPU7x
- 搭配 TPU Cluster Director 使用 TPU7x
- 使用 Google Cloud ML Diagnostics 平台最佳化及診斷工作負載
- 使用針對 TPU7x 最佳化的配方執行訓練工作負載
- 執行 TPU7x 微基準測試
- Ironwood 效能最佳化
- 在 GKE 上使用多層檢查點訓練大規模機器學習模型