
TPU7x (Ironwood)
Halaman ini menjelaskan arsitektur dan konfigurasi yang tersedia untuk TPU7x, TPU terbaru yang tersedia di Google Cloud. TPU7x adalah rilis pertama dalam keluarga Ironwood,TPU generasi ketujuh Google Cloud. Generasi Ironwood dirancang untuk pelatihan dan inferensi AI berskala besar.
Dengan footprint 9.216 chip per Pod, TPU7x memiliki banyak kesamaan dengan TPU v5p. TPU7x memberikan performa tinggi untuk model MoE dan padat berskala besar, pelatihan awal, pengambilan sampel, dan inferensi yang banyak menggunakan decoding.
Untuk menggunakan TPU7x, Anda dapat menggunakan Google Kubernetes Engine (GKE) atau Compute Engine. Untuk mengetahui informasi selengkapnya tentang penggunaan TPU dengan GKE, lihat Tentang TPU di GKE.
Anda juga dapat menggunakan TPU7x dan GKE dengan TPU Cluster Director. TPU Cluster Director tersedia melalui reservasi mode Semua Kapasitas, yang memberi Anda akses penuh ke semua kapasitas yang Anda pesan (tanpa penahanan) dan visibilitas penuh ke topologi hardware TPU, status pemanfaatan, dan status kondisi. Untuk mengetahui informasi selengkapnya, lihat Ringkasan mode Semua Kapasitas.
Arsitektur sistem
Setiap chip TPU7x berisi dua TensorCore dan empat SparseCore. Tabel berikut menunjukkan spesifikasi utama dan nilainya untuk TPU7x dibandingkan dengan generasi sebelumnya.
| Spesifikasi | v5p | v6e (Trillium) | TPU7x (Ironwood) |
|---|---|---|---|
| Jumlah chip per pod | 8960 | 256 | 9216 |
| Komputasi puncak per chip (BF16) (TFLOPs) | 459 | 918 | 2307 |
| Komputasi puncak per chip (FP8) (TFLOPs) | 459 | 918 | 4614 |
| Kapasitas HBM per chip (GiB) | 95 | 32 | 192 |
| Bandwidth HBM per chip (GBps) | 2765 | 1638 | 7380 |
| Jumlah vCPU (VM 4 chip) | 208 | 180 | 224 |
| RAM (GB) (VM 4 chip) | 448 | 720 | 960 |
| Jumlah TensorCore per chip | 2 | 1 | 2 |
| Jumlah SparseCore per chip | 4 | 2 | 4 |
| Bandwidth interkoneksi antar-chip (ICI) dua arah per chip (GBps) | 1200 | 800 | 1200 |
| Bandwidth jaringan pusat data (DCN) per chip (Gbps) | 50 | 100 | 100 |
Diagram berikut mengilustrasikan arsitektur Ironwood:
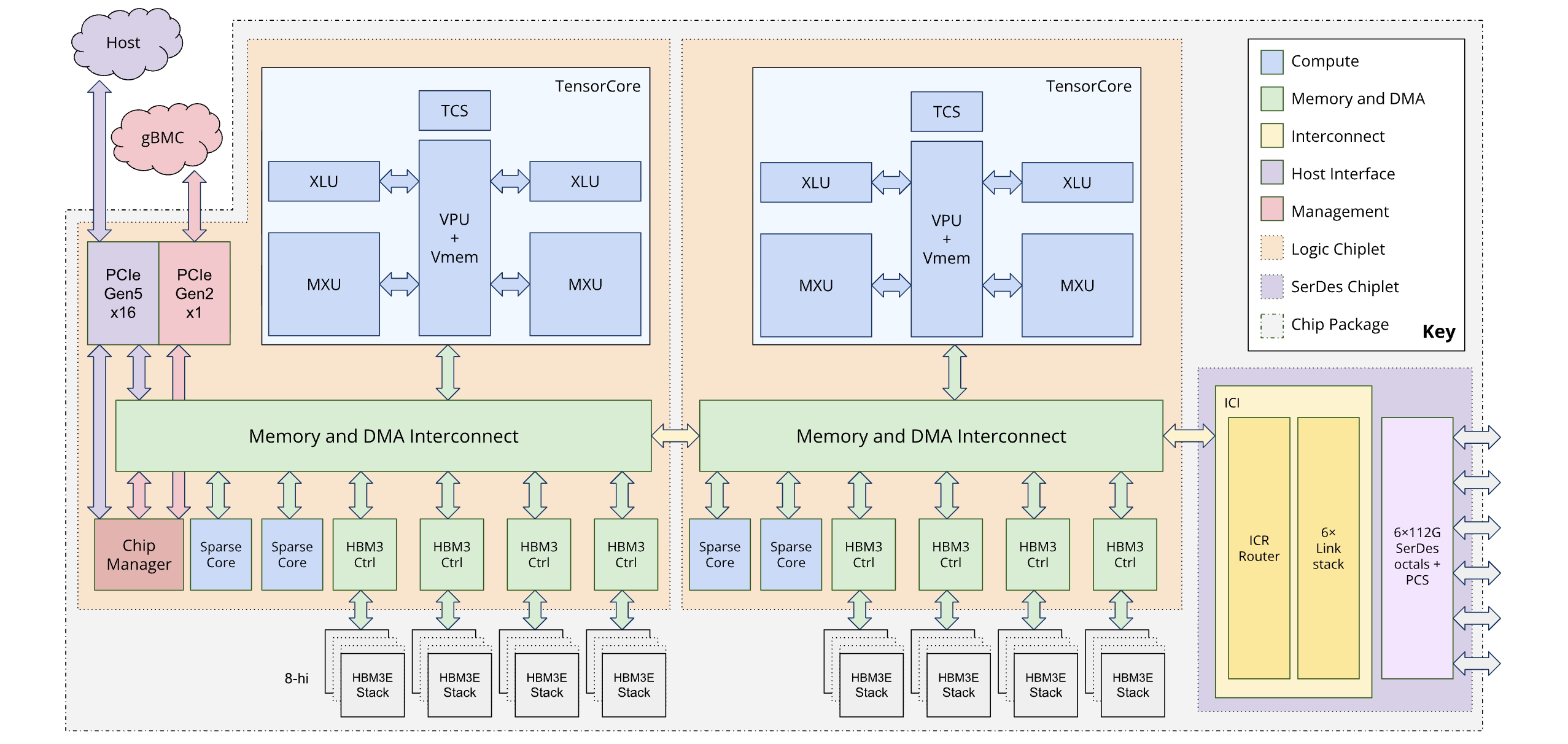
Hierarki memori
TPU7x memiliki sistem memori bertingkat, dan pengelolaan pergerakan data antar-tingkatan ini sangat penting untuk performa:
- Memori bandwidth tinggi (HBM): Setiap chip dilengkapi dengan HBM 192 GB, dengan bandwidth sekitar 7,37 TB/dtk. Kapasitas HBM yang besar memungkinkan ukuran batch yang besar, yang dapat meningkatkan throughput. Namun, meskipun ukurannya besar, HBM masih dapat menjadi hambatan, terutama untuk operasi vektor yang terikat memori atau pola akses data yang tidak efisien.
- Memori vektor (VMEM): VMEM adalah SRAM (static random-access memory) on-chip yang lebih kecil dengan bandwidth yang jauh lebih tinggi ke Matrix Multiply Unit (MXU) daripada HBM. Memori ini berfungsi sebagai ruang kerja berkecepatan tinggi untuk kernel kustom. Ukuran buffer ini adalah parameter yang dapat disesuaikan. Mengoptimalkan ukuran buffer sangat penting untuk menyetel kernel Pallas kustom, karena ukuran bloknya sering kali dibatasi oleh VMEM yang tersedia.
- Memori host dan PCIe: Setiap set empat chip TPU terhubung ke host CPU menggunakan jaringan PCIe. Meskipun koneksi ini memiliki bandwidth yang jauh lebih rendah daripada HBM, memori utama host dapat digunakan untuk memindahkan aktivasi atau status pengoptimalan guna mengosongkan HBM, sebuah teknik yang sangat berguna untuk mengelola tekanan memori dalam model besar.
Untuk mengetahui informasi selengkapnya tentang cara mengelola pergerakan data secara efisien di antara tingkat hierarki memori TPU7x, lihat Pengoptimalan performa Ironwood.
Arsitektur chiplet ganda
Model pemrograman Ironwood memungkinkan Anda mengakses dua chiplet TPU, bukan satu arsitektur inti logis (juga dikenal sebagai MegaCore) yang digunakan pada generasi sebelumnya (TPU v4 dan v5p). Perubahan ini meningkatkan efektivitas biaya dan efisiensi pembuatan chip. Meskipun hal ini merupakan perubahan arsitektur, desain baru memastikan bahwa Anda dapat menggunakan kembali model software yang ada dengan perubahan minimal.
TPU Ironwood terdiri dari dua chiplet berbeda, yang masing-masing memiliki ruang memori khusus. Hal ini berbeda dengan ruang memori terpadu arsitektur MegaCore.
Komposisi chiplet: Setiap chiplet adalah unit mandiri dengan satu TensorCore, dua SparseCore, dan memori bandwidth tinggi (HBM) 96 GB.
Interkoneksi berkecepatan tinggi: Kedua chiplet terhubung oleh antarmuka die-to-die (D2D) yang enam kali lebih cepat daripada link interkoneksi antar-chip (ICI) 1D. Komunikasi antar-chiplet dikelola menggunakan operasi kolektif.
Eksposur model dan framework pemrograman
Model pemrograman untuk Ironwood mirip dengan model generasi TPU yang lebih awal dari v4, seperti TPU v3. Arsitektur baru ini diekspos dengan cara berikut:
Dua perangkat per chip: Framework seperti JAX mengekspos setiap chip Ironwood sebagai dua "perangkat" terpisah, satu untuk setiap chiplet.
Spesifikasi chiplet: Anda dapat menentukan chiplet yang akan digunakan untuk komputasi. JAX menambahkan dimensi keempat ke spesifikasi topologi untuk membedakan antara chiplet. Desain ini memungkinkan Anda menggunakan kembali model software yang ada dengan sedikit perubahan.
Untuk mengetahui informasi selengkapnya tentang cara mencapai performa optimal dengan arsitektur dual-chiplet, lihat Rekomendasi performa untuk arsitektur dual-chiplet Ironwood
Konfigurasi yang didukung
Chip TPU7x memiliki koneksi langsung ke chip tetangga terdekat dalam 3 dimensi, sehingga menghasilkan mesh 3D dari koneksi jaringan. Slice yang lebih besar dari 64 chip terdiri dari satu atau beberapa "kubus" chip 4x4x4.
Chip TPU7x memiliki topologi interkoneksi torus 3D. Topologi ini memungkinkan slice untuk peningkatan skala hingga 9216 chip. Memiliki bandwidth dua arah sebesar 200 GBps per sumbu untuk komunikasi antar-chip dalam pod.
Tabel berikut menunjukkan bentuk irisan 3D umum yang didukung untuk TPU7x:
| Topologi | Chip TPU | Host | VM | Kubus | Cakupan |
|---|---|---|---|---|---|
| 2x2x1 | 4 | 1 | 1 | 1/16 | Host tunggal |
| 2x2x2 | 8 | 2 | 2 | 1/8 | Multi-host |
| 2x2x4 | 16 | 4 | 4 | 1/4 | Multi-host |
| 2x4x4 | 32 | 8 | 8 | 1/2 | Multi-host |
| 4x4x4 | 64 | 16 | 16 | 1 | Multi-host |
| 4x4x8 | 128 | 32 | 32 | 2 | Multi-host |
| 4x8x8 | 256 | 64 | 64 | 4 | Multi-host |
| 8x8x8 | 512 | 128 | 128 | 8 | Multi-host |
| 8x8x16 | 1024 | 256 | 256 | 16 | Multi-host |
| 8x16x16 | 2048 | 512 | 512 | 32 | Multi-host |
VM TPU7x
Setiap mesin virtual (VM) TPU7x berisi 4 chip. Setiap VM memiliki akses ke dua node NUMA. Untuk mengetahui informasi selengkapnya tentang node NUMA, lihat Akses memori tidak seragam di Wikipedia.
Semua slice TPU7x menggunakan VM 4 chip host penuh. Spesifikasi teknis untuk VM TPU7x adalah:
- Jumlah vCPU per VM: 224
- RAM per VM: 960 GB
- Jumlah node NUMA per VM: 2
Hyperdisk
Secara default, disk boot VM untuk TPU7x adalah Hyperdisk Balanced. Anda dapat melampirkan lebih banyak disk ke VM TPU untuk penyimpanan tambahan. Jenis disk berikut didukung di TPU7x:
- Hyperdisk Balanced
- Hyperdisk ML
Untuk mengetahui informasi selengkapnya tentang Hyperdisk, lihat Ringkasan Hyperdisk. Untuk mengetahui informasi selengkapnya tentang opsi penyimpanan untuk Cloud TPU, lihat Opsi penyimpanan untuk data Cloud TPU.
Langkah berikutnya
- Menggunakan TPU7x dengan GKE
- Menggunakan TPU7x dengan TPU Cluster Director
- Gunakan platform Diagnostik ML Google Cloud untuk mengoptimalkan dan mendiagnosis beban kerja Anda
- Menjalankan workload pelatihan menggunakan resep yang dioptimalkan untuk TPU7x
- Menjalankan microbenchmark TPU7x
- Pengoptimalan performa Ironwood
- Melatih model machine learning berskala besar di GKE dengan Checkpointing Multi-Tier