
במאמר הזה מוסבר איך Cloud TPU פועל עם Google Kubernetes Engine (GKE), כולל מינוח, היתרונות של יחידות לעיבוד טנסורים (TPU) ושיקולים לגבי תזמון עומסי עבודה. יחידות TPU הן מעגלים משולבים לאפליקציות ספציפיות (ASIC) שפותחו על ידי Google כדי להאיץ עומסי עבודה של למידת מכונה שמשתמשים ב-frameworks כמו TensorFlow, PyTorch ו-JAX.
המסמך הזה מיועד לאדמינים ולמפעילים של פלטפורמות, ולמומחים בתחום הנתונים וה-AI שמריצים מודלים של למידת מכונה (ML) עם מאפיינים כמו היקף גדול, הרצה ארוכה או דומיננטיות של חישובי מטריצות. כדי לקבל מידע נוסף על תפקידים נפוצים ועל משימות לדוגמה שאנחנו מתייחסים אליהן בתוכן של Google Cloud, אפשר לעיין במאמר תפקידי משתמשים נפוצים ומשימות ב-GKE.
לפני שקוראים את המסמך הזה, חשוב להבין איך פועלים מאיצי ML. לפרטים, אפשר לקרוא את המאמר מבוא ל-Cloud TPU.
יתרונות השימוש במעבדי TPU ב-GKE
GKE מספק תמיכה מלאה בניהול מחזור החיים של צומתי TPU ושל מאגרי צומתי TPU, כולל יצירה, הגדרה ומחיקה של מכונות וירטואליות של TPU. GKE תומך גם במכונות וירטואליות זמניות ובשימוש ב-Cloud TPU שמור. מידע נוסף מופיע במאמר בנושא אפשרויות צריכה של Cloud TPU.
היתרונות של שימוש ב-TPU ב-GKE כוללים:
- סביבת הפעלה עקבית: אפשר להשתמש בפלטפורמה אחת לכל עומסי העבודה של למידת מכונה ועומסי עבודה אחרים.
- שדרוגים אוטומטיים: GKE מבצע עדכוני גרסה באופן אוטומטי, וכך מצמצם את התקורה התפעולית.
- איזון עומסים: GKE מפזר את העומס, וכך מקטין את זמן האחזור ומשפר את המהימנות.
- התאמה אוטומטית לעומס: GKE מתאים אוטומטית את משאבי ה-TPU בהתאם לצרכים של עומסי העבודה.
- ניהול משאבים: בעזרת Kueue, מערכת מקורית של Kubernetes להוספת משימות לתור, אתם יכולים לנהל משאבים בכמה דיירים בארגון שלכם באמצעות הוספה לתור, קדימות, תעדוף ושיתוף הוגן.
- אפשרויות של ארגז חול: GKE Sandbox עוזר להגן על עומסי העבודה באמצעות gVisor. מידע נוסף זמין במאמר GKE Sandbox.
תחילת העבודה עם Ironwood (TPU7x)
Ironwood (TPU7x) הוא ה-TPU מהדור השביעי של Google, שנועד לעומסי עבודה של AI בקנה מידה גדול. מידע נוסף על היתרונות של Ironwood (TPU7x) זמין במאמר מידע על Ironwood (TPU7x) ב-GKE.
מינוח שקשור למעבדי TPU ב-GKE
במסמך הזה אנחנו משתמשים במינוח הבא שקשור ל-TPU:
- עמידות של Cloud TPU ICI: תכונה שעוזרת לשפר את הסבילות לשגיאות של הקישורים האופטיים ושל מתגי המעגלים האופטיים (OCS) שמקשרים בין יחידות TPU בתוך קוביות. מידע נוסף זמין במאמר בנושא ארכיטקטורת TPU.
- קוביית TPU: טופולוגיה של
4x4x4שבבי TPU שמחוברים ביניהם. האפשרות הזו רלוונטית רק לטופולוגיות ב-3-tuples ({A}x{B}x{C}). - TPU type: סוג ה-Cloud TPU, כמו v5e.
- פרוסת TPU: אוסף של שבבים שנמצאים כולם באותו TPU Pod ומחוברים באמצעות חיבורים מהירים בין השבבים (ICI). הפרוסות מתוארות במונחים של צ'יפים או TensorCores, בהתאם לגרסת ה-TPU.
- צומת TPU slice: צומת Kubernetes שמיוצג על ידי מכונה וירטואלית אחת עם שבב TPU אחד או יותר שמחוברים ביניהם.
- מאגר צמתים של פרוסות TPU: קבוצה של צמתי Kubernetes באותו אשכול, שלכולם יש את אותה הגדרת TPU.
- TPU topology: המספר והסידור הפיזי של שבבי ה-TPU ב-TPU slice.
- אטומי: ב-GKE, כל הצמתים המקושרים נחשבים ליחידה אחת. במהלך פעולות שינוי גודל, GKE משנה את הגודל של כל קבוצת הצמתים ל-0 ויוצר צמתים חדשים. אם מכונה בקבוצה נכשלת או מסיימת את הפעולה, GKE יוצר מחדש את כל קבוצת הצמתים כיחידה חדשה.
- בלתי משתנה: אי אפשר להוסיף ידנית צמתים חדשים לקבוצת הצמתים המקושרים. עם זאת, אפשר ליצור מאגר צמתים חדש עם טופולוגיית ה-TPU הרצויה ולתזמן את עומסי העבודה במאגר הצמתים החדש.
סוגים של מאגרי צמתים של פרוסות TPU
GKE תומך בשני סוגים של מאגרי צומתי TPU:
סוג ה-TPU והטופולוגיה קובעים אם צומת ה-TPU slice יכול להיות multi-host או single-host. מה אנחנו ממליצים לעשות:
- למודלים בקנה מידה גדול, משתמשים בצמתים של פרוסות TPU מרובות מארחים.
- למודלים בקנה מידה קטן, משתמשים בצמתים של פרוסות TPU במארח יחיד.
- להדרכה או להסקת מסקנות בקנה מידה גדול, אפשר להשתמש ב-Pathways. Pathways מפשטת חישובים של למידת מכונה בהיקפים גדולים, כי היא מאפשרת ללקוח JAX יחיד לתזמן עומסי עבודה בכמה חלקי TPU גדולים. מידע נוסף זמין במאמר בנושא Pathways.
מאגרי צמתים של פרוסות TPU עם מספר מארחים
מאגר צמתים של פרוסת TPU עם כמה מארחים הוא מאגר צמתים שמכיל שתי מכונות וירטואליות של TPU או יותר, שמחוברות ביניהן. לכל מכונה וירטואלית מחובר מכשיר TPU. ה-TPU ב-TPU slice עם כמה מארחים מחוברים באמצעות חיבור מהיר בין רכיבים (ICI). אחרי שיוצרים מאגר צמתים של פרוסת TPU עם כמה מארחים, אי אפשר להוסיף לו צמתים. לדוגמה, אי אפשר ליצור מאגר צמתים של v4-32 ואז להוסיף מאוחר יותר צומת Kubernetes (TPU VM) למאגר הצמתים. כדי להוסיף פרוסת TPU לאשכול GKE, צריך ליצור מאגר צמתים חדש.
המכונות הווירטואליות במאגר צמתים של פרוסת TPU עם כמה מארחים נחשבות ליחידה אטומית אחת. אם GKE לא מצליח לפרוס צומת אחד בפרוסת ה-TPU, לא נפרסים צמתים בפרוסת ה-TPU.
אם צריך לתקן צומת בפריסת TPU מרובת-מארחים, GKE משבית את כל מכונות ה-VM בפריסת ה-TPU, וכך מאלץ את פינוי כל ה-Pods של Kubernetes בעומס העבודה. אחרי שכל מכונות ה-VM בפרוסת ה-TPU יפעלו, אפשר יהיה לתזמן את ה-Pods של Kubernetes במכונות ה-VM בפרוסת ה-TPU החדשה.
בתרשים הבא מוצג פרוס TPU מרובה-מארחים v5litepod-16 (v5e). לפרוסת ה-TPU הזו יש ארבע מכונות וירטואליות. לכל מכונה וירטואלית בפרוסת ה-TPU יש ארבעה שבבי TPU v5e שמחוברים באמצעות חיבורים מהירים בין רכיבים (ICI), ולכל שבב TPU v5e יש TensorCore אחד:
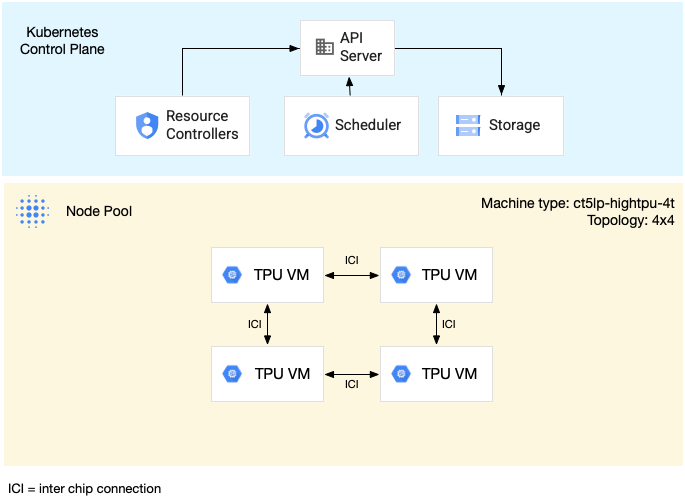
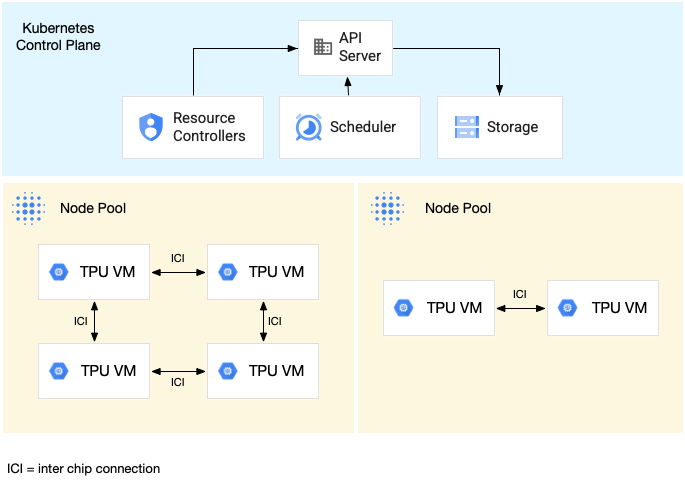
בתרשים הבא מוצג אשכול GKE שמכיל פרוסת TPU אחת v5litepod-16 (v5e) (טופולוגיה: 4x4) ופרוסת TPU אחת v5litepod-8 (v5e) (טופולוגיה: 2x4):
מאגרי צמתים של חלקי TPU במארח יחיד
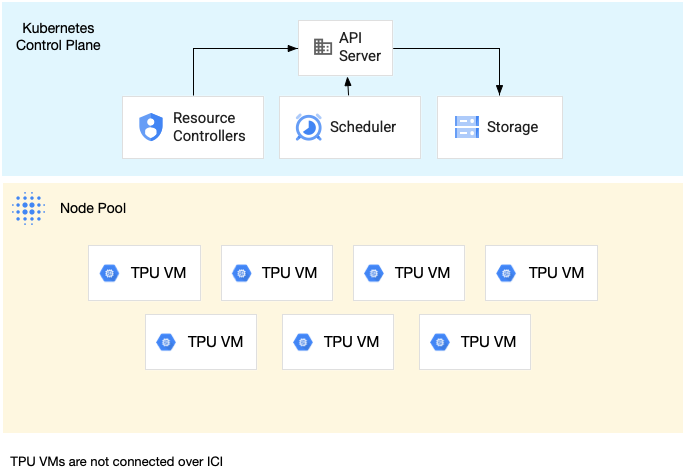
מאגר צמתים של פרוסת מארח יחיד הוא מאגר צמתים שמכיל מכונות וירטואליות עצמאיות של TPU. לכל מכונה וירטואלית מחובר מכשיר TPU. אמנם מכונות ה-VM במאגר צמתים של פרוסת מארח יחיד יכולות לתקשר דרך רשת מרכז הנתונים (DCN), אבל יחידות ה-TPU שמצורפות למכונות ה-VM לא מחוברות זו לזו.
בתרשים הבא מוצגת דוגמה לפרוסת TPU במארח יחיד שמכילה שבע מכונות v4-8:
מאפיינים של מעבדי TPU ב-GKE
ל-TPU יש מאפיינים ייחודיים שדורשים תכנון והגדרה מיוחדים.
צריכת TPU
כדי לבצע אופטימיזציה של השימוש במשאבים והעלויות תוך שמירה על איזון בין ביצועי עומס העבודה, GKE תומך באפשרויות הבאות לשימוש ב-TPU:
- Flex-start: כדי להקצות מכונות וירטואליות מסוג Flex-start למשך עד שבעה ימים, כאשר GKE מקצה את החומרה באופן אוטומטי על בסיס הזמינות. מידע נוסף מופיע במאמר מידע על הקצאת GPU, TPU ו-H4D במצב הקצאה עם הפעלה גמישה.
- מכונות וירטואליות (VM) זמניות מסוג Spot: כדי להקצות מכונות וירטואליות זמניות מסוג Spot, אפשר לקבל הנחות משמעותיות, אבל המכונות האלה יכולות להיפסק בכל שלב, עם אזהרה של 30 שניות מראש. מידע נוסף זמין במאמר בנושא מכונות וירטואליות מסוג Spot.
- מקום שמור לעתיד לפרק זמן של עד 90 יום (במצב לוח שנה): הקצאת משאבי TPU לפרק זמן של עד 90 יום. מידע נוסף זמין במאמר בנושא שליחת בקשה ל-TPU עם מקום שמור לעתיד במצב יומן.
- הזמנות של TPU: כדי לבקש מקום שמור לעתיד למשך שנה או יותר.
- על פי דרישה: כדי להשתמש ב-TPU בלי לתכנן מראש את הקיבולת. לפני שמבקשים משאבים, צריך לוודא שיש לכם מספיק מכסת משאבים לפי דרישה לסוג ולכמות הספציפיים של מכונות TPU וירטואליות. האפשרות 'על פי דרישה' היא האפשרות הכי גמישה לשימוש במשאבים, אבל אין ערובה לכך שיהיו מספיק משאבים על פי דרישה כדי לספק את הבקשה שלכם.
אם לא מציינים אפשרות אחרת, מודל הצריכה שמוגדר כברירת מחדל ל-TPU ב-GKE הוא לפי דרישה. כדי לבחור את אפשרות הצריכה שתתאים לדרישות של עומס העבודה שלכם, אפשר לעיין במאמר מידע על אפשרויות צריכת מאיצים לעומסי עבודה של AI/ML ב-GKE.
לפני שמשתמשים ב-TPU ב-GKE, צריך לבחור את אפשרות הצריכה שהכי מתאימה לדרישות של עומס העבודה.
טופולוגיה
הטופולוגיה מגדירה את הסידור הפיזי של יחידות ה-TPU בפריסת TPU. GKE מקצה פרוסת TPU בטופולוגיות דו-ממדיות או תלת-ממדיות, בהתאם לגרסת ה-TPU. מגדירים טופולוגיה כמספר שבבי ה-TPU בכל מימד באופן הבא:
ב-TPU v4, v5p ו-Ironwood (TPU7x) שמתוזמנים במאגרי צמתים של פרוסות TPU מרובות מארחים, מגדירים את הטופולוגיה ב-3-tuples ({A}x{B}x{C}), לדוגמה 4x4x4. התוצאה של
{A}x{B}x{C} מגדירה את מספר שבבי ה-TPU במאגר הצמתים. לדוגמה, אפשר להגדיר טופולוגיות קטנות עם פחות מ-64 שבבי TPU עם צורות טופולוגיה כמו 2x2x2, 2x2x4 או 2x4x4. אם משתמשים בטופולוגיות גדולות יותר עם יותר מ-64 שבבי TPU, הערכים שמוקצים ל-{A}, {B} ו-{C} צריכים לעמוד בתנאים הבאים:
- הערכים {A}, {B} ו-{C} חייבים להיות כפולות של ארבע.
- הטופולוגיה הגדולה ביותר שנתמכת בגרסה 4 היא
12x16x16ובגרסה 5p היא16x16x24. - הערכים שמוקצים צריכים להיות בתבנית A ≤ B ≤ C. לדוגמה,
4x4x8או8x8x8.
שמות של סוגי מכונות
השמות של סוגי המכונות של TPUs ב-GKE משתנים בהתאם למצב האשכול ולגרסת ה-TPU:
GKE Standard: בוחרים סוג מכונה ספציפי של Compute Engine, לדוגמה,
ct6e-standard-1tל-TPU Trillium (v6e).GKE Autopilot: לא בוחרים סוגי מכונות באופן ישיר. במקום זאת, אתם מבקשים יחידות TPU באמצעות סוג מאיץ במניפסט של עומס העבודה. לדוגמה, אפשר להשתמש ב-
tpu-v6e-sliceעבור TPU Trillium (v6e) או ב-tpu-v5-lite-podsliceעבור TPU v5e. לאחר מכן, GKE Autopilot מקצה את הצמתים הבסיסיים עם סוגי המכונות המתאימים כדי למלא את הבקשה.
כדי לראות את סוגי המכונות המדויקים שזמינים לכל גרסת TPU, אפשר לעיין בטבלאות שבמאמר תכנון השימוש ב-TPU ב-GKE.
מצב הרשאה
אם אתם משתמשים בגרסאות GKE מוקדמות יותר מ-1.28, אתם צריכים להגדיר את הקונטיינרים עם יכולות מיוחדות כדי לגשת ל-TPU. באשכולות במצב Standard, אפשר להשתמש במצב הרשאות כדי להעניק את הגישה הזו. מצב הרשאות יתר מבטל הרבה מהגדרות האבטחה האחרות ב-securityContext. פרטים נוספים זמינים במאמר בנושא הפעלת מאגרי תגים ללא מצב הרשאות.
בגרסאות 1.28 ואילך לא נדרש מצב הרשאות או יכולות מיוחדות.
איך מכשירי TPU ב-GKE פועלים
בניהול משאבים ובקביעת סדר עדיפויות ב-Kubernetes, מכונות וירטואליות ב-TPU מקבלות יחס זהה לזה של סוגים אחרים של מכונות וירטואליות. כדי לבקש צ'יפים של TPU, משתמשים בשם המשאב google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
כשמשתמשים ב-TPU ב-GKE, כדאי לקחת בחשבון את המאפיינים הבאים של TPU:
- מכונה וירטואלית יכולה לגשת לעד 8 שבבי TPU.
- פרוסת TPU מכילה מספר קבוע של שבבי TPU, והמספר תלוי בסוג מכונת ה-TPU שבוחרים.
- מספר ה-
google.com/tpuהמבוקש צריך להיות שווה למספר הכולל של שבבי ה-TPU הזמינים בצומת של פרוסת ה-TPU. כל קונטיינר ב-Pod של GKE שמבקש TPU חייב להשתמש בכל שבבי ה-TPU בצומת. אחרת, הפריסה תיכשל כי GKE לא יכול להשתמש במשאבי TPU באופן חלקי. כדאי להביא בחשבון את התרחישים הבאים:- סוג המכונה
ct5lp-hightpu-4tעם טופולוגיה של2x4מכיל שני צמתי TPU slice עם ארבעה צ'יפים של TPU כל אחד, כלומר סך הכול שמונה צ'יפים של TPU. עם סוג המכונה הזה, אתם יכולים: - אי אפשר לפרוס GKE Pod שנדרשים לו שמונה שבבי TPU בצמתים במאגר הצמתים הזה.
- אפשר לפרוס שני Pods שכל אחד מהם דורש ארבעה שבבי TPU, כאשר כל Pod נמצא באחד משני הצמתים במאגר הצמתים הזה.
- TPU v5e עם טופולוגיה של 4x4 כולל 16 שבבי TPU בארבעה צמתים. עומס העבודה של GKE Autopilot שבוחר בהגדרה הזו צריך לבקש ארבעה שבבי TPU בכל עותק, לעותק אחד עד ארבעה.
- סוג המכונה
- באשכולים רגילים, אפשר לתזמן כמה פודי Kubernetes במכונה וירטואלית, אבל רק קונטיינר אחד בכל פוד יכול לגשת לשבבי ה-TPU.
- כדי ליצור פודים של kube-system, כמו kube-dns, לכל אשכול רגיל צריך להיות לפחות מאגר צמתים אחד של פרוסות שאינן TPU.
- כברירת מחדל, לצמתים של חלקי TPU יש
google.com/tputaint שמונע מעומסי עבודה שאינם TPU להיות מתוזמנים בצמתים של חלקי TPU. עומסי עבודה שלא משתמשים ב-TPU מופעלים בצמתים שאינם TPU, וכך מפנים משאבי מחשוב בצמתים של חלקי TPU לקוד שמשתמש ב-TPU. שימו לב: הדחייה (taint) לא מבטיחה ניצול מלא של משאבי TPU. - GKE אוסף את היומנים שנוצרים על ידי קונטיינרים שפועלים בצמתים של חלקי TPU. מידע נוסף זמין במאמר בנושא רישום ביומן.
- מדדי ניצול של TPU, כמו ביצועים בזמן ריצה, זמינים ב-Cloud Monitoring. מידע נוסף זמין במאמר בנושא יכולת צפייה ומדדים.
- אתם יכולים להשתמש ב-GKE Sandbox כדי להריץ את עומסי העבודה של TPU בסביבת ארגז חול. GKE Sandbox פועל עם מודלים של TPU מגרסה 4 ואילך. מידע נוסף זמין במאמר GKE Sandbox.
יצירה אוטומטית של מאגר צמתים עם מעבדי TPU
יצירה אוטומטית של מאגר צמתים תומכת ב-Cloud TPU הבאים רק בגרסאות ספציפיות של GKE:
- TPU v3: גרסה 1.31.0 ואילך.
- TPU v5 ו-TPU v4: גרסה 1.29.0 ואילך.
- TPU Trillium: גרסה 1.32.0 ואילך.
- Ironwood (TPU7x): גרסה 1.34.1-gke.2541000 ואילך.
יש תמיכה בסוגים אחרים של Cloud TPU בכל הגרסאות של GKE. מידע נוסף על גרסאות GKE שזמינות ל-TPU מופיע במאמר בנושא אימות הזמינות של TPU ב-GKE.
שינוי אוטומטי של גודל מאגר הצמתים ב-Cloud TPU
GKE משנה את הגודל של מאגרי צמתים של Cloud TPU שנוצרו באופן אוטומטי או באופן ידני, שמשתמשים ב-Cluster Autoscaler, באחת מהדרכים הבאות:
- מאגר צמתים של פרוסת TPU במארח יחיד: GKE מוסיף או מסיר צמתי TPU במאגר הצמתים הקיים. מאגר הצמתים יכול להכיל כל מספר של צמתי TPU בין אפס לבין הגודל המקסימלי של מאגר הצמתים, כפי שנקבע על ידי דגלי שינוי הגודל האוטומטי
--max-nodesו---total-max-nodes. לכל צמתי ה-TPU במאגר הצמתים יש את אותו סוג מכונה ואותה טופולוגיה. מידע נוסף על יצירת מאגר צמתים של פרוסת TPU במארח יחיד זמין במאמר יצירת מאגר צמתים של פרוסת TPU במארח יחיד. - מאגר צמתים של חלקי TPU עם כמה מארחים: מערכת GKE מבצעת הגדלה אטומית של מאגר הצמתים מאפס למספר הצמתים שנדרש כדי להתאים לטופולוגיית ה-TPU. לדוגמה, אם יש מאגר צמתים של TPU עם
ct5lp-hightpu-4tסוג מכונה וטופולוגיה של16x16, במאגר הצמתים תמיד יהיו 64 צמתים או אפס צמתים. מערכת GKE מצמצמת את מאגר הצמתים אם אין בו עומסי עבודה של TPU. כדי להקטין את מאגר הצמתים, GKE מוציא את כל ה-Pods המתוזמנים ומסיר את כל הצמתים במאגר הצמתים. מידע נוסף על יצירת מאגר צמתים של TPU slice עם כמה מארחים זמין במאמר יצירת מאגר צמתים של TPU slice עם כמה מארחים.
תזמון אוספים
תזמון של אוספים נתמך רק ב-TPU Trillium.
ב-TPU Trillium, אפשר להשתמש בתזמון איסוף כדי לקבץ צמתים של פרוסות TPU. קיבוץ של צמתי פרוסות TPU מקל על התאמת מספר הרפליקות כדי לעמוד בדרישות של עומס העבודה. Google Cloud הוא שולט בעדכוני תוכנה כדי להבטיח שתמיד יהיו מספיק פרוסות באוסף שיכולות לשרת תעבורה.
TPU Trillium תומך בתזמון איסוף עבור מאגרי צמתים עם מארח יחיד ומארחים מרובים שמריצים עומסי עבודה של הסקה. בהמשך מוסבר איך התנהגות התזמון של איסוף הנתונים משתנה בהתאם לסוג פרוסת ה-TPU שבה משתמשים:
- Multi-host TPU slice: GKE groups multi-host TPU slices to form a collection. כל מאגר צמתים של GKE הוא עותק משוכפל באוסף הזה. כדי להגדיר אוסף, יוצרים פלח TPU מרובה-מארחים ומקצים לאוסף שם ייחודי. כדי להוסיף עוד חלקי TPU לאוסף, יוצרים עוד מאגר צמתים של חלקי TPU עם כמה מארחים, עם אותו שם אוסף וסוג עומס עבודה.
- פרוסת TPU במארח יחיד: GKE מתייחס למאגר הצמתים של פרוסת TPU במארח יחיד כאל אוסף. כדי להוסיף עוד חלקי TPU לאוסף, אפשר לשנות את הגודל של מאגר הצמתים של חלקי ה-TPU במארח יחיד.
יש מגבלות על תזמון איסוף נתונים:
- אפשר לתזמן אוספים רק ל-TPU Trillium.
- אפשר להגדיר אוספים רק במהלך יצירת מאגר הצמתים.
- אין תמיכה במכונות וירטואליות מסוג Spot.
- במאגרי צמתים של פרוסות TPU עם כמה מארחים, כל מאגרי הצמתים באוסף צריכים להשתמש באותו סוג מכונה, באותה טופולוגיה ובאותה גרסה.
אפשר להגדיר תזמון של אוספים בתרחישים הבאים:
- כשיוצרים מאגר צמתים של חלקי TPU ב-GKE Standard
- כשפורסים עומסי עבודה ב-GKE Autopilot
- כשיוצרים אשכול שמופעלת בו הקצאת צמתים אוטומטית (NAP)
המאמרים הבאים
במאמרים הבאים מוסבר איך מגדירים Cloud TPU ב-GKE:
- כדי להתחיל בהגדרת TPU, אפשר לתכנן את השימוש ב-TPU ב-GKE.
- פריסת עומסי עבודה של TPU ב-GKE Autopilot
- פריסת עומסי עבודה של TPU ב-GKE Standard
- פריסת עומסי עבודה של GKE Cloud TPU ב-Cluster Toolkit
- שיטות מומלצות לשימוש ב-Cloud TPU למשימות של למידת מכונה
- סרטון: יצירת למידת מכונה בקנה מידה גדול ב-Cloud TPU באמצעות GKE
- הפעלת מודלי שפה גדולים באמצעות KubeRay ב-TPU
- מידע על שימוש בארגז חול (Sandbox) לעומסי עבודה של GPU באמצעות GKE Sandbox