
使用 JAX 在 Cloud TPU 上建構 AI 生產環境
JAX AI 堆疊擴充了 JAX 數值核心,並提供一系列 Google 支援的可組合程式庫,進而發展成強大的端對端開放原始碼平台,可進行極大規模的機器學習。因此,JAX AI 堆疊包含完整且強大的生態系統,可處理整個機器學習生命週期:
工業級基礎:JAX AI 堆疊專為大規模運算而設計,可運用 ML Pathways 在數萬個晶片上協調訓練作業,並使用 Orbax 進行彈性且高輸送量的非同步檢查點作業,進而訓練出最先進的生產級模型。
完整且可投入生產的工具包:JAX AI 堆疊提供一整套程式庫,可支援整個開發程序:Flax 可彈性編寫模型、Optax 可組合最佳化策略,以及 Grain 可提供確定性資料管線,確保大規模執行作業時可重現結果。
頂尖的專業效能:為充分運用硬體,JAX AI 堆疊提供專業程式庫,包括適用於最先進自訂核心的 Tokamax、適用於非侵入式量化 (可提升訓練和推論速度) 的 Qwix,以及適用於深入硬體整合式效能剖析的 XProf。
完整生產路徑:JAX AI 堆疊可讓您從研究階段順利過渡到部署階段。包括:MaxText,可做為基礎模型訓練的可擴充參考資料;Tunix,可進行最先進的強化學習 (RL) 和對齊作業;以及整合 vLLM TPU 和 JAX 服務執行階段的統一推論解決方案。
JAX AI 堆疊的哲學是鬆散耦合的元件,每個元件都擅長一件事。JAX 本身並非單一的機器學習架構,而是範圍狹窄,著重於高效陣列運算和程式轉換。這個核心架構是生態系統的基礎,可提供各種功能,包括訓練機器學習模型,以及科學運算等其他類型的工作負載。
這個鬆散耦合的元件系統可讓您選取及組合程式庫,以最適合的方式滿足需求。從軟體工程的角度來看,這個架構也讓您能以疊代方式更新傳統上視為核心架構元件的功能 (例如資料管道和檢查點),而不必擔心核心架構不穩定,或受限於發布週期。由於大部分功能都是在程式庫中實作,而非單一架構的變更,這讓核心數字程式庫更耐用,且能因應未來技術環境的變化。
以下各節將提供 JAX AI 堆疊的技術總覽、主要功能、背後的設計決策,以及這些功能如何結合,為現代機器學習工作負載建構耐用的平台。
JAX AI Stack 和其他生態系統元件
| 元件 | 功能 / 說明 |
|---|---|
| JAX AI Stack 核心和元件1 | |
| JAX | 以加速器為導向的陣列運算和程式轉換 (JIT、grad、vmap、pmap)。 |
| Flax | 彈性十足的類神經網路撰寫程式庫,可直覺地建立及修改模型。 |
| Optax | 可組合的梯度處理和最佳化轉換程式庫。 |
| Orbax | 「Any-scale」分散式檢查點程式庫,適用於大規模訓練,可提升復原能力。 |
| 穀物 | 可擴充、具決定性且可檢查點的輸入資料管道程式庫。 |
| JAX AI 堆疊 - 基礎架構 | |
| XLA | 適用於 TPU、CPU 和 GPU 的開放原始碼機器學習編譯器。 |
| Pathways | 分散式執行階段,可自動調度管理數萬個晶片的運算作業。 |
| JAX AI 堆疊 - 進階主題開發 | |
| 帕拉斯 | JAX 擴充功能,用於編寫以 Python 實作的低階高效能自訂核心。 |
| Tokamax | 精選程式庫,內含最先進的高效能自訂核心 (例如 Attention)。 |
| Qwix | 提供全面且不具侵入性的量化程式庫 (PTQ、QAT、QLoRA)。 |
| JAX AI Stack - 應用程式 | |
| MaxText / MaxDiffusion | 旗艦級可擴充參考架構,用於訓練基礎模型 (例如 LLM 和 Diffusion)。 |
| Tunix | 這個架構適用於訓練後和校正 (RLHF、DPO) 的先進技術。 |
| vLLM | 高效能 LLM 推論解決方案,內建 vLLM 架構整合功能。 |
| XProf | 深入整合硬體的分析器,可分析整個系統的效能。 |
1 包含在 jax-ai-stack Python 套件中。
圖 1:JAX AI 堆疊和生態系統元件
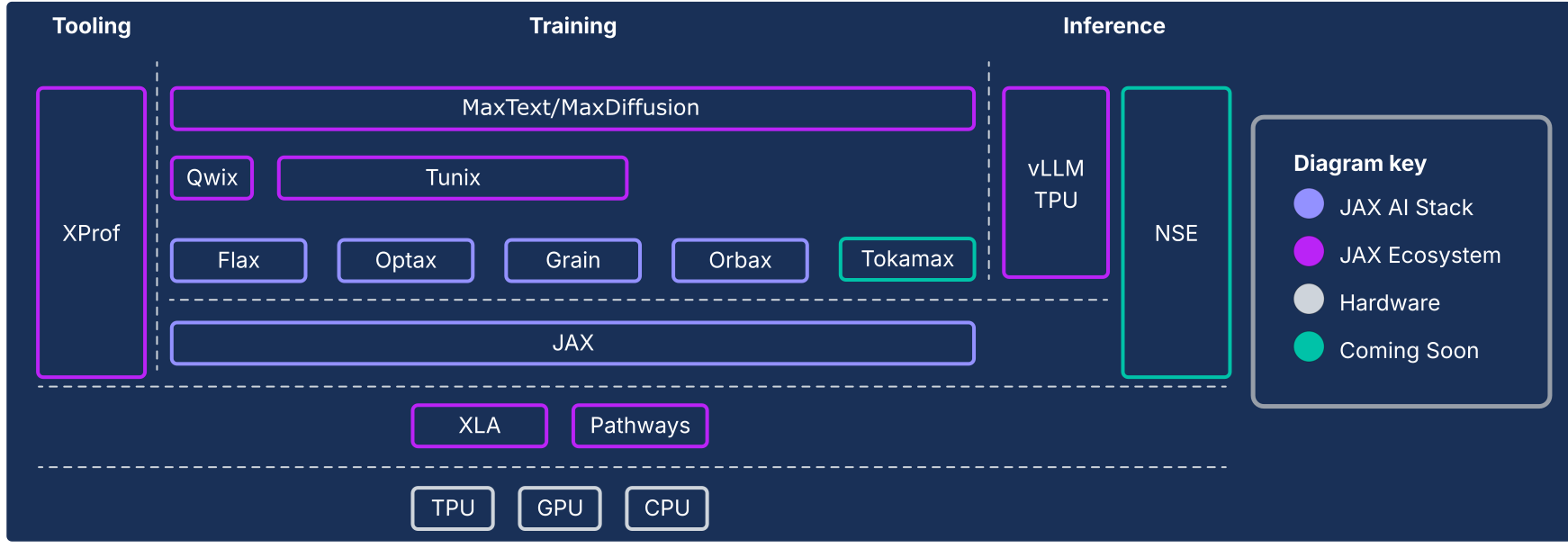
架構要務:超越架構的效能
隨著模型架構趨於一致 (例如多模態混合專家 (MoE) Transformer),追求最高效能的趨勢也帶動了巨型核心的出現。Megakernel 實際上是特定模型的前向傳遞 (或大部分) 過程,使用較低層級的 API (例如 NVIDIA GPU 上的 CUDA SDK) 手動編碼。這種做法會積極重疊運算、記憶體和通訊,盡量提高硬體使用率。研究社群的最新研究顯示,這種方法可大幅提升 GPU 推論的輸送量,在某些情況下甚至可提升 22% 以上。這項趨勢不僅限於推論;有證據顯示,部分大規模訓練工作涉及低階硬體控制,以大幅提升效率。
如果這個趨勢加速發展,所有現有的高階架構都有可能變得不那麼重要,因為對於成熟穩定的架構而言,最終決定效能的還是硬體低階存取權。這對所有現代機器學習堆疊來說都是一大挑戰:如何在不犧牲高階架構的生產力和彈性的情況下,提供專家級的硬體控制。
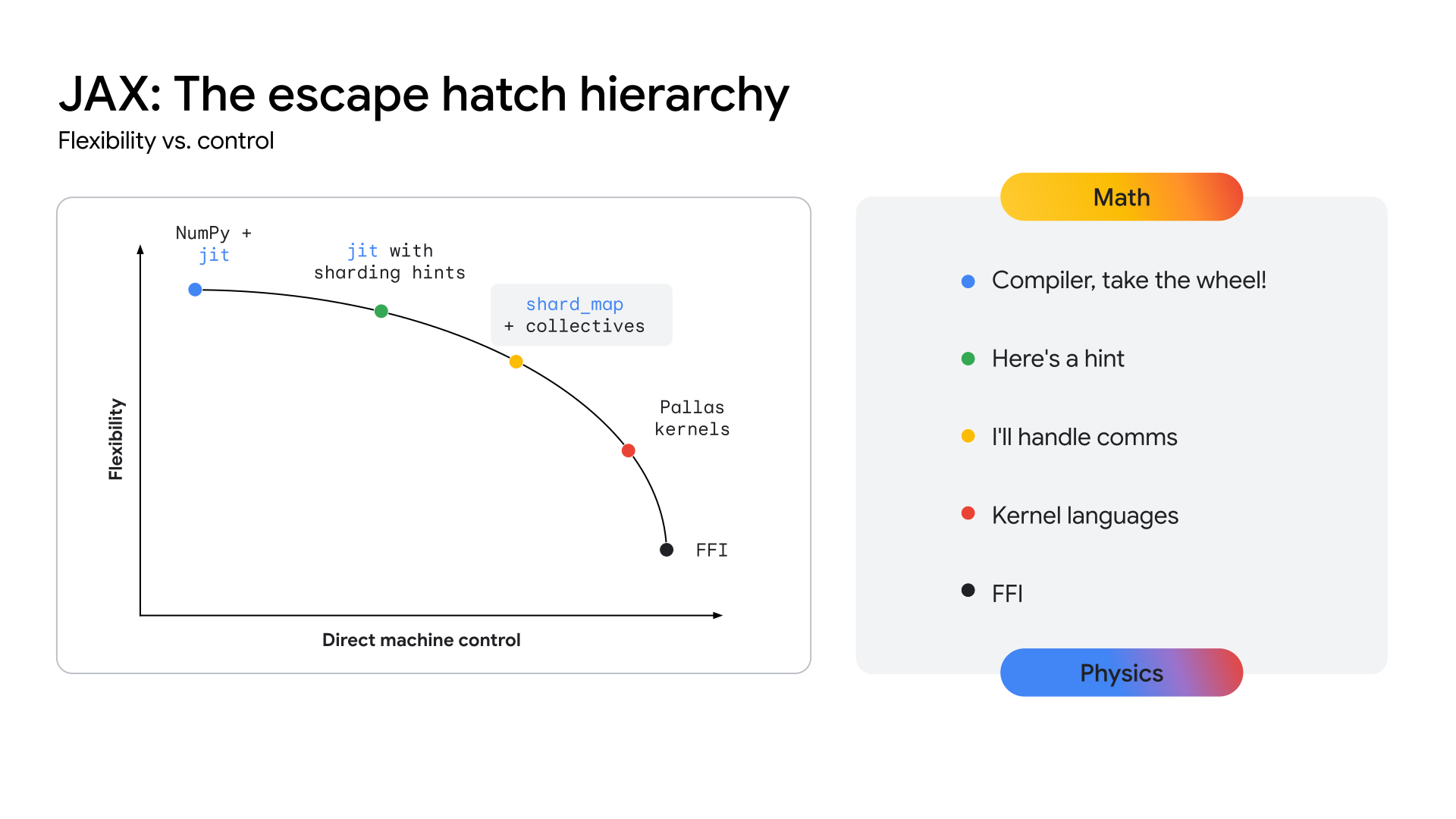
為了讓 TPU 清楚指引達到這個效能水準的路徑,生態系統必須公開更接近硬體的 API 層,才能開發這些高度專業化的核心。JAX 堆疊的設計宗旨是提供連續的抽象化層級 (請參閱圖 2),從 XLA 編譯器的自動化高階最佳化,到 Pallas 核心撰寫程式庫的精細手動控制,藉此解決這個問題。
圖 2:JAX 連續抽象化
核心 JAX AI 堆疊
JAX AI Stack 的核心包含五個重要程式庫,可做為模型開發的基礎:
JAX:可組合的高效能程式轉換基礎
JAX 是 Python 程式庫,專為加速器導向的陣列運算和程式轉換而設計,適用於高效能數值運算和大規模機器學習。JAX 採用函式程式設計模型和類似 NumPy 的 API,為高階程式庫奠定穩固基礎。
JAX 的設計以編譯器為優先,因此可透過XLA (請參閱 XLA 專區) 進行積極的全程式分析、最佳化和硬體目標設定,從本質上提升擴充性。JAX 強調函式程式設計 (例如純函式),因此核心程式轉換作業更易於處理,且最重要的是可組合。
您可以混用及搭配這些核心轉換,在模型大小、叢集大小和硬體類型之間,實現工作負載的高效能和擴充性:
- jit:將 Python 函式即時編譯為最佳化、融合的 XLA 可執行檔。
- grad:自動微分,支援正向和反向模式,以及高階衍生項目。
- vmap:自動向量化,可順暢批次處理資料,並以平行方式處理資料,不必修改函式邏輯。
- pmap / shard_map:在多部裝置 (例如 TPU 核心) 間自動平行化,形成分散式訓練的基礎。
與 XLA 的 GSPMD (通用 SPMD) 模型無縫整合後,JAX 就能自動在大型 TPU Pod 中平行處理運算,且只需進行極少的程式碼變更。在大多數情況下,您只需要高階分片註解即可進行資源調度。
Flax:彈性類神經網路撰寫
Flax 提供直覺式物件導向模型建構方法,簡化 JAX 中類神經網路的建立、偵錯和分析作業。JAX 的函式 API 功能強大,可為習慣使用 PyTorch 等架構的開發人員提供更熟悉的層級式抽象化,且不會造成任何效能損失。
這項設計可簡化經過訓練的模型元件的修改或合併作業。LoRA 和量化等技術需要可操控的模型定義,而 Flax 的 NNX API 透過 Python 介面提供這項功能。NNX 封裝模型狀態、減少使用者認知負荷,並允許以程式輔助方式遍歷及修改模型階層。
主要優勢:
- 直覺式物件導向 API:簡化模型建構作業,並支援進階用途,例如子模組替換和部分初始化。
- 與 JAX 核心一致:Flax 提供與 JAX 函式範例完全相容的升級轉換,不僅提供 JAX 的完整效能,也更方便開發人員使用。
Optax:可組合的梯度處理和最佳化策略
Optax 是 JAX 的梯度處理和最佳化程式庫。這項工具旨在為模型建構者提供建構區塊,讓他們能以自訂方式重新組合,訓練深度學習模型等應用程式。它以核心 JAX 程式庫的功能為基礎,提供經過充分測試的高效能損失和最佳化工具函式程式庫,以及可用於訓練機器學習模型的相關技術。
動機
損失的計算和最小化是機器學習模型訓練的核心。核心 JAX 程式庫支援自動微分,提供訓練模型所需的數值功能,但未提供熱門最佳化工具 (例如 RMSProp 或 Adam) 或損失 (例如 CrossEntropy 或 MSE) 的標準實作方式。您可以實作這些函式 (部分進階開發人員會選擇這麼做),但最佳化工具實作中的錯誤會導致模型品質問題,難以診斷。Optax 會提供這些演算法的實作項目,並測試正確性和效能,使用者不必自行實作這類重要項目。
最佳化理論領域完全屬於研究範疇,但由於在訓練中扮演核心角色,因此也是訓練生產 ML 模型不可或缺的一環。擔任這項角色的程式庫必須具備足夠的彈性,才能因應快速的研究疊代,同時也要夠穩健且效能良好,才能可靠地訓練生產模型。此外,也應提供經過完善測試的演算法實作項目,符合標準方程式。Optax 程式庫採用模組化可組合架構,並強調正確易讀的程式碼,因此可達成這個目標。
設計
Optax 提供可讀、經過充分測試且有效率的核心演算法實作項目,可提升研究速度,並加速從研究到生產的過程。Optax 的用途不限於深度學習,但在這個脈絡中,Optax 可視為一系列以純函式方式實作的知名損失函式、最佳化演算法和梯度轉換,符合 JAX 的理念。收集眾所周知的損失和最佳化工具,讓使用者輕鬆上手,充滿信心。
Optax 採用模組化方法,可讓您將多個最佳化器串連在一起,然後套用其他常見的轉換 (例如梯度裁剪),並使用 MultiStep 或 Lookahead 等常見技術包裝這些轉換,只需幾行程式碼,就能達成強大的最佳化策略。彈性介面可供您研究新的最佳化演算法,並使用強大的二階最佳化技術,例如 shampoo 或 muon。
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
上一個程式碼片段顯示如何使用自訂學習率、梯度裁剪和梯度累積設定最佳化工具。
主要優勢
- 功能強大的程式庫:提供完整的損失、最佳化工具和演算法程式庫,著重於正確性和可讀性。
- 可鏈結的模組化轉換:這個彈性 API 可讓您以宣告方式制定強大且複雜的最佳化策略,而不必修改訓練迴圈。
- 功能齊全且可擴充:純函式實作項目可與 JAX 的平行化機制 (例如 pmap) 無縫整合,讓您使用相同的程式碼,從單一主機擴充至大型叢集。
Orbax / TensorStore - 大規模分散式檢查點
Orbax 是 JAX 的檢查點程式庫,適用於各種規模,從單一裝置到大規模分散式訓練都沒問題。目標是整合分散的檢查點實作項目,並為更多使用者提供重要的效能功能,例如非同步和多層檢查點。Orbax 可提供大規模訓練作業所需的復原能力,並提供彈性格式來發布檢查點。
與一般檢查點和還原系統會擷取整個系統狀態不同,使用 Orbax 進行機器學習檢查點作業時,只會選擇性地保留繼續訓練模型權重、最佳化工具狀態和資料載入器狀態所需的資訊。這種做法可盡量減少加速器停機時間。Orbax 會將 I/O 作業與運算作業重疊,藉此達成上述目標,這項重要功能適用於大型工作負載。加速器閒置時間會縮短為裝置主機資料傳輸的持續時間,且可進一步與下一個訓練步驟重疊,從效能角度來看,檢查點幾乎不會耗用資源。
從本質上來說,Orbax 使用 TensorStore,有效率地平行讀取及寫入陣列資料。Orbax API 會將這項複雜性抽象化,提供容易使用的介面來處理 PyTrees,這是 JAX 中模型的標準表示法。
主要優勢:
- 廣泛採用: Orbax 每月下載次數達數百萬,是分享 ML 構件的常見媒介。
- 簡化複雜性:Orbax 會抽象化分散式檢查點的複雜性,包括非同步儲存、原子性和檔案系統詳細資料。
- 彈性:Orbax 提供常見用途的 API,同時也允許您自訂工作流程,以處理特殊需求。
- 效能優異且可擴充:非同步檢查點、有效率的儲存格式 (OCDBT) 和智慧資料載入策略等功能,可確保 Orbax 擴充至涉及數萬個節點的訓練執行作業。
Grain:確定性且可擴充的輸入資料管道
Grain 是 Python 程式庫,用於讀取及處理資料,以訓練和評估 JAX 模型。這項服務彈性十足、速度快且具決定性,並支援檢查點等進階功能,對於成功訓練大型工作負載至關重要。支援熱門資料格式和儲存後端,並提供彈性 API,可將支援範圍擴展至原生不支援的使用者特定格式和後端。雖然 Grain 主要用於 JAX,但它與架構無關,不需要 JAX 即可執行,也能搭配其他架構使用。
動機
資料管道是訓練基礎架構的重要部分,必須具備彈性,才能有效表達常見的轉換,且效能要夠高,才能隨時讓加速器保持忙碌。此外,也必須能支援多種儲存格式和後端。 由於步數時間較長,大規模訓練大型模型對資料管道有額外要求,不只是常規訓練工作負載的要求,主要著重於確定性和可重現性2。Grain 程式庫採用彈性架構設計,可滿足這些需求。
2在 PaLM 論文的第 5.1 節中,作者指出他們觀察到損失大幅增加,即使已啟用梯度裁剪功能也是如此。解決方法是移除違規資料批次,並從損失尖峰前的檢查點重新啟動訓練。只有在完全可決定且可重現的訓練設定下,才能達成這點。
設計
在最高層級,有兩種方式可建構輸入管道:做為獨立的資料工作站叢集,或將資料工作站與驅動加速器的主機共置。基於各種原因,Grain 選擇後者。
加速器會與強大的主機結合,這些主機通常會在訓練步驟中閒置,因此是執行輸入資料管道的自然選擇。這種實作方式還有其他優點,可提供輸入和運算的分片一致檢視畫面,簡化資料分片檢視畫面。有人可能會認為將資料工作站放在加速器主機上,會導致主機 CPU 飽和,但這並不妨礙使用 RPC 3 將運算密集型轉換作業卸載至其他叢集。
在 API 方面,Grain 採用純 Python 實作,支援多個程序和彈性 API,可讓您根據易於理解的轉換範例,組合管道階段,實作任意複雜的資料轉換。
Grain 支援高效隨機存取資料格式 (例如 ArrayRecord 和 Bagz),以及其他常見資料格式 (例如 Parquet 和 TFDS)。Grain 預設支援從本機檔案系統讀取,以及從 Cloud Storage 讀取。除了支援常見的儲存格式和後端,儲存層的簡潔抽象化功能還可讓您新增支援項目,或包裝現有資料來源,使其與 Grain 程式庫相容。
3:這就是多模態資料管道的運作方式。舉例來說,圖片和音訊權杖化工具本身就是模型,會在自己的叢集上以自己的加速器執行,而輸入管道會發出 RPC 呼叫,將資料範例轉換為權杖串流。
主要優勢
- 確定性資料饋送:將資料工作站與加速器共置,並搭配穩定的全域重組和可檢查點的疊代器,即可使用 Orbax 在一致的快照中,將模型狀態和資料管道狀態一起檢查點,提升訓練過程的確定性。
- 彈性 API 可進行強大的資料轉換:彈性純 Python 轉換 API 可讓您在輸入處理管道中執行大量資料轉換。
- 可擴充支援多種格式和後端:可擴充的資料來源 API 支援熱門的儲存格式和後端,並可讓您新增對新格式和後端的支援。
- 強大的偵錯介面:資料管道視覺化工具和偵錯模式可讓您檢查、偵錯及最佳化資料管道的效能。
擴充的 JAX AI 技術堆疊
除了核心堆疊之外,豐富的專用程式庫生態系統還提供基礎架構、進階工具和應用程式層解決方案,可滿足端對端機器學習開發需求。
基礎架構:編譯器和執行階段
XLA:與硬體無關的編譯器中心引擎
動機
XLA 或 Accelerated Linear Algebra 是 Google 的特定領域編譯器,可與 JAX 完美整合,並支援 TPU、CPU 和 GPU 硬體裝置。XLA 的設計目標是成為硬體獨立的程式碼產生器,適用於 TPU、GPU 和 CPU。
XLA 編譯器優先編譯的設計是基本的架構選擇,可在快速發展的研究領域中創造持久優勢。相較之下,其他生態系統中以核心為主的做法,是依賴手動最佳化的程式庫來提升效能。對於穩定且成熟的模型架構,這種做法非常有效,但會造成創新瓶頸。當新研究推出新穎的架構時,生態系統必須等待編寫及最佳化新核心。不過,以編譯器為中心的設計通常可以概括新模式,從第一天起就為尖端研究提供高效能路徑。
設計
XLA 的運作方式是及時編譯 JAX 在追蹤程序中產生的計算圖 (例如,函式以 @jax.jit 裝飾時)。
這項編譯作業會依序執行下列管道:
- JAX 運算圖
- 高階最佳化工具 (HLO)
- 低階最佳化工具 (LLO)
- 硬體代碼
- 從 JAX 圖形到 HLO:JAX 運算圖形會轉換為 XLA 的 HLO 表示法。在這個高層級,系統會套用與硬體無關的強大最佳化功能,例如運算子融合和有效率的記憶體管理。StableHLO 方言是這個階段的耐用版本化介面。
- 從 HLO 到 LLO:完成高階最佳化後,硬體專屬後端會接手作業,將 HLO 表示法降級為機器導向的 LLO。
- 從 LLO 到硬體程式碼:LLO 最終會編譯成高效率的機器碼。對於 TPU,這段程式碼會以超長指令字 (VLIW) 封包的形式直接傳送至硬體。
為實現擴充性,XLA 的設計是以平行處理為基礎。這項技術會運用演算法,盡可能使用晶片上的矩陣乘法單元 (MXU)。在晶片之間,XLA 會使用 SPMD (單一程式多重資料),這是一種以編譯器為基礎的平行化技術,可在所有裝置上使用單一程式。這個強大的模型透過 JAX API 公開,可讓您使用高階分片註解,管理資料、模型或管道平行處理。
如需更複雜的平行模式,也可以使用多程式多資料 (MPMD),而 PartIR:MPMD 等程式庫也允許 JAX 使用者提供 MPMD 註解。
主要優勢
- 編譯:即時編譯運算圖可將記憶體配置、緩衝區分配和記憶體管理最佳化。而以核心為基礎的方法等替代方案,則會將這項負擔轉移給開發人員。在大多數情況下,XLA 都能達到優異的效能,同時不會影響開發人員的速度。
- 平行處理:XLA 會透過 SPMD 實作多種形式的平行處理,並在 JAX 層級公開。這項功能可讓您表達分片策略,在數千個晶片上實驗及擴充模型。
Pathways:大規模分散式運算的統一執行階段
Pathways提供分散式訓練和推論的抽象化功能,內建容錯和復原機制,讓機器學習研究人員在編寫程式碼時,就像使用單一強大的機器一樣。
動機
如要訓練及部署大型模型,需要數百到數千個晶片。這些晶片分布在多個機架和主機上。訓練工作是大型同步程式,需要所有這些晶片及其各自的主機,共同處理已平行化 (分片) 的 XLA 計算。以大型語言模型為例,這類模型可能需要數萬個以上的晶片,因此這項服務除了在 Pod 內使用晶片間互連 (ICI) 和晶片上互連 (OCI) 結構外,還必須能夠跨資料中心結構的多個 Pod。
設計
ML Pathways 是我們用來協調主機和 TPU 晶片之間分散式運算的系統。這項技術的設計目的,是為了在數十萬個加速器之間實現擴充性和效率。對於大規模訓練,它提供單一 Python 用戶端,可處理多個 Pod 工作、整合 Megascale XLA、編譯服務和遠端 Python。此外,還支援跨切片平行處理和搶占容許度,可從資源搶占作業自動復原。
Pathways 整合了最佳化的跨主機集合,可讓 XLA 計算圖形擴展到單一 TPU Pod 以外。這項功能擴大了 XLA 對資料、模型和管道平行處理的支援,可透過資料中心網路 (DCN) 跨 TPU 區隔界線運作,方法是整合分散式執行階段,管理 DCN 通訊與 XLA 通訊基本類型。
主要優勢
單一控制器架構與 JAX 整合,是重要的抽象概念。研究人員可藉此探索各種分片和並行策略,輕鬆擴充至數以萬計的晶片,用於訓練和部署模型。
進階開發:效能、資料和效率
Pallas:在 JAX 中編寫高效能自訂核心
雖然 JAX 是以編譯器為優先,但有時您可能需要精細控制硬體,才能達到最高效能。Pallas 是 JAX 的擴充功能,可讓您為 GPU 和 TPU 編寫自訂核心。目標是精確控管產生的程式碼,同時兼顧 JAX 追蹤和 jax.numpy API 的高階人體工學。
Pallas 採用以格線為基礎的平行處理模型,使用者定義的核心函式會透過多維度格線啟動平行工作群組。您可以定義張量在較慢但較大的記憶體 (例如 HBM) 和較快但較小的晶載記憶體 (例如 TPU 上的 VMEM、GPU 上的共用記憶體) 之間如何分塊和傳輸,並使用索引對應將格線位置與特定資料區塊建立關聯,藉此明確管理記憶體階層。Pallas 可將相同的核心定義降低,在 Google 的 TPU 和各種 GPU 上有效執行,方法是將核心編譯成適合目標架構的中間表示法 (TPU 的 Mosaic),或是運用 GPU 的 Triton 等技術。有了 Pallas,您就能編寫專門處理注意力等區塊的高效能核心,在目標硬體上達到最佳模型效能,不必依賴特定供應商的工具包。
Tokamax:精選的最新核心程式庫
如果 Pallas 是用於撰寫核心的工具,Tokamax 則是支援 TPU 和 GPU 的最先進自訂加速器核心程式庫。Tokamax 以 JAX 和 Pallas 為基礎建構而成,可充分發揮硬體效能。此外,還提供工具,方便您建構及自動調整自訂核心。
動機
JAX 的基礎是 XLA,是編譯器優先架構,但您可能需要直接控制硬體,才能在少數情況下達到最高效能4。自訂核心對於充分發揮昂貴的機器學習加速器資源 (例如 TPU 和 GPU) 效能至關重要。雖然這些技術廣泛用於提升注意力等重要運算子的執行效能,但實作時需要深入瞭解模型和目標硬體架構。Tokamax 提供一個經過精心挑選、充分測試的高效能核心權威來源,並搭配強大的共用基礎架構,用於開發、維護及生命週期管理。您也可以將這類程式庫做為參考實作項目,並視需要建構及自訂。這樣一來,您就能專注於模型建構工作,不必擔心基礎架構的問題。
4這是行之有年的範例,在 CPU 領域中也有先例,編譯後的程式碼會構成程式的大部分,開發人員會降至內建函式或內嵌組語,以最佳化效能關鍵區段。
設計
對於任何給定的核心,Tokamax 提供可由多種實作方式支援的通用 API。舉例來說,TPU 核心可透過標準 XLA 降低作業實作,或使用 Pallas/Mosaic-TPU 明確實作。GPU 核心可透過標準 XLA 降低、Mosaic-GPU 或 Triton 實作。根據預設,Tokamax API 會為指定設定挑選最知名的實作方式,這是根據定期自動調整和基準化執行作業的快取結果判斷而來,但您也可以視需要選擇特定實作方式。隨著時間推移,我們可能會新增實作項目,以便充分運用新一代硬體的特定功能,進一步提升效能。
除了核心本身,Tokamax 程式庫的重要元件還包括支援基礎架構,可讓您編寫自訂核心。舉例來說,您可以透過自動調整基礎架構定義一組可設定的參數 (例如圖塊大小),讓 Tokamax 執行詳盡的掃描,以判斷並快取最佳調整設定。夜間迴歸測試可保護您免於受到基礎編譯器基礎架構或其他依附元件變更,所導致的非預期效能和數值問題。
主要優勢
- 流暢的開發人員體驗:統一的精選程式庫提供已知良好的主要核心高效率實作項目,並以程式輔助方式和說明文件清楚說明支援的硬體世代和預期效能。這可減少碎片化和流失。
- 彈性和生命週期管理:您可以選擇不同的實作方式,甚至在適當的時候變更。舉例來說,如果 XLA 編譯器加強支援特定作業,不再需要自訂核心,則可進行淘汰和遷移。
- 擴充性:您可以實作自己的核心,同時運用支援完善的共用基礎架構,專注於加值功能和最佳化作業。清楚撰寫的標準實作方式可做為使用者學習和擴充的起點。
Qwix:非侵入式全面量化
Qwix 是 JAX AI 堆疊的完整量化程式庫,支援所有階段的大型語言模型和其他模型類型,包括訓練 (量化感知訓練 (QAT)、量化技術 (QT)、量化低秩適應 (QLoRA)) 和推論訓練後量化 (PTQ),適用於 XLA 和裝置端執行階段。
動機
現有的量化程式庫 (特別是 PyTorch 生態系統中的程式庫) 通常用途有限 (例如僅限 PTQ 或僅限 QLoRA)。這種零散的環境會迫使您切換工具,阻礙一致的程式碼使用方式,以及訓練和推論之間精確的數值比對。此外,許多解決方案都需要大幅修改模型,將模型邏輯與量化邏輯緊密結合。
設計
Qwix 的設計理念強調提供全面解決方案,以及非侵入式模型整合。這項架構採用可擴充的階層式設計,並以可重複使用的功能 API 為基礎建構而成。
這項非侵入式整合功能是透過精心設計的攔截機制達成,可將 JAX 函式重新導向至量化對應項目。這樣一來,您就能整合模型,完全不必修改任何內容,並將量化程式碼與模型定義完全分離。
以下範例說明如何將 w4a4 (4 位元權重、4 位元啟用) 量化套用至 LLM 的 MLP 層,並將 w8 (8 位元權重) 量化套用至嵌入器。如要變更量化配方,只需更新規則清單即可。
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
主要優勢
- 全面解決方案:Qwix 適用於各種量化情境,可確保訓練和推論之間使用一致的程式碼。
- 非侵入式模型整合:如範例所示,您只需一行程式碼,即可整合模型。您可以在多個量化配置中使用超參數,找出最佳品質與效能取捨。
- 與其他程式庫聯合:Qwix 可與 JAX AI 堆疊完美整合。舉例來說,當模型使用 Qwix 量化時,Tokamax 會自動調整為使用核心的量化版本,無須額外的使用者程式碼。
- 研究友善:Qwix 的基礎 API 和可擴充架構可協助研究人員探索新演算法,並透過整合式基準和評估工具,輕鬆進行比較。
應用程式層:訓練和調整
基礎模型訓練:MaxText 和 MaxDiffusion
MaxText 和 MaxDiffusion 分別是 Google 的旗艦 LLM 和 Diffusion 模型訓練架構。這些存放區包含經過高度最佳化的熱門開放權重模型實作項目。這些程式碼具有雙重用途:既是可直接使用的模型訓練程式碼庫,也是基礎模型建構者可參考的範本。
動機
業界對訓練生成式 AI 模型的需求快速成長。 開放式模型日益普及,加速了這股趨勢,並提供經過驗證的架構。訓練及調整這些模型需要高效能、高效率、可擴充至大量晶片,以及清楚易懂的程式碼。MaxText 和 MaxDiffusion 是全方位的解決方案,可在 TPU 或 GPU 上使用,專為滿足這些需求而設計。
設計
MaxText 和 MaxDiffusion 是基礎模型程式碼庫,設計時兼顧可讀性和效能。這些架構採用經過充分測試的可重複使用元件:使用自訂核心 (例如 Tokamax) 的模型定義,可發揮最大效能;用於協調及監控的訓練架構;以及功能強大的設定系統,可透過直覺式介面控制分片和量化 (使用 Qwix) 等詳細資料。並納入多層檢查點等進階可靠性功能,確保持續維持良好的輸送量。
MaxText 和 MaxDiffusion 使用一流的 JAX 程式庫 Qwix、Tunix、Orbax 和 Optax,提供核心功能。這些程式庫提供強大且可擴充的基礎架構,可減少開發負擔,讓您專注於模型化工作。模型程式碼會共用,以利推論,進而有效率地大規模部署模型。
主要優勢
- 效能設計:訓練基礎架構可設定為高「良率」(實用輸送量),模型實作項目則可最佳化為高 MFU (模型 FLOPS 使用率),因此 MaxText 和 MaxDiffusion 開箱即能大規模提供高效能。
- 專為擴充性而生:這些架構運用 JAX AI 堆疊 (尤其是 Pathways) 的強大功能,讓您從數十個晶片無縫擴充至數萬個晶片。
- 基礎模型建構工具的穩固基礎:高品質且易於閱讀的實作項目,可做為開發人員的穩固起點,無論是做為端對端解決方案,或是做為自行自訂的參考實作項目,都非常實用。
訓練後和對齊:Tunix 架構
Tunix 提供最先進的開放原始碼強化學習 (RL) 演算法,以及強大的架構和基礎架構,可簡化開發人員的作業流程,讓他們使用 JAX 和 TPU 實驗 LLM 訓練後技術,包括監督式微調 (SFT) 和對齊。
動機
訓練後步驟是發揮 LLM 真正力量的關鍵。增強式學習 (RL) 階段對於開發對齊和推理能力尤其重要。這個領域的開放原始碼開發幾乎完全以 PyTorch 和 GPU 為基礎,為 JAX 和 TPU 解決方案留下基本差距。Tunix (Tune-in-JAX) 是高效能的 JAX 原生程式庫,專門用於填補這項缺口。
設計
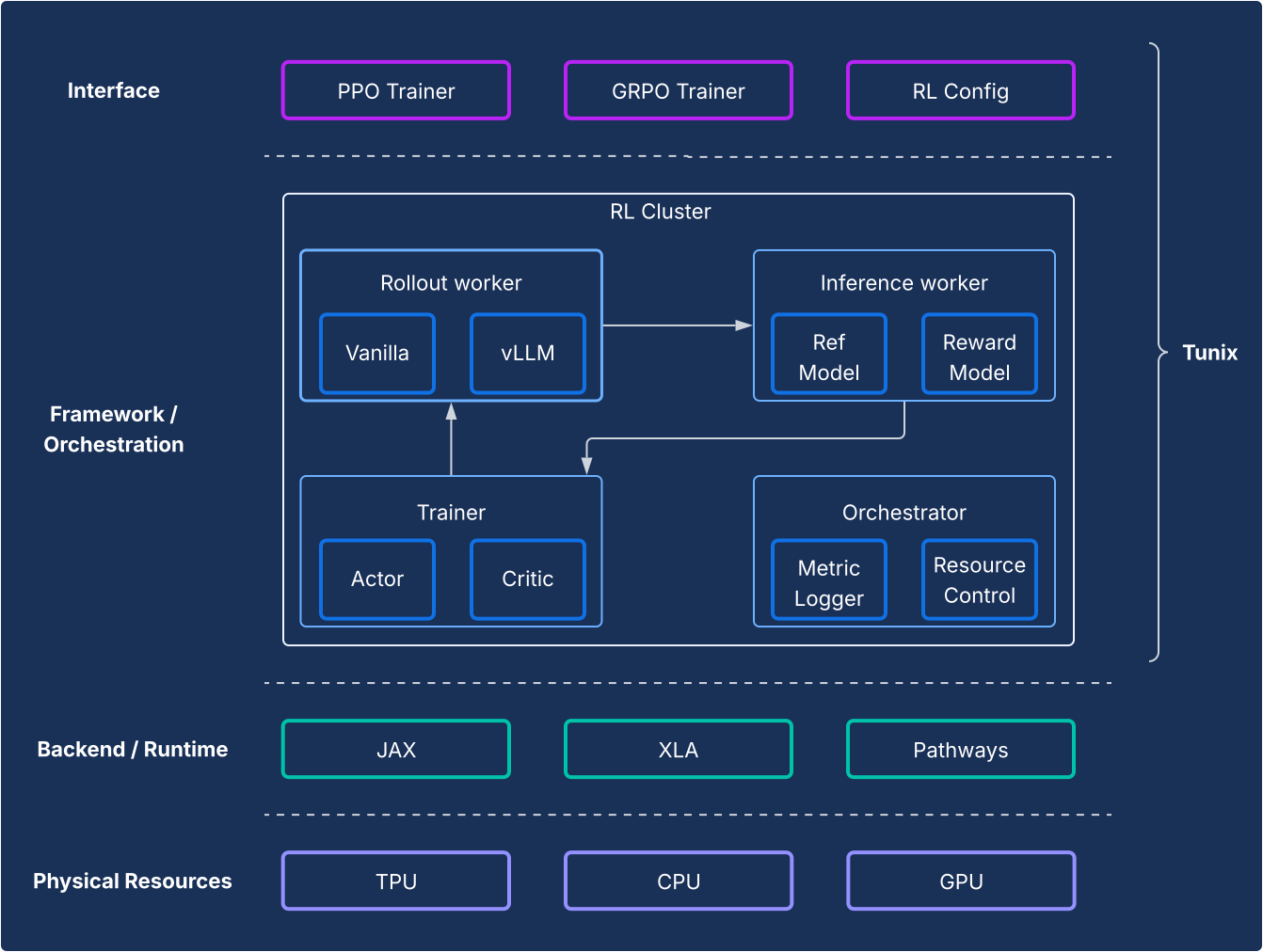
從架構的角度來看,Tunix 可實現最先進的設定,清楚區分 RL 演算法和基礎架構。這個 API 類似於用戶端,但更輕量,可隱藏 RL 基礎架構的複雜性,讓您開發新演算法。Tunix 提供熱門演算法的現成解決方案,包括近端策略最佳化 (PPO)、直接偏好最佳化 (DPO) 等。
在基礎架構方面,Tunix 與 Pathways 整合,可提供單一控制器架構,方便進行多節點 RL 訓練。在訓練方面,Tunix 原生支援參數效率訓練 (例如 LoRA),並運用 JAX 分片和 XLA (機器學習運算圖的通用且可擴充的平行化 (GSPMD)),產生高效能的運算圖。支援 Gemma 和 Llama 等熱門開放原始碼模型,開箱即可使用。
主要優勢
- 簡化:提供類似用戶端的高階 API,可抽象化基本分散式基礎架構的複雜性。
- 開發人員效率:Tunix 內建演算法和「配方」,可加速研發生命週期,提供可運作的模型,讓您快速反覆運算。
- 效能和可擴充性:Tunix 會在後端將 Pathways 做為單一控制器,藉此打造高效率且可水平擴充的訓練基礎架構。
應用程式層:生產和推論
JAX 採用歷來面臨的挑戰,是從研究到生產的路徑。JAX AI 堆疊現在提供成熟的雙管齊下生產故事,兼具生態系統相容性和 JAX 效能。
高效能 LLM 推論:vLLM 解決方案
vLLM-TPU 是 Google 的高效能推論堆疊,專為在 Cloud TPU 上有效率地執行 PyTorch 和 JAX 大型語言模型 (LLM) 而設計。這項功能可將熱門的開放原始碼 vLLM 架構與 Google 的 JAX 和 TPU 生態系統原生整合,進而達成上述目標。
動機
這個產業正快速發展,對無縫、高效能且易於使用的推論解決方案需求日益增加。開發人員經常面臨複雜且不一致的工具、效能不佳和模型相容性有限等重大挑戰。vLLM 堆疊提供統一、高效能且直覺式的平台,可解決這些問題。
設計
這項解決方案擴充了 vLLM 架構,而非重新發明。vLLM-TPU 是經過高度最佳化的開放原始碼 LLM 服務引擎,以高處理量著稱,可透過 PagedAttention (管理 KV 快取,例如虛擬記憶體,以盡量減少片段化) 和持續批次處理 (動態將要求新增至批次,以提高使用率) 等重要功能達成。
vLLM-TPU 以此為基礎,開發要求處理、排程和記憶體管理的核心元件。這項功能導入了以 JAX 為基礎的後端,可做為橋梁,將 vLLM 的運算圖和記憶體運算轉譯為可在 TPU 執行的程式碼。這個後端會處理裝置互動、JAX 模型執行作業,以及管理 TPU 硬體上的 KV 快取。這項技術整合了 TPU 專屬最佳化功能,例如高效能注意力機制 (例如運用 JAX Pallas 核心,實現 Ragged Paged Attention) 和量化,全都針對 TPU 架構量身打造。
主要優勢
- 使用者加入/退出服務的成本為零:使用者可以順利採用這項解決方案,從使用者體驗的角度來看,在 TPU 上處理推論要求與在 GPU 上處理應該相同。啟動伺服器、接受提示及傳回輸出的 CLI 都是共用的。
- 全面採用生態系統:這種做法會使用 vLLM 介面和使用者體驗,並為其貢獻心力,確保相容性與易用性。
- TPU 和 GPU 之間的互換性:這項解決方案可在 TPU 和 GPU 上有效運作,讓您享有彈性。
- 高成本效益 (最佳效能/費用):針對熱門模型提升效能,提供最佳效能/費用比。
JAX 服務:Orbax 序列化和 Neptune 服務引擎
如要使用 LLM 以外的模型,或希望採用完全以 JAX 為基礎的管道,Orbax 序列化程式庫和 Neptune 服務引擎 (NSE) 系統可提供端對端的高效能服務解決方案。
動機
過去,JAX 模型通常需要迂迴的途徑才能投入生產環境,例如包裝在 TensorFlow 圖表中,並使用 TensorFlow 服務部署。這種做法有許多限制和缺點,開發人員必須使用獨立的生態系統,疊代速度也會變慢。專屬的 JAX 原生服務系統對於永續性、降低複雜度和提升效能至關重要。
設計
這個解決方案包含兩個核心元件,如下圖所示。
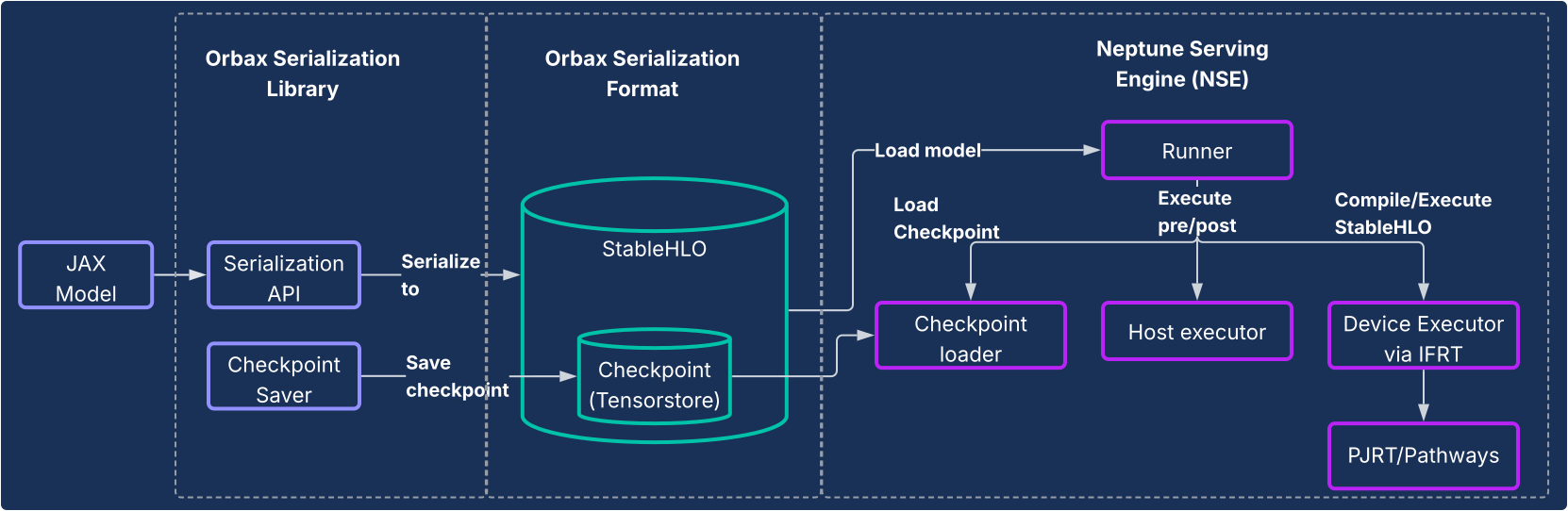
- Orbax 序列化程式庫:提供簡單易用的 API,可將 JAX 模型序列化為新的強大 Orbax 序列化格式。這個格式經過最佳化調整,適用於正式版部署作業。它會使用 StableHLO 直接表示 JAX 模型運算,因此運算圖形可以原生表示。此外,這項工具也運用 TensorStore 儲存權重,方便快速載入檢查點以進行服務。
- Neptune Serving Engine (NSE):這是隨附的高效能彈性服務引擎 (通常以 C++ 二進位檔部署),專為以 Orbax 格式原生執行 JAX 模型而設計。NSE 提供生產環境必備的功能,例如快速載入模型、透過內建批次處理功能並行提供高處理量服務、支援多個模型版本,以及單一和多個主機服務 (運用 PJRT 和 Pathways)。使用 Neptune 服務引擎執行下列作業:
- 非 LLM 模型:這是一般用途的解決方案,適合推薦系統、擴散模型和其他 AI 模型等工作負載。
- 小型 LLM 和「單次」服務:專為非自迴歸模型或以「一元」方式服務的較小型模型設計,這類模型會在單一傳遞中產生整個輸出內容,不需要像 KV 快取一樣進行複雜的狀態管理。
簡而言之,Neptune Serving Engine 可填補大型自迴歸語言模型以外的各種模型服務缺口,為更廣泛的 ML 生態系統提供高效能的 TPU 原生解決方案。
主要優勢
- JAX 原生服務:這項解決方案是專為 JAX 建構,可消除模型序列化和服務中的架構間負荷。確保模型快速載入,並在 CPU、GPU 和 TPU 中以最佳化方式執行。
- 輕鬆部署至正式環境:序列化模型提供密封部署路徑,不受 Python 依附元件偏移影響,並支援執行階段模型完整性檢查。這為 JAX 模型生產化提供順暢直覺的路徑。
- 提升開發人員體驗:這項解決方案無須進行繁瑣的架構包裝,可大幅減少依附元件和系統複雜度,加快 JAX 開發人員的疊代速度。
全系統分析和剖析
XProf:深入整合硬體的效能剖析
XProf 是一種剖析和效能分析工具,可深入瞭解機器學習工作負載執行的各個層面,協助您偵錯及提升效能。並與 JAX 和 TPU 生態系統深度整合。
動機
一方面,機器學習工作負載日益複雜。另一方面,針對這些工作負載的專用硬體功能也如雨後春筍般湧現。鑑於機器學習基礎架構的成本極高,有效搭配這兩者以確保最高效能和效率至關重要。這需要深入瞭解工作負載和硬體,並以容易理解的方式呈現。XProf 非常擅長這項工作。
設計
XProf 主要由兩個元件組成:收集和分析。
- 收集:XProf 會從各種來源擷取資訊,包括 JAX 程式碼中的註解、XLA 編譯器中作業的成本模型,以及 TPU 內建的硬體剖析功能。您可以透過程式輔助或視需要觸發這項收集作業,產生完整的事件構件。
- 分析:XProf 會後續處理收集到的資料,並建立一系列強大的視覺化圖表,可透過瀏覽器存取。
主要優勢
XProf 的真正強大之處在於與完整堆疊的深度整合,可提供廣泛且深入的分析,這是共同設計的 JAX/TPU 生態系統帶來的實質效益。
- 與 TPU 共同設計:XProf 會運用專為無縫收集設定檔而設計的硬體功能,將收集作業的負擔降至不到 1%。因此,剖析作業可成為開發過程中輕量級的疊代部分。
- 分析的廣度和深度:XProf 可針對多個軸向進行深入分析。這項服務提供的工具包括:
- 追蹤記錄檢視器:在不同硬體單元 (例如 TensorCore) 上執行的作業時間軸檢視畫面。
- HLO Op Profile:將總時間細分為不同類別的作業。
- 記憶體檢視器:詳細列出在分析視窗期間,不同作業的記憶體分配情形。
- 屋頂線分析:協助您判斷特定作業是否受限於運算或記憶體,以及這些作業與硬體最高效能的差距。
- 圖表檢視器:提供硬體執行的完整 HLO 圖表檢視畫面。
比較觀點:JAX/TPU 堆疊是極具吸引力的選擇
現代機器學習領域提供許多成熟的優質工具鍊。JAX AI Stack 具有獨特且強大的優勢,可供專注於大規模高效能機器學習的開發人員使用,這直接源自於其模組化設計和深入的硬體共同設計。
雖然許多架構提供各種功能,但 JAX AI Stack 在開發生命週期的重要領域中,提供特定且強大的差異化功能:
- 更簡單強大的開發人員體驗:Optax 的可鏈結梯度轉換範例可提供更強大且彈性的最佳化策略,只要宣告一次,不必在訓練迴圈中強制管理。在系統層級,Pathways 的單一控制器介面更簡單,可抽象化多切片訓練的複雜性,大幅簡化研究人員的工作。
- 專為大規模韌性設計:JAX 堆疊專為極大規模訓練而設計。Orbax 提供「英雄級訓練韌性」功能,例如緊急和多層檢查點。此外,Grain 也提供完整支援,可透過決定性全域隨機重組和可檢查點的資料載入器,確保可重現性。能夠以原子方式檢查資料管道狀態 (Grain) 和模型狀態 (Orbax),是確保長期執行工作可重現性的重要功能。
- 完整的端對端生態系統:這個堆疊提供整合完善的端對端解決方案。開發人員可以將 MaxText 做為訓練的 SOTA 參考資料、使用 Tunix 進行對齊,並透過 vLLM-TPU (適用於 vLLM 相容性) 和 NSE (適用於 JAX 效能),遵循明確的雙路徑進行生產。
從高階軟體角度來看,許多堆疊都十分相似,但決定因素通常是效能/總擁有成本,而這正是 JAX 和 TPU 共同設計的獨特優勢。這項效能/TCO 優勢是軟體和 TPU 硬體垂直整合的直接成果。XLA 編譯器可針對 TPU 架構融合運算,XProf 分析器則可使用硬體掛鉤進行分析,且負擔不到 1%,這些都是深度整合的實質效益。
對於採用這個堆疊的機構而言,JAX AI 堆疊功能齊全,可將遷移成本降到最低。對於採用熱門開放模型架構的客戶而言,從其他架構轉移至 MaxText 通常只需要設定設定檔。此外,這個堆疊可擷取 safetensors 等熱門檢查點格式,因此現有檢查點可直接遷移,不必重新訓練,省下高昂費用。
下表列出 JAX AI 堆疊提供的元件,以及其他架構或程式庫中的對等項目。
| 功能 | JAX | 其他架構中的替代方案/對等項目5 |
| 編譯器 / 執行階段 | XLA | Inductor、Eager |
| MultiPod 訓練 | 課程 | Torch 閃電策略、Ray Train、Monarch (新功能)。 |
| 核心架構 | JAX | PyTorch |
| 模型撰寫 | Flax、Max* 模型 | torch.nn.*,
NVidia TransformerEngine、HuggingFace Transformers
|
| 最佳化工具和損失 | Optax | torch.optim.*、torch.nn.*Loss |
| 資料載入器 | 噴砂效果 | Ray Data、HuggingFace 資料載入器 |
| 查核點機制 | Orbax | PyTorch 分散式檢查點、 NeMo 檢查點 |
| 量化 | Qwix | TorchAO、bitsandbytes |
| 核心撰寫與知名實作 | Pallas / Tokamax | Triton/Helion、Liger-kernel、TransformerEngine |
| 訓練 / 調整後 | Tunix | VERL、NeMoRL |
| 剖析 | XProf | PyTorch 分析器、NSight 系統、NSight Compute |
| 基礎模型訓練 | MaxText、MaxDiffusion | NeMo-Megatron、DeepSpeed、TorchTitan |
| LLM 推論 | vLLM | SGLang |
| 非 LLM 推論 | NSE | Triton Inference Server、RayServe |
5這裡的部分對等項目不一定能直接比較,因為相較於 JAX,其他架構的 API 邊界有所不同。這份對應清單並未含括完整內容,而且經常會出現新的程式庫。
結論:為 AI 發展的未來打造經久耐用的正式版平台
上表提供的資料說明瞭一個顯而易見的結論:這些堆疊在少數領域各有優缺點,但從軟體角度來看,整體而言非常相似。這兩個堆疊都提供基礎模型的預先訓練、訓練後調整和部署作業的解決方案。
JAX AI 堆疊提供強大且令人信服的解決方案,可訓練及部署任何規模的機器學習模型。透過軟體和 TPU 硬體間的深度垂直整合,提供領先業界的效能和總擁有成本。
這個堆疊以經過實戰測試的內部系統為基礎,不斷演進,提供固有的可靠性和可擴充性,讓使用者能夠放心地開發及部署大型模型。這個架構以 JAX AI 堆疊哲學為基礎,採用模組化和可組合的設計,可為使用者提供無與倫比的自由度和控制權,讓他們根據特定需求調整堆疊,而不受單一架構的限制。
JAX AI 堆疊以 XLA 和 Pathways 為基礎,提供可擴充且容錯的基礎,並以 JAX 提供高效能且具表現力的數值程式庫,以及 Flax、Optax、Grain 和 Orbax 等強大的核心開發程式庫,以及 Pallas、Tokamax 和 Qwix 等進階效能工具,以及 MaxText、vLLM 和 NSE 等強大的應用程式和生產層,為使用者提供穩固的基礎,可快速將最先進的研究成果投入生產。