
Membangun AI produksi di Cloud TPU dengan JAX
Stack AI JAX memperluas inti numerik JAX dengan kumpulan library yang dapat disusun dan didukung Google, sehingga mengubahnya menjadi platform open source yang andal dan menyeluruh untuk Machine Learning dalam skala ekstrem. Dengan demikian, stack AI JAX terdiri dari ekosistem komprehensif dan tangguh yang menangani seluruh siklus proses ML:
Fondasi skala industri: Stack AI JAX dirancang untuk skala besar, memanfaatkan ML Pathways untuk mengatur pelatihan di puluhan ribu chip dan Orbax untuk pembuatan checkpoint asinkron yang tangguh dan ber-throughput tinggi, sehingga memungkinkan pelatihan model canggih tingkat produksi.
Toolkit lengkap yang siap produksi: Stack AI JAX menyediakan serangkaian library komprehensif untuk seluruh proses pengembangan: Flax untuk penulisan model yang fleksibel, Optax untuk strategi pengoptimalan yang dapat dikomposisikan, dan Grain untuk pipeline data deterministik yang penting untuk menjalankan skala besar yang dapat direproduksi.
Performa puncak khusus: Untuk mencapai pemanfaatan hardware maksimum, stack AI JAX menawarkan library khusus termasuk Tokamax untuk kernel kustom canggih, Qwix untuk kuantisasi non-intrusif yang meningkatkan kecepatan pelatihan dan inferensi, serta XProf untuk pembuatan profil performa yang mendalam dan terintegrasi dengan hardware.
Jalur lengkap ke produksi: Stack AI JAX memberikan transisi yang lancar dari riset ke deployment. Hal ini mencakup MaxText sebagai referensi yang dapat diskalakan untuk pelatihan model dasar, Tunix untuk reinforcement learning (RL) dan penyelarasan yang canggih, serta solusi inferensi terpadu dengan integrasi vLLM TPU dan runtime penayangan JAX.
Filosofi stack AI JAX adalah salah satu komponen yang terhubung secara longgar, yang masing-masing melakukan satu hal dengan baik. Daripada menjadi framework ML monolitik, JAX sendiri memiliki cakupan sempit dan berfokus pada operasi array yang efisien dan transformasi program. Ekosistem ini dibangun berdasarkan framework inti ini untuk menyediakan berbagai fungsi, yang terkait dengan pelatihan model ML dan jenis workload lainnya seperti komputasi ilmiah.
Sistem komponen yang terhubung secara longgar ini memungkinkan Anda memilih dan menggabungkan library dengan cara terbaik yang sesuai dengan kebutuhan Anda. Dari perspektif rekayasa software, arsitektur ini juga memungkinkan Anda memperbarui fungsi yang biasanya dianggap sebagai komponen framework inti (misalnya, pipeline data dan pembuatan titik pemeriksaan) secara iteratif tanpa risiko mengganggu stabilitas framework inti atau terperangkap dalam siklus rilis. Mengingat sebagian besar fungsi diimplementasikan dalam library, bukan perubahan pada framework monolitik, hal ini membuat library numerik inti lebih tahan lama dan dapat beradaptasi dengan perubahan lanskap teknologi di masa mendatang.
Bagian berikut memberikan ringkasan teknis tentang stack AI JAX, fitur utamanya, keputusan desain di baliknya, dan cara menggabungkannya untuk membangun platform yang andal untuk workload ML modern.
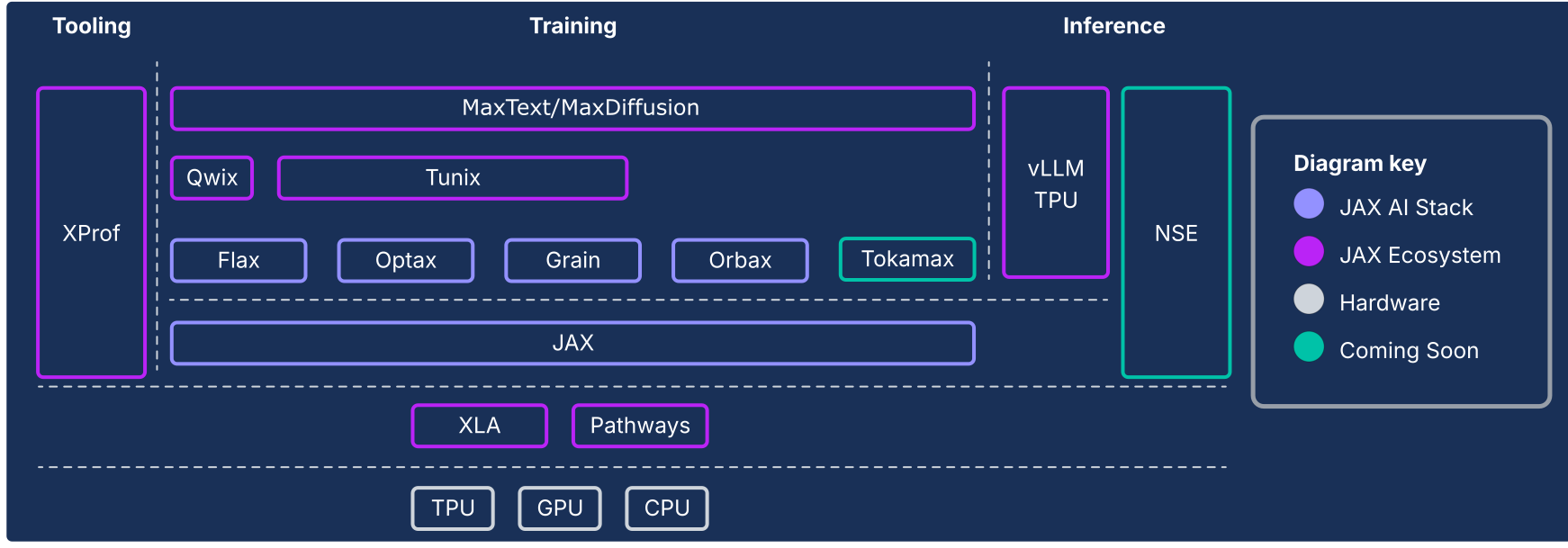
Stack AI JAX dan komponen ekosistem lainnya
| Komponen | Fungsi / Deskripsi |
|---|---|
| Komponen dan inti stack AI JAX1 | |
| JAX | Komputasi array dan transformasi program yang berorientasi pada akselerator (JIT, grad, vmap, pmap). |
| Flax | Library penulisan jaringan neural yang fleksibel untuk pembuatan dan modifikasi model yang intuitif. |
| Optax | Library pemrosesan gradien yang dapat dikomposisikan dan transformasi pengoptimalan. |
| Orbax | Library checkpointing terdistribusi "skala apa pun" untuk ketahanan pelatihan skala heroik. |
| Butiran | Library pipeline data input yang skalabel, deterministik, dan dapat diperiksa. |
| JAX AI stack - Infrastructure | |
| XLA | Compiler machine learning open source untuk TPU, CPU, dan GPU. |
| Pathways | Runtime terdistribusi untuk mengatur komputasi di puluhan ribu chip. |
| Stack AI JAX - Lanjutan Pengembangan | |
| Pallas | Ekstensi JAX untuk menulis kernel kustom berperforma tinggi tingkat rendah yang diimplementasikan di Python. |
| Tokamax | Kumpulan library kernel kustom berperforma tinggi dan canggih (misalnya, Attention). |
| Qwix | Library komprehensif dan tidak mengganggu untuk kuantisasi (PTQ, QAT, QLoRA). |
| JAX AI stack - Application | |
| MaxText / MaxDiffusion | Framework referensi unggulan yang dapat diskalakan untuk melatih model dasar (misalnya, LLM dan Difusi). |
| Tunix | Framework untuk penyelarasan dan pelatihan pasca-pelatihan canggih (RLHF, DPO). |
| vLLM | Solusi inferensi LLM berperforma tinggi menggunakan integrasi bawaan framework vLLM. |
| XProf | Profiler terintegrasi hardware yang mendalam untuk analisis performa seluruh sistem. |
1Disertakan dalam paket Python jax-ai-stack.
Gambar 1: Komponen stack dan ekosistem AI JAX
Imperatif arsitektur: performa di luar framework
Seiring dengan konvergensi arsitektur model — misalnya, pada Transformer Mixture-of-Experts (MoE) multimodal — upaya untuk mencapai performa puncak memunculkan Megakernel. Megakernel secara efektif adalah seluruh penerusan ke depan (atau sebagian besar) dari satu model tertentu, yang dikodekan secara manual menggunakan API tingkat bawah seperti CUDA SDK di GPU NVIDIA. Pendekatan ini mencapai pemanfaatan hardware maksimum dengan tumpang-tindih secara agresif antara komputasi, memori, dan komunikasi. Karya terbaru dari komunitas riset telah menunjukkan bahwa pendekatan ini dapat menghasilkan peningkatan throughput yang signifikan, lebih dari 22% dalam beberapa kasus, untuk inferensi di GPU. Tren ini tidak terbatas pada inferensi; bukti menunjukkan bahwa beberapa upaya pelatihan skala besar telah melibatkan kontrol hardware tingkat rendah untuk mencapai peningkatan efisiensi yang signifikan.
Jika tren ini berlanjut, semua framework tingkat tinggi seperti yang ada saat ini berisiko menjadi kurang relevan, karena akses tingkat rendah ke hardware adalah hal yang pada akhirnya penting untuk performa pada arsitektur yang matang dan stabil. Hal ini menimbulkan tantangan bagi semua stack ML modern: cara menyediakan kontrol hardware tingkat pakar tanpa mengorbankan produktivitas dan fleksibilitas framework tingkat tinggi.
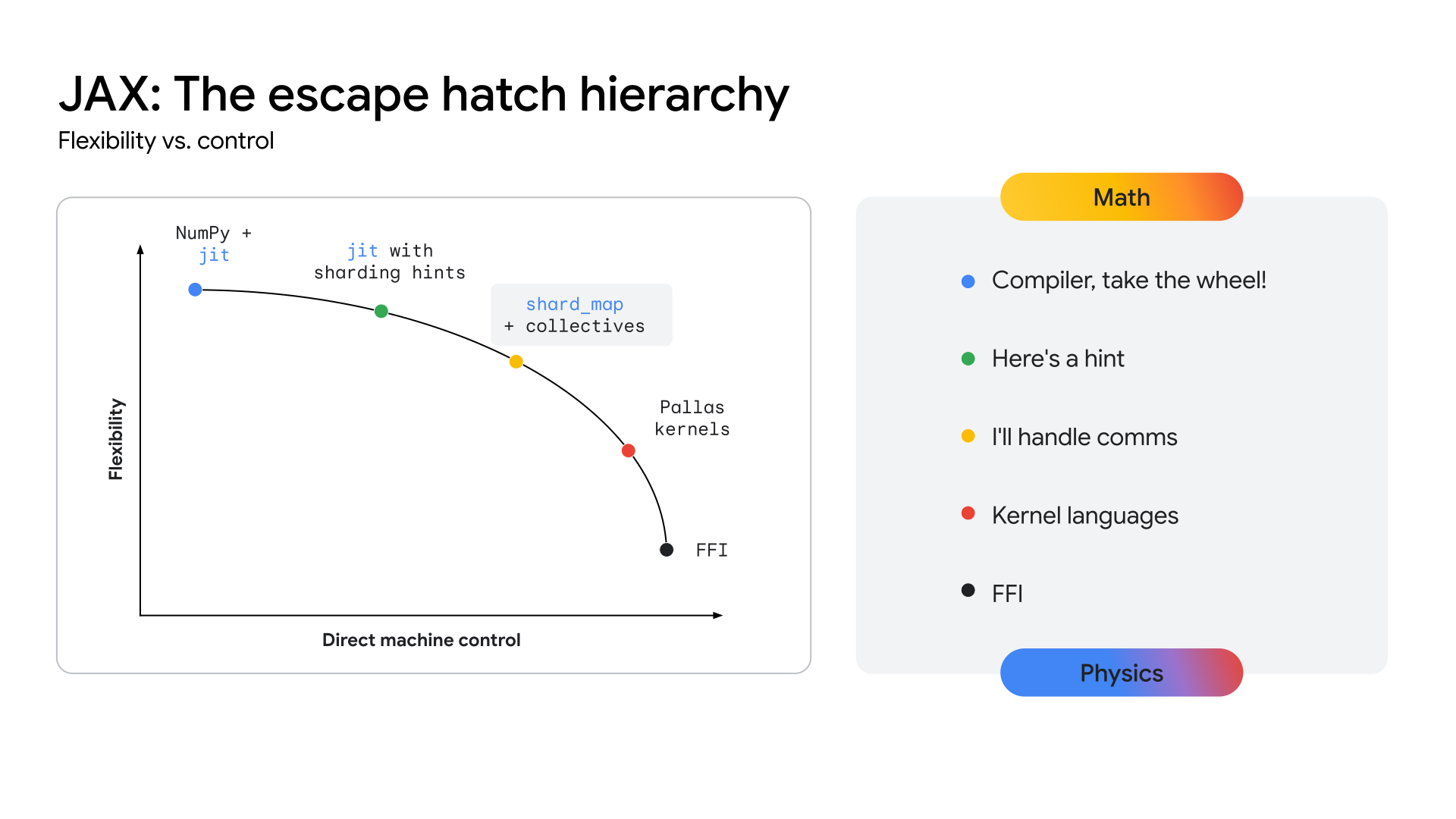
Agar TPU dapat memberikan jalur yang jelas ke tingkat performa ini, ekosistem harus mengekspos lapisan API yang lebih dekat dengan hardware, sehingga memungkinkan pengembangan kernel yang sangat khusus ini. Stack JAX dirancang untuk menyelesaikan masalah ini dengan menawarkan kesinambungan abstraksi (Lihat Gambar 2), mulai dari pengoptimalan tingkat tinggi otomatis dari compiler XLA hingga kontrol manual yang cermat dari library penulisan kernel Pallas.
Gambar 2: Kontinuum abstraksi JAX
Stack AI JAX inti
JAX AI Stack inti terdiri dari lima library utama yang menyediakan fondasi untuk pengembangan model:
JAX: Fondasi untuk transformasi program berperforma tinggi yang dapat dikomposisikan
JAX adalah library Python untuk komputasi array dan transformasi program yang berorientasi pada akselerator, yang dirancang untuk komputasi numerik berperforma tinggi dan Machine Learning skala besar. Dengan model pemrograman fungsional dan API seperti NumPy, JAX memberikan fondasi yang kuat untuk library tingkat yang lebih tinggi.
Dengan desain compiler-first, JAX secara inheren meningkatkan skalabilitas dengan memanfaatkan XLA (lihat bagian XLA) untuk analisis, pengoptimalan, dan penargetan hardware seluruh program yang agresif. Penekanan JAX pada pemrograman fungsional (misalnya, fungsi murni) membuat transformasi program intinya lebih mudah dikelola dan, yang terpenting, dapat dikomposisikan.
Transformasi inti ini dapat digabungkan dan disesuaikan untuk mencapai performa tinggi dan penskalaan workload di seluruh ukuran model, ukuran cluster, dan jenis hardware:
- jit: Kompilasi just-in-time fungsi Python menjadi file yang dapat dieksekusi XLA yang dioptimalkan dan digabungkan.
- grad: Diferensiasi otomatis, mendukung mode maju dan mundur, serta turunan tingkat yang lebih tinggi.
- vmap: Vektorisasi otomatis, yang memungkinkan batching dan paralelisme data yang lancar tanpa mengubah logika fungsi.
- pmap / shard_map: Paralelisasi otomatis di beberapa perangkat (misalnya, core TPU), yang menjadi dasar untuk pelatihan terdistribusi.
Integrasi yang lancar dengan model GSPMD (SPMD Tujuan Umum) XLA memungkinkan JAX memparalelkan komputasi secara otomatis di seluruh Pod TPU besar dengan perubahan kode minimal. Dalam sebagian besar kasus, penskalaan hanya memerlukan anotasi sharding tingkat tinggi.
Flax: Pembuatan jaringan neural yang fleksibel
Flax menyederhanakan pembuatan, pen-debug-an, dan analisis jaringan saraf di JAX dengan menyediakan pendekatan intuitif dan berorientasi objek untuk pembuatan model. Meskipun API fungsional JAX sangat canggih, API ini menawarkan abstraksi berbasis lapisan yang lebih familiar bagi developer yang terbiasa dengan framework seperti PyTorch, tanpa mengurangi performa.
Desain ini menyederhanakan modifikasi atau penggabungan komponen model terlatih.
Teknik seperti LoRA dan kuantisasi memerlukan definisi model yang dapat dimanipulasi, yang disediakan oleh NNX API Flax melalui antarmuka Python. NNX merangkum
status model, mengurangi beban kognitif pengguna, dan memungkinkan penelusuran
dan modifikasi hierarki model secara terprogram.
Kekuatan utama:
- API Berorientasi Objek yang Intuitif: Menyederhanakan konstruksi model dan memungkinkan kasus penggunaan lanjutan seperti penggantian submodul dan inisialisasi parsial.
- Konsisten dengan Core JAX: Flax menyediakan transformasi yang diangkat yang sepenuhnya kompatibel dengan paradigma fungsional JAX, sehingga menawarkan performa penuh JAX dengan kemudahan penggunaan yang ditingkatkan bagi developer.
Optax: Strategi pemrosesan dan pengoptimalan gradien yang dapat disusun
Optax adalah library pemrosesan dan pengoptimalan gradien untuk JAX. Dirancang untuk menyediakan elemen penyusun bagi pembuat model yang dapat digabungkan kembali dengan cara kustom untuk melatih model deep learning di antara aplikasi lainnya. Library ini dibangun berdasarkan kemampuan library JAX inti untuk menyediakan library fungsi kerugian dan pengoptimalan berperforma tinggi yang telah diuji dengan baik serta teknik terkait yang dapat digunakan untuk melatih model ML.
Motivasi
Penghitungan dan minimisasi kerugian adalah inti dari apa yang memungkinkan
pelatihan model ML. Dengan dukungan untuk diferensiasi otomatis, library JAX inti menyediakan kemampuan numerik untuk melatih model, tetapi tidak menyediakan penerapan standar pengoptimal populer (misalnya, RMSProp atau Adam) atau kerugian (misalnya, CrossEntropy atau MSE). Meskipun Anda dapat menerapkan fungsi ini (dan beberapa developer tingkat lanjut akan memilih untuk melakukannya), bug dalam penerapan pengoptimal akan menimbulkan masalah kualitas model yang sulit didiagnosis. Daripada meminta pengguna menerapkan bagian penting tersebut,
Optax menyediakan implementasi algoritma ini yang diuji kebenaran dan performanya.
Bidang teori pengoptimalan berada tepat di bidang penelitian, tetapi peran utamanya dalam pelatihan juga menjadikannya bagian yang sangat penting dalam pelatihan model ML produksi. Library yang menjalankan peran ini harus cukup fleksibel untuk mengakomodasi iterasi riset yang cepat, serta cukup andal dan berperforma tinggi untuk dapat diandalkan dalam pelatihan model produksi. Selain itu, library ini harus menyediakan implementasi algoritma canggih yang telah diuji dengan baik dan sesuai dengan persamaan standar. Library Optax, melalui arsitektur composable modular dan penekanan pada kode yang benar dan mudah dibaca, dirancang untuk mencapai hal ini.
Desain
Optax dirancang untuk meningkatkan kecepatan riset dan transisi dari riset ke produksi dengan menyediakan penerapan algoritma inti yang mudah dibaca, diuji dengan baik, dan efisien. Optax memiliki kegunaan di luar konteks deep learning, tetapi dalam konteks ini, Optax dapat dilihat sebagai kumpulan fungsi kerugian, algoritma pengoptimalan, dan transformasi gradien yang terkenal yang diimplementasikan dengan cara fungsional murni sesuai dengan filosofi JAX. Kumpulan kerugian dan pengoptimal yang terkenal memungkinkan pengguna memulai dengan mudah dan percaya diri.
Pendekatan modular yang dilakukan Optax memungkinkan Anda merangkai beberapa pengoptimal bersama-sama, diikuti dengan transformasi umum lainnya (misalnya, pemangkasan gradien) dan membungkusnya menggunakan teknik umum seperti MultiStep atau Lookahead untuk mencapai strategi pengoptimalan yang efektif dengan beberapa baris kode. Antarmuka yang fleksibel memungkinkan Anda meneliti algoritma pengoptimalan baru dan menggunakan teknik pengoptimalan orde kedua yang canggih seperti shampoo atau muon.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Cuplikan kode sebelumnya menunjukkan cara menyiapkan pengoptimal dengan kecepatan pembelajaran kustom, pemangkasan gradien, dan akumulasi gradien.
Kekuatan utama
- Library yang Andal: Menyediakan library komprehensif tentang kerugian, pengoptimal, dan algoritma dengan fokus pada kebenaran dan keterbacaan.
- Transformasi Modular yang Dapat Dirangkai: API fleksibel ini memungkinkan Anda membuat strategi pengoptimalan yang canggih dan kompleks secara deklaratif, tanpa mengubah loop pelatihan.
- Fungsional dan Dapat Diskalakan: Implementasi fungsional murni terintegrasi dengan lancar dengan mekanisme paralel JAX (misalnya, pmap), sehingga Anda dapat menggunakan kode yang sama untuk menskalakan dari satu host ke cluster besar.
Orbax / TensorStore - Checkpointing terdistribusi skala besar
Orbax adalah library pembuatan titik pemeriksaan untuk JAX yang didesain untuk semua skala, dari pelatihan terdistribusi skala besar hingga perangkat tunggal. Tujuannya adalah untuk menyatukan penerapan pembuatan titik pemeriksaan yang terfragmentasi dan menghadirkan fitur performa penting, seperti pembuatan titik pemeriksaan asinkron dan multi-tingkat, kepada audiens yang lebih luas. Orbax memungkinkan ketahanan yang diperlukan untuk tugas pelatihan besar dan menyediakan format fleksibel untuk memublikasikan titik pemeriksaan.
Tidak seperti sistem checkpoint dan pemulihan umum yang mengambil snapshot seluruh status sistem, checkpoint ML dengan Orbax secara selektif hanya mempertahankan informasi penting untuk melanjutkan pelatihan bobot model, status pengoptimal, dan status pemuat data. Pendekatan yang ditargetkan ini meminimalkan waktu henti akselerator. Orbax mencapai hal ini dengan tumpang-tindih operasi I/O dengan komputasi, fitur penting untuk workload besar. Waktu saat akselerator waktu tidak digunakan dikurangi menjadi durasi transfer data dari perangkat ke host, yang dapat lebih tumpang-tindih dengan langkah pelatihan berikutnya, sehingga pembuatan titik pemeriksaan hampir bebas dari perspektif performa.
Pada dasarnya, Orbax menggunakan TensorStore untuk membaca dan menulis data array secara paralel yang efisien. API Orbax mengabstraksi kompleksitas ini, dengan menawarkan antarmuka yang mudah digunakan untuk menangani PyTrees, yang merupakan representasi model standar di JAX.
Kekuatan utama:
- Penggunaan luas: Dengan jutaan download bulanan, Orbax berfungsi sebagai media umum untuk membagikan artefak ML.
- Menyederhanakan kompleksitas: Orbax menghilangkan kompleksitas checkpointing terdistribusi, termasuk penyimpanan asinkron, atomisitas, dan detail sistem file.
- Fleksibel: Selain menawarkan API untuk kasus penggunaan umum, Orbax memungkinkan Anda menyesuaikan alur kerja untuk menangani persyaratan khusus.
- Berperforma dan Dapat Diskalakan: Fitur seperti checkpointing asinkron, format penyimpanan yang efisien (OCDBT), dan strategi pemuatan data cerdas memastikan Orbax dapat diskalakan untuk menjalankan pelatihan yang melibatkan puluhan ribu node.
Grain: Pipeline data input yang deterministik dan skalabel
Grain adalah library Python untuk membaca dan memproses data untuk melatih dan mengevaluasi model JAX. Hal ini fleksibel, cepat, dan deterministik serta mendukung fitur canggih seperti checkpointing yang penting untuk keberhasilan pelatihan workload besar. Library ini mendukung format data dan backend penyimpanan populer, serta menyediakan API yang fleksibel untuk memperluas dukungan ke format dan backend khusus pengguna yang tidak didukung secara native. Meskipun utamanya dirancang untuk bekerja dengan JAX, Grain bersifat independen terhadap framework, tidak memerlukan JAX untuk dijalankan, dan dapat digunakan dengan framework lain juga.
Motivasi
Pipeline data membentuk bagian penting dari infrastruktur pelatihan - pipeline ini harus fleksibel sehingga transformasi umum dapat dinyatakan secara efisien, dan cukup berperforma sehingga dapat membuat akselerator tetap sibuk setiap saat. Mereka juga harus dapat mengakomodasi beberapa format dan backend penyimpanan. Karena waktu langkah yang lebih tinggi, pelatihan model besar dalam skala besar menimbulkan persyaratan tambahan pada pipeline data di luar persyaratan yang diperlukan oleh beban kerja pelatihan reguler, yang terutama berfokus pada determinisme dan kemampuan reproduksi2. Library Grain dirancang dengan arsitektur fleksibel yang memenuhi kebutuhan ini.
2Di Bagian 5.1 makalah PaLM, penulis mencatat bahwa mereka mengamati lonjakan kerugian yang sangat besar meskipun telah mengaktifkan pemangkasan gradien. Solusinya adalah menghapus batch data yang bermasalah dan memulai ulang pelatihan dari titik pemeriksaan sebelum lonjakan kerugian. Hal ini hanya mungkin dilakukan dengan penyiapan pelatihan yang sepenuhnya deterministik dan dapat direproduksi.
Desain
Pada tingkat tertinggi, ada dua cara untuk menyusun pipeline input, sebagai cluster pekerja data terpisah atau dengan menempatkan pekerja data bersama-sama di host yang mendorong akselerator. Grain memilih opsi kedua karena berbagai alasan.
Akselerator digabungkan dengan host yang canggih yang biasanya tidak digunakan selama langkah pelatihan, sehingga menjadi pilihan yang tepat untuk menjalankan pipeline data input. Ada keuntungan tambahan dari penerapan ini - penerapan ini menyederhanakan tampilan Anda tentang sharding data dengan memberikan tampilan sharding yang konsisten di seluruh input dan komputasi. Dapat dikatakan bahwa menempatkan pekerja data di host akselerator berisiko membebani CPU host, tetapi hal ini tidak menghalangi pelepasan transformasi intensif komputasi ke cluster lain menggunakan RPC3.
Di sisi API, dengan implementasi Python murni yang mendukung beberapa proses dan API yang fleksibel, Grain memungkinkan Anda menerapkan transformasi data yang kompleks secara arbitrer dengan menyusun tahap pipeline bersama-sama berdasarkan paradigma transformasi yang dipahami dengan baik.
Secara langsung, Grain mendukung format data akses acak yang efisien seperti ArrayRecord dan Bagz bersama dengan format data populer lainnya seperti Parquet dan TFDS. Grain menyertakan dukungan untuk membaca dari sistem file lokal serta membaca dari Cloud Storage secara default. Selain mendukung format dan backend penyimpanan yang populer, abstraksi yang bersih ke lapisan penyimpanan memungkinkan Anda menambahkan dukungan untuk atau membungkus sumber data yang ada agar kompatibel dengan library Grain.
3Beginilah cara kerja pipeline data multimodal - tokenizer gambar dan audio, misalnya, adalah model itu sendiri yang berjalan di cluster sendiri pada akseleratornya sendiri dan pipeline input akan melakukan panggilan RPC untuk mengonversi contoh data menjadi aliran token.
Kekuatan utama
- Pemberian data deterministik: Menempatkan pekerja data bersama dengan akselerator dan menggabungkannya dengan shuffle global yang stabil dan iterator yang dapat di-checkpoint memungkinkan status model dan status pipeline data di-checkpoint bersama dalam snapshot yang konsisten menggunakan Orbax, sehingga meningkatkan determinisme proses pelatihan.
- API fleksibel untuk memungkinkan transformasi data yang efektif: API transformasi Python murni yang fleksibel memungkinkan Anda melakukan transformasi data yang ekstensif dalam pipeline pemrosesan input.
- Dukungan yang dapat diperluas untuk beberapa format dan backend: API sumber data yang dapat diperluas mendukung format dan backend penyimpanan populer serta memungkinkan Anda menambahkan dukungan untuk format dan backend baru.
- Antarmuka pen-debugan yang canggih: Alat visualisasi pipeline data dan mode debug memungkinkan Anda memeriksa, men-debug, dan mengoptimalkan performa pipeline data.
Stack AI JAX yang diperluas
Selain stack inti, ekosistem library khusus yang kaya menyediakan infrastruktur, alat canggih, dan solusi lapisan aplikasi yang diperlukan untuk pengembangan ML end-to-end.
Infrastruktur dasar: compiler dan runtime
XLA: Mesin yang independen dari hardware dan berfokus pada compiler
Motivasi
XLA atau Accelerated Linear Algebra adalah compiler khusus domain Google, yang terintegrasi dengan baik ke dalam JAX dan mendukung perangkat hardware TPU, CPU, dan GPU. XLA dirancang untuk menjadi generator kode independen hardware yang menargetkan TPU, GPU, dan CPU.
Desain compiler XLA yang mengutamakan compiler adalah pilihan arsitektur mendasar yang menciptakan keunggulan yang berkelanjutan dalam lanskap riset yang berkembang pesat. Sebaliknya, pendekatan berpusat pada kernel yang berlaku di ekosistem lain mengandalkan library yang dioptimalkan secara manual untuk performa. Meskipun sangat efektif untuk arsitektur model yang stabil dan mapan, hal ini menciptakan hambatan untuk inovasi. Saat riset baru memperkenalkan arsitektur baru, ekosistem harus menunggu kernel baru ditulis dan dioptimalkan. Namun, desain yang berfokus pada compiler kami sering kali dapat melakukan generalisasi ke pola baru, sehingga memberikan jalur berperforma tinggi untuk riset mutakhir sejak hari pertama.
Desain
XLA berfungsi dengan mengompilasi grafik komputasi yang dihasilkan JAX selama proses pelacakannya (misalnya, saat fungsi dihiasi dengan @jax.jit) secara Just-In-Time (JIT).
Kompilasi ini mengikuti pipeline multi-tahap:
- Grafik Komputasi JAX
- Pengoptimal Tingkat Tinggi (HLO)
- Pengoptimal Tingkat Rendah (LLO)
- Kode Hardware
- Dari JAX Graph ke HLO: Grafik komputasi JAX dikonversi menjadi representasi HLO XLA. Pada tingkat tinggi ini, pengoptimalan yang canggih dan tidak bergantung pada hardware seperti fusi operator dan pengelolaan memori yang efisien diterapkan. Dialek StableHLO berfungsi sebagai antarmuka berversi yang tahan lama untuk tahap ini.
- Dari HLO ke LLO: Setelah pengoptimalan tingkat tinggi, backend khusus hardware mengambil alih, menurunkan representasi HLO menjadi LLO yang berorientasi pada mesin.
- Dari LLO ke Kode Hardware: LLO akhirnya dikompilasi menjadi kode mesin yang sangat efisien. Untuk TPU, kode ini digabungkan sebagai paket Very Long Instruction Word (VLIW) yang dikirim langsung ke hardware.
Untuk penskalaan, desain XLA dibuat berdasarkan paralelisme. Compiler ini menggunakan algoritma untuk memanfaatkan unit perkalian matriks (MXU) secara maksimal pada chip. Antar-chip, XLA menggunakan SPMD (Single Program Multiple Data), teknik paralelisasi berbasis compiler yang menggunakan satu program di semua perangkat. Model canggih ini diekspos melalui JAX API, sehingga Anda dapat mengelola paralelisme data, model, atau pipeline dengan anotasi sharding tingkat tinggi.
Untuk pola paralelisme yang lebih kompleks, Multiple Program Multiple Data (MPMD)
juga memungkinkan, dan library seperti PartIR:MPMD memungkinkan pengguna JAX memberikan
anotasi MPMD juga.
Kekuatan utama
- Kompilasi: kompilasi just-in-time dari grafik komputasi memungkinkan pengoptimalan tata letak memori, alokasi buffer, dan pengelolaan memori. Alternatif seperti metodologi berbasis kernel membebankan tugas tersebut kepada developer. Dalam sebagian besar kasus, XLA dapat mencapai performa yang sangat baik tanpa mengorbankan kecepatan developer.
- Paralelisme: XLA menerapkan beberapa bentuk paralelisme dengan SPMD, dan ini diekspos di tingkat JAX. Hal ini memungkinkan Anda mengekspresikan strategi partisi, sehingga memungkinkan eksperimen dan skalabilitas model di ribuan chip.
Pathways: Lingkungan runtime terpadu untuk komputasi terdistribusi berskala besar
Pathways menawarkan abstraksi untuk pelatihan dan inferensi terdistribusi dengan toleransi dan pemulihan kesalahan bawaan, sehingga peneliti ML dapat membuat kode seolah-olah mereka menggunakan satu mesin yang canggih.
Motivasi
Untuk dapat melatih dan men-deploy model besar, diperlukan ratusan hingga ribuan chip. Chip ini tersebar di banyak rak dan mesin host. Tugas pelatihan adalah program sinkron skala besar yang memerlukan semua chip ini, dan host masing-masing untuk bekerja bersama-sama dalam komputasi XLA yang telah diparalelkan (di-shard). Dalam kasus model bahasa besar, yang mungkin memerlukan lebih dari puluhan ribu chip, layanan ini harus dapat mencakup beberapa Pod di seluruh fabric pusat data selain menggunakan fabric interkoneksi antar-chip (ICI) dan interkoneksi dalam chip (OCI) dalam Pod.
Desain
ML Pathways adalah sistem yang kami gunakan untuk mengoordinasikan komputasi terdistribusi di seluruh host dan chip TPU. Layanan ini dirancang untuk skalabilitas dan efisiensi di ratusan ribu akselerator. Untuk pelatihan berskala besar, layanan ini menyediakan satu klien Python untuk beberapa tugas Pod, integrasi Megascale XLA, layanan kompilasi, dan Python jarak jauh. Layanan ini juga mendukung paralelisme lintas slice dan toleransi terhadap penghentian sementara, sehingga memungkinkan pemulihan otomatis dari penghentian sementara resource.
Pathways menggabungkan kolektif lintas host yang dioptimalkan yang memungkinkan grafik komputasi XLA melampaui satu Pod TPU. Hal ini memperluas dukungan XLA untuk paralelisme data, model, dan pipeline agar dapat berfungsi di seluruh batas slice TPU menggunakan jaringan pusat data (DCN) dengan mengintegrasikan runtime terdistribusi yang mengelola komunikasi DCN dengan primitif komunikasi XLA.
Kekuatan utama
Arsitektur pengontrol tunggal, yang terintegrasi dengan JAX, adalah abstraksi utama. Dengan demikian, peneliti dapat menjelajahi berbagai strategi sharding dan paralelisme untuk pelatihan dan deployment sambil menskalakan hingga puluhan ribu chip dengan mudah.
Pengembangan lanjutan: performa, data, dan efisiensi
Pallas: Menulis kernel kustom berperforma tinggi di JAX
Meskipun JAX adalah compiler pertama, ada situasi saat Anda mungkin menginginkan kontrol terperinci atas hardware untuk mencapai performa maksimum. Pallas adalah ekstensi untuk JAX yang memungkinkan penulisan kernel kustom untuk GPU dan TPU. Tujuannya adalah
untuk memberikan kontrol yang tepat atas kode yang dihasilkan, yang dikombinasikan dengan ergonomi
tingkat tinggi dari pelacakan JAX dan jax.numpy API.
Pallas mengekspos model paralelisme berbasis petak tempat fungsi kernel yang ditentukan pengguna diluncurkan di seluruh petak multidimensi dari grup kerja paralel. Hal ini memungkinkan pengelolaan hierarki memori secara eksplisit dengan memungkinkan Anda menentukan cara tensor diatur dan ditransfer antara memori yang lebih lambat dan lebih besar (misalnya, HBM) dan memori on-chip yang lebih cepat dan lebih kecil (misalnya, VMEM di TPU, Memori Bersama di GPU), menggunakan peta indeks untuk mengaitkan lokasi petak dengan blok data tertentu. Pallas dapat menurunkan definisi kernel yang sama untuk dieksekusi secara efisien di TPU Google dan berbagai GPU dengan mengompilasi kernel ke dalam representasi perantara yang sesuai untuk arsitektur target – Mosaic untuk TPU, atau menggunakan teknologi seperti Triton untuk GPU. Dengan Pallas, Anda dapat menulis kernel berperforma tinggi yang mengkhususkan blok seperti perhatian untuk mencapai performa model terbaik pada hardware target tanpa perlu mengandalkan toolkit khusus vendor.
Tokamax: Kumpulan library kernel canggih yang dikurasi
Jika Pallas adalah alat untuk membuat kernel, Tokamax adalah library kernel akselerator kustom canggih yang mendukung TPU dan GPU. Tokamax dibangun di atas JAX dan Pallas, serta memungkinkan Anda menggunakan kemampuan penuh hardware Anda. Alat ini juga menyediakan alat bagi Anda untuk membuat dan menyetel otomatis kernel kustom.
Motivasi
JAX, dengan akarnya di XLA, adalah framework compiler-first, tetapi ada sejumlah kecil kasus di mana Anda mungkin perlu mengontrol hardware secara langsung untuk mencapai performa maksimum4. Kernel kustom sangat penting untuk mendapatkan performa terbaik dari resource akselerator ML yang mahal seperti TPU dan GPU. Meskipun banyak digunakan untuk memungkinkan eksekusi operator utama yang berperforma tinggi seperti Perhatian, penerapannya memerlukan pemahaman mendalam tentang model dan arsitektur hardware target. Tokamax menyediakan satu sumber resmi kernel berperforma tinggi yang terkurasi dan teruji dengan baik, bersama dengan infrastruktur bersama yang andal untuk pengembangan, pemeliharaan, dan pengelolaan siklus prosesnya. Library tersebut juga dapat berfungsi sebagai implementasi referensi yang dapat Anda gunakan untuk membangun dan menyesuaikan sesuai kebutuhan. Dengan begitu, Anda dapat berfokus pada upaya pemodelan tanpa perlu mengkhawatirkan infrastruktur.
4Ini adalah paradigma yang sudah mapan dan memiliki preseden di dunia CPU, di mana kode yang dikompilasi membentuk sebagian besar program dengan developer yang beralih ke intrinsik atau assembly inline untuk mengoptimalkan bagian-bagian penting performa.
Desain
Untuk setiap kernel tertentu, Tokamax menyediakan API umum yang dapat didukung oleh beberapa penerapan. Misalnya, kernel TPU dapat diimplementasikan baik dengan pengurangan XLA standar, atau secara eksplisit dengan Pallas/Mosaic-TPU. Kernel GPU dapat diimplementasikan dengan penurunan XLA standar, dengan Mosaic-GPU, atau Triton. Secara default, Tokamax API memilih penerapan yang paling dikenal untuk konfigurasi tertentu, yang ditentukan oleh hasil yang di-cache dari proses penyetelan otomatis dan tolok ukur berkala, meskipun Anda dapat memilih penerapan tertentu jika diperlukan. Implementasi baru dapat ditambahkan seiring waktu untuk memanfaatkan fitur tertentu di generasi hardware baru dengan lebih baik demi performa yang lebih baik.
Komponen utama library Tokamax, selain kernel itu sendiri, adalah infrastruktur pendukung yang memungkinkan Anda menulis kernel kustom. Misalnya, infrastruktur penyetelan otomatis memungkinkan Anda menentukan serangkaian parameter yang dapat dikonfigurasi (misalnya, ukuran petak) yang dapat digunakan Tokamax untuk melakukan pemindaian menyeluruh, guna menentukan dan menyimpan dalam cache setelan yang disetel sebaik mungkin. Regresi harian melindungi Anda dari masalah performa dan numerik yang tidak terduga yang disebabkan oleh perubahan pada infrastruktur compiler yang mendasarinya atau dependensi lainnya.
Kekuatan utama
- Pengalaman developer yang lancar: Library terpadu dan terkurasi menyediakan implementasi kernel utama yang berperforma tinggi dan sudah teruji, dengan ekspresi yang jelas tentang generasi hardware yang didukung dan performa yang diharapkan, baik secara terprogram maupun dalam dokumentasi. Tindakan ini meminimalkan fragmentasi dan churn.
- Fleksibilitas dan pengelolaan siklus proses: Anda dapat memilih penerapan yang berbeda, bahkan mengubahnya dari waktu ke waktu jika sesuai. Misalnya, jika compiler XLA meningkatkan dukungan untuk operasi tertentu yang tidak lagi memerlukan kernel kustom, ada jalur untuk penghentian penggunaan dan migrasi.
- Ekstensibilitas: Anda dapat menerapkan kernel Anda sendiri, sekaligus memanfaatkan infrastruktur bersama yang didukung dengan baik, sehingga Anda dapat berfokus pada kemampuan dan pengoptimalan yang bernilai tambah. Implementasi standar yang ditulis dengan jelas berfungsi sebagai titik awal bagi pengguna untuk belajar dan memperluasnya.
Qwix: Kuantisasi komprehensif yang tidak mengganggu
Qwix adalah library kuantisasi komprehensif untuk stack AI JAX, yang mendukung LLM dan jenis model lainnya di semua tahap, termasuk pelatihan (Quantization Aware Training (QAT), Quantization Technique (QT), Quantized Low-Rank Adaptation (QLoRA)) dan inferensi Post Training Quantization (PTQ), yang menargetkan runtime XLA dan perangkat.
Motivasi
Library kuantisasi yang ada, terutama di ekosistem PyTorch, sering kali memiliki tujuan terbatas (misalnya, hanya PTQ atau hanya QLoRA). Lanskap yang terfragmentasi ini memaksa Anda beralih alat, sehingga menghambat penggunaan kode yang konsisten dan pencocokan numerik yang tepat antara pelatihan dan inferensi. Selain itu, banyak solusi memerlukan modifikasi model yang substansial, yang mengikat logika model secara erat ke logika kuantisasi.
Desain
Filosofi desain Qwix menekankan solusi yang komprehensif dan, yang paling penting, integrasi model yang tidak mengganggu. Arsitekturnya memiliki desain hierarkis dan dapat di-extend yang dibangun di atas API fungsional yang dapat digunakan kembali.
Integrasi yang tidak mengganggu ini dicapai melalui mekanisme pencegatan yang dirancang dengan cermat yang mengalihkan fungsi JAX ke fungsi yang dikuantisasi. Hal ini memungkinkan Anda mengintegrasikan model tanpa modifikasi apa pun, sehingga kode kuantisasi sepenuhnya terpisah dari definisi model.
Contoh berikut menunjukkan penerapan kuantisasi w4a4 (bobot 4-bit, aktivasi 4-bit) ke lapisan MLP LLM dan kuantisasi w8 (bobot 8-bit) ke embedder. Untuk mengubah resep kuantisasi, Anda hanya perlu memperbarui daftar aturan.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Kekuatan utama
- Solusi Komprehensif: Qwix dapat diterapkan secara luas di berbagai skenario kuantisasi, sehingga memastikan penggunaan kode yang konsisten antara pelatihan dan inferensi.
- Integrasi Model yang Tidak Mengganggu: Seperti yang ditunjukkan contoh, Anda dapat mengintegrasikan model dengan satu baris kode. Hal ini memungkinkan Anda menggunakan hyperparameter di berbagai skema kuantisasi untuk menemukan kompromi kualitas versus performa terbaik.
- Gabungan dengan Library Lainnya: Qwix terintegrasi dengan lancar dengan stack AI JAX. Misalnya, Tokamax otomatis beradaptasi untuk menggunakan kernel versi terkuantisasi, tanpa kode pengguna tambahan, saat model dikuantisasi dengan Qwix.
- Mendukung Riset: API dasar dan arsitektur Qwix yang dapat di-extend memungkinkan peneliti menjelajahi algoritma baru dan memfasilitasi perbandingan langsung dengan alat evaluasi dan tolok ukur terintegrasi.
Lapisan aplikasi: pelatihan dan penyelarasan
Pelatihan model dasar: MaxText dan MaxDiffusion
MaxText dan MaxDiffusion adalah framework pelatihan model LLM dan Difusi unggulan Google. Repositori ini berisi pilihan implementasi yang sangat dioptimalkan dari model open-weight populer. Model ini memiliki tujuan ganda: berfungsi sebagai codebase pelatihan model yang siap digunakan dan sebagai referensi yang dapat digunakan oleh pembuat model dasar untuk membangun model yang lebih canggih.
Motivasi
Ada pertumbuhan minat yang pesat di seluruh industri dalam melatih model GenAI. Popularitas model terbuka telah mempercepat tren ini, dengan menyediakan arsitektur yang terbukti. Pelatihan dan adaptasi model ini memerlukan performa tinggi, efisiensi, skalabilitas ke sejumlah besar chip, dan kode yang jelas serta mudah dipahami. MaxText dan MaxDiffusion adalah solusi komprehensif yang dapat digunakan di TPU atau GPU dan dirancang untuk memenuhi kebutuhan ini.
Desain
MaxText dan MaxDiffusion adalah codebase model dasar yang dirancang dengan mempertimbangkan keterbacaan dan performa. Model ini disusun dengan komponen yang teruji dengan baik dan dapat digunakan kembali: definisi model yang menggunakan kernel kustom (seperti Tokamax) untuk performa maksimum, harness pelatihan untuk orkestrasi dan pemantauan, serta sistem konfigurasi yang canggih yang memungkinkan Anda mengontrol detail seperti sharding dan kuantisasi (menggunakan Qwix) melalui antarmuka yang intuitif. Fitur keandalan lanjutan seperti checkpointing multi-tingkat disertakan untuk memastikan throughput yang baik dan berkelanjutan.
MaxText dan MaxDiffusion menggunakan library JAX terbaik di kelasnya, yaitu Qwix, Tunix, Orbax, dan Optax untuk memberikan kemampuan inti. Library ini menyediakan infrastruktur yang andal dan skalabel, sehingga mengurangi beban pengembangan dan memungkinkan Anda berfokus pada tugas pemodelan. Untuk inferensi, kode model dibagikan untuk memungkinkan penyajian yang efisien dan dapat diskalakan.
Kekuatan utama
- Performa yang Dirancang: Dengan infrastruktur pelatihan yang disiapkan untuk "goodput" (throughput yang berguna) tinggi dan implementasi model yang dioptimalkan untuk MFU (Penggunaan Operasi Floating Point Model) tinggi, MaxText dan MaxDiffusion memberikan performa tinggi dalam skala besar secara langsung.
- Dibuat untuk Skala: Dengan memanfaatkan kecanggihan stack AI JAX (terutama Pathways), framework ini memungkinkan Anda melakukan penskalaan secara lancar dari puluhan chip hingga puluhan ribu chip.
- Dasar yang Kuat untuk Pembuat Model Dasar: Penerapan berkualitas tinggi dan mudah dibaca berfungsi sebagai titik awal yang kuat bagi developer untuk digunakan sebagai solusi end-to-end atau sebagai penerapan referensi untuk penyesuaian mereka sendiri.
Setelah pelatihan dan penyelarasan: Framework Tunix
Tunix menawarkan algoritma reinforcement learning (RL) open source canggih, beserta framework dan infrastruktur yang andal, sehingga memberikan jalur yang efisien bagi developer untuk bereksperimen dengan teknik pasca-pelatihan LLM, termasuk penyesuaian yang diawasi (SFT) dan penyelarasan menggunakan JAX dan TPU.
Motivasi
Pasca-pelatihan adalah langkah penting untuk memanfaatkan kemampuan LLM yang sesungguhnya. Tahap reinforcement learning (RL) sangat penting untuk mengembangkan kemampuan penalaran dan keselarasan. Pengembangan open source di area ini hampir secara eksklusif didasarkan pada PyTorch dan GPU, sehingga menimbulkan kesenjangan mendasar untuk solusi JAX dan TPU. Tunix (Tune-in-JAX) adalah library berperforma tinggi dan native JAX yang dirancang untuk mengisi kesenjangan ini.
Desain
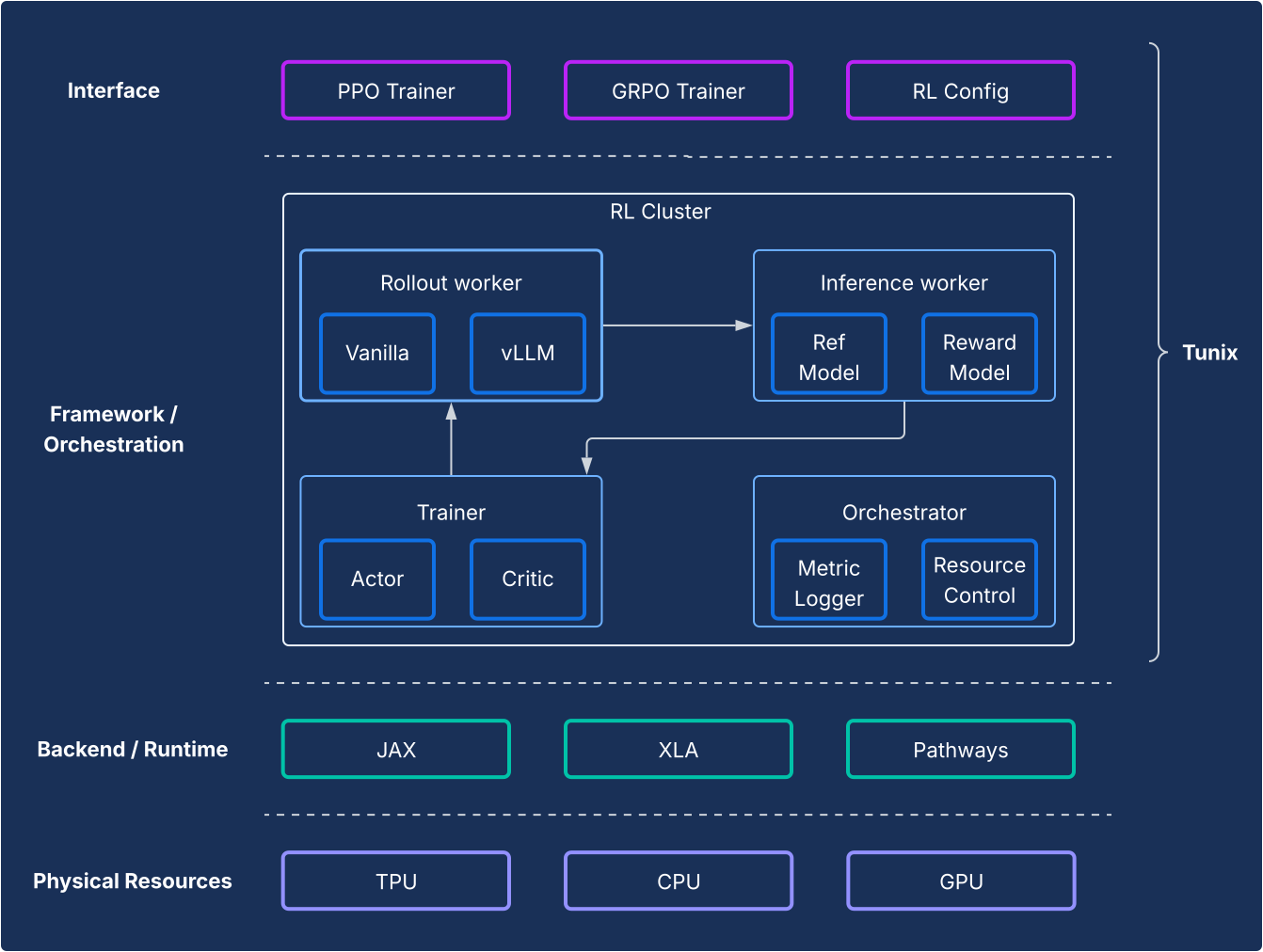
Dari perspektif framework, Tunix memungkinkan penyiapan canggih yang memisahkan algoritma RL dengan jelas dari infrastruktur. API ini menawarkan API ringan seperti klien yang menyembunyikan kompleksitas infrastruktur RL, sehingga Anda dapat mengembangkan algoritma baru. Tunix menyediakan solusi siap pakai untuk algoritma populer, termasuk Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO), dan lainnya.
Di sisi infrastruktur, Tunix memiliki integrasi dengan Pathways, yang memungkinkan arsitektur pengontrol tunggal yang membuat pelatihan RL multi-node dapat diakses. Di sisi pelatihan, Tunix secara native mendukung pelatihan yang efisien parameter (misalnya, LoRA) dan memanfaatkan sharding JAX dan XLA (General and Scalable Parallelization for ML Computation Graph (GSPMD)) untuk menghasilkan grafik komputasi yang berperforma tinggi. Layanan ini mendukung model open source populer seperti Gemma dan Llama secara langsung.
Kekuatan utama
- Kesederhanaan: API ini menyediakan API tingkat tinggi seperti klien yang mengabstraksi kompleksitas infrastruktur terdistribusi yang mendasarinya.
- Efisiensi Developer: Tunix mempercepat siklus proses R&D dengan algoritma dan "resep" bawaan, sehingga Anda mendapatkan model yang berfungsi dan dapat melakukan iterasi dengan cepat.
- Performa dan Skalabilitas: Tunix memungkinkan infrastruktur pelatihan yang sangat efisien dan dapat diskalakan secara horizontal dengan memanfaatkan Pathways sebagai pengontrol tunggal di backend.
Lapisan aplikasi: Produksi dan inferensi
Tantangan historis untuk adopsi JAX adalah jalur dari riset ke produksi. Stack AI JAX kini menyediakan kisah produksi dua cabang yang matang, yang menawarkan kompatibilitas ekosistem dan performa JAX.
Inferensi LLM berperforma tinggi: Solusi vLLM
vLLM-TPU adalah stack inferensi berperforma tinggi Google yang dirancang untuk menjalankan Model Bahasa Besar (LLM) PyTorch dan JAX secara efisien di Cloud TPU. Hal ini dicapai dengan mengintegrasikan framework vLLM open source populer secara native dengan ekosistem JAX dan TPU Google.
Motivasi
Industri ini berkembang pesat, dengan permintaan yang terus meningkat untuk solusi inferensi yang lancar, berperforma tinggi, dan mudah digunakan. Developer sering kali menghadapi tantangan signifikan dari alat yang kompleks dan tidak konsisten, performa yang kurang memuaskan, dan kompatibilitas model yang terbatas. Stack vLLM mengatasi masalah ini dengan menyediakan platform terpadu, berperforma tinggi, dan intuitif.
Desain
Solusi ini memperluas framework vLLM, bukan membuatnya dari awal. vLLM-TPU adalah mesin penayangan LLM open source yang sangat dioptimalkan dan dikenal karena throughput-nya yang tinggi, yang dicapai menggunakan fitur utama seperti PagedAttention (yang mengelola cache KV seperti memori virtual untuk meminimalkan fragmentasi) dan Continuous Batching (yang secara dinamis menambahkan permintaan ke batch untuk meningkatkan pemanfaatan).
vLLM-TPU dibangun berdasarkan fondasi ini dan mengembangkan komponen inti untuk penanganan permintaan, penjadwalan, dan pengelolaan memori. Backend ini memperkenalkan backend berbasis JAX yang bertindak sebagai jembatan, menerjemahkan grafik komputasi dan operasi memori vLLM ke dalam kode yang dapat dieksekusi TPU. Backend ini menangani interaksi perangkat, eksekusi model JAX, dan spesifikasi pengelolaan cache KV pada hardware TPU. Model ini menggabungkan pengoptimalan khusus TPU, seperti mekanisme perhatian yang efisien (misalnya, memanfaatkan kernel JAX Pallas untuk Ragged Paged Attention) dan kuantisasi, yang semuanya disesuaikan untuk arsitektur TPU.
Kekuatan utama
- Biaya Aktivasi/Penonaktifan Pengguna Nol: Pengguna dapat menggunakan solusi ini tanpa hambatan yang signifikan. Dari perspektif pengalaman pengguna, pemrosesan permintaan inferensi di TPU harus sama dengan di GPU. CLI untuk memulai server, menerima perintah, dan menampilkan output semuanya sama.
- Menggunakan Ekosistem Sepenuhnya: Pendekatan ini memanfaatkan dan berkontribusi pada antarmuka dan pengalaman pengguna vLLM, sehingga memastikan kompatibilitas dan kemudahan penggunaan.
- Fungibilitas antara TPU dan GPU: Solusi ini berfungsi secara efisien di TPU dan GPU, sehingga memberi Anda fleksibilitas.
- Hemat Biaya (Performa Terbaik/$): Mengoptimalkan performa untuk memberikan rasio performa terhadap biaya terbaik untuk model populer.
Penayangan JAX: Serialisasi Orbax dan mesin penayangan Neptune
Untuk model selain LLM, atau bagi pengguna yang menginginkan pipeline sepenuhnya JAX-native, library serialisasi Orbax dan sistem mesin penayangan Neptune (NSE) menyediakan solusi penayangan berperforma tinggi yang menyeluruh.
Motivasi
Sebelumnya, model JAX sering kali mengandalkan jalur yang berbelit-belit untuk produksi, seperti di-wrap dalam grafik TensorFlow dan di-deploy menggunakan TensorFlow Serving. Pendekatan ini menimbulkan batasan dan inefisiensi yang signifikan, sehingga memaksa developer untuk berinteraksi dengan ekosistem terpisah dan memperlambat iterasi. Sistem penayangan khusus JAX-native sangat penting untuk keberlanjutan, pengurangan kompleksitas, dan performa yang dioptimalkan.
Desain
Solusi ini terdiri dari dua komponen inti, seperti yang diilustrasikan dalam diagram berikut.
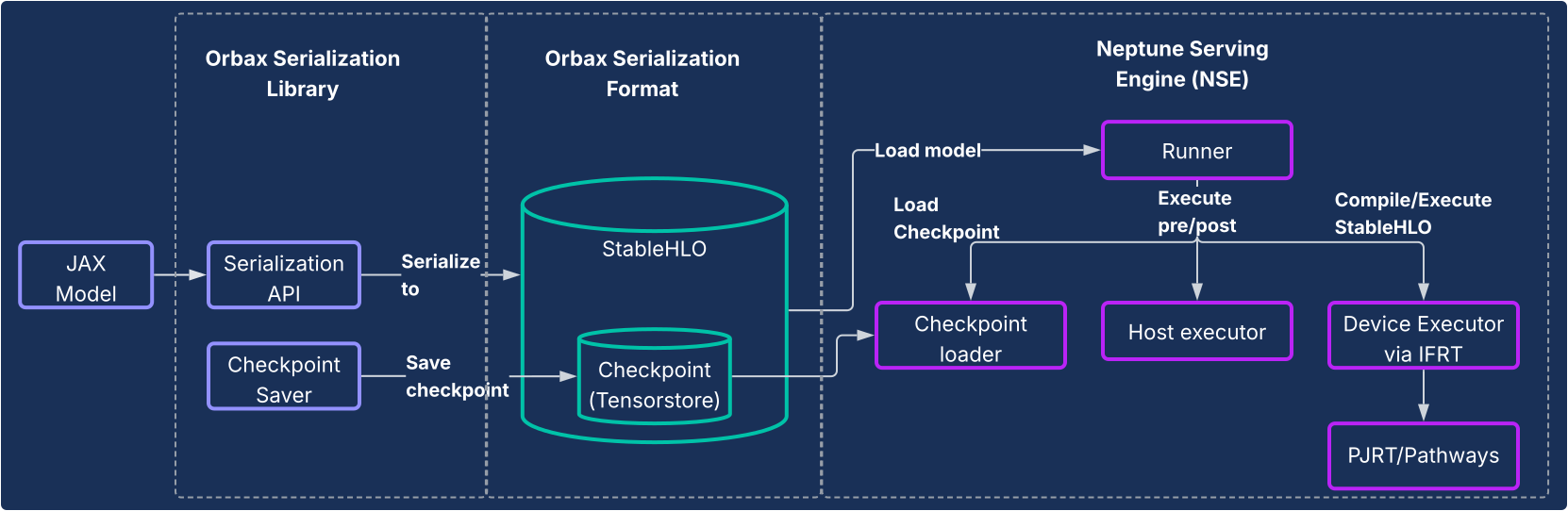
- Orbax Serialization Library: Menyediakan API yang mudah digunakan untuk menyerialkan model JAX ke dalam format serialisasi Orbax baru yang andal. Format ini dioptimalkan untuk deployment produksi. Hal ini secara langsung merepresentasikan komputasi model JAX menggunakan StableHLO, sehingga memungkinkan grafik komputasi direpresentasikan secara native. Selain itu, TensorStore digunakan untuk menyimpan bobot, sehingga memungkinkan pemuatan titik pemeriksaan yang cepat untuk penayangan.
- Neptune Serving Engine (NSE): Ini adalah mesin penayangan berperforma tinggi dan fleksibel yang menyertainya (biasanya di-deploy sebagai biner C++) yang dirancang untuk menjalankan model JAX secara native dalam format Orbax. NSE menawarkan kemampuan penting untuk produksi, seperti pemuatan model yang cepat, penayangan serentak dengan throughput tinggi dengan pengelompokan bawaan, dukungan untuk beberapa versi model, dan penayangan host tunggal dan ganda (dengan memanfaatkan PJRT dan Pathways). Menggunakan Neptune
Serving Engine untuk:
- Model non-LLM: Solusi ini adalah solusi serbaguna yang ideal untuk beban kerja seperti sistem rekomendasi, model difusi, dan model AI lainnya.
- LLM kecil dan penayangan "sekali lihat": Dirancang untuk model non-autoregresif atau model yang lebih kecil yang ditayangkan secara "unary", dengan seluruh output dihasilkan dalam satu proses tanpa memerlukan pengelolaan status yang kompleks seperti cache KV.
Singkatnya, Neptune Serving Engine mengisi kesenjangan untuk menyajikan berbagai model yang bukan model bahasa autoregresif besar, sehingga memberikan solusi native TPU berperforma tinggi untuk ekosistem ML yang lebih luas.
Kekuatan utama
- Penayangan Native JAX: Solusi ini dibuat secara native untuk JAX, sehingga menghilangkan overhead antar-framework dalam serialisasi dan penayangan model. Hal ini memastikan pemuatan model yang cepat dan eksekusi yang dioptimalkan di seluruh CPU, GPU, dan TPU.
- Deployment Produksi yang Mudah: Model berserial menyediakan jalur deployment hermetik yang tidak terpengaruh oleh penyimpangan dalam dependensi Python dan memungkinkan pemeriksaan integritas model runtime. Hal ini memberikan jalur yang lancar dan intuitif untuk produksi model JAX.
- Peningkatan Pengalaman Developer: Dengan meniadakan kebutuhan untuk pembungkus framework yang rumit, solusi ini secara signifikan mengurangi dependensi dan kompleksitas sistem, sehingga mempercepat iterasi bagi developer JAX.
Analisis dan pembuatan profil di seluruh sistem
XProf: Profiling performa terintegrasi hardware yang mendalam
XProf adalah alat analisis performa dan pembuatan profil yang memberikan visibilitas mendalam ke berbagai aspek eksekusi workload ML, sehingga Anda dapat men-debug dan mengoptimalkan performa. API ini terintegrasi secara mendalam ke dalam ekosistem JAX dan TPU.
Motivasi
Di satu sisi, workload ML menjadi semakin rumit. Di sisi lain, ada peningkatan kemampuan hardware khusus yang menargetkan workload ini. Mencocokkan keduanya secara efektif untuk memastikan performa dan efisiensi puncak sangat penting, mengingat besarnya biaya infrastruktur ML. Hal ini memerlukan visibilitas yang mendalam ke dalam workload dan hardware, yang disajikan dengan cara yang dapat dipahami dengan cepat. XProf unggul dalam hal ini.
Desain
XProf terdiri dari dua komponen utama: pengumpulan dan analisis.
- Pengumpulan: XProf mengambil informasi dari berbagai sumber: anotasi dalam kode JAX Anda, model biaya untuk operasi dalam compiler XLA, dan fitur pembuatan profil hardware khusus dalam TPU. Pengumpulan ini dapat dipicu secara terprogram atau sesuai permintaan, sehingga menghasilkan artefak peristiwa yang komprehensif.
- Analisis: XProf memproses data yang dikumpulkan dan membuat serangkaian visualisasi yang canggih, yang dapat diakses dengan browser.
Kekuatan utama
Kemampuan XProf yang sebenarnya berasal dari integrasi mendalamnya dengan stack penuh, yang memberikan analisis yang luas dan mendalam yang merupakan manfaat nyata dari ekosistem JAX/TPU yang didesain bersama.
- Didesain bersama dengan TPU: XProf memanfaatkan fitur hardware yang secara khusus didesain untuk pengumpulan profil yang lancar, sehingga memungkinkan overhead pengumpulan kurang dari 1%. Hal ini memungkinkan pembuatan profil menjadi bagian pengembangan yang ringan dan iteratif.
- Luas dan Kedalaman Analisis: XProf menghasilkan analisis mendalam di beberapa sumbu. Alatnya meliputi:
- Trace Viewer: Tampilan linimasa operasi eksekusi di berbagai unit hardware (misalnya, TensorCore).
- Profil Operasi HLO: Mengelompokkan total waktu yang dihabiskan ke dalam berbagai kategori operasi.
- Penampil Memori: Menampilkan detail alokasi memori menurut berbagai operasi selama jendela yang di-profil.
- Analisis Roofline: Membantu Anda mengidentifikasi apakah operasi tertentu terikat pada komputasi atau memori dan seberapa jauh operasi tersebut dari kemampuan puncak hardware.
- Graph Viewer: Memberikan tampilan ke dalam grafik HLO lengkap yang dieksekusi oleh hardware.
Perspektif komparatif: Stack JAX/TPU sebagai pilihan yang menarik
Lanskap Machine Learning modern menawarkan banyak toolchain yang sangat baik dan matang. JAX AI Stack menghadirkan serangkaian keunggulan yang unik dan menarik bagi developer yang berfokus pada ML berperforma tinggi dalam skala besar, yang berasal langsung dari desain modular dan desain bersama hardware yang mendalam.
Meskipun banyak framework menawarkan berbagai fitur, JAX AI Stack memberikan pembeda yang spesifik dan efektif di area utama siklus proses pengembangan:
- Pengalaman developer yang lebih sederhana dan efektif: Paradigma transformasi gradien yang dapat dirangkai dari Optax memungkinkan strategi pengoptimalan yang lebih efektif dan fleksibel yang dideklarasikan sekali, bukan dikelola secara imperatif dalam loop pelatihan. Di tingkat sistem, antarmuka pengontrol tunggal Pathways yang lebih sederhana menghilangkan kompleksitas pelatihan multiris, yang merupakan penyederhanaan signifikan bagi peneliti.
- Direkayasa untuk ketahanan skala heroik: Stack JAX dirancang untuk pelatihan skala ekstrem. Orbax menyediakan fitur "ketahanan pelatihan skala heroik" seperti checkpointing darurat dan multi-tingkat. Hal ini dilengkapi oleh Grain, yang menawarkan dukungan penuh untuk reproduksibilitas dengan pengacakan global deterministik dan pemuat data yang dapat diperiksa. Kemampuan untuk membuat checkpoint secara atomik pada status pipeline data (Grain) dengan status model (Orbax) adalah kemampuan penting untuk menjamin reproduksibilitas dalam tugas yang berjalan lama.
- Ekosistem menyeluruh yang lengkap: Stack ini menyediakan solusi menyeluruh yang kohesif. Developer dapat menggunakan MaxText sebagai referensi SOTA untuk pelatihan, Tunix untuk penyelarasan, dan mengikuti jalur ganda yang jelas menuju produksi dengan vLLM-TPU (untuk kompatibilitas vLLM) dan NSE (untuk performa JAX).
Meskipun banyak stack yang serupa dari sudut pandang software tingkat tinggi, faktor penentu sering kali adalah Performa/TCO, yang menjadi keunggulan tersendiri dari desain bersama JAX dan TPU. Manfaat Performa/TCO ini adalah hasil langsung dari integrasi vertikal di seluruh software dan hardware TPU. Kemampuan compiler XLA untuk menggabungkan operasi secara khusus untuk arsitektur TPU, atau kemampuan profiler XProf untuk menggunakan hook hardware untuk pembuatan profil dengan overhead <1%, adalah manfaat nyata dari integrasi mendalam ini.
Untuk organisasi yang mengadopsi stack ini, sifat JAX AI yang memiliki fitur lengkap meminimalkan biaya migrasi. Untuk pelanggan yang menggunakan arsitektur model open source populer, peralihan dari framework lain ke MaxText sering kali hanya memerlukan penyiapan file konfigurasi. Selain itu, kemampuan stack untuk memproses format checkpoint populer seperti safetensors memungkinkan checkpoint yang ada dimigrasikan tanpa perlu pelatihan ulang yang mahal.
Tabel berikut menyediakan pemetaan komponen yang disediakan oleh stack AI JAX dan komponen yang setara di framework atau library lain.
| Fungsi | JAX | Alternatif/persamaan dalam framework lain5 |
| Compiler / runtime | XLA | Induktor, bersemangat |
| Pelatihan MultiPod | Jalur | Strategi kilat Torch, Ray Train, Monarch (baru). |
| Framework inti | JAX | PyTorch |
| Pembuatan model | Model Flax, Max* | torch.nn.*,
NVidia TransformerEngine, HuggingFace Transformers
|
| Pengoptimal & kerugian | Optax | torch.optim.*, torch.nn.*Loss |
| Pemuat Data | Butiran | Ray Data, pemuat data HuggingFace |
| Checkpointing | Orbax | Checkpointing terdistribusi PyTorch, Checkpointing NeMo |
| Kuantisasi | Qwix | TorchAO, bitsandbytes |
| Penulisan kernel & penerapan yang umum | Pallas / Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| Pasca-pelatihan / penyesuaian | Tunix | VERL, NeMoRL |
| Pembuatan profil | XProf | Profiler PyTorch, NSight Systems, NSight Compute |
| Pelatihan model dasar | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| Inferensi LLM | vLLM | SGLang |
| Inferensi Non-LLM | NSE | Triton Inference Server, RayServe |
5Beberapa persamaan di sini tidak selalu merupakan perbandingan yang akurat karena framework lain menggambar batas API secara berbeda dibandingkan dengan JAX. Daftar persamaan tidak lengkap dan ada library baru yang sering muncul.
Kesimpulan: Platform yang andal dan siap produksi untuk masa depan AI
Data yang diberikan dalam tabel sebelumnya menggambarkan kesimpulan yang jelas - stack ini memiliki kelebihan dan kekurangan masing-masing di sejumlah kecil area, tetapi secara keseluruhan sangat mirip dari sudut pandang software. Kedua stack ini menyediakan solusi siap pakai untuk pra-pelatihan, adaptasi pasca-pelatihan, dan deployment model dasar.
Stack AI JAX menawarkan solusi yang menarik dan andal untuk melatih dan men-deploy model ML dalam skala apa pun. Solusi ini memanfaatkan integrasi vertikal yang mendalam di seluruh software dan hardware TPU untuk memberikan performa terbaik di kelasnya dan total biaya kepemilikan.
Dengan dibangun di atas sistem internal yang telah teruji, stack ini telah berkembang untuk memberikan keandalan dan skalabilitas yang inheren, sehingga memungkinkan pengguna mengembangkan dan men-deploy model terbesar sekalipun dengan percaya diri. Desainnya yang modular dan dapat disusun, yang berakar pada filosofi stack AI JAX, memberikan kebebasan dan kontrol yang tak tertandingi kepada pengguna, sehingga mereka dapat menyesuaikan stack dengan kebutuhan spesifik mereka tanpa batasan framework monolitik.
Dengan XLA dan Pathways yang menyediakan dasar yang skalabel dan toleran terhadap kesalahan, JAX yang menyediakan library numerik berperforma tinggi dan ekspresif, library pengembangan inti yang canggih seperti Flax, Optax, Grain, dan Orbax, alat performa canggih seperti Pallas, Tokamax, dan Qwix, serta lapisan aplikasi dan produksi yang andal di MaxText, vLLM, dan NSE, stack AI JAX memberikan fondasi yang kuat bagi pengguna untuk membangun dan dengan cepat menghadirkan riset canggih ke produksi.