
Este documento descreve como configurar um agente LangGraph ReAct ou um agente de IA generativa criado com o framework do Kit de Desenvolvimento de Agente (ADK) para enviar comandos e respostas multimodais ao seu projeto Google Cloud . Também descreve como visualizar, analisar e avaliar sua mídia multimodal armazenada:
Use a página Explorador de traces para ver comandos ou respostas individuais ou uma conversa inteira. Você pode conferir a mídia em um formato renderizado ou bruto. Para saber mais, consulte Ver comandos e respostas multimodais.
Use os serviços do BigQuery para analisar os dados multimodais. Por exemplo, você pode usar uma função como
AI.GENERATEpara resumir uma conversa. Para saber mais, consulte Analisar dados de solicitação-resposta usando o BigQuery.Use o SDK da Vertex AI para avaliar uma conversa. Por exemplo, você pode usar o Google Colaboratory para fazer uma análise de sentimentos. Para saber mais, consulte Executar avaliações nos dados de solicitação-resposta com o Colaboratory.
Tipos de mídia que você pode coletar
É possível coletar os seguintes tipos de mídia:
- Áudio.
- Documentos.
- Imagens.
- Texto simples e texto formatado em Markdown.
- Vídeo.
Seus comandos e respostas podem incluir conteúdo e links inline. Os links podem direcionar para recursos públicos ou buckets do Cloud Storage.
Onde seus comandos e respostas são armazenados
Quando o aplicativo autônomo cria ou recebe comandos ou respostas, o SDK usado invoca a instrumentação do OpenTelemetry. Essa instrumentação formata os comandos e as respostas, além dos dados multimodais que eles podem conter, de acordo com a versão 1.37.0 das convenções semânticas da GenAI do OpenTelemetry. Versões mais recentes também são compatíveis.
Em seguida, a instrumentação do OpenTelemetry faz o seguinte:
Ele cria identificadores de objetos para solicitações e dados de resposta e grava esses dados no seu bucket do Cloud Storage. As entradas no seu bucket do Cloud Storage são salvas no formato JSON Lines.
Ele envia dados de registro e rastreamento para seu projeto Google Cloud , em que os serviços Logging e Trace ingerem e armazenam os dados. As convenções semânticas do OpenTelemetry determinam muitos dos atributos e campos anexados às entradas de registro ou aos intervalos de rastreamento.
Quando a instrumentação do OpenTelemetry cria objetos de bucket do Cloud Storage, ela também grava uma entrada de registro que contém referências a esses objetos. O exemplo a seguir mostra parte de uma entrada de registro que inclui referências de objeto:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }No exemplo de entrada de registro, observe o seguinte:
- O rótulo
"event.name": "gen_ai.client.inference.operation.details"indica que a entrada de registro contém referências a objetos do Cloud Storage. - Os rótulos cujas chaves incluem
gen_aireferenciam um objeto em um bucket do Cloud Storage. - Todas as entradas de registro que contêm referências de objetos são gravadas no mesmo
registro, chamado
projects/my-project/logs/gen_ai.client.inference.operation.details.
Para saber como mostrar entradas de registro que contêm referências de objetos, consulte a seção Encontrar todas as entradas de registro que referenciam comandos e respostas deste documento.
- O rótulo
Coletar comandos e respostas multimodais
O SDK usado pelo aplicativo invoca automaticamente o OpenTelemetry para armazenar seus comandos e respostas e enviar dados de registro e rastreamento para o projeto Google Cloud . Não é necessário modificar o aplicativo. No entanto, é necessário configurar seu projetoGoogle Cloud e o SDK que você está usando.
Para coletar e visualizar seus comandos e respostas multimodais de um aplicativo, faça o seguinte:
Configure o projeto:
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Verifique se você tem um bucket do Cloud Storage. Se necessário, crie um bucket do Cloud Storage.
Portanto, recomendamos que você faça o seguinte:
Crie o bucket do Cloud Storage no mesmo local que o bucket de registros que armazena os dados de registro do aplicativo. Essa configuração torna as consultas do BigQuery mais eficientes.
Verifique se a classe de armazenamento do bucket do Cloud Storage é compatível com tabelas externas. Com esse recurso, é possível consultar seus comandos e respostas com o BigQuery. Se você não planeja usar as configurações padrão para um novo bucket do Cloud Storage, antes de criar o bucket, consulte Criar tabelas externas do Cloud Storage.
Defina o período de armazenamento do bucket do Cloud Storage para corresponder ao período de armazenamento do bucket de registros que armazena suas entradas de registro. O período de armazenamento padrão para dados de registro é de 30 dias. Para saber como definir o período de armazenamento do bucket do Cloud Storage, consulte Bloqueio de bucket.
Conceda à conta de serviço usada pelo aplicativo a permissão
storage.objects.createno bucket do Cloud Storage. Essa permissão permite que seu aplicativo grave objetos no bucket do Cloud Storage. Esses objetos armazenam os comandos e as respostas que seu aplicativo agente cria ou recebe. Para mais informações, consulte Definir e gerenciar políticas do IAM em buckets.
-
Configure o SDK:
Instale e faça upgrade das seguintes dependências:
ADK
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
LangGraph
opentelemetry-instrumentation-vertexai==2.2b0(ou mais recente)opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
Se você estiver usando o ADK, atualize a invocação do aplicativo para ativar a flag
otel_to_cloud:Se você estiver usando a CLI para ADK, execute o seguinte comando:
adk web --otel_to_cloud [other options]Caso contrário, transmita a flag ao criar o app FastAPI:
get_fast_api_app(..., otel_to_cloud=True)
Configure as variáveis de ambiente a seguir:
Instrua o OpenTelemetry a formatar objetos do Cloud Storage como JSON Lines.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Instrua o OpenTelemetry a fazer upload dos dados de comando e resposta em vez de incorporar esse conteúdo em períodos de trace. As referências aos objetos enviados são incluídas em uma entrada de registro.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Instrua o OpenTelemetry a usar as convenções semânticas mais recentes para IA generativa.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'Especifique o caminho para os objetos:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'Na expressão anterior, STORAGE_BUCKET se refere ao nome do bucket do Cloud Storage. PATH se refere ao caminho em que os objetos são armazenados.
Para agentes LangGraph ReAct, instrua o OpenTelemetry a capturar automaticamente dados de registro:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'
Conferir comandos e respostas multimodais
Para determinar os comandos e as respostas a serem mostrados em um período, o Cloud Trace emite consultas para ler dados de registro e dados armazenados em um bucket do Cloud Storage. Seus papéis do Identity and Access Management (IAM) nos recursos consultados determinam se os dados são retornados. Em alguns casos, uma mensagem de erro pode aparecer. Por exemplo, se você não tiver permissão para ler dados de um bucket do Cloud Storage, as tentativas de acessar esses dados vão resultar em um erro de permissão negada.
Os comandos e as respostas aparecem em um formato semelhante a um chat, e você seleciona se a mídia, como imagens, é renderizada automaticamente ou aparece no formato de origem. Da mesma forma, você pode ver todo o histórico de conversas ou apenas os comandos e respostas anexados a um período.
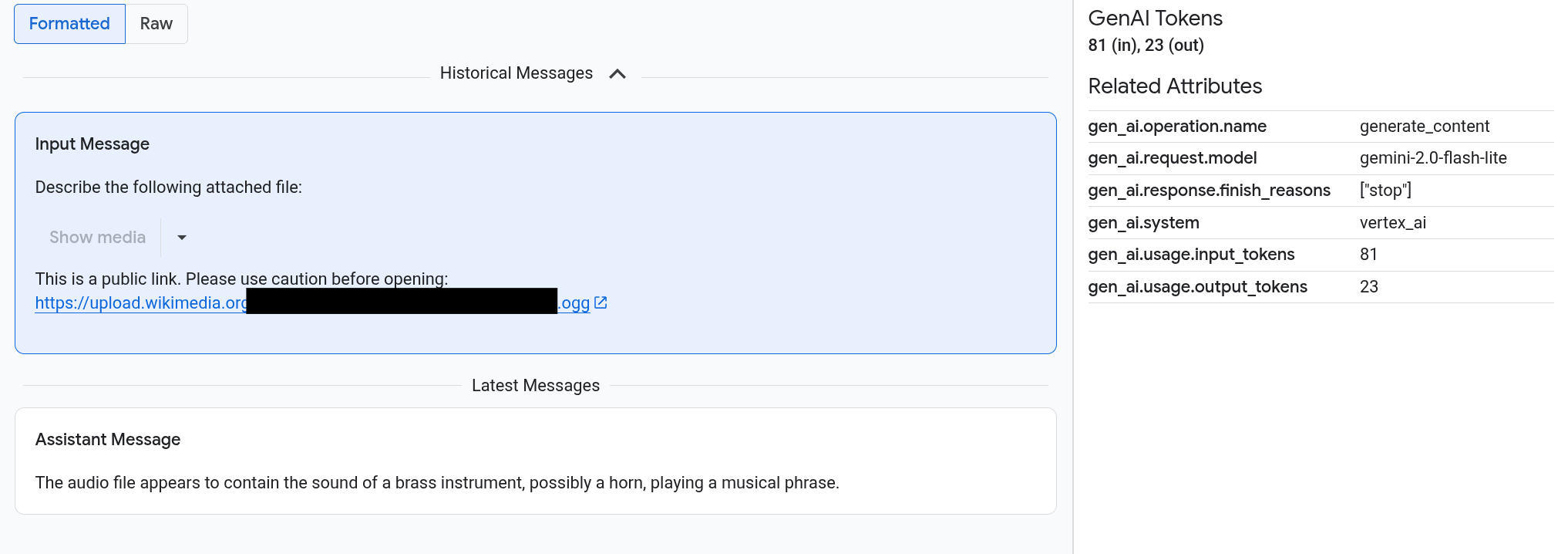
Por exemplo, o exemplo a seguir ilustra como os comandos e as respostas aparecem e como os atributos do OpenTelemetry são resumidos:
Antes de começar
Para ter as permissões necessárias para acessar seus comandos e respostas multimodais, peça ao administrador para conceder a você os seguintes papéis do IAM no projeto:
-
Usuário do Cloud Trace (
roles/cloudtrace.user) -
Visualizador de registros (
roles/logging.viewer) -
Leitor de objetos do Storage (
roles/storage.objectViewer)
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Também é possível conseguir as permissões necessárias usando papéis personalizados ou outros papéis predefinidos.
Encontrar intervalos que contenham comandos e respostas multimodais
Para encontrar os intervalos que contêm comandos e respostas multimodais, faça o seguinte:
-
No console Google Cloud , acesse a página Explorador de traces:
Acessar o Explorador de traces
Também é possível encontrar essa página usando a barra de pesquisa.
No painel Filtro de extensão, acesse a seção Nome da extensão e selecione
generate_content.Se preferir, adicione o filtro
gen_ai.operation.name: generate_content.Selecione um intervalo na lista.
A página Detalhes do intervalo é aberta. Essa página mostra o período no contexto do rastreamento. Se um nome de intervalo tiver um botão chamado Entradas/Saídas,
 , significa que há
eventos de IA generativa disponíveis. A próxima seção, Analise seus comandos e respostas multimodais, explica como os dados são apresentados e as opções de visualização.
, significa que há
eventos de IA generativa disponíveis. A próxima seção, Analise seus comandos e respostas multimodais, explica como os dados são apresentados e as opções de visualização.
Analisar seus comandos e respostas multimodais
A guia Entradas/Saídas contém duas seções.
Uma seção mostra os comandos e as respostas, e a outra mostra OpenTelemetry: atributos. Essa guia aparece apenas quando os períodos enviados ao Trace seguem as convenções semânticas da GenAI do OpenTelemetry, versão 1.37.0 ou mais recente, o que resulta em mensagens com nomes que começam com gen_ai.
A guia Entradas/Saídas mostra suas mensagens em um formato semelhante a um chat. Você controla quais mensagens aparecem e o formato delas usando as opções na guia:
- Para ver toda a conversa, abra o painel Mensagens históricas.
- Para ver apenas os comandos e as respostas no período selecionado, use o painel Mensagens mais recentes.
Para ver imagens, vídeos ou outras mídias, selecione Formatado.
O sistema nem sempre mostra mídia. Para proteger você, se um comando ou resposta incluir um link para uma imagem, um documento ou um vídeo público, confirme se quer que a mídia seja mostrada. Da mesma forma, se um comando ou resposta incluir mídia armazenada no seu bucket do Cloud Storage e se a mídia for muito grande, você precisará confirmar que quer que ela seja mostrada.
Algumas mídias, como imagens e vídeos, aparecem com um menu anexado. Use esse menu para realizar ações como baixar uma imagem em uma unidade local. As opções do menu dependem do tipo de mídia.
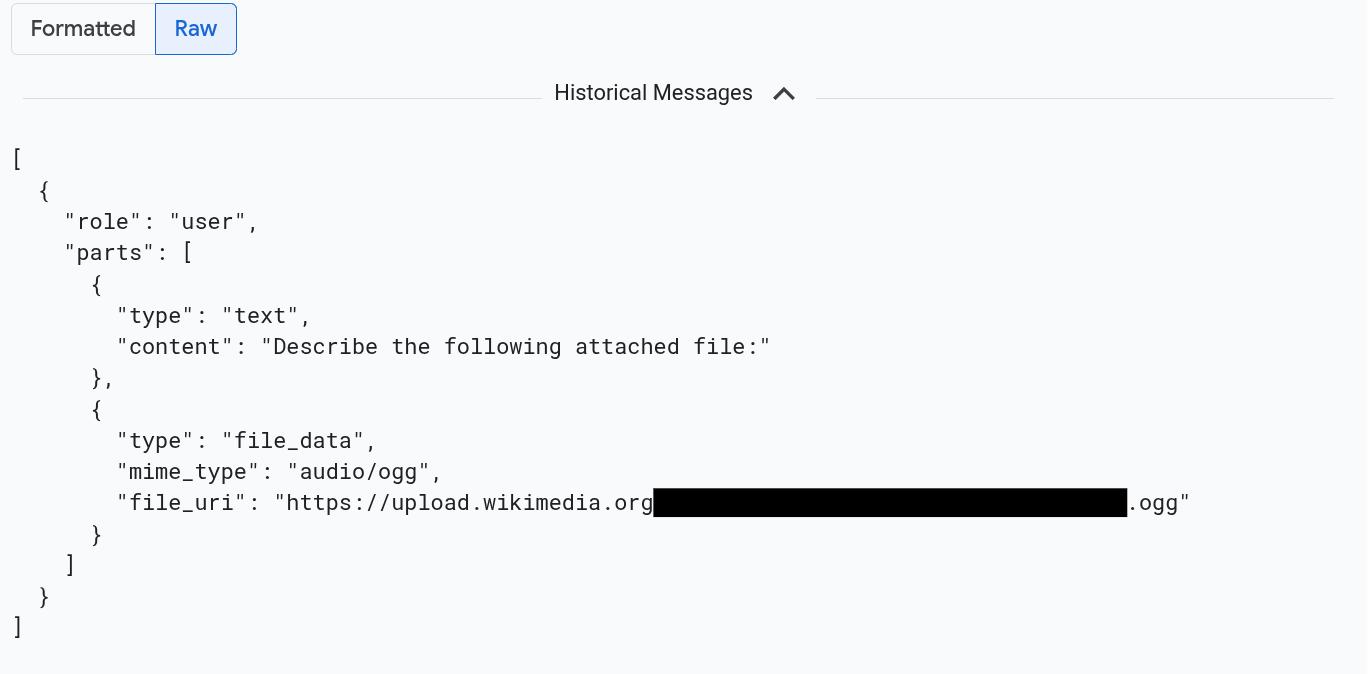
Para ver as mensagens formatadas em JSON, selecione Bruto. Com essa seleção, a mídia, como imagens, não é renderizada.
Por exemplo, a imagem a seguir ilustra como uma conversa aparece em formato bruto:
Encontrar todas as entradas de registro que fazem referência a comandos e respostas
Para listar as entradas de registro que incluem referências de objetos a comandos e respostas multimodais, faça o seguinte:
-
No console Google Cloud , acesse a página Análise de registros.
Acessar a Análise de registros
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Logging.
No seletor de projetos, selecione seu projeto Google Cloud .
Na barra de ferramentas, expanda Todos os nomes de registro, insira
gen_aino filtro e selecione o registro chamado gen_ai.client.inference.operation.details.As etapas anteriores adicionam a seguinte consulta à Análise de registros:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"Se preferir, copie a instrução e cole no painel Consulta do Explorador de registros, mas substitua PROJECT_ID pelo ID do projeto antes de copiar a instrução.
Também é possível filtrar dados de registros por valor de rótulo. Por exemplo, se você adicionar o filtro a seguir, somente as entradas de registro que contêm o rótulo especificado vão aparecer:
labels."event.name"="gen_ai.client.inference.operation.details"Para ver os comandos e as respostas referenciados por uma entrada de registro, clique em
 Ver detalhes do trace.
Ver detalhes do trace.Para saber como usar as opções na guia Entradas/Saídas, consulte a seção Explorar seus comandos e respostas multimodais deste documento.
Analisar dados de solicitação-resposta usando o BigQuery
É possível analisar os comandos e as respostas armazenados no bucket do Cloud Storage usando o BigQuery. Antes de fazer essa análise, siga estas etapas:
- Ative as APIs necessárias e verifique se você recebeu os papéis do IAM necessários.
- Crie um conjunto de dados vinculado no bucket de registros.
- Conceda ao BigQuery permissão para ler dados do seu bucket do Cloud Storage.
- Crie uma tabela externa.
Depois de criar a tabela externa, você mescla os dados no bucket de registros com a tabela externa e realiza a análise nos dados mesclados. Esta seção ilustra como combinar tabelas e extrair campos específicos. Ele também mostra como analisar a tabela unida com funções do BigQuery ML.
Antes de começar
Os papéis do IAM listados nesta seção são necessários para realizar ações como fazer upgrade de um bucket de registros e criar uma tabela externa. No entanto, depois que a configuração é concluída, menos permissões são necessárias para executar consultas.
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Para receber as permissões necessárias para configurar o sistema e acessar seus comandos e respostas multimodais no BigQuery, peça ao administrador para conceder a você os seguintes papéis do IAM no projeto:
-
Gravador de configuração de registros (
roles/logging.configWriter) -
Administrador de armazenamento (
roles/storage.admin) -
Administrador de conexão do BigQuery (
roles/bigquery.connectionAdmin) -
Visualizador de dados do BigQuery (
roles/bigquery.dataViewer) -
Usuário do BigQuery Studio (
roles/bigquery.studioUser)
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Também é possível conseguir as permissões necessárias usando papéis personalizados ou outros papéis predefinidos.
-
Gravador de configuração de registros (
Criar um conjunto de dados vinculado no bucket de registros
Para determinar se o bucket de registros que armazena seus dados foi atualizado para a Análise de dados de registros, execute o seguinte comando:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONSubstitua o seguinte antes de executar o comando:
- LOG_BUCKET_ID: o ID do bucket de registros.
- LOCATION: o local do bucket de registros.
Quando um bucket de registros é atualizado para a Análise de registros, os resultados do comando
describeincluem a seguinte declaração:analyticsEnabled: trueSe o bucket de registros não for atualizado, execute o seguinte comando:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncO upgrade pode levar alguns minutos para ser concluído. Quando o comando
describeinformar que olifecycleStateéACTIVE, o upgrade estará concluído.Para criar um conjunto de dados vinculado no bucket de registros, execute o seguinte comando:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONSubstitua o seguinte antes de executar o comando:
- LOG_BUCKET_ID: o ID do bucket de registros.
- LOCATION: o local do bucket de registros.
- LINKED_DATASET_NAME: nome do conjunto de dados vinculado a ser criado.
Com o conjunto de dados vinculado, o BigQuery pode ler os dados de registro armazenados no bucket de registros. Para saber mais, consulte Consultar um conjunto de dados vinculado do BigQuery.
Para confirmar se o link existe, execute o seguinte comando:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONSe o comando anterior for bem-sucedido, a resposta vai incluir a seguinte linha:
LINK_ID: LINKED_DATASET_NAME
Conceder ao BigQuery permissão para ler do seu bucket do Cloud Storage
Para criar uma conexão do BigQuery, execute o seguinte comando:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDSubstitua o seguinte antes de executar o comando:
- PROJECT_ID: o identificador do projeto.
- CONNECTION_ID: o ID da conexão a ser criada.
- CONNECTION_LOCATION: o local da conexão.
Quando o comando for concluído, uma mensagem semelhante a esta será exibida:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdVerifique a conexão.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDA resposta a esse comando lista o ID da conexão e uma conta de serviço:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Conceda à conta de serviço da conexão do BigQuery uma função do IAM que permita ler os dados armazenados no bucket do Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerSubstitua o seguinte antes de executar o comando:
- STORAGE_BUCKET: o nome do bucket do Cloud Storage.
- SERVICE_ACCT_EMAIL: o endereço de e-mail da sua conta de serviço.
Criar uma tabela externa do BigLake
Para usar o BigQuery e consultar dados que ele não armazena, crie uma tabela externa. Como um bucket do Cloud Storage armazena os comandos e as respostas, crie uma tabela externa do BigLake.
-
No Google Cloud console, acesse a página BigQuery.
Também é possível encontrar essa página usando a barra de pesquisa.
No editor de consultas, digite a seguinte instrução:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Substitua o seguinte antes de executar o comando:
- PROJECT_ID: o identificador do projeto.
- EXT_TABLE_DATASET_NAME: o nome do conjunto de dados a ser criado.
- EXT_TABLE_NAME: o nome da tabela externa do BigLake a ser criada.
- CONNECTION_LOCATION: o local do seu CONNECTION_ID.
- CONNECTION_ID: o ID da conexão.
- STORAGE_BUCKET: o nome do bucket do Cloud Storage.
- PATH: o caminho para os comandos e respostas. A variável de ambiente
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHespecifica o caminho.
Clique em Executar.
Para saber mais sobre tabelas externas, consulte:
Mesclar a tabela externa com os dados de registros
Esta seção mostra como analisar seus comandos multimodais no BigQuery. A solução depende da junção da sua tabela externa do BigLake com os dados de registro, o que permite recuperar objetos do seu bucket do Cloud Storage. O exemplo faz uma junção no URI das mensagens de entrada, gen_ai.input.messages. Você também pode fazer uma junção no URI das mensagens de saída, gen_ai.output.messages, ou nas instruções do sistema, gen_ai.system_instructions.
Para unir sua tabela externa do BigLake aos dados de registro, faça o seguinte:
-
No Google Cloud console, acesse a página BigQuery.
Também é possível encontrar essa página usando a barra de pesquisa.
No editor de consultas, insira a consulta a seguir, que une os dados de registro e a tabela externa no caminho para as entradas do bucket do Cloud Storage:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriSubstitua o seguinte antes de executar a consulta:
- PROJECT_ID: o identificador do projeto.
- LINKED_DATASET_NAME: o nome do conjunto de dados vinculado.
- EXT_TABLE_DATASET_NAME: o nome do conjunto de dados da tabela externa do BigLake.
- EXT_TABLE_NAME: o nome da tabela externa do BigLake.
Opcional: a consulta anterior filtra pelo nome do registro e pelo carimbo de data/hora. Se você também quiser filtrar por um ID de rastreamento específico, adicione a seguinte instrução à cláusula
WHERE:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'Na expressão anterior, substitua TRACE_ID pela string hexadecimal de 16 bytes que contém um ID de rastreamento.
Usar funções do BigQuery ML
Você pode usar funções do BigQuery ML, como
AI.GENERATE
nos comandos e respostas armazenados no seu bucket do Cloud Storage.
Por exemplo, a consulta a seguir une as entradas de registro de conclusão com a tabela externa, simplifica e filtra o resultado da junção. Em seguida, o comando
executa AI.GENERATE para analisar se as entradas contêm uma imagem e gerar
um resumo de cada entrada:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Substitua o seguinte antes de executar a consulta:
- PROJECT_ID: o identificador do projeto.
- LINKED_DATASET_NAME: o nome do conjunto de dados vinculado.
- EXT_TABLE_DATASET_NAME: o nome do conjunto de dados da tabela externa do BigLake.
- EXT_TABLE_NAME: o nome da tabela externa do BigLake.
- CONNECTION_LOCATION: o local do seu CONNECTION_ID.
- CONNECTION_ID: o ID da conexão.
Executar avaliações nos dados de solicitação-resposta com o Colaboratory
É possível avaliar seus comandos e respostas usando o SDK da Vertex AI para Python.
Para executar avaliações usando um notebook do Google Colaboratory, faça o seguinte:
Para conferir um exemplo de notebook, clique em
evaluating_observability_datasets.ipynb.O GitHub vai abrir e mostrar instruções para usar o notebook.
Selecione Abrir no Colab.
O Colaboratory abre e mostra o arquivo
evaluating_observability_datasets.ipynb.Na barra de ferramentas, clique em Copiar para o Drive.
O Colaboratory cria uma cópia do notebook, salva no seu drive e abre a cópia.
Na sua cópia, acesse a seção Definir informações do projeto do Google Cloud e insira o Google Cloud ID do projeto e um local compatível com a Vertex AI. Por exemplo, é possível definir o local como
"us-central1".Acesse a seção Carregar conjuntos de dados da IA generativa do Google Observability e insira valores para as seguintes fontes:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
Para encontrar os valores desses campos, use os rótulos
gen_aianexados às entradas de registro. Por exemplo, para INPUT_SOURCE, o valor é semelhante a este:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'Na expressão anterior, os campos têm os seguintes significados:
- STORAGE_BUCKET: o nome do bucket do Cloud Storage.
- PATH: o caminho para os comandos e respostas.
- REFERENCE: o identificador dos dados no bucket do Cloud Storage.
Para saber como encontrar valores para essas fontes, consulte Encontrar todas as entradas de registro que fazem referência a comandos e respostas.
Na barra de ferramentas, clique em Executar tudo.