
이 문서에서는 에이전트 개발 키트(ADK) 프레임워크로 빌드된 AI 에이전트를 구성하여 멀티모달 프롬프트 및 대답을 수집하고 저장하는 방법을 설명합니다. 또한 저장된 멀티모달 미디어를 보고 분석하고 평가하는 방법도 설명합니다.
Trace 탐색기 페이지를 사용하여 개별 프롬프트 또는 대답을 보거나 전체 대화를 봅니다. 렌더링된 형식 또는 원시 형식으로 미디어를 볼 수 있는 옵션이 있습니다. 자세한 내용은 멀티모달 프롬프트 및 대답 보기를 참조하세요.
BigQuery 서비스를 사용하여 멀티모달 데이터를 분석합니다. 예를 들어
AI.GENERATE와 같은 함수를 사용하여 대화를 요약할 수 있습니다. 자세한 내용은 BigQuery를 사용하여 프롬프트 및 대답 데이터 분석을 참조하세요.Vertex AI SDK를 사용하여 대화를 평가합니다. 예를 들어 Google Colaboratory를 사용하여 감정 분석을 수행할 수 있습니다. 자세한 내용은 Colaboratory를 사용하여 프롬프트 및 대답 데이터에 대한 평가 실행을 참조하세요.
수집할 수 있는 미디어 유형
다음 유형의 미디어를 수집할 수 있습니다.
- 오디오
- 문서
- 이미지
- 일반 텍스트 및 마크다운 형식 텍스트
- 동영상
프롬프트 및 대답에는 인라인 콘텐츠와 링크가 포함될 수 있습니다. 링크는 공개 리소스 또는 Cloud Storage 버킷으로 연결될 수 있습니다.
프롬프트 및 대답이 저장되는 위치
에이전트형 애플리케이션이 프롬프트나 대답을 만들거나 수신하면 ADK가 OpenTelemetry 계측을 호출합니다. 이 계측은 OpenTelemetry 생성형 AI 시맨틱 규칙 버전 1.37.0에 따라 프롬프트 및 대답, 그리고 프롬프트 및 대답에 포함될 수 있는 멀티모달 데이터의 형식의 지정합니다. 더 높은 버전도 지원됩니다.
그런 다음 OpenTelemetry 계측은 다음을 수행합니다.
프롬프트 및 대답 데이터의 객체 식별자를 만든 다음 해당 데이터를 Cloud Storage 버킷에 작성합니다. Cloud Storage 버킷의 항목은 JSON Lines 형식으로 저장됩니다.
로그 및 trace 데이터를 Google Cloud 프로젝트로 전송하며, 여기서 Logging 및 Trace 서비스가 데이터를 수집하고 저장합니다. OpenTelemetry 시맨틱 규칙은 로그 항목 또는 trace 스팬에 연결된 많은 속성과 필드를 결정합니다.
OpenTelemetry 계측은 Cloud Storage 버킷 객체를 만들 때 이러한 객체에 대한 참조가 포함된 로그 항목도 작성합니다. 다음 예시는 객체 참조가 포함된 로그 항목의 일부를 보여줍니다.
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system.instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }로그 항목 예시에서 다음 사항에 유의하세요.
"event.name": "gen_ai.client.inference.operation.details"라벨은 로그 항목에 Cloud Storage 객체에 대한 참조가 포함되어 있음을 나타냅니다.- 키에
gen_ai가 포함된 라벨은 각각 Cloud Storage 버킷의 객체를 참조합니다. - 객체 참조가 포함된 모든 로그 항목은
projects/my-project/logs/gen_ai.client.inference.operation.details라는 동일한 로그에 기록됩니다.
객체 참조가 포함된 로그 항목을 표시하는 방법은 이 문서의 프롬프트 및 대답을 참조하는 모든 로그 항목 찾기 섹션을 참조하세요.
멀티모달 프롬프트 및 대답 수집
ADK는 프롬프트 및 대답을 저장하고 로그 및 trace 데이터를 Google Cloud 프로젝트로 전송하기 위해 OpenTelemetry를 자동으로 호출합니다. 애플리케이션을 수정할 필요가 없습니다. 하지만 Google Cloud 프로젝트와 ADK를 구성해야 합니다.
애플리케이션에서 멀티모달 프롬프트 및 대답을 수집하고 보려면 다음을 수행하세요.
프로젝트를 구성합니다.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Cloud Storage 버킷이 있는지 확인합니다. 필요한 경우 Cloud Storage 버킷을 만듭니다.
다음을 수행하는 것이 좋습니다.
애플리케이션의 로그 데이터를 저장하는 로그 버킷과 동일한 위치에 Cloud Storage 버킷을 만듭니다. 이 구성을 사용하면 BigQuery 쿼리의 효율성이 높아집니다.
Cloud Storage 버킷의 스토리지 클래스가 외부 테이블을 지원하는지 확인합니다. 이 기능을 사용하면 BigQuery로 프롬프트 및 대답을 쿼리할 수 있습니다. 새 Cloud Storage 버킷에 기본 설정을 사용할 계획이 없으면 버킷을 만들기 전에 Cloud Storage 외부 테이블 만들기를 검토하세요.
로그 항목을 저장하는 로그 버킷의 보관 기간과 일치하도록 Cloud Storage 버킷의 보관 기간을 설정합니다. 로그 데이터의 기본 보관 기간은 30일입니다. Cloud Storage 버킷의 보관 기간을 설정하는 방법은 버킷 잠금을 참조하세요.
애플리케이션에서 사용하는 서비스 계정에 Cloud Storage 버킷에 대한
storage.objects.create권한을 부여합니다. 이 권한을 사용하면 애플리케이션이 Cloud Storage 버킷에 객체를 작성할 수 있습니다. 이러한 객체는 에이전트형 애플리케이션이 만들거나 수신하는 프롬프트 및 대답을 저장합니다. 자세한 내용은 버킷에 IAM 정책 설정 및 관리를 참조하세요.
-
ADK를 구성합니다.
다음 종속 항목을 설치하고 업그레이드합니다.
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
otel_to_cloud플래그를 사용 설정하도록 ADK 호출을 업데이트합니다.ADK용 CLI를 사용하는 경우 다음 명령어를 실행합니다.
adk web --otel_to_cloud [other options]그렇지 않으면 FastAPI 앱을 만들 때 플래그를 전달합니다.
get_fast_api_app(..., otel_to_cloud=True)
다음 환경 변수를 설정합니다.
Cloud Storage 객체의 형식을 JSON Lines로 지정하도록 OpenTelemetry에 지시합니다.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'이 콘텐츠를 trace 스팬에 삽입하는 대신 프롬프트 및 대답 데이터를 업로드하도록 OpenTelemetry에 지시합니다. 업로드된 객체에 대한 참조가 로그 항목에 포함됩니다.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'생성형 AI의 최신 시맨틱 규칙을 사용하도록 OpenTelemetry에 지시합니다.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'객체의 경로를 지정합니다.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'이전 표현식에서 STORAGE_BUCKET은 Cloud Storage 버킷의 이름을 나타냅니다. PATH는 객체가 저장된 경로를 나타냅니다.
멀티모달 프롬프트 및 대답 보기
스팬에 표시할 프롬프트 및 대답을 확인하기 위해 Cloud Trace는 로그 데이터를 읽고 Cloud Storage 버킷에 저장된 데이터를 읽는 쿼리를 실행합니다. 쿼리된 리소스에 대한 Identity and Access Management(IAM) 역할에 따라 데이터 반환 여부가 결정됩니다. 경우에 따라 오류 메시지가 표시될 수 있습니다. 예를 들어 Cloud Storage 버킷에서 데이터를 읽을 권한이 없는 경우 해당 데이터에 액세스하려고 하면 권한 거부 오류가 발생합니다.
프롬프트 및 대답은 채팅과 같은 형식으로 표시되며, 이미지와 같은 미디어가 자동으로 렌더링되는지 또는 소스 형식으로 표시되는지 여부를 선택할 수 있습니다. 마찬가지로 전체 대화 기록을 보거나 스팬에 연결된 프롬프트 및 대답만 볼 수 있습니다.
예를 들어 다음 예시에서는 프롬프트 및 대답이 표시되는 방식과 OpenTelemetry: 속성이 요약되는 방식을 보여줍니다.
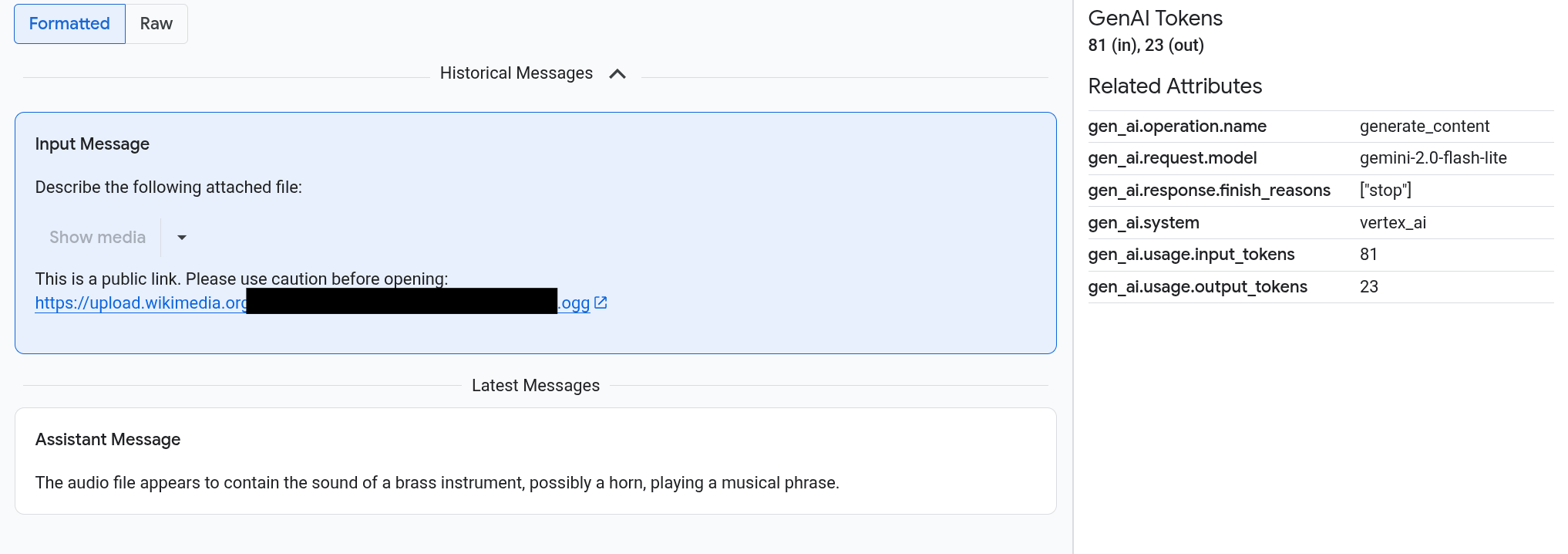
시작하기 전에
멀티모달 프롬프트 및 대답을 보는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 다음 IAM 역할을 부여해 달라고 요청하세요.
-
Cloud Trace 사용자(
roles/cloudtrace.user) -
로그 뷰어(
roles/logging.viewer) -
스토리지 객체 뷰어(
roles/storage.objectViewer)
역할 부여 방법에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
멀티모달 프롬프트 및 대답이 포함된 스팬 찾기
멀티모달 프롬프트 및 대답이 포함된 스팬을 찾으려면 다음을 수행하세요.
-
Google Cloud 콘솔에서 Trace 탐색기 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾을 수도 있습니다.
스팬 필터 창에서 스팬 이름 섹션으로 이동하여
generate_content를 선택합니다.또는
gen_ai.operation.name: generate_content필터를 추가합니다.스팬 목록에서 스팬을 선택합니다.
해당 스팬의 세부정보 페이지가 열립니다. 이 페이지에는 trace 컨텍스트 내의 스팬이 표시됩니다. 스팬 이름에 입력/출력(
 )이라는 라벨이 지정된 버튼이 있으면 사용할 수 있는 생성형 AI 이벤트가 있는 것입니다. 다음 섹션인 멀티모달 프롬프트 및 대답 살펴보기에서는 데이터가 표시되는 방식과 시각화 옵션을 설명합니다.
)이라는 라벨이 지정된 버튼이 있으면 사용할 수 있는 생성형 AI 이벤트가 있는 것입니다. 다음 섹션인 멀티모달 프롬프트 및 대답 살펴보기에서는 데이터가 표시되는 방식과 시각화 옵션을 설명합니다.
멀티모달 프롬프트 및 대답 살펴보기
입력/출력 탭에는 두 섹션이 있습니다.
한 섹션에는 프롬프트 및 대답이 표시되고 다른 섹션에는 OpenTelemetry: 속성이 표시됩니다. 이 탭은 Trace에 전송된 스팬이 OpenTelemetry 생성형 AI 시맨틱 규칙 버전 1.37.0 이상을 따르는 경우에만 표시되며, 이 경우 이름이 gen_ai로 시작하는 메시지가 생성됩니다.
입력/출력 탭에는 채팅과 유사한 형식으로 메시지가 표시됩니다. 탭의 옵션을 사용하여 표시되는 메시지와 형식을 관리합니다.
- 전체 대화를 보려면 이전 메시지 창을 펼칩니다.
- 선택한 스팬의 프롬프트 및 대답만 보려면 최근 메시지 창을 사용합니다.
이미지, 동영상 또는 기타 미디어를 보려면 형식 지정됨을 선택합니다.
시스템에 항상 미디어가 표시되는 것은 아닙니다. 사용자를 보호하기 위해 프롬프트 또는 대답에 공개 이미지, 문서 또는 동영상에 연결되는 링크가 포함되어 있는 경우 해당 미디어를 표시할지 확인해야 합니다. 마찬가지로 프롬프트 또는 대답에 Cloud Storage 버킷에 저장된 미디어가 포함되어 있고 미디어가 매우 큰 경우 미디어를 표시할지 확인해야 합니다.
이미지, 동영상과 같은 일부 미디어는 연결된 메뉴와 함께 표시됩니다. 이 메뉴를 사용하여 이미지를 로컬 드라이브에 다운로드하는 등의 작업을 수행할 수 있습니다. 메뉴 옵션은 미디어 유형에 따라 달라집니다.
메시지를 JSON 형식으로 보려면 원시를 선택합니다. 이 옵션을 선택하면 이미지와 같은 미디어가 렌더링되지 않습니다.
예를 들어 다음 이미지에서는 대화가 원시 형식으로 표시되는 방식을 보여줍니다.
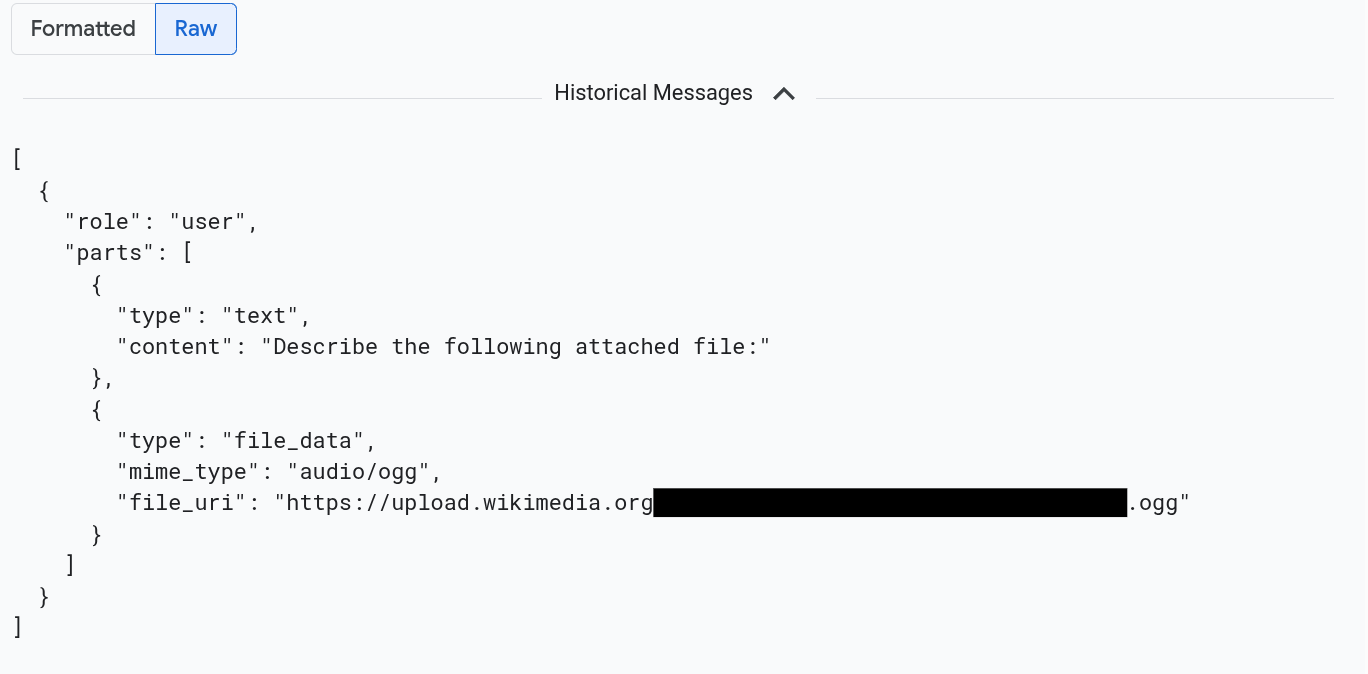
프롬프트 및 대답을 참조하는 모든 로그 항목 찾기
멀티모달 프롬프트 및 대답에 대한 객체 참조가 포함된 로그 항목을 나열하려면 다음을 수행하세요.
-
Google Cloud 콘솔에서 로그 탐색기 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Logging인 결과를 선택합니다.
프로젝트 선택기에서 Google Cloud 프로젝트를 선택합니다.
툴바에서 모든 로그 이름을 펼치고 필터에
gen_ai를 입력한 다음 gen_ai.client.inference.operation.details라는 로그를 선택합니다.이전 단계에서는 로그 탐색기에 다음 쿼리를 추가합니다.
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"원하는 경우 문을 복사하여 로그 탐색기의 쿼리 창에 붙여넣을 수 있지만, 문을 복사하기 전에 PROJECT_ID를 프로젝트 ID로 바꿔야 합니다.
라벨 값으로 로그 데이터를 필터링할 수도 있습니다. 예를 들어 다음 필터를 추가하면 지정된 라벨이 포함된 로그 항목만 표시됩니다.
labels."event.name"="gen_ai.client.inference.operation.details"로그 항목에서 참조하는 프롬프트 및 대답을 보려면 로그 항목에서
 trace 세부정보 보기를 클릭합니다.
trace 세부정보 보기를 클릭합니다.입력/출력 탭의 옵션을 사용하는 방법을 알아보려면 이 문서의 멀티모달 프롬프트 및 대답 살펴보기 섹션을 참조하세요.
BigQuery를 사용하여 프롬프트 및 대답 데이터 분석
BigQuery를 사용하여 Cloud Storage 버킷에 저장된 프롬프트 및 대답을 분석할 수 있습니다. 이 분석을 수행하기 전에 다음 단계를 완료하세요.
- 필요한 API를 사용 설정하고 필요한 IAM 역할이 부여되었는지 확인합니다.
- 로그 버킷에서 연결된 데이터 세트를 만듭니다.
- BigQuery에 Cloud Storage 버킷에서 읽을 수 있는 권한을 부여합니다.
- 외부 테이블을 만듭니다.
외부 테이블을 만든 후 로그 버킷의 데이터를 외부 테이블과 조인하고 조인된 데이터에 대한 분석을 수행합니다. 이 섹션에서는 테이블을 조인하고 특정 필드를 추출하는 방법을 보여줍니다. 또한 BigQuery ML 함수로 조인된 테이블을 분석하는 방법을 보여줍니다.
시작하기 전에
이 섹션에 나열된 IAM 역할은 로그 버킷 업그레이드 및 외부 테이블 만들기와 같은 작업을 수행하는 데 필요합니다. 하지만 구성이 완료되면 쿼리를 실행하는 데 필요한 권한이 줄어듭니다.
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
BigQuery에서 멀티모달 프롬프트 및 대답을 볼 수 있도록 시스템을 구성하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 다음 IAM 역할을 부여해 달라고 요청하세요.
-
로그 구성 작성자(
roles/logging.configWriter) -
스토리지 관리자(
roles/storage.admin) -
BigQuery 연결 관리자(
roles/bigquery.connectionAdmin) -
BigQuery 데이터 뷰어(
roles/bigquery.dataViewer) -
BigQuery Studio 사용자(
roles/bigquery.studioUser)
역할 부여 방법에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
-
로그 구성 작성자(
로그 버킷에서 연결된 데이터 세트 만들기
로그 데이터를 저장하는 로그 버킷이 로그 애널리틱스를 사용하도록 업그레이드되었는지를 확인하려면 다음 명령어를 실행합니다.
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATION명령어를 실행하기 전에 다음을 바꿉니다.
- LOG_BUCKET_ID: 로그 버킷의 ID
- LOCATION: 로그 버킷의 위치
로그 애널리틱스를 위해 로그 버킷이 업그레이드되면
describe명령어의 결과에 다음 문이 포함됩니다.analyticsEnabled: true로그 버킷이 업그레이드되지 않은 경우 다음 명령어를 실행합니다.
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --async업그레이드가 완료되기까지 몇 분 정도 걸릴 수 있습니다.
describe명령어가lifecycleState를ACTIVE로 보고하면 업그레이드가 완료된 것입니다.로그 버킷에서 연결된 데이터 세트를 만들려면 다음 명령어를 실행합니다.
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATION명령어를 실행하기 전에 다음을 바꿉니다.
- LOG_BUCKET_ID: 로그 버킷의 ID
- LOCATION: 로그 버킷의 위치
- LINKED_DATASET_NAME: 만들려는 연결된 데이터 세트의 이름
연결된 데이터 세트를 사용하면 BigQuery에서 로그 버킷에 저장된 로그 데이터를 읽을 수 있습니다. 자세한 내용은 연결된 BigQuery 데이터 세트 쿼리를 참조하세요.
링크가 있는지 확인하려면 다음 명령어를 실행합니다.
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATION성공적으로 실행되면 이전 명령어에 대한 대답에 다음 줄이 포함됩니다.
LINK_ID: LINKED_DATASET_NAME
BigQuery에 Cloud Storage 버킷에서 읽을 수 있는 권한 부여
BigQuery 연결을 만들려면 다음 명령어를 실행합니다.
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID명령어를 실행하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트의 식별자
- CONNECTION_ID: 만들려는 연결의 ID
- CONNECTION_LOCATION: 연결의 위치
명령어가 성공적으로 완료되면 다음과 유사 메시지가 표시됩니다.
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully created연결을 확인합니다.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID이 명령어에 대한 대답에는 연결 ID가 나열되고 서비스 계정이 나열됩니다.
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}BigQuery 연결의 서비스 계정에 Cloud Storage 버킷에 저장된 데이터를 읽을 수 있는 IAM 역할을 부여합니다.
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewer명령어를 실행하기 전에 다음을 바꿉니다.
- STORAGE_BUCKET: Cloud Storage 버킷의 이름
- SERVICE_ACCT_EMAIL: 서비스 계정의 이메일 주소
외부 BigLake 테이블 만들기
BigQuery를 사용하여 BigQuery에 저장되지 않은 데이터를 쿼리하려면 외부 테이블을 만드세요. Cloud Storage 버킷에 프롬프트 및 대답이 저장되므로 BigLake 외부 테이블을 만드세요.
-
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾을 수도 있습니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );명령어를 실행하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트의 식별자
- EXT_TABLE_DATASET_NAME: 만들려는 데이터 세트의 이름
- EXT_TABLE_NAME: 만들려는 외부 BigLake 테이블의 이름
- CONNECTION_LOCATION: CONNECTION_ID의 위치
- CONNECTION_ID: 연결의 ID
- STORAGE_BUCKET: Cloud Storage 버킷의 이름
- PATH: 프롬프트 및 대답의 경로.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH환경 변수가 경로를 지정합니다.
실행을 클릭합니다.
외부 테이블에 대해 자세히 알아보려면 다음을 참조하세요.
외부 테이블을 로그 데이터와 조인
이 섹션에서는 BigQuery에서 멀티모달 프롬프트를 분석하는 방법을 보여줍니다. 이 솔루션은 Cloud Storage 버킷에서 객체를 가져올 수 있도록 외부 BigLake 테이블을 로그 데이터와 조인합니다. 이 예시에서는 입력 메시지의 URI(gen_ai.input.messages)를 기준으로 조인합니다. 출력 메시지의 URI(gen_ai.output.messages) 또는 시스템 안내(gen_ai.system.instructions)를 기준으로 조인할 수도 있습니다.
외부 BigLake 테이블을 로그 데이터와 조인하려면 다음을 수행하세요.
-
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾을 수도 있습니다.
쿼리 편집기에서 로그 데이터와 Cloud Storage 버킷 항목 경로의 외부 테이블을 조인하는 다음 쿼리를 입력합니다.
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri쿼리를 실행하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트의 식별자
- LINKED_DATASET_NAME: 연결된 데이터 세트의 이름
- EXT_TABLE_DATASET_NAME: 외부 BigLake 테이블에 대한 데이터 세트의 이름
- EXT_TABLE_NAME: 외부 BigLake 테이블의 이름
선택사항: 이전 쿼리는 로그 이름과 타임스탬프로 필터링합니다. 특정 trace ID를 기준으로도 필터링하려면
WHERE절에 다음 문을 추가합니다.AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'이전 표현식에서 TRACE_ID를 trace ID가 포함된 16바이트 16진수 문자열로 바꿉니다.
BigQuery ML 함수 사용
Cloud Storage 버킷에 저장된 프롬프트 및 대답에 AI.GENERATE와 같은 BigQuery ML 함수를 사용할 수 있습니다.
예를 들어 다음 쿼리는 완료 로그 항목을 외부 테이블과 조인하고 조인 결과를 평면화하고 필터링합니다. 그런 다음 프롬프트는 AI.GENERATE를 실행하여 항목에 이미지가 포함되어 있는지 여부를 분석하고 각 항목의 요약을 생성합니다.
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
쿼리를 실행하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트의 식별자
- LINKED_DATASET_NAME: 연결된 데이터 세트의 이름
- EXT_TABLE_DATASET_NAME: 외부 BigLake 테이블에 대한 데이터 세트의 이름
- EXT_TABLE_NAME: 외부 BigLake 테이블의 이름
- CONNECTION_LOCATION: CONNECTION_ID의 위치
- CONNECTION_ID: 연결의 ID
Colaboratory를 사용하여 프롬프트 및 대답 데이터에 대한 평가 실행
Vertex AI SDK for Python을 사용하여 프롬프트 및 대답을 평가할 수 있습니다.
Google Colaboratory 노트북을 사용하여 평가를 실행하려면 다음을 수행하세요.
노트북 예시를 보려면
evaluating_observability_datasets.ipynb를 클릭합니다.GitHub가 열리고 노트북 사용 안내가 표시됩니다.
Colab에서 열기를 선택합니다.
Colaboratory가 열리고
evaluating_observability_datasets.ipynb파일이 표시됩니다.툴바에서 Drive에 복사를 클릭합니다.
Colaboratory는 노트북 사본을 만들어 내 드라이브에 저장한 후 사본을 엽니다.
사본에서 Google Cloud 프로젝트 정보 설정 섹션으로 이동하여 Google Cloud 프로젝트 ID와 Vertex AI에서 지원하는 위치를 입력합니다. 예를 들어 위치를
"us-central1"로 설정할 수 있습니다.Google Observability 생성형 AI 데이터 세트 로드 섹션으로 이동하여 다음 소스의 값을 입력합니다.
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
로그 항목에 연결된
gen_ai라벨을 사용하여 이러한 필드의 값을 찾을 수 있습니다. 예를 들어 INPUT_SOURCE의 값은 다음과 비슷합니다.'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'이전 표현식에서 필드의 의미는 다음과 같습니다.
- STORAGE_BUCKET: Cloud Storage 버킷의 이름
- PATH: 프롬프트 및 대답의 경로.
- REFERENCE: Cloud Storage 버킷에 있는 데이터의 식별자
이러한 소스의 값을 찾는 방법은 프롬프트 및 대답을 참조하는 모든 로그 항목 찾기를 참조하세요.
툴바에서 모두 실행을 클릭합니다.