
Questo documento descrive come configurare un agente LangGraph ReAct o un agente AI generativa creato con il framework Agent Development Kit (ADK) per inviare prompt e risposte multimodali al tuo progetto Google Cloud . Descrive inoltre come visualizzare, analizzare e valutare i contenuti multimediali multimodali archiviati:
Utilizza la pagina Esplora tracce per visualizzare singoli prompt o risposte oppure un'intera conversazione. Hai la possibilità di visualizzare i contenuti multimediali in formato renderizzato o non elaborato. Per scoprire di più, consulta Visualizzare prompt e risposte multimodali.
Utilizza i servizi BigQuery per analizzare i dati multimodali. Ad esempio, potresti utilizzare una funzione come
AI.GENERATEper riassumere una conversazione. Per saperne di più, vedi Analizzare i dati delle richieste e delle risposte utilizzando BigQuery.Utilizza l'SDK Vertex AI per valutare una conversazione. Ad esempio, puoi utilizzare Google Colaboratory per eseguire l'analisi del sentiment. Per saperne di più, consulta Eseguire valutazioni sui dati di prompt e risposta con Colaboratory.
Tipi di contenuti multimediali che puoi raccogliere
Puoi raccogliere i seguenti tipi di contenuti multimediali:
- Audio.
- Documenti.
- Google Immagini
- Testo normale e testo formattato in Markdown.
- Video.
I prompt e le risposte possono includere contenuti e link in linea. I link possono indirizzare a risorse pubbliche o a bucket Cloud Storage.
Dove vengono archiviati prompt e risposte
Quando l'applicazione con agenti crea o riceve prompt o risposte, l'SDK utilizzato dall'applicazione richiama la strumentazione OpenTelemetry. Questa strumentazione formatta i prompt e le risposte, nonché i dati multimodali che potrebbero contenere, in base alla versione 1.37.0 delle convenzioni semantiche OpenTelemetry GenAI. Sono supportate anche le versioni successive.
Successivamente, l'instrumentazione OpenTelemetry esegue le seguenti operazioni:
Crea identificatori di oggetti per i prompt e i dati di risposta, quindi scrive questi dati nel tuo bucket Cloud Storage. Le voci nel bucket Cloud Storage vengono salvate nel formato JSON Lines.
Invia i dati di log e traccia al tuo progetto Google Cloud , dove i servizi Logging e Trace li importano e li archiviano. Le convenzioni semantiche di OpenTelemetry determinano molti degli attributi e dei campi allegati alle voci di log o agli intervalli di traccia.
Quando la strumentazione OpenTelemetry crea oggetti bucket Cloud Storage, scrive anche una voce di log che contiene riferimenti a questi oggetti. L'esempio seguente mostra una parte di una voce di log che include riferimenti agli oggetti:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }Nell'esempio di voce di log, nota quanto segue:
- L'etichetta
"event.name": "gen_ai.client.inference.operation.details"indica che la voce di log contiene riferimenti a oggetti Cloud Storage. - Le etichette le cui chiavi includono
gen_aifanno riferimento a un oggetto in un bucket Cloud Storage. - Tutte le voci di log che contengono riferimenti a oggetti vengono scritte nello stesso log, denominato
projects/my-project/logs/gen_ai.client.inference.operation.details.
Per scoprire come mostrare le voci di log che contengono riferimenti a oggetti, consulta la sezione Trovare tutte le voci di log che fanno riferimento a prompt e risposte di questo documento.
- L'etichetta
Raccogliere prompt e risposte multimodali
L'SDK utilizzato dall'applicazione richiama automaticamente OpenTelemetry per archiviare prompt e risposte e per inviare i dati di log e traccia al tuo progetto Google Cloud . Non è necessario modificare l'applicazione. Tuttavia, devi configurare il tuo progettoGoogle Cloud e l'SDK che stai utilizzando.
Per raccogliere e visualizzare prompt e risposte multimodali da un'applicazione:
Configura il progetto:
-
Verifica che la fatturazione sia abilitata per il tuo progetto Google Cloud .
-
Abilita le API Vertex AI, Cloud Storage, Telemetry, Cloud Logging e Cloud Trace.
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre del ruolo IAM Amministratore utilizzo dei servizi (
roles/serviceusage.serviceUsageAdmin), che include l'autorizzazioneserviceusage.services.enable. Scopri come concedere i ruoli. Assicurati di avere un bucket Cloud Storage. Se necessario, crea un bucket Cloud Storage.
Ti consigliamo di procedere come segue:
Crea il bucket Cloud Storage nella stessa località del bucket di log che archivia i dati di log della tua applicazione. Questa configurazione rende più efficienti le query BigQuery.
Assicurati che la classe di archiviazione del bucket Cloud Storage supporti le tabelle esterne. Questa funzionalità ti consente di eseguire query su prompt e risposte con BigQuery. Se non prevedi di utilizzare le impostazioni predefinite per un nuovo bucket Cloud Storage, prima di creare il bucket, consulta Creare tabelle esterne Cloud Storage.
Imposta il periodo di conservazione del bucket Cloud Storage in modo che corrisponda al periodo di conservazione del bucket di log in cui sono archiviate le voci di log. Il periodo di conservazione predefinito per i dati dei log è di 30 giorni. Per scoprire come impostare il periodo di conservazione per il bucket Cloud Storage, consulta Blocco dei bucket.
Concedi al account di servizio utilizzato dalla tua applicazione l'autorizzazione
storage.objects.createsul bucket Cloud Storage. Questa autorizzazione consente alla tua applicazione di scrivere oggetti nel tuo bucket Cloud Storage. Questi oggetti memorizzano i prompt e le risposte che la tua applicazione agentica crea o riceve. Per saperne di più, consulta Imposta e gestisci le policy IAM sui bucket.
-
Configura l'SDK:
Installa ed esegui l'upgrade delle seguenti dipendenze:
ADK
google-adk>=1.16.0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0LangGraph
opentelemetry-instrumentation-vertexai>=2.2b0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0Non tutte le versioni di
fsspecsupportano la raccolta di prompt e risposte. È noto che la versione elencata supporta questa funzionalità. Puoi anche esaminare il campione per determinare se puoi utilizzare una versione successiva.Se utilizzi ADK, aggiorna la chiamata dell'applicazione per attivare il flag
otel_to_cloud:Se utilizzi la CLI per l'ADK, esegui il seguente comando:
adk web --otel_to_cloud [other options]In caso contrario, passa il flag durante la creazione dell'app FastAPI:
get_fast_api_app(..., otel_to_cloud=True)
Imposta le seguenti variabili di ambiente:
Chiedi a OpenTelemetry di formattare gli oggetti Cloud Storage come JSON Lines.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Chiedi a OpenTelemetry di caricare i dati di prompt e risposta anziché incorporare questi contenuti negli intervalli di traccia. I riferimenti agli oggetti caricati sono inclusi in una voce di log.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Chiedi a OpenTelemetry di utilizzare le convenzioni semantiche più recenti per l'AI generativa.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'(Facoltativo) Indica a OpenTelemetry di non allegare i contenuti dei messaggi come attributi negli span.
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT='NO_CONTENT'Non è necessario impostare la variabile di ambiente precedente. Tuttavia, se lo fai, ti consigliamo di impostarlo su
NO_CONTENT. Per informazioni sui valori consentiti, consultagenai/types.py.Specifica il percorso degli oggetti:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'Nell'espressione precedente, STORAGE_BUCKET si riferisce al nome del bucket Cloud Storage. PATH si riferisce al percorso in cui sono archiviati gli oggetti.
Per gli agenti LangGraph ReAct, indica a OpenTelemetry di acquisire automaticamente i dati di log:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'Potrebbe essere necessario impostare altre variabili di ambiente. Ad esempio, se esegui il deployment su Gemini Enterprise Agent Platform, devi impostare anche la seguente variabile di ambiente.
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY='true'
Visualizzare prompt e risposte multimodali
Per determinare le richieste e le risposte da visualizzare per un intervallo, Cloud Trace invia query per leggere i dati di log e i dati archiviati in un bucket Cloud Storage. I tuoi ruoli Identity and Access Management (IAM) nelle risorse interrogate determinano se i dati vengono restituiti. In alcuni casi, potresti visualizzare un messaggio di errore. Ad esempio, se non disponi dell'autorizzazione per leggere i dati da un bucket Cloud Storage, i tentativi di accedere a questi dati generano un errore di autorizzazione negata.
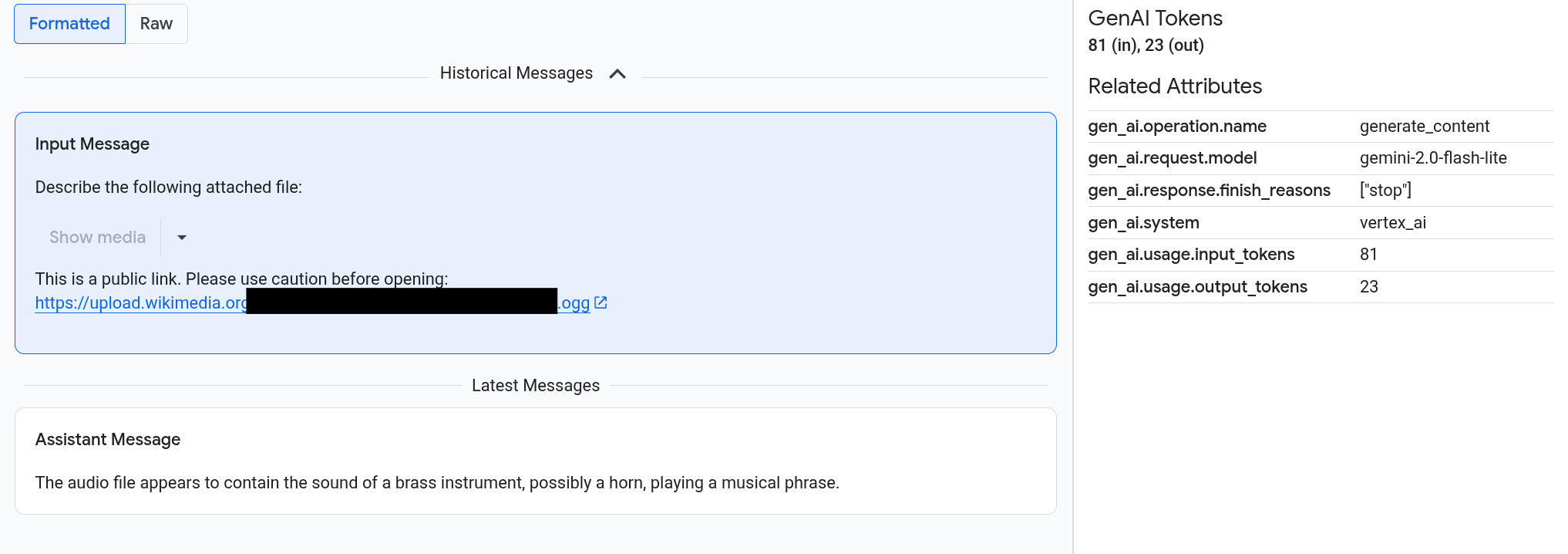
I prompt e le risposte vengono visualizzati in un formato simile a una chat e puoi scegliere se i contenuti multimediali come le immagini vengono visualizzati automaticamente o nel formato di origine. Allo stesso modo, puoi visualizzare l'intera cronologia della conversazione o solo i prompt e le risposte allegati a un intervallo.
Ad esempio, il seguente esempio mostra come vengono visualizzati i prompt e le risposte e come vengono riepilogati gli attributi OpenTelemetry:
Prima di iniziare
Per ottenere le autorizzazioni necessarie per visualizzare prompt e risposte multimodali, chiedi all'amministratore di concederti i seguenti ruoli IAM nel progetto:
- Utente Cloud Trace (
roles/cloudtrace.user) - Visualizzatore log (
roles/logging.viewer) - Storage Object Viewer (
roles/storage.objectViewer)
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Trova gli intervalli che contengono prompt e risposte multimodali
Per trovare gli intervalli che contengono prompt e risposte multimodali:
-
Nella console Google Cloud , vai alla pagina
 Esplora tracce:
Esplora tracce:
Puoi trovare questa pagina anche utilizzando la barra di ricerca.
Nel riquadro Filtro span, vai alla sezione Nome span e seleziona
generate_content.In alternativa, aggiungi il filtro
gen_ai.operation.name: generate_content.Seleziona un intervallo dall'elenco.
Viene visualizzata la pagina Dettagli dello span. Questa pagina mostra lo span, nel contesto della traccia. Se il nome di uno span ha un pulsante con l'etichetta Input/Output,
 , significa che sono disponibili
eventi di AI generativa. La sezione successiva,
Esplora prompt e risposte multimodali, spiega come
vengono presentati i dati e le opzioni di visualizzazione.
, significa che sono disponibili
eventi di AI generativa. La sezione successiva,
Esplora prompt e risposte multimodali, spiega come
vengono presentati i dati e le opzioni di visualizzazione.
Esplorare prompt e risposte multimodali
La scheda Input/Output contiene due sezioni.
Una sezione mostra i prompt e
le risposte, mentre l'altra mostra OpenTelemetry: Attributes. Questa scheda
viene visualizzata solo quando gli span inviati a Trace
seguono le convenzioni semantiche OpenTelemetry GenAI,
versione 1.37.0 o successive,
che generano messaggi i cui nomi iniziano con gen_ai.
La scheda Input/Output mostra i messaggi in un formato simile a una chat. Controlla quali messaggi vengono visualizzati e il loro formato utilizzando le opzioni della scheda:
- Per visualizzare l'intera conversazione, espandi il riquadro Messaggi storici.
- Per visualizzare solo i prompt e le risposte nell'intervallo selezionato, utilizza il riquadro Ultimi messaggi.
Per visualizzare immagini, video o altri contenuti multimediali, seleziona Formattato.
Il sistema non mostra sempre i contenuti multimediali. Per proteggerti, se un prompt o una risposta include un link a un'immagine, un documento o un video pubblici, devi confermare di voler visualizzare i contenuti multimediali. Allo stesso modo, se un prompt o una risposta include contenuti multimediali archiviati nel tuo bucket Cloud Storage e se i contenuti multimediali sono molto grandi, devi confermare di volerli mostrare.
Alcuni contenuti multimediali, come immagini e video, vengono visualizzati con un menu allegato. Puoi utilizzare questo menu per eseguire azioni come scaricare un'immagine su un'unità locale. Le opzioni del menu dipendono dal tipo di media.
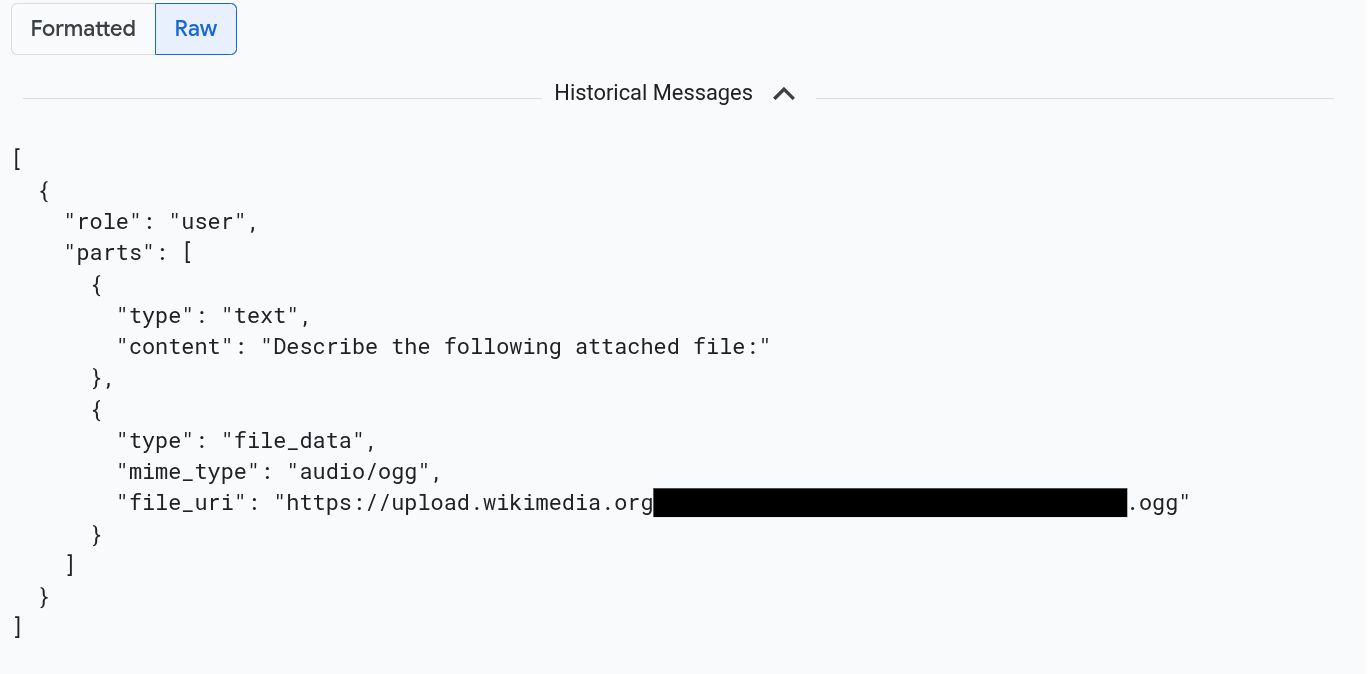
Per visualizzare i messaggi formattati in JSON, seleziona Non elaborato. Con questa selezione, i contenuti multimediali come le immagini non vengono visualizzati.
Ad esempio, l'immagine seguente mostra l'aspetto di una conversazione in formato non elaborato:
Trovare tutte le voci di log che fanno riferimento a prompt e risposte
Per elencare le voci di log che includono riferimenti a oggetti a prompt e risposte multimodali:
-
Nella console Google Cloud , vai alla pagina Esplora log:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Logging.
Nel selettore di progetti, seleziona il tuo progetto Google Cloud .
Nella barra degli strumenti, espandi Tutti i nomi di log, inserisci
gen_ainel filtro e poi seleziona il log denominato gen_ai.client.inference.operation.details.I passaggi precedenti aggiungono la seguente query a Esplora log:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"Se preferisci, puoi copiare l'istruzione e incollarla nel riquadro Query di Esplora log, ma sostituisci PROJECT_ID con l'ID progetto prima di copiare l'istruzione.
Puoi anche filtrare i dati di log in base al valore dell'etichetta. Ad esempio, se aggiungi il seguente filtro, vengono visualizzate solo le voci di log che contengono l'etichetta specificata:
labels."event.name"="gen_ai.client.inference.operation.details"Per visualizzare i prompt e le risposte a cui fa riferimento una voce di log, fai clic su
Visualizza dettagli traccia nella voce di log.Per scoprire come utilizzare le opzioni nella scheda Input/Output, consulta la sezione Esplorare prompt e risposte multimodali di questo documento.
Analizzare i dati delle richieste e delle risposte utilizzando BigQuery
Puoi analizzare i prompt e le risposte archiviati nel bucket Cloud Storage utilizzando BigQuery. Prima di eseguire questa analisi, completa i seguenti passaggi:
- Abilita le API richieste e assicurati di aver ricevuto i ruoli IAM necessari.
- Crea un set di dati collegato nel bucket dei log.
- Concedi a BigQuery l'autorizzazione a leggere dal tuo bucket Cloud Storage.
- Crea una tabella esterna.
Dopo aver creato la tabella esterna, unisci i dati nel bucket dei log alla tabella esterna ed esegui l'analisi sui dati uniti. Questa sezione mostra come unire le tabelle ed estrarre campi specifici. Mostra anche come analizzare la tabella unita con le funzioni BigQuery ML.
Prima di iniziare
I ruoli IAM elencati in questa sezione sono necessari per eseguire azioni come l'upgrade di un bucket dei log e la creazione di una tabella esterna. Tuttavia, una volta completata la configurazione, per eseguire le query sono necessarie meno autorizzazioni.
-
Abilita le API BigQuery e BigQuery Connection.
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre del ruolo IAM Amministratore utilizzo dei servizi (
roles/serviceusage.serviceUsageAdmin), che include l'autorizzazioneserviceusage.services.enable. Scopri come concedere i ruoli. -
Per ottenere le autorizzazioni necessarie per configurare il sistema in modo da poter visualizzare prompt e risposte multimodali in BigQuery, chiedi all'amministratore di concederti i seguenti ruoli IAM sul progetto:
- Logs Configuration Writer (
roles/logging.configWriter) - Storage Admin (
roles/storage.admin) - Amministratore connessioni BigQuery (
roles/bigquery.connectionAdmin) - Visualizzatore dati BigQuery (
roles/bigquery.dataViewer) - Utente BigQuery Studio (
roles/bigquery.studioUser)
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
- Logs Configuration Writer (
Crea un set di dati collegato nel bucket dei log
Per determinare se è stato eseguito l'upgrade del bucket di log che archivia i dati di log per Observability Analytics, esegui questo comando:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONSostituisci quanto segue prima di eseguire il comando:
- LOG_BUCKET_ID: l'ID del bucket di log.
- LOCATION: la posizione del bucket dei log.
Quando un bucket di log viene aggiornato per Observability Analytics, i risultati del comando
describeincludono la seguente istruzione:analyticsEnabled: trueSe il bucket di log non è stato sottoposto ad upgrade, esegui questo comando:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncIl completamento dell'upgrade può richiedere diversi minuti. Quando il comando
describesegnala chelifecycleStateèACTIVE, l'upgrade è completato.Per creare un set di dati collegato nel bucket dei log, esegui questo comando:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONSostituisci quanto segue prima di eseguire il comando:
- LOG_BUCKET_ID: l'ID del bucket di log.
- LOCATION: la posizione del bucket dei log.
- LINKED_DATASET_NAME: il nome del set di dati collegato da creare.
Il set di dati collegato consente a BigQuery di leggere i dati di log archiviati nel bucket dei log. Per scoprire di più, consulta Eseguire una query su un set di dati BigQuery collegato.
Per verificare che il link esista, esegui questo comando:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONIn caso di esito positivo, la risposta al comando precedente include la seguente riga:
LINK_ID: LINKED_DATASET_NAME
Concedere a BigQuery l'autorizzazione a leggere dal bucket Cloud Storage
Per creare una connessione BigQuery, esegui questo comando:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDSostituisci quanto segue prima di eseguire il comando:
- PROJECT_ID: l'identificatore del progetto.
- CONNECTION_ID: l'ID della connessione da creare.
- CONNECTION_LOCATION: la posizione della connessione.
Al termine del comando, viene visualizzato un messaggio simile al seguente:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdVerifica la connessione.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDLa risposta a questo comando elenca l'ID connessione e un account di servizio:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Concedi al account di servizio per la connessione BigQuery un ruolo IAM che gli consenta di leggere i dati archiviati nel bucket Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerSostituisci quanto segue prima di eseguire il comando:
- STORAGE_BUCKET: il nome del bucket Cloud Storage.
- SERVICE_ACCT_EMAIL: l'indirizzo email del account di servizio.
Crea una tabella BigLake esterna
Per utilizzare BigQuery per eseguire query sui dati che BigQuery non archivia, crea una tabella esterna. Poiché un bucket Cloud Storage memorizza i prompt e le risposte, crea una tabella esterna BigLake.
-
Nella console Google Cloud , vai alla pagina BigQuery.
Puoi trovare questa pagina anche utilizzando la barra di ricerca.
Nell'editor di query, inserisci la seguente istruzione:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Sostituisci quanto segue prima di eseguire il comando:
- PROJECT_ID: l'identificatore del progetto.
- EXT_TABLE_DATASET_NAME: il nome del set di dati da creare.
- EXT_TABLE_NAME: il nome della tabella BigLake esterna da creare.
- CONNECTION_LOCATION: la posizione del tuo CONNECTION_ID.
- CONNECTION_ID: l'ID della connessione.
- STORAGE_BUCKET: il nome del bucket Cloud Storage.
- PATH: il percorso dei prompt e delle risposte. La variabile di ambiente
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHspecifica il percorso.
Fai clic su Esegui.
Per saperne di più sulle tabelle esterne, consulta quanto segue:
Unire la tabella esterna ai dati di log
Questa sezione illustra come analizzare i prompt multimodali in
BigQuery. La soluzione si basa sull'unione della tabella BigLake esterna con i dati di log, il che ti consente di recuperare gli oggetti dal bucket Cloud Storage. L'esempio esegue il join
sull'URI dei messaggi di input, gen_ai.input.messages. Puoi anche unirti all'URI per i messaggi di output, gen_ai.output.messages, o alle istruzioni di sistema, gen_ai.system_instructions.
Per unire la tabella BigLake esterna ai dati di log, procedi nel seguente modo:
-
Nella console Google Cloud , vai alla pagina BigQuery.
Puoi trovare questa pagina anche utilizzando la barra di ricerca.
Nell'editor di query, inserisci la seguente query, che unisce i dati di log e la tabella esterna nel percorso delle voci del bucket Cloud Storage:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriSostituisci quanto segue prima di eseguire la query:
- PROJECT_ID: l'identificatore del progetto.
- LINKED_DATASET_NAME: il nome del set di dati collegato.
- EXT_TABLE_DATASET_NAME: il nome del set di dati per la tabella BigLake esterna.
- EXT_TABLE_NAME: il nome della tabella BigLake esterna.
(Facoltativo) La query precedente filtra in base al nome del log e al timestamp. Se vuoi filtrare anche in base a un ID traccia specifico, aggiungi la seguente istruzione alla clausola
WHERE:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'Nell'espressione precedente, sostituisci TRACE_ID con la stringa esadecimale di 16 byte che contiene un ID traccia.
Utilizzare le funzioni BigQuery ML
Puoi utilizzare le funzioni BigQuery ML come
AI.GENERATE
sui prompt e sulle risposte archiviati nel bucket Cloud Storage.
Ad esempio, la seguente query unisce le voci di log di completamento alla
tabella esterna, appiattisce e filtra il risultato dell'unione. Successivamente, il prompt
esegue AI.GENERATE per analizzare se le voci contengono un'immagine e per generare
un riepilogo di ogni voce:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Sostituisci quanto segue prima di eseguire la query:
- PROJECT_ID: l'identificatore del progetto.
- LINKED_DATASET_NAME: il nome del set di dati collegato.
- EXT_TABLE_DATASET_NAME: il nome del set di dati per la tabella BigLake esterna.
- EXT_TABLE_NAME: il nome della tabella BigLake esterna.
- CONNECTION_LOCATION: la posizione del tuo CONNECTION_ID.
- CONNECTION_ID: l'ID della connessione.
Esegui valutazioni sui dati di prompt e risposta con Colaboratory
Puoi valutare prompt e risposte utilizzando l'SDK Vertex AI Python.
Per eseguire le valutazioni utilizzando un notebook Google Colaboratory:
Per visualizzare un notebook di esempio, fai clic su
evaluating_observability_datasets.ipynb.Si apre GitHub e vengono visualizzate le istruzioni per l'utilizzo del notebook.
Seleziona Apri in Colab.
Si apre Colaboratory e viene visualizzato il file
evaluating_observability_datasets.ipynb.Nella barra degli strumenti, fai clic su Copia su Drive.
Colaboratory crea una copia del notebook, la salva su Drive e poi la apre.
Nella tua copia, vai alla sezione intitolata Imposta le informazioni del progetto Google Cloud e inserisci il tuo Google Cloud ID progetto e una posizione supportata da Vertex AI. Ad esempio, potresti impostare la posizione su
"us-central1".Vai alla sezione Carica i set di dati di Google Observability Gen AI e inserisci i valori per le seguenti origini:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
Puoi trovare i valori di questi campi utilizzando le etichette
gen_aiassociate alle voci di log. Ad esempio, per INPUT_SOURCE, il valore è simile al seguente:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'Nell'espressione precedente, i campi hanno i seguenti significati:
- STORAGE_BUCKET: il nome del bucket Cloud Storage.
- PATH: il percorso dei prompt e delle risposte.
- REFERENCE: l'identificatore dei dati nel tuo bucket Cloud Storage.
Per informazioni su come trovare i valori per queste origini, vedi Trovare tutte le voci di log che fanno riferimento a prompt e risposte.
Nella barra degli strumenti, fai clic su Esegui tutto.