
Ce document explique comment configurer un agent LangGraph ReAct ou un agent d'IA générative créé avec le framework Agent Development Kit (ADK) pour envoyer des requêtes et des réponses multimodales à votre projet Google Cloud . Il explique également comment afficher, analyser et évaluer les contenus multimédias multimodaux stockés :
Utilisez la page Explorateur Trace pour afficher des requêtes ou des réponses individuelles, ou une conversation entière. Vous pouvez afficher le contenu multimédia au format rendu ou brut. Pour en savoir plus, consultez Afficher les requêtes et les réponses multimodales.
Utilisez les services BigQuery pour analyser les données multimodales. Par exemple, vous pouvez utiliser une fonction telle que
AI.GENERATEpour résumer une conversation. Pour en savoir plus, consultez Analyser les données des requêtes et des réponses à l'aide de BigQuery.Utilisez le SDK Vertex AI pour évaluer une conversation. Par exemple, vous pouvez utiliser Google Colaboratory pour effectuer une analyse des sentiments. Pour en savoir plus, consultez Exécuter des évaluations sur les données d'invites et de réponses avec Colaboratory.
Lorsque vous collectez des données sur les requêtes et les réponses multimodales, le contenu complet des requêtes et des réponses de vos utilisateurs finaux est collecté. Ces données d'invites et de réponses sont stockées dans un bucket Cloud Storage. Pour savoir comment gérer le bucket de stockage, y compris contrôler l'accès ou supprimer des données, consultez la documentation Cloud Storage.
Vous pouvez utiliser des produits tels que Model Armor et Sensitive Data Protection pour gérer les données sensibles qui peuvent se trouver dans les requêtes et les réponses.
Types de contenus multimédias que vous pouvez collecter
Vous pouvez collecter les types de contenus multimédias suivants :
- Audio.
- Documents.
- Images
- Texte brut et texte au format Markdown.
- Vidéo.
Les requêtes et les réponses peuvent inclure du contenu intégré et des liens. Les liens peuvent rediriger vers des ressources publiques ou des buckets Cloud Storage.
Emplacement de stockage des requêtes et des réponses
Lorsque votre application agentique crée ou reçoit des requêtes ou des réponses, le SDK utilisé par votre application appelle l'instrumentation OpenTelemetry. Cette instrumentation met en forme les requêtes et les réponses, ainsi que les données multimodales qu'elles peuvent contenir, conformément à la version 1.37.0 des conventions sémantiques OpenTelemetry GenAI. Les versions ultérieures sont également acceptées.
Ensuite, l'instrumentation OpenTelemetry effectue les opérations suivantes :
Il crée des identifiants d'objet pour les données de requêtes et de réponses, puis écrit ces données dans votre bucket Cloud Storage. Les entrées de votre bucket Cloud Storage sont enregistrées au format JSON Lines.
Il envoie les données de journaux et de trace à votre projet Google Cloud , où les services Logging et Trace ingèrent et stockent les données. Les conventions sémantiques OpenTelemetry déterminent de nombreux attributs et champs associés à vos entrées de journal ou à vos spans de trace.
Lorsque l'instrumentation OpenTelemetry crée des objets de bucket Cloud Storage, elle écrit également une entrée de journal contenant des références à ces objets. L'exemple suivant montre une partie d'une entrée de journal qui inclut des références d'objet :
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }Dans l'exemple d'entrée de journal, notez les points suivants :
- Le libellé
"event.name": "gen_ai.client.inference.operation.details"indique que l'entrée de journal contient des références à des objets Cloud Storage. - Les libellés dont les clés incluent
gen_aifont chacun référence à un objet dans un bucket Cloud Storage. - Toutes les entrées de journal contenant des références d'objet sont écrites dans le même journal, nommé
projects/my-project/logs/gen_ai.client.inference.operation.details.
Pour savoir comment afficher les entrées de journal contenant des références d'objet, consultez la section Rechercher toutes les entrées de journal qui font référence à des requêtes et des réponses de ce document.
- Le libellé
Collecter les requêtes et les réponses multimodales
Le SDK utilisé par votre application appelle automatiquement OpenTelemetry pour stocker les requêtes et les réponses, et pour envoyer les données de journaux et de trace à votre projet Google Cloud . Vous n'avez pas besoin de modifier votre application. Toutefois, vous devez configurer votre projetGoogle Cloud et le SDK que vous utilisez.
Pour collecter et afficher les requêtes et réponses multimodales d'une application, procédez comme suit :
Configurez votre projet :
-
Vérifiez que la facturation est activée pour votre projet Google Cloud .
-
Activez les API Vertex AI, Cloud Storage, Telemetry, Cloud Logging et Cloud Trace.
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (
roles/serviceusage.serviceUsageAdmin), qui contient l'autorisationserviceusage.services.enable. Découvrez comment attribuer des rôles. Assurez-vous de disposer d'un bucket Cloud Storage. Si nécessaire, créez un bucket Cloud Storage.
Nous vous recommandons d'effectuer les opérations suivantes :
Créez votre bucket Cloud Storage au même emplacement que le bucket de journaux qui stocke les données de journaux de votre application. Cette configuration rend les requêtes BigQuery plus efficaces.
Assurez-vous que la classe de stockage de votre bucket Cloud Storage est compatible avec les tables externes. Cette fonctionnalité vous permet d'interroger les requêtes et les réponses avec BigQuery. Si vous ne prévoyez pas d'utiliser les paramètres par défaut pour un nouveau bucket Cloud Storage, consultez Créer des tables externes Cloud Storage avant de créer le bucket.
Définissez la période de conservation de votre bucket Cloud Storage pour qu'elle corresponde à celle du bucket de journaux qui stocke vos entrées de journal. La période de conservation par défaut des données de journaux est de 30 jours. Pour savoir comment définir la période de conservation de votre bucket Cloud Storage, consultez Verrouillage de bucket.
Accordez au compte de service utilisé par votre application l'autorisation
storage.objects.createsur votre bucket Cloud Storage. Cette autorisation permet à votre application d'écrire des objets dans votre bucket Cloud Storage. Ces objets stockent les requêtes et les réponses que votre application agentique crée ou reçoit. Pour en savoir plus, consultez Définir et gérer des stratégies IAM sur des buckets.
-
Configurez le SDK :
Installez et mettez à niveau les dépendances suivantes :
ADK
google-adk>=1.16.0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0LangGraph
opentelemetry-instrumentation-vertexai>=2.2b0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0Toutes les versions de
fsspecne sont pas compatibles avec la collecte des requêtes et des réponses. La version listée est connue pour être compatible avec cette fonctionnalité. Vous pouvez également examiner l'échantillon pour déterminer si vous pouvez utiliser une version ultérieure.Si vous utilisez ADK, mettez à jour l'appel de votre application pour activer l'indicateur
otel_to_cloud:Si vous utilisez la CLI pour ADK, exécutez la commande suivante :
adk web --otel_to_cloud [other options]Sinon, transmettez le flag lors de la création de l'application FastAPI :
get_fast_api_app(..., otel_to_cloud=True)
Définissez les variables d'environnement suivantes :
Indiquez à OpenTelemetry de mettre en forme les objets Cloud Storage en tant que fichiers JSON Lines.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Indiquez à OpenTelemetry d'importer les données de requête et de réponse au lieu d'intégrer ce contenu dans les étendues de trace. Les références aux objets importés sont incluses dans une entrée de journal.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Indiquez à OpenTelemetry d'utiliser les conventions sémantiques les plus récentes pour l'IA générative.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'Facultatif : Demandez à OpenTelemetry de ne pas joindre le contenu du message en tant qu'attributs sur les spans.
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT='NO_CONTENT'Vous n'avez pas besoin de définir la variable d'environnement précédente. Toutefois, si vous le faites, nous vous recommandons de le définir sur
NO_CONTENT. Pour en savoir plus sur les valeurs autorisées, consultezgenai/types.py.Spécifiez le chemin d'accès aux objets :
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'Dans l'expression précédente, STORAGE_BUCKET fait référence au nom du bucket Cloud Storage. PATH correspond au chemin d'accès où les objets sont stockés.
Pour les agents LangGraph ReAct, demandez à OpenTelemetry de capturer automatiquement les données de journalisation :
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'Vous devrez peut-être définir d'autres variables d'environnement. Par exemple, si vous déployez sur Gemini Enterprise Agent Platform, vous devez également définir la variable d'environnement suivante.
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY='true'
Afficher les requêtes et les réponses multimodales
Pour déterminer les invites et les réponses à afficher pour une étendue, Cloud Trace envoie des requêtes pour lire les données de journaux et les données stockées dans un bucket Cloud Storage. Vos rôles Identity and Access Management (IAM) sur les ressources interrogées déterminent si des données sont renvoyées. Dans certains cas, un message d'erreur peut s'afficher. Par exemple, si vous n'êtes pas autorisé à lire les données d'un bucket Cloud Storage, toute tentative d'accès à ces données génère une erreur de refus d'autorisation.
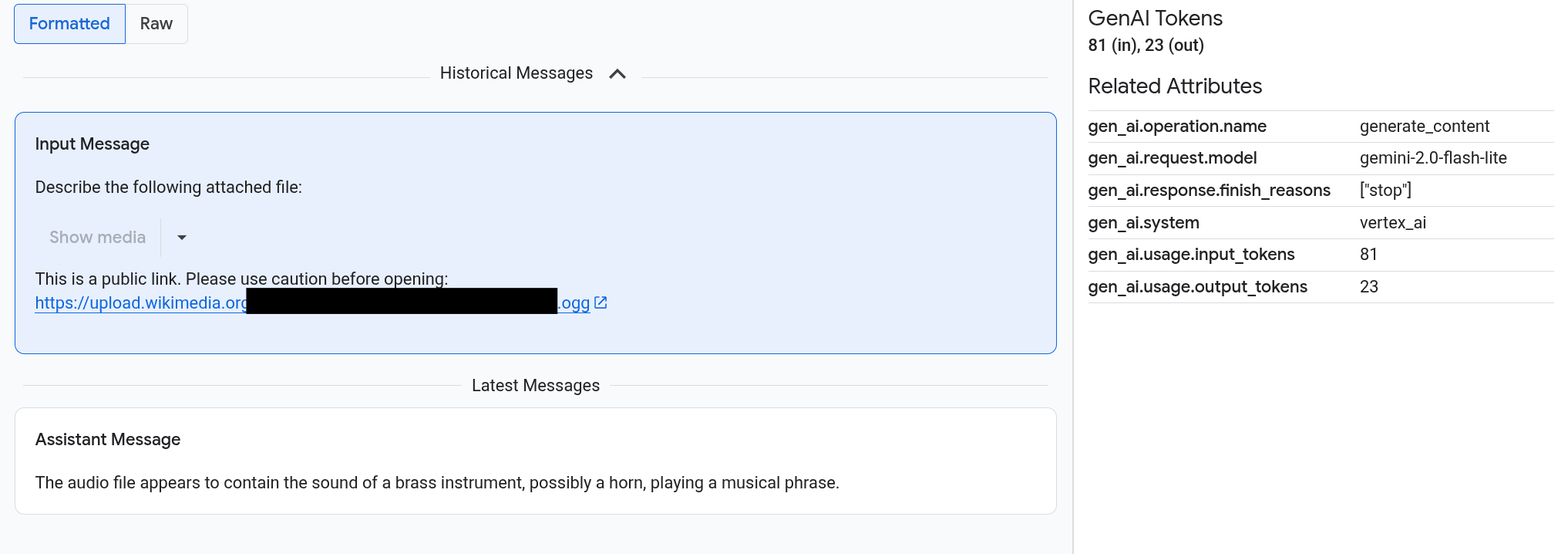
Les requêtes et les réponses s'affichent dans un format de type chat. Vous pouvez choisir si les éléments multimédias tels que les images s'affichent automatiquement ou au format source. De même, vous pouvez afficher l'intégralité de l'historique des conversations ou uniquement les requêtes et les réponses associées à une étendue.
Par exemple, l'exemple suivant montre comment les requêtes et les réponses s'affichent, et comment les attributs OpenTelemetry sont résumés :
Avant de commencer
Pour obtenir les autorisations nécessaires pour afficher les requêtes et les réponses multimodales, demandez à votre administrateur de vous accorder les rôles IAM suivants sur le projet :
-
Utilisateur Cloud Trace (
roles/cloudtrace.user) - Lecteur de journaux (
roles/logging.viewer) - Lecteur des objets Storage (
roles/storage.objectViewer)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Rechercher des étendues contenant des requêtes et des réponses multimodales
Pour trouver les étendues contenant des requêtes et des réponses multimodales, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page
 Explorateur Trace :
Explorateur Trace :
Vous pouvez également accéder à cette page à l'aide de la barre de recherche.
Dans le volet Filtre de segments, accédez à la section Nom du segment et sélectionnez
generate_content.Vous pouvez également ajouter le filtre
gen_ai.operation.name: generate_content.Sélectionnez un segment dans la liste des segments.
La page Détails du segment s'ouvre. Cette page affiche le span dans le contexte de la trace. Si le nom d'une étendue comporte un bouton intitulé Entrées/Sorties,
 , cela signifie que des événements d'IA générative sont disponibles. La section suivante, Explorer les requêtes et les réponses multimodales, explique comment les données sont présentées et les options de visualisation.
, cela signifie que des événements d'IA générative sont disponibles. La section suivante, Explorer les requêtes et les réponses multimodales, explique comment les données sont présentées et les options de visualisation.
Explorer les requêtes et les réponses multimodales
L'onglet Entrées/Sorties contient deux sections.
Une section affiche les requêtes et les réponses, et l'autre affiche OpenTelemetry : Attributs. Cet onglet ne s'affiche que lorsque les spans envoyés à Trace suivent les conventions sémantiques OpenTelemetry pour l'IA générative, version 1.37.0 ou ultérieure, ce qui génère des messages dont le nom commence par gen_ai.
L'onglet Entrées/Sorties affiche les messages dans un format de type chat. Vous pouvez contrôler les messages qui s'affichent et leur format à l'aide des options de l'onglet :
- Pour afficher l'intégralité de la conversation, développez le volet Messages historiques.
- Pour n'afficher que les requêtes et les réponses dans la plage sélectionnée, utilisez le volet Derniers messages.
Pour afficher des images, des vidéos ou d'autres contenus multimédias, sélectionnez Formaté.
Le système n'affiche pas toujours les contenus multimédias. Pour vous protéger, si une requête ou une réponse inclut un lien vers une image, un document ou une vidéo publics, vous devez confirmer que vous souhaitez afficher le contenu multimédia. De même, si une requête ou une réponse inclut des éléments multimédias stockés dans votre bucket Cloud Storage et que ces éléments sont très volumineux, vous devez confirmer que vous souhaitez les afficher.
Certains contenus multimédias, comme les images et les vidéos, s'affichent avec un menu associé. Vous pouvez utiliser ce menu pour effectuer des actions telles que le téléchargement d'une image sur un lecteur local. Les options de menu dépendent du type de contenu multimédia.
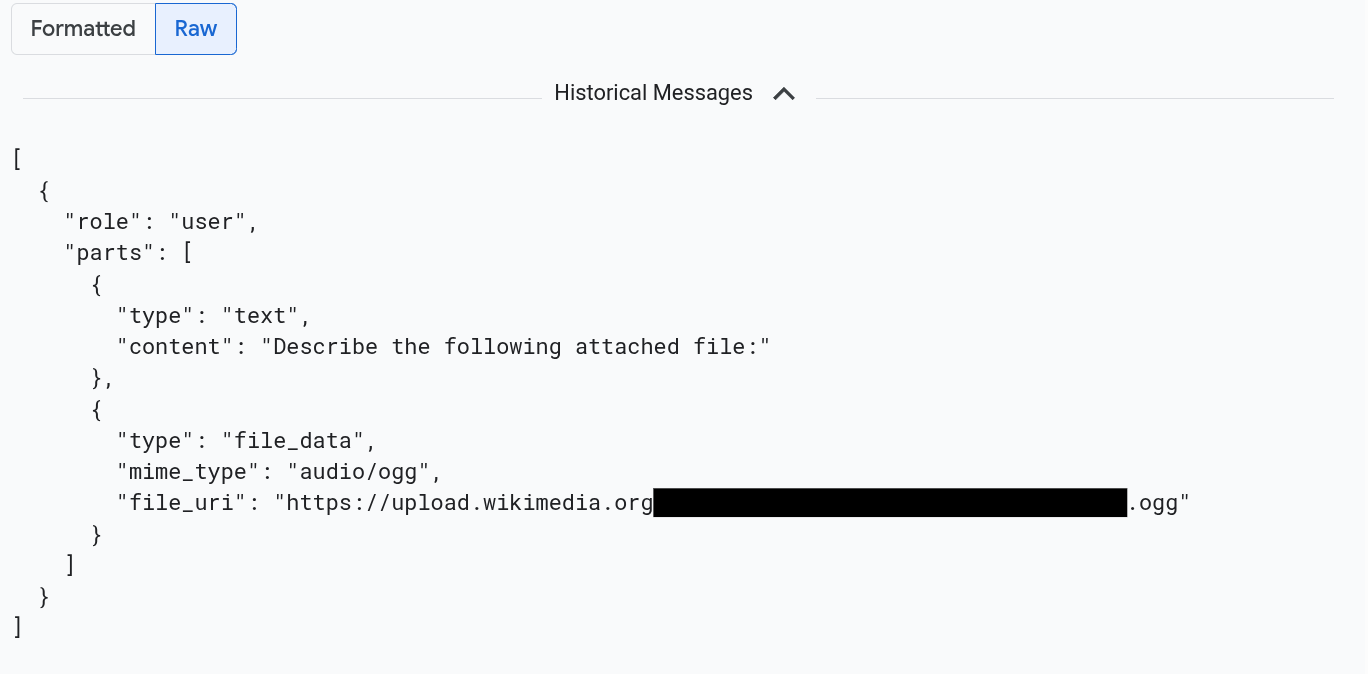
Pour afficher les messages au format JSON, sélectionnez Brut. Avec cette sélection, les éléments multimédias tels que les images ne sont pas affichés.
Par exemple, l'image suivante montre à quoi ressemble une conversation au format brut :
Rechercher toutes les entrées de journal qui font référence aux requêtes et aux réponses
Pour lister les entrées de journal qui incluent des références d'objet aux requêtes et réponses multimodales, procédez comme suit :
-
Dans la console Google Cloud , accédez à la pageExplorateur de journaux :
Accéder à l'explorateur de journaux
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Logging.
Dans le sélecteur de projet, sélectionnez votre projet Google Cloud .
Dans la barre d'outils, développez Tous les noms de journaux, saisissez
gen_aidans le filtre, puis sélectionnez le journal nommé gen_ai.client.inference.operation.details.Les étapes précédentes ajoutent la requête suivante à l'explorateur de journaux :
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"Si vous préférez, vous pouvez copier l'instruction et la coller dans le volet Requête de l'explorateur de journaux, mais remplacez PROJECT_ID par l'ID de votre projet avant de copier l'instruction.
Vous pouvez également filtrer les données de journaux par valeur de libellé. Par exemple, si vous ajoutez le filtre suivant, seules les entrées de journal contenant le libellé spécifié s'affichent :
labels."event.name"="gen_ai.client.inference.operation.details"Pour afficher les requêtes et les réponses auxquelles fait référence une entrée de journal, cliquez sur
Afficher les détails des traces dans l'entrée de journal.Pour savoir comment utiliser les options de l'onglet Entrées/Sorties, consultez la section Explorer les requêtes et les réponses multimodales de ce document.
Analyser les données des requêtes et des réponses à l'aide de BigQuery
Vous pouvez analyser les requêtes et les réponses stockées dans votre bucket Cloud Storage à l'aide de BigQuery. Avant d'effectuer cette analyse, procédez comme suit :
- Activez les API requises et assurez-vous de disposer des rôles IAM nécessaires.
- Créez un ensemble de données associé dans votre bucket de journaux.
- Autorisez BigQuery à lire les données de votre bucket Cloud Storage.
- Créez une table externe.
Une fois la table externe créée, vous joignez les données de votre bucket de journaux à votre table externe, puis vous analysez les données jointes. Cette section explique comment joindre vos tables et extraire des champs spécifiques. Il explique également comment analyser la table jointe avec les fonctions BigQuery ML.
Avant de commencer
Les rôles IAM listés dans cette section sont requis pour effectuer des actions telles que la mise à niveau d'un bucket de journaux et la création d'une table externe. Toutefois, une fois la configuration terminée, moins d'autorisations sont requises pour exécuter des requêtes.
-
Activez les API BigQuery et BigQuery Connection.
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (
roles/serviceusage.serviceUsageAdmin), qui contient l'autorisationserviceusage.services.enable. Découvrez comment attribuer des rôles. -
Pour obtenir les autorisations nécessaires pour configurer le système afin de pouvoir afficher les requêtes et les réponses multimodales dans BigQuery, demandez à votre administrateur de vous accorder les rôles IAM suivants sur le projet :
- Rédacteur de configuration des journaux (
roles/logging.configWriter) - Administrateur de l'espace de stockage (
roles/storage.admin) - Administrateur de connexion BigQuery (
roles/bigquery.connectionAdmin) - Lecteur de données BigQuery (
roles/bigquery.dataViewer) - Utilisateur BigQuery Studio (
roles/bigquery.studioUser)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
- Rédacteur de configuration des journaux (
Créer un ensemble de données associé sur votre bucket de journaux
Pour déterminer si le bucket de journaux qui stocke vos données de journaux est mis à niveau pour l'analyse de l'observabilité, exécutez la commande suivante :
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONAvant d'exécuter la commande, remplacez les éléments suivants :
- LOG_BUCKET_ID : ID du bucket de journaux.
- LOCATION : emplacement du bucket de journaux.
Lorsqu'un bucket de journaux est mis à niveau pour Observability Analytics, les résultats de la commande
describeincluent l'instruction suivante :analyticsEnabled: trueSi votre bucket de journaux n'est pas mis à niveau, exécutez la commande suivante :
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncLa mise à niveau peut prendre plusieurs minutes. Une fois la mise à niveau terminée, la commande
describeindique quelifecycleStateestACTIVE.Pour créer un ensemble de données associé dans votre bucket de journaux, exécutez la commande suivante :
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONAvant d'exécuter la commande, remplacez les éléments suivants :
- LOG_BUCKET_ID : ID du bucket de journaux.
- LOCATION : emplacement du bucket de journaux.
- LINKED_DATASET_NAME : nom de l'ensemble de données associé à créer.
L'ensemble de données associé permet à BigQuery de lire les données de journaux stockées dans votre bucket de journaux. Pour en savoir plus, consultez Interroger un ensemble de données BigQuery associé.
Pour vérifier que le lien existe, exécutez la commande suivante :
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONEn cas de réussite, la réponse à la commande précédente inclut la ligne suivante :
LINK_ID: LINKED_DATASET_NAME
Autoriser BigQuery à lire les données de votre bucket Cloud Storage
Pour créer une connexion BigQuery, exécutez la commande suivante :
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDAvant d'exécuter la commande, remplacez les éléments suivants :
- PROJECT_ID : identifiant du projet.
- CONNECTION_ID : ID de la connexion à créer.
- CONNECTION_LOCATION : emplacement de la connexion
Une fois la commande exécutée, un message semblable à celui-ci s'affiche :
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdVérifiez la connexion.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDLa réponse à cette commande liste l'ID de connexion et un compte de service :
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Attribuez au compte de service de la connexion BigQuery un rôle IAM lui permettant de lire les données stockées dans votre bucket Cloud Storage :
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerAvant d'exécuter la commande, remplacez les éléments suivants :
- STORAGE_BUCKET : nom du bucket Cloud Storage.
- SERVICE_ACCT_EMAIL : adresse e-mail de votre compte de service.
Créer une table externe BigLake
Pour utiliser BigQuery afin d'interroger des données que BigQuery ne stocke pas, créez une table externe. Étant donné qu'un bucket Cloud Storage stocke les requêtes et les réponses, créez une table externe BigLake.
-
Dans la console Google Cloud , accédez à la page BigQuery.
Vous pouvez également accéder à cette page à l'aide de la barre de recherche.
Dans l'éditeur de requête, saisissez l'instruction suivante :
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Avant d'exécuter la commande, remplacez les éléments suivants :
- PROJECT_ID : identifiant du projet.
- EXT_TABLE_DATASET_NAME : nom de l'ensemble de données à créer.
- EXT_TABLE_NAME : nom de la table BigLake externe à créer.
- CONNECTION_LOCATION : emplacement de votre CONNECTION_ID.
- CONNECTION_ID : ID de la connexion.
- STORAGE_BUCKET : nom du bucket Cloud Storage.
- PATH : chemin d'accès aux requêtes et aux réponses. La variable d'environnement
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHspécifie le chemin d'accès.
Cliquez sur Exécuter.
Pour en savoir plus sur les tables externes, consultez les ressources suivantes :
Associer votre table externe à vos données de journaux
Cette section explique comment analyser les requêtes multimodales dans BigQuery. La solution consiste à joindre votre table BigLake externe à vos données de journaux, ce qui vous permet de récupérer des objets de votre bucket Cloud Storage. L'exemple effectue une jointure sur l'URI des messages d'entrée, gen_ai.input.messages. Vous pouvez également joindre l'URI des messages de sortie, gen_ai.output.messages, ou les instructions système, gen_ai.system_instructions.
Pour joindre votre table BigLake externe à vos données de journaux, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page BigQuery.
Vous pouvez également accéder à cette page à l'aide de la barre de recherche.
Dans l'éditeur de requête, saisissez la requête suivante, qui joint vos données de journaux et votre table externe sur le chemin d'accès aux entrées du bucket Cloud Storage :
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriRemplacez les éléments suivants avant d'exécuter la requête :
- PROJECT_ID : identifiant du projet.
- LINKED_DATASET_NAME : nom de l'ensemble de données associé.
- EXT_TABLE_DATASET_NAME : nom de l'ensemble de données pour la table BigLake externe.
- EXT_TABLE_NAME : nom de la table BigLake externe.
Facultatif : La requête précédente filtre par nom de journal et code temporel. Si vous souhaitez également filtrer par ID de trace spécifique, ajoutez l'instruction suivante à la clause
WHERE:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'Dans l'expression précédente, remplacez TRACE_ID par la chaîne hexadécimale de 16 octets contenant un ID de trace.
Utiliser les fonctions BigQuery ML
Vous pouvez utiliser des fonctions BigQuery ML telles que AI.GENERATE sur les requêtes et les réponses stockées dans votre bucket Cloud Storage.
Par exemple, la requête suivante joint les entrées du journal d'achèvement à la table externe, aplatit et filtre le résultat de la jointure. Ensuite, la requête exécute AI.GENERATE pour analyser si les entrées contiennent une image et générer un résumé de chaque entrée :
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Remplacez les éléments suivants avant d'exécuter la requête :
- PROJECT_ID : identifiant du projet.
- LINKED_DATASET_NAME : nom de l'ensemble de données associé.
- EXT_TABLE_DATASET_NAME : nom de l'ensemble de données pour la table BigLake externe.
- EXT_TABLE_NAME : nom de la table BigLake externe.
- CONNECTION_LOCATION : emplacement de votre CONNECTION_ID.
- CONNECTION_ID : ID de la connexion.
Exécuter des évaluations sur les données de requête et de réponse avec Colaboratory
Vous pouvez évaluer les requêtes et les réponses à l'aide du SDK Vertex AI pour Python.
Pour exécuter des évaluations à l'aide d'un notebook Google Colaboratory, procédez comme suit :
Pour afficher un exemple de notebook, cliquez sur
evaluating_observability_datasets.ipynb.GitHub s'ouvre et affiche les instructions d'utilisation du notebook.
Sélectionnez Ouvrir dans Colab.
Colaboratory s'ouvre et affiche le fichier
evaluating_observability_datasets.ipynb.Dans la barre d'outils, cliquez sur Copier dans Drive.
Colaboratory crée une copie du notebook, l'enregistre dans votre Drive, puis l'ouvre.
Dans votre copie, accédez à la section Set Google Cloud project information (Définir les informations du projet Google Cloud), puis saisissez votre ID de projet Google Cloud et un emplacement compatible avec Vertex AI. Par exemple, vous pouvez définir l'emplacement sur
"us-central1".Accédez à la section Charger des ensembles de données d'IA générative Google Observability et saisissez les valeurs pour les sources suivantes :
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
Vous pouvez trouver les valeurs de ces champs à l'aide des libellés
gen_aiassociés à vos entrées de journal. Par exemple, pour INPUT_SOURCE, la valeur ressemble à ce qui suit :'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'Dans l'expression précédente, les champs ont les significations suivantes :
- STORAGE_BUCKET : nom du bucket Cloud Storage.
- PATH : chemin d'accès aux requêtes et aux réponses.
- REFERENCE : identifiant des données dans votre bucket Cloud Storage.
Pour savoir comment trouver les valeurs de ces sources, consultez Trouver toutes les entrées de journal qui font référence à des requêtes et des réponses.
Dans la barre d'outils, cliquez sur Exécuter tout.