
Los operadores distribuidos se ejecutan en varios servidores, a diferencia de los operadores hoja, unarios, binarios o n-arios.
Los siguientes son operadores distribuidos:
- Unión distribuida
- Aplicación distribuida
- Unión de combinación distribuida
- Unión hash de transmisión de envío
Esquema de la base de datos
Las consultas y los planes de ejecución en esta página se basan en el siguiente esquema de base de datos:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puedes usar las siguientes declaraciones del lenguaje de manipulación de datos (DML) para agregar datos a estas tablas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Un operador de unión distribuida es el operador básico a partir del cual se derivan las aplicaciones distribuidas cruzadas y las aplicaciones distribuidas externas.
Los operadores distribuidos aparecen en los planes de ejecución con una variante de unión distribuida sobre una o más variantes de unión distribuida local. Una variante de unión distribuida realiza la distribución remota de los subplanes.
Una variante de unión distribuida local se encuentra encima de cada uno de los análisis realizados para la consulta. Las variantes de unión distribuida local garantizan la ejecución estable de consultas cuando se producen reinicios para los límites de división que cambian de forma dinámica. Aunque este operador está oculto en el plan visual, siempre está presente.
Siempre que sea posible, una variante de unión distribuida usa un predicado de división para la reducción de división. La depuración de divisiones significa que los servidores remotos ejecutan subplanes solo en las divisiones que satisfacen el predicado, lo que mejora la latencia y el rendimiento de las consultas.
Unión distribuida
Un operador de unión distribuida divide de manera conceptual una o más tablas en varias divisiones, evalúa una subconsulta de manera independiente en cada división y, luego, unifica todos los resultados.
En la siguiente consulta, se muestra este operador:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
El plan de ejecución aparece de la siguiente manera:
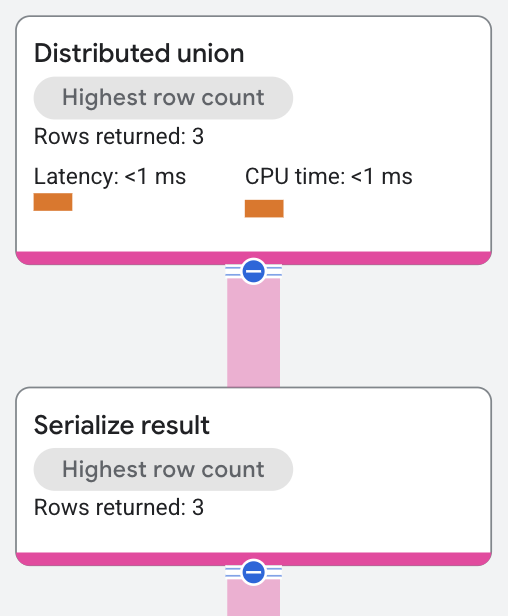
El operador de unión distribuida envía planes secundarios a servidores remotos, que realizan un análisis de tabla en divisiones que satisfacen el predicado WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK' de la consulta.
Un operador de serialización de resultados calcula los valores de SongName y SongGenre a partir de las filas que muestran los análisis de tabla. Luego, el operador de unión distribuida muestra los resultados combinados de los servidores remotos como los resultados de la consulta de SQL.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
El operador Unión distribuida tiene estadísticas de ejecución distintas adicionales.Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Ejecuciones paralelas locales | Es la cantidad de subconsultas que se ejecutan en paralelo. |
| Llamadas a distancia | Es la cantidad de subconsultas remotas ejecutadas. |
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Por lo general, las ejecuciones son paralelas, a diferencia de las ejecuciones de aplicación cruzada. Por este motivo, las cifras de latencia en los operadores distribuidos son acumulativas, a diferencia de la mayoría de los operadores, que informan cuánta latencia agregó el operador. La cantidad de ejecuciones en una unión distribuida se basa en los límites de división de la tabla, que, a su vez, dependen del tamaño y la carga de los datos, y pueden incluir la sugerencia de la instrucción use_additional_parallelism. Este enfoque de las estadísticas se aplica a todos los operadores distribuidos.
Aplicación distribuida
Un operador de aplicación distribuida (DA) extiende el operador de unión de aplicación ejecutándose en varios servidores. El lado de entrada agrupa las filas en lotes (a diferencia de un operador de aplicación cruzada normal, que actúa solo en una fila de entrada a la vez). El lado del mapa del DA es un conjunto de operadores de unión de aplicación simple que se ejecutan en servidores remotos. Una unión de aplicación distribuida admite los mismos métodos de aplicación que la unión de aplicación.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
El operador Distributed apply tiene estadísticas de ejecución distintas adicionales.Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Ejecuciones paralelas locales | Es la cantidad de subconsultas que se ejecutan en paralelo. |
| Llamadas a distancia | Es la cantidad de subconsultas remotas ejecutadas. |
| Cantidad de lotes | Un lote es una colección dinámica de filas que se procesan al mismo tiempo. Muestra la cantidad de lotes que un cross apply distribuido envió desde la entrada al lado del mapa. |
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Aplicación distribuida cruzada
En la siguiente consulta, se muestra este operador:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
El plan de ejecución aparece de la siguiente manera:
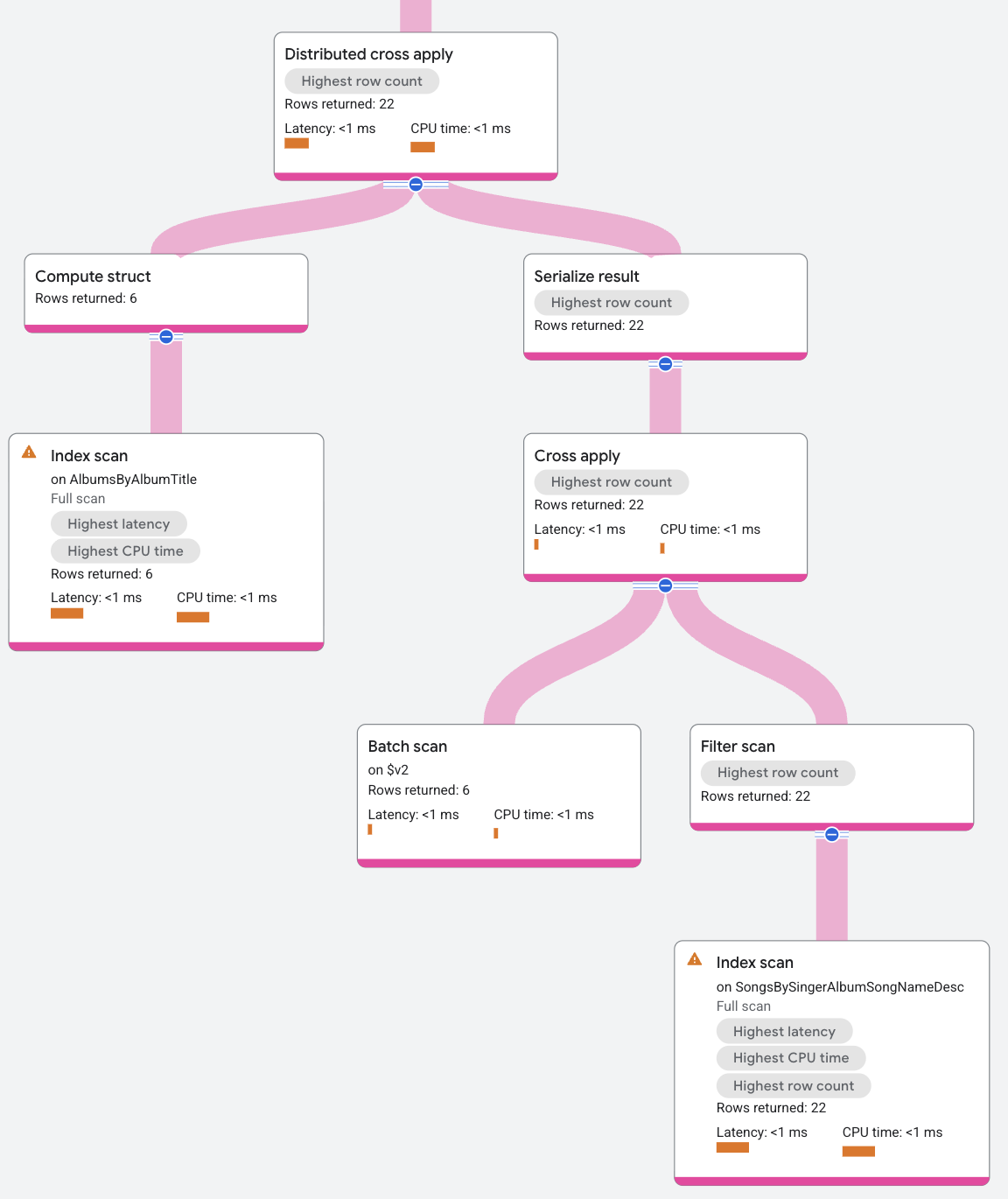
La entrada de DCA contiene un análisis del índice en el índice SongsBySingerAlbumSongNameDesc que agrupa las filas de AlbumId. El lado del mapa para el DCA es una aplicación cruzada estándar, en la que la entrada es un lote de filas y el lado del mapa es un análisis de índice en el índice AlbumsByAlbumTitle, sujeto al predicado de AlbumId en la fila de entrada que coincide con la clave AlbumId en el índice AlbumsByAlbumTitle. La asignación muestra el SongName para los valores SingerId en las filas de entrada por lotes.
Para resumir el proceso del DCA de este ejemplo, la entrada de la DCA son las filas por lotes de la tabla Albums y el resultado de la DCA es la aplicación de estas filas al mapa del análisis del índice.
Aplicación distribuida externa
Una aplicación externa distribuida es una DA con semántica de combinación externa izquierda. Consulta outer apply para obtener detalles sobre la semántica.
En la siguiente consulta, se muestra este operador:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
El plan de ejecución aparece de la siguiente manera:
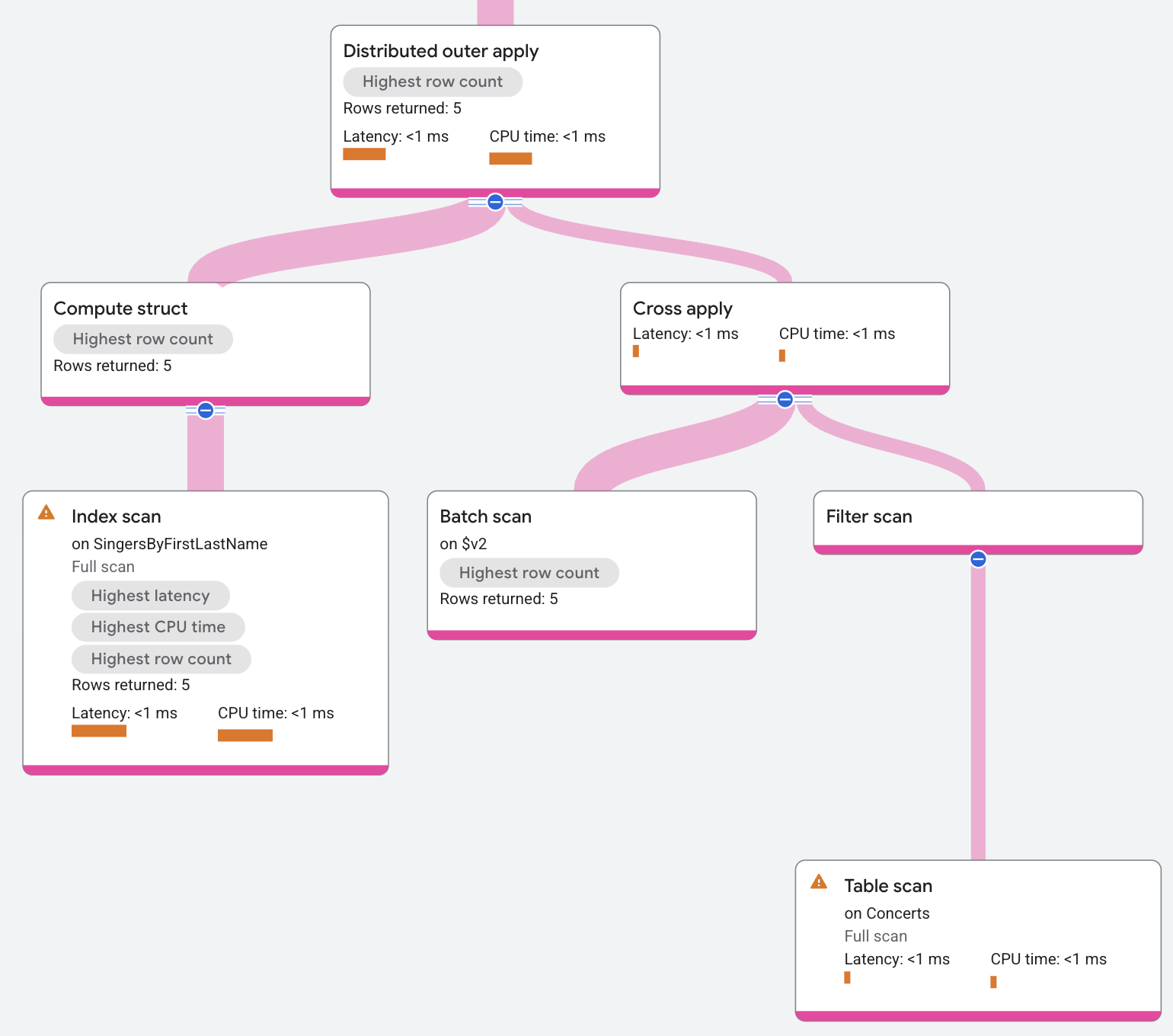
Aplicación distribuida semi
Un semiaplicar distribuido es un DA con semántica de semiunión. Consulta semi apply para obtener detalles sobre la semántica.
Aplicación distribuida de anti-semi
Una aplicación de semiunión distribuida negativa es una DA con semántica de semiunión negativa. Consulta anti-semi apply para obtener detalles sobre la semántica.
Unión de fusión distribuida
El operador de unión de combinación distribuida distribuye una consulta en varios servidores remotos. Luego, combina los resultados de la consulta para producir un resultado ordenado, conocido como orden combinado distribuido.
Una unión de combinación distribuida ejecuta los siguientes pasos:
El servidor raíz envía una subconsulta a cada servidor remoto que aloja una división de los datos consultados. La subconsulta incluye instrucciones para que los resultados se ordenen de una manera específica.
Cada servidor remoto ejecuta la subconsulta en su división y, luego, envía los resultados en el orden solicitado.
El servidor raíz combina la subconsulta ordenada para producir un resultado completamente ordenado.
La unión de combinación distribuida está habilitada de forma predeterminada para la versión 3 de Spanner y versiones posteriores.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
El operador Distributed apply tiene estadísticas de ejecución distintas adicionales.Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Ejecuciones paralelas locales | Es la cantidad de subconsultas que se ejecutan en paralelo. |
| Llamadas a distancia | Es la cantidad de subconsultas remotas ejecutadas. |
| Cantidad de lotes | Un lote es una colección dinámica de filas que se procesan al mismo tiempo. Muestra la cantidad de lotes que un cross apply distribuido envió desde la entrada al lado del mapa. |
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Unión hash de transmisión de envío
Un operador de unión hash de transmisión de envío es una implementación distribuida basada en unión hash de uniones de SQL. El operador de unión hash de transmisión de envío lee filas del lado de la entrada para construir un lote de datos. El operador transmite ese lote a todos los servidores que contienen datos del lado del mapa. En los servidores de destino en los que se recibe el lote de datos, el operador compila una unión hash con el lote como los datos del lado de la compilación y analiza los datos locales como el lado de la sonda de la unión hash.
La unión hash de transmisión de inserción tiene las siguientes ventajas:
- Si la tabla de compilación es pequeña, se puede enviar a todas las divisiones del mapa.
- La tabla lateral del mapa se puede analizar, con o sin filtros residuales. Esto ocurre cuando las claves de unión no son las mismas que las claves primarias de la tabla de asignación.
El optimizador no selecciona automáticamente la unión hash de transmisión de envío. Para usar este operador, establece el método de unión en PUSH_BROADCAST_HASH_JOIN en la sugerencia de la consulta, como se muestra en el siguiente ejemplo:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
El plan de ejecución aparece de la siguiente manera:
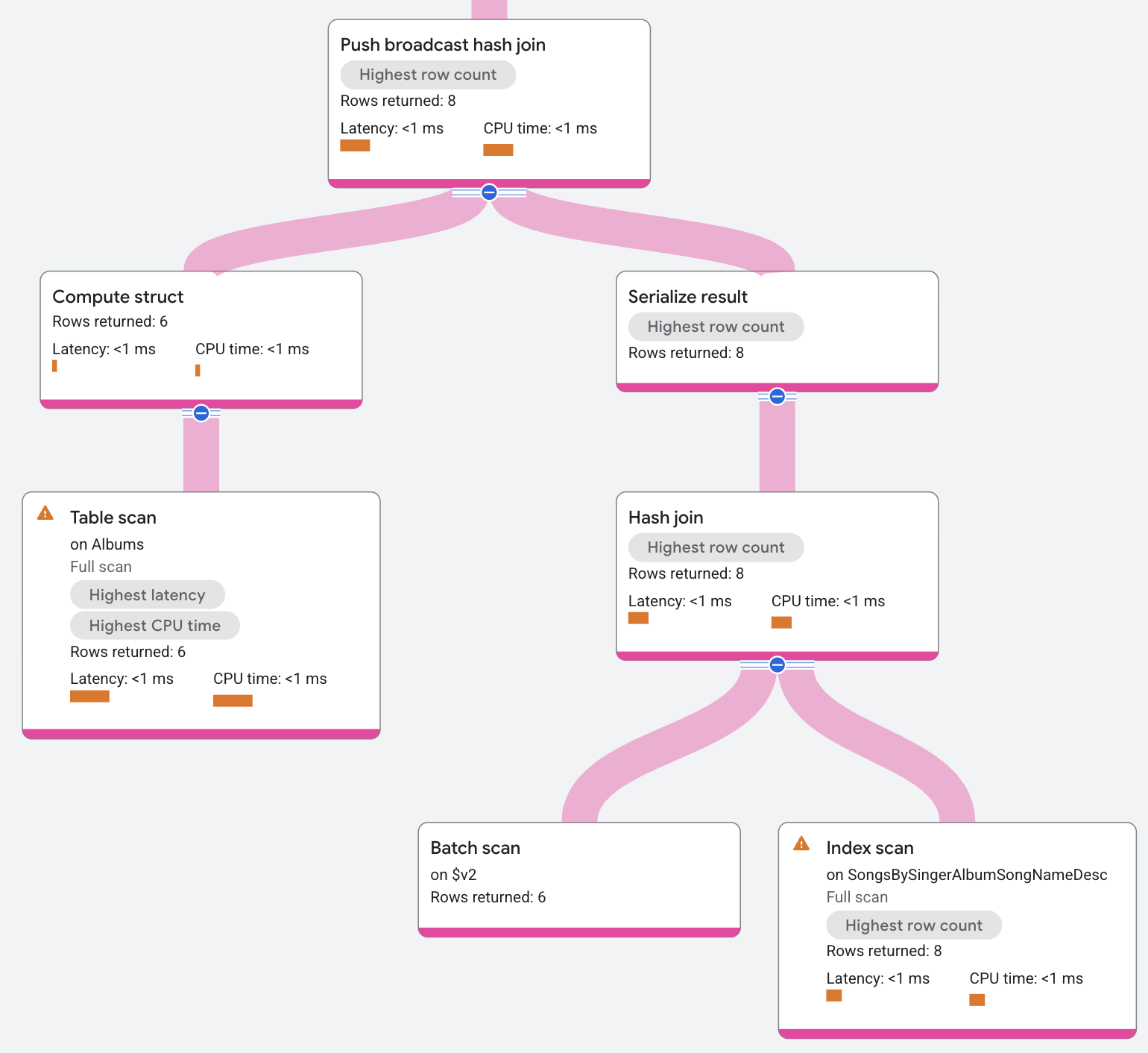
La entrada para la unión hash de transmisión de envío es el índice AlbumsByAlbumTitle.
El operador serializa esa entrada en un lote de datos. El operador envía ese lote a todas las divisiones locales del índice SongsBySingerAlbumSongNameDesc, en las que deserializa el lote y lo compila en una tabla hash. Luego, la tabla hash usa los datos del índice local como una sonda que devuelve las coincidencias resultantes.
En la tabla hash, estas también se pueden filtrar por una condición residual antes de que se muestren. (Un ejemplo de dónde aparecen las condiciones residuales es en las uniones que no son de igualdad).
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
El operador Distributed apply tiene estadísticas de ejecución distintas adicionales.Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Ejecuciones paralelas locales | Es la cantidad de subconsultas que se ejecutan en paralelo. |
| Llamadas a distancia | Es la cantidad de subconsultas remotas ejecutadas. |
| Cantidad de lotes | Un lote es una colección dinámica de filas que se procesan al mismo tiempo. Muestra la cantidad de lotes que un cross apply distribuido envió desde la entrada al lado del mapa. |
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |