
Un operador binario tiene dos operadores secundarios relacionales. Los siguientes son operadores binarios:
Esquema de la base de datos
Las consultas y los planes de ejecución en esta página se basan en el siguiente esquema de base de datos:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puedes usar las siguientes declaraciones del lenguaje de manipulación de datos (DML) para agregar datos a estas tablas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Aplicar unión
Una unión de aplicación es el operador de unión principal que usa Spanner. Los operadores de aplicación de unión ejecutan el procesamiento orientado a filas, a diferencia de los operadores que ejecutan el procesamiento basado en conjuntos, como la unión hash. El operador de aplicación tiene dos entradas, input (operador secundario izquierdo) y map (operador secundario derecho). El operador de aplicación aplica cada fila del lado de entrada al lado del mapa con un método de aplicación: cruzado, externo, semi o anti-semi. Además, en el lado del mapa de una aplicación distribuida también aparece una variante de una unión de aplicación.
El operador Apply join es más eficiente en los siguientes casos:
- La cardinalidad de la entrada es baja.
- La clave de unión es un prefijo de la clave primaria del lado del mapa.
- La consulta une dos tablas intercaladas.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Aplicación cruzada
Un Cross apply realiza una unión interna en la que solo se devuelven las filas coincidentes.
En la siguiente consulta, se muestra este operador:
La consulta solicita el nombre de cada cantante, junto con el nombre de solo una de sus canciones.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
La consulta propaga la primera columna desde la tabla Singers y la segunda columna desde la tabla Songs. En los casos en que haya una SingerId en la tabla Singers pero no haya coincidencias de SingerId en la tabla Songs, la segunda columna contendrá NULL.
El plan de ejecución comienza de la siguiente manera:
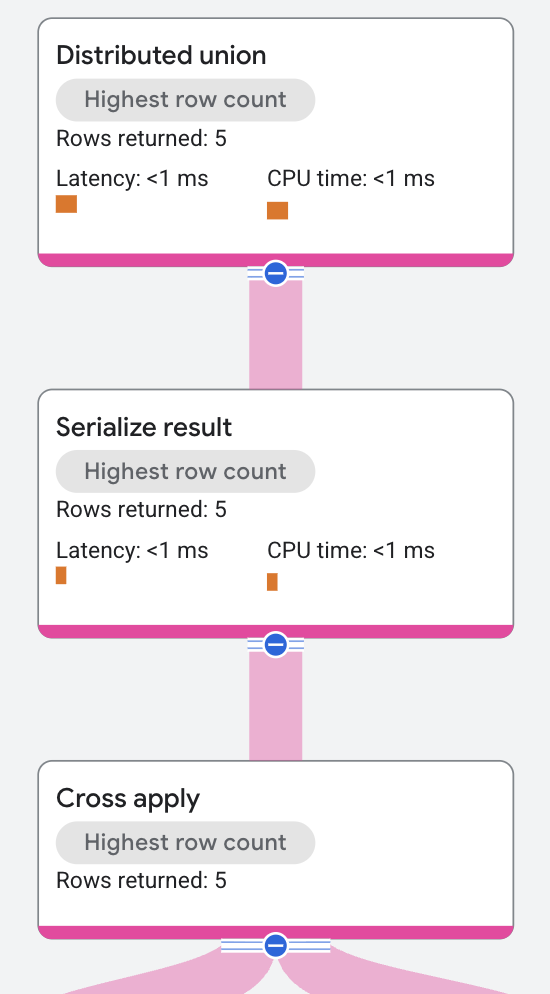
El nodo de nivel superior es un operador de unión distribuida. El operador de unión distribuida distribuye los planes secundarios a los servidores remotos. El subplan contiene un operador de serialización de resultados que procesa el nombre del cantante y el nombre de una de sus canciones, y serializa cada fila del resultado.
El operador de serialización de resultados recibe su entrada desde el operador de aplicación cruzada.
El lado de entrada para el operador de aplicación cruzada es un análisis de tabla en la tabla Singers.
El plan de ejecución continúa de la siguiente manera:
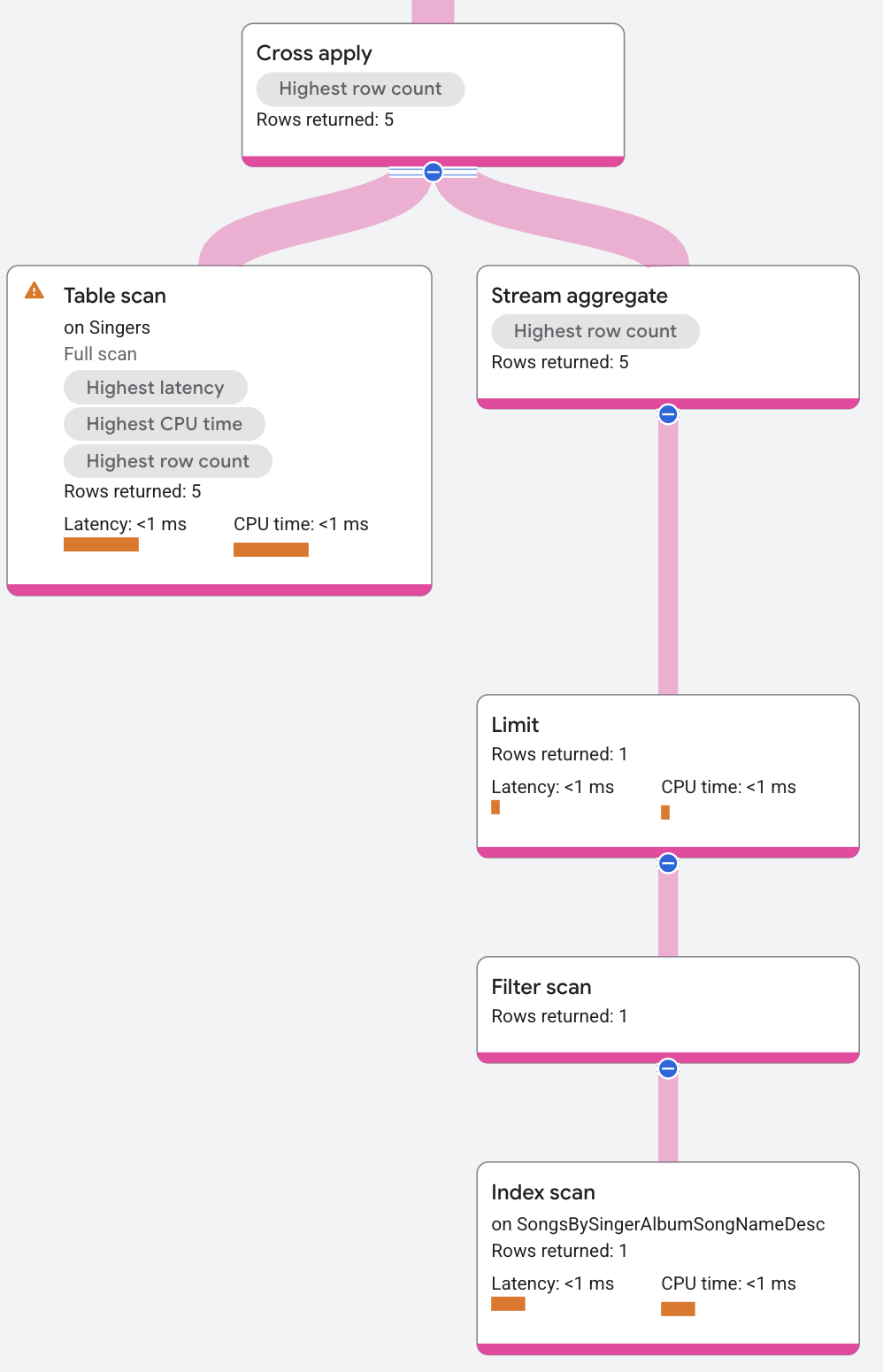
El lado del mapa de la operación de aplicación cruzada contiene lo siguiente (de arriba abajo):
- Un operador de agregación que devuelve
Songs.SongName. - Un operador de límite que restringe la cantidad de canciones que se muestran a una por cantante.
- Un análisis de índice en el índice
SongsBySingerAlbumSongNameDesc.
El operador de aplicación cruzada asigna cada fila desde el lado de entrada a una fila en el lado del mapa que tiene el mismo SingerId. El resultado del operador de aplicación cruzada es el valor FirstName desde la fila de entrada y el valor SongName desde la fila del mapa.
(El valor SongName es NULL si no hay ninguna fila del mapa que coincida con el SingerId). El operador de unión distribuida en la parte superior del plan de ejecución combina todas las filas de salida de los servidores remotos y los muestra como resultados de la consulta.
Aplicación externa
Una aplicación externa proporciona una semántica de combinación externa izquierda. Garantiza que cada ejecución en el lado del mapa muestre al menos una fila agregando relleno de NULL si es necesario.
Aplicación parcial
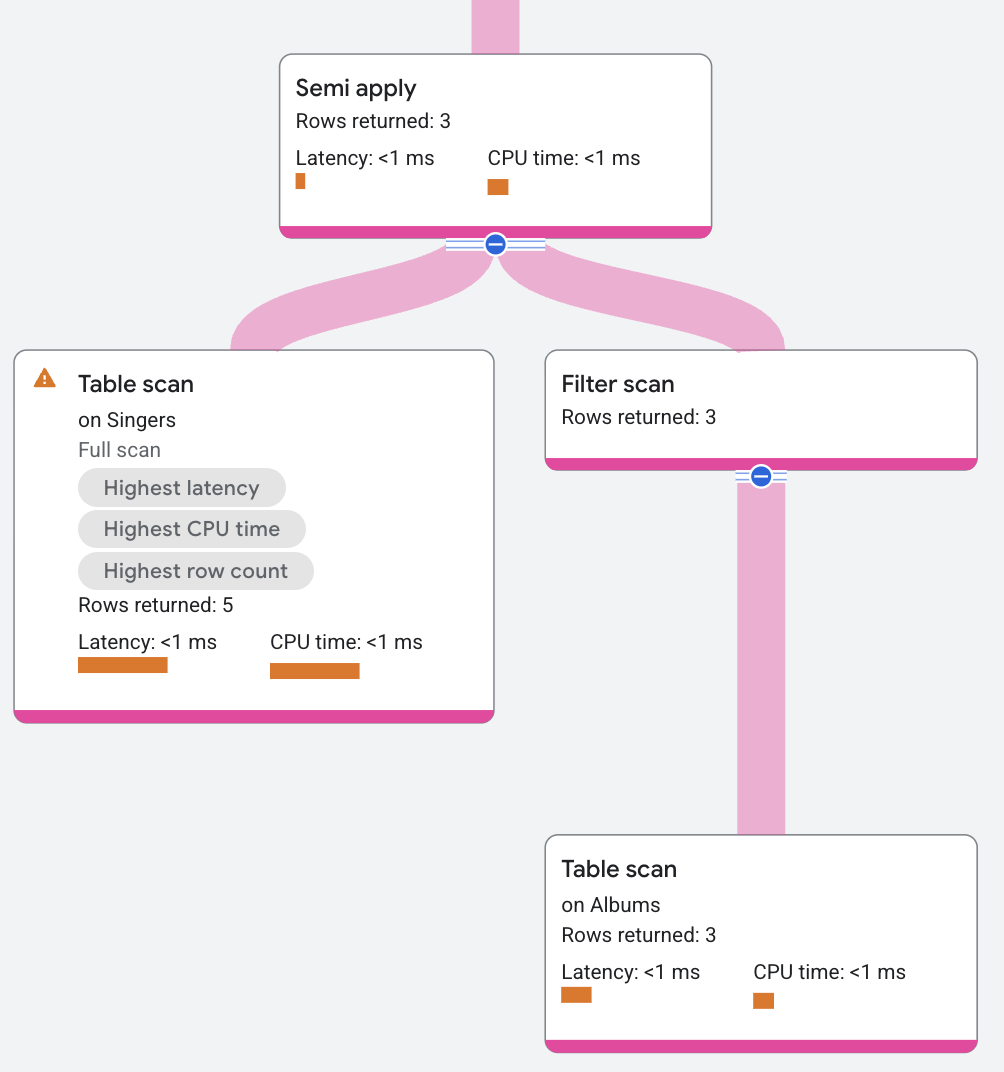
El operador semi apply devuelve columnas de entrada solo cuando se produce una coincidencia en el lado del mapa.
La siguiente consulta usa una semiunión para encontrar qué cantantes tienen un álbum:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
El segmento del plan aparece de la siguiente manera:
Anti-semi apply
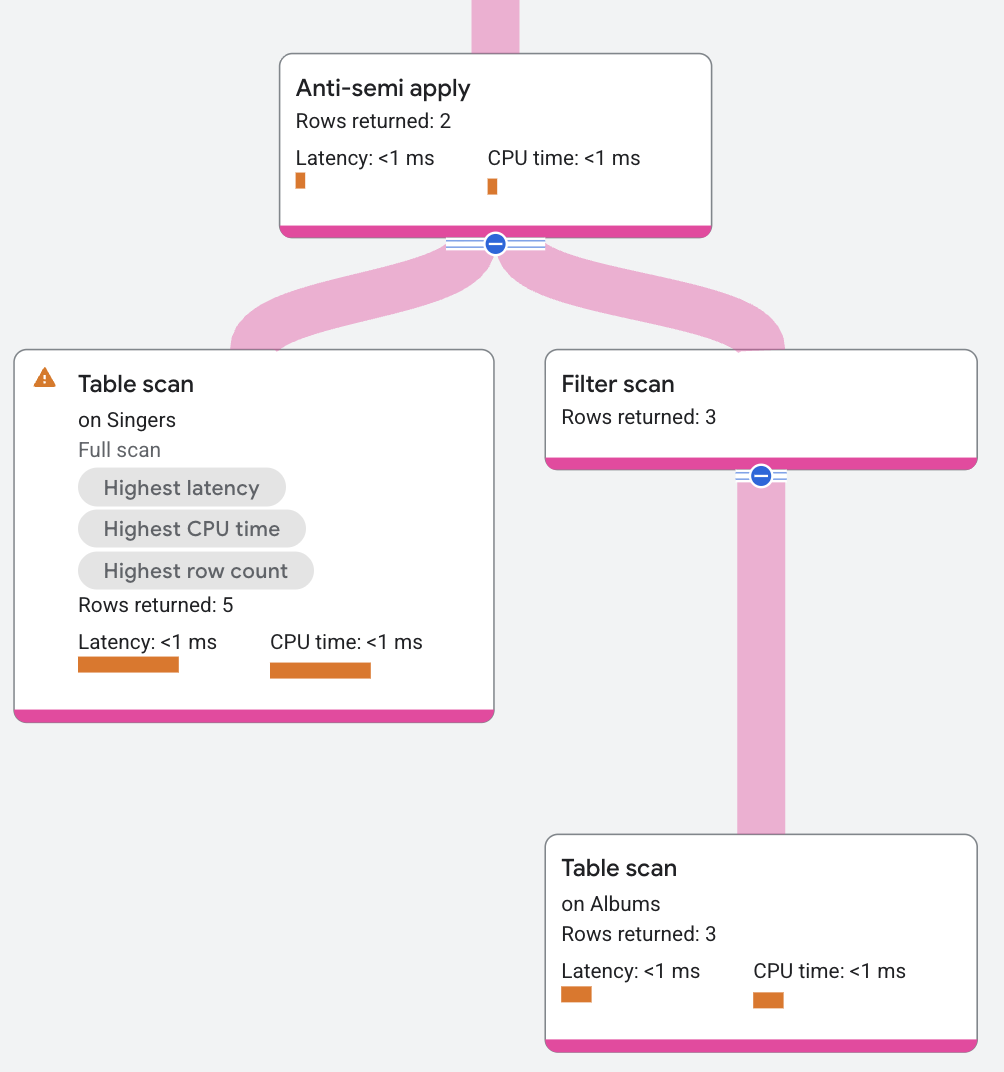
Un operador de Anti-semi apply es similar a un operador de semi apply, excepto que devuelve las columnas de la tabla de entrada solo cuando no se produce una coincidencia en el lado del mapa.
La siguiente consulta usa una anti-semi unión para encontrar qué cantantes no tienen un álbum:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
El segmento del plan aparece de la siguiente manera:
Unión hash
Un operador de unión hash es una implementación basada en hash de uniones de SQL. Las uniones de hash ejecutan el procesamiento basado en conjuntos. El operador de unión hash lee las filas de la entrada marcadas como compilación (hijo izquierdo) y las inserta en una tabla hash basada en una condición de unión. Luego, el operador de unión hash lee las filas de la entrada marcadas como sondeo (elemento secundario derecho). Para cada fila que se lee desde la entrada de sondeo, el operador de unión hash busca las filas que coinciden en la tabla hash. y las muestra como resultado.
La combinación hash tiene las siguientes ventajas:
- No requiere que las entradas estén ordenadas.
- Calcula un filtro de Bloom cuando se compila la tabla hash. El operador usa el filtro para excluir las filas del lado de la sonda que no tienen coincidencias. Ten en cuenta que este es un filtro residual, no un filtro de búsqueda.
En la siguiente consulta, se muestra este operador:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
El segmento del plan de ejecución aparece de la siguiente manera:
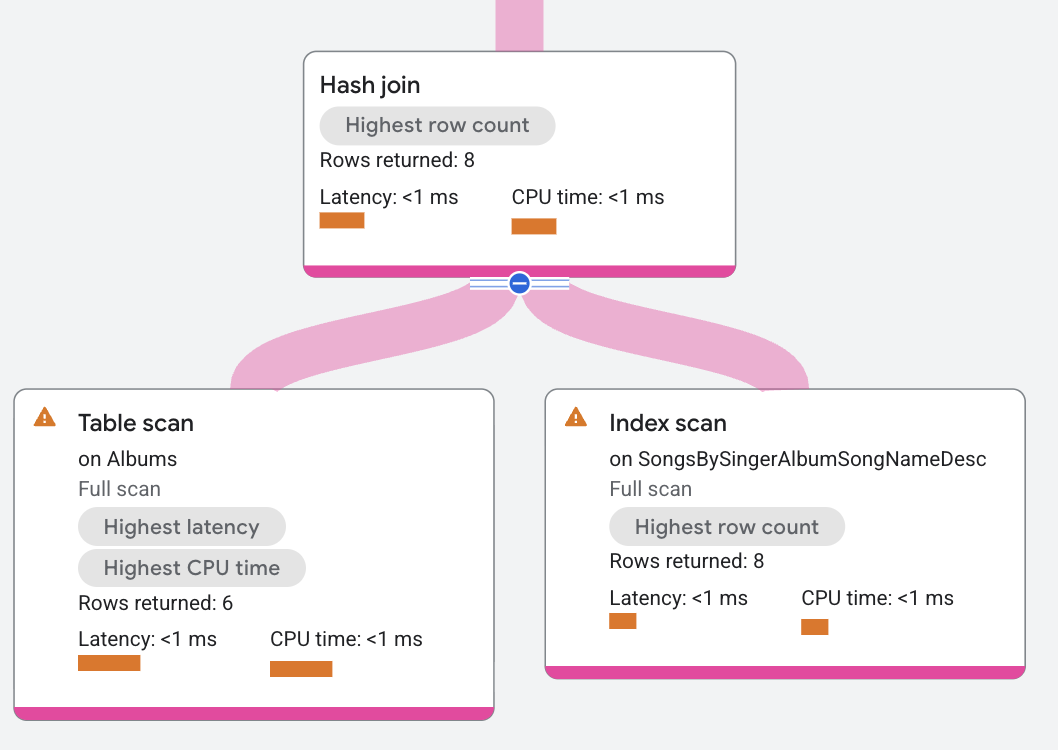
En el plan de ejecución, compilación es una unión distribuida que reparte los análisis en la tabla Albums. Sondeo es un operador de unión distribuida que reparte los análisis en el índice SongsBySingerAlbumSongNameDesc.
El operador de unión hash lee todas las filas desde el lado de la compilación. Cada fila de compilación se coloca en una tabla hash basada en las columnas de la condición a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId. A continuación, el operador de unión hash lee todas las filas del lado del sondeo. Para cada fila de sondeo, el operador de unión hash busca coincidencias en la tabla hash. El operador de unión hash muestra las coincidencias resultantes.
En la tabla hash, estas también se pueden filtrar por una condición residual antes de que se muestren. (Un ejemplo de dónde aparecen las condiciones residuales es en las uniones que no son de igualdad). Los planes de ejecución de unión hash pueden ser complejos debido a la administración de memoria y a las variantes de unión. El algoritmo principal de unión hash está adaptado para manejar variantes de unión interna, semi, anti y externa.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Combinación por fusión
Un operador de unión por combinación es una implementación basada en combinación de la unión de SQL. Ambos lados de la unión producen filas ordenadas por las columnas que se usan en la condición de unión. La combinación por fusión consume ambas transmisiones de entrada de forma simultánea y genera filas cuando se cumple la condición de combinación. Si las entradas no están ordenadas, el optimizador agrega operadores Sort explícitos al plan.
La unión por combinación tiene las siguientes ventajas:
- Si los datos ya están ordenados, no se necesita memoria.
- Incluso si los datos no están ordenados, para una unión distribuida, se puede realizar la ordenación en cada división individual, en lugar de crear una tabla hash grande en la raíz.
El optimizador no selecciona automáticamente la opción Combinación por fusión. Para usar este operador, configura el método de unión como MERGE_JOIN en la sugerencia de la consulta, como se muestra en el siguiente ejemplo:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
El plan de ejecución aparece de la siguiente manera:
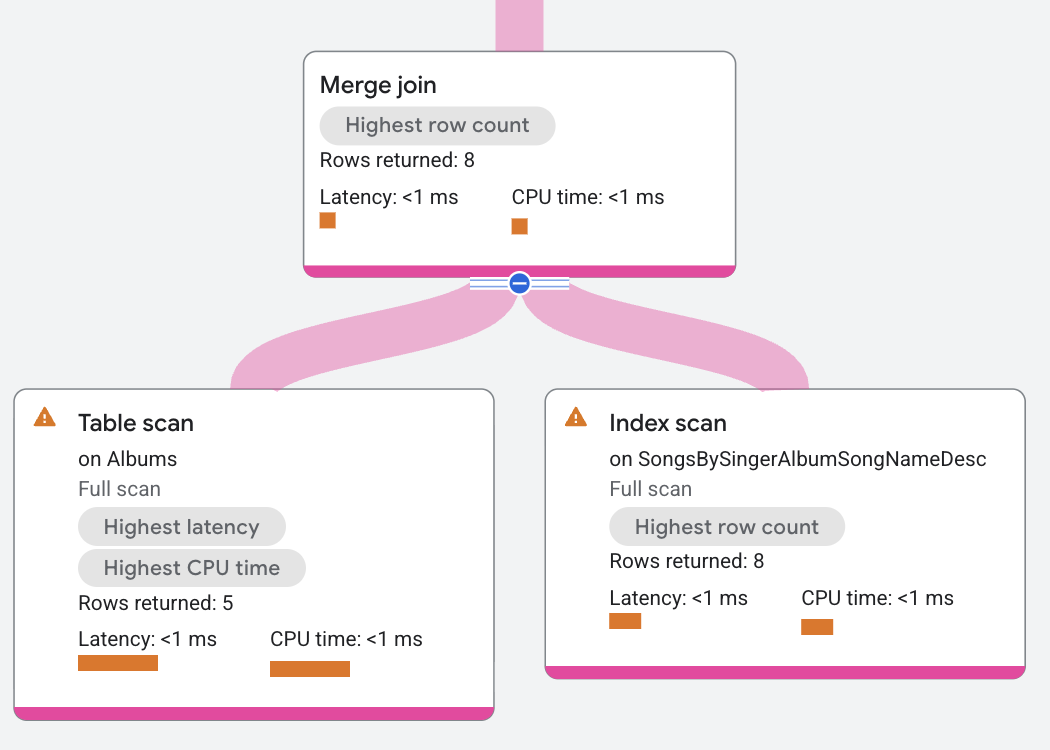
En este plan de ejecución, la unión por combinación se distribuye de modo que la unión se ejecute donde residen los datos. Esto también permite que la unión combinada de este ejemplo funcione sin operadores de orden adicionales, ya que ambos análisis de tabla ya están ordenados por SingerId, AlbumId, que es la condición de unión. En este plan, el análisis izquierdo de la tabla Albums avanza cada vez que su SingerId, AlbumId es menor que los valores SingerId_1, AlbumId_1 del análisis derecho. Del mismo modo, el análisis derecho avanza siempre que sus valores sean menores que los del análisis izquierdo. Este avance de combinación sigue buscando equivalencias para devolver filas coincidentes.
Considera otro ejemplo de unión por combinación con la siguiente consulta:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
El plan de ejecución aparece de la siguiente manera:
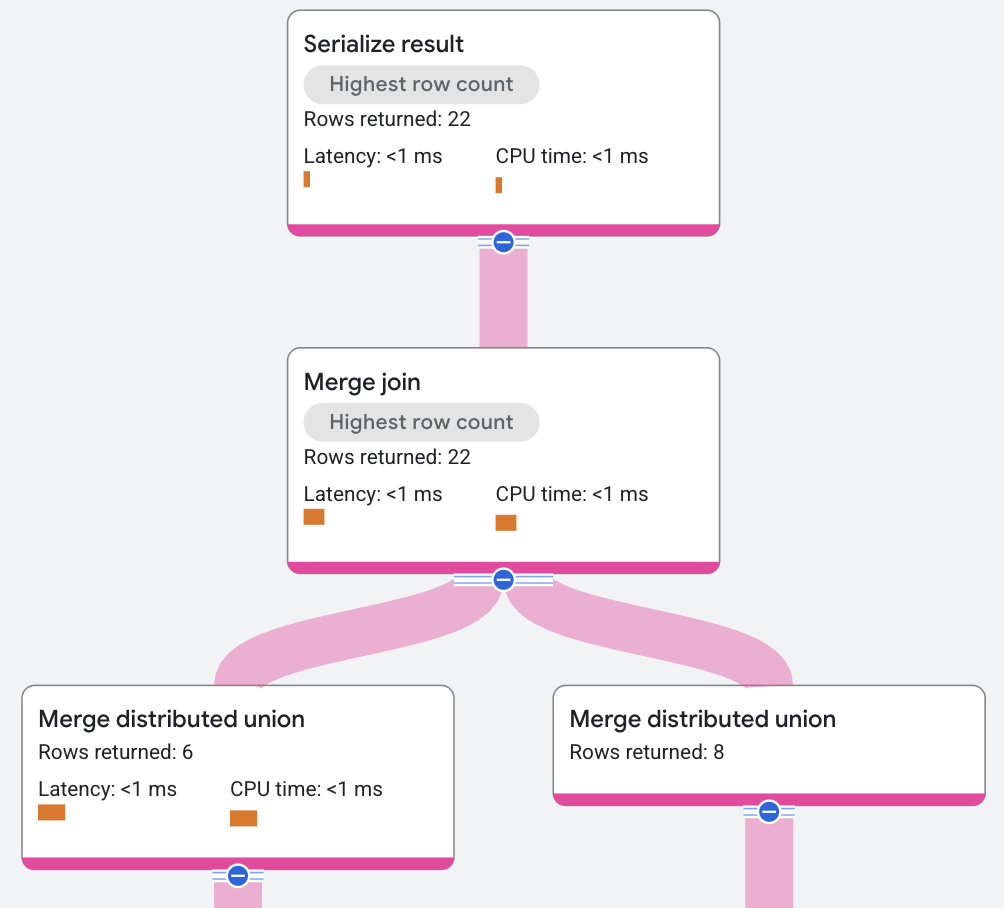
En el plan de ejecución anterior, el optimizador de consultas introdujo operadores de orden adicionales para ejecutar la unión por combinación. La condición JOIN en esta consulta de ejemplo solo se aplica a AlbumId, que no es la forma en que se almacenan los datos, por lo que se debe agregar una ordenación. El motor de consultas admite un algoritmo de combinación distribuida, que permite que la clasificación se realice de forma local en lugar de global, lo que distribuye y paraleliza el costo de la CPU.
Los resultados coincidentes también se pueden filtrar por una condición residual. Por ejemplo, las condiciones residuales aparecen en las uniones que no son de igualdad. Los planes de ejecución de unión por combinación pueden ser complejos debido a los requisitos de ordenamiento adicionales. El algoritmo principal de unión por combinación maneja variantes de unión interna, semi, anti y externa.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |
Unión recursiva
Un operador de unión recursiva realiza una unión de dos entradas, una que representa un caso de base y la otra que representa un caso de recursive. Se usa en consultas de grafos con recorridos de ruta cuantificados. La entrada base se procesa primero y exactamente una vez. La entrada recursiva se procesa hasta que finaliza la recursión. La recursión finaliza cuando se alcanza el límite superior, si se especificó, o cuando la recursión no produce resultados nuevos. En el siguiente ejemplo, se agrega la tabla Collaborations al esquema y se crea un gráfico de propiedades llamado MusicGraph.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
La siguiente consulta de gráfico encuentra a los cantantes que colaboraron con un cantante determinado o con sus colaboradores.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
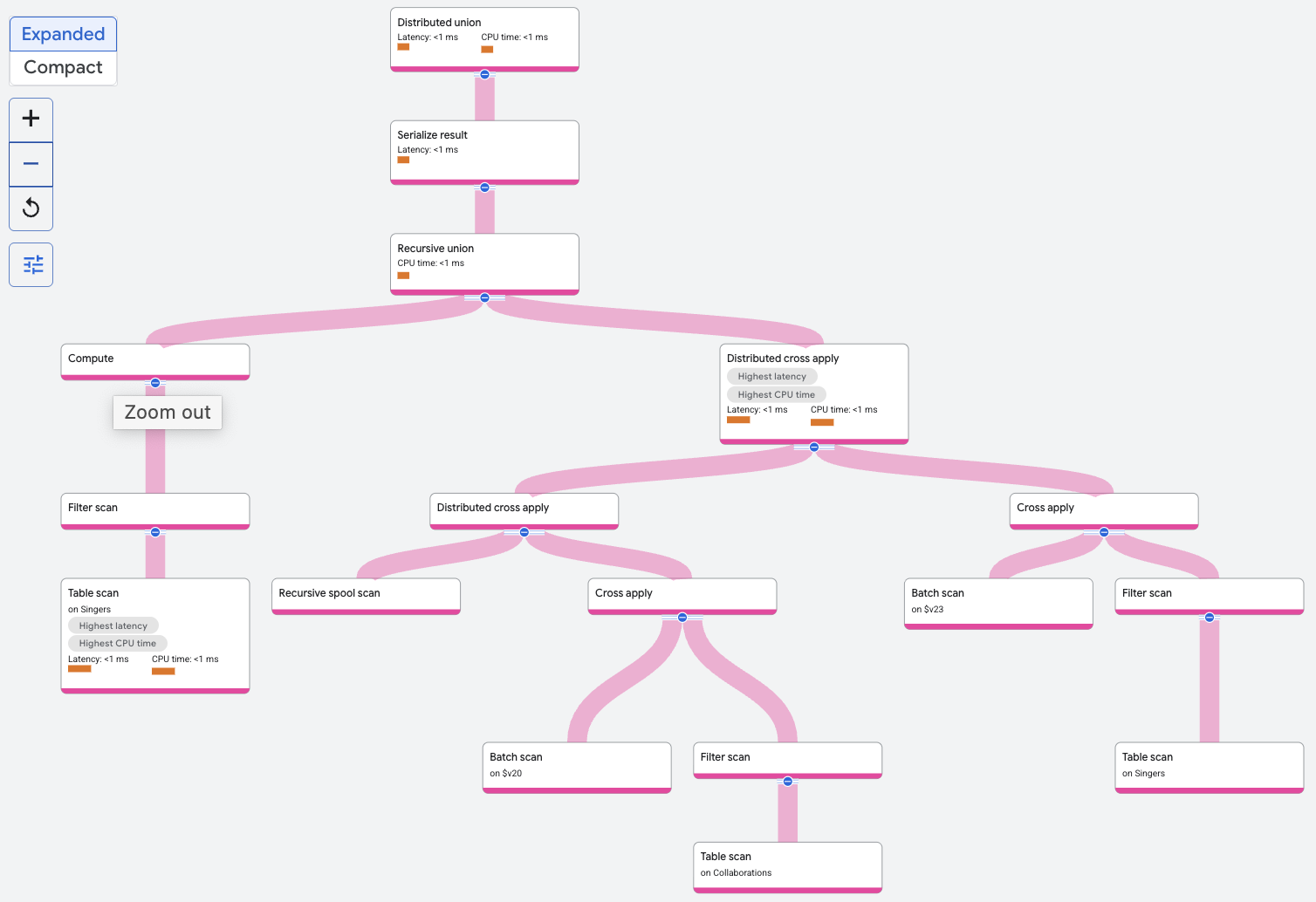
El operador de unión recursiva filtra la tabla Singers para encontrar al cantante con el SingerId determinado. Esta es la entrada base para la unión recursiva. La entrada recursiva para la unión recursiva incluye un operador de aplicación cruzada distribuida o de otra unión para otras consultas que une repetidamente la tabla Collaborations con los resultados de la iteración anterior de la unión. Las filas de la entrada base forman la iteración cero.
En cada iteración, el análisis recursivo de carrete almacena el resultado de la iteración. Las filas del análisis de spool recursivo se unen con la tabla Collaborations en spoolscan.featuredSingerId = Collaborations.SingerId. La recursión finaliza cuando se completan dos iteraciones, ya que ese es el límite superior especificado en la consulta.
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |