
Distributed operators execute across multiple servers unlike leaf, unary, binary, or n-ary operators.
The following operators are distributed operators:
Database schema
The queries and execution plans on this page are based on the following database schema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
You can use the following Data Manipulation Language (DML) statements to add data to these tables:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
The distributed union operator is the primitive operator from which distributed cross apply and distributed outer apply are derived.
Distributed operators appear in execution plans with a distributed union variant on top of one or more local distributed union variants. A distributed union variant performs the remote distribution of subplans.
A local distributed union variant is on top of each of the scans performed for the query. The local distributed union variants ensure stable query execution when restarts occur for dynamically changing split boundaries. Although this operator is hidden from the visual plan, it is always present.
Whenever possible, a distributed union variant uses a split predicate for split pruning. Split pruning means the remote servers execute subplans only on splits that satisfy the predicate, improving latency and query performance.
Distributed union
A distributed union operator conceptually divides one or more tables into multiple splits, remotely evaluates a subquery independently on each split, and then unions all results.
The following query demonstrates this operator:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
The execution plan appears as follows:
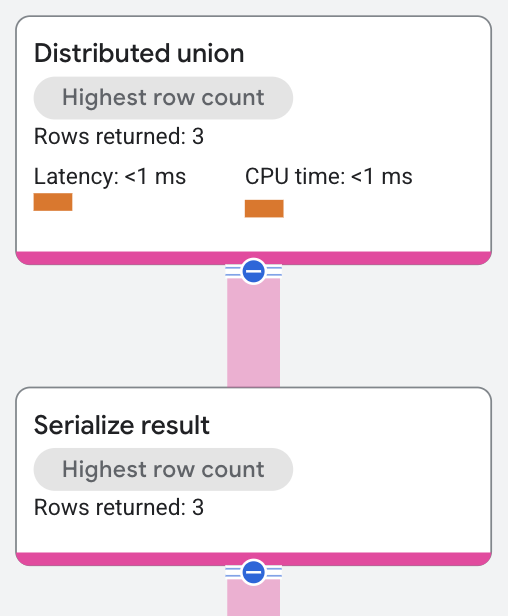
The distributed union operator sends subplans to remote servers, which perform a
table scan across splits that satisfy
the query's predicate WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK'.
A serialize result
operator computes the SongName and SongGenre
values from the rows returned by the table scans. The distributed union operator
then returns the combined results from the remote servers as the SQL query
results.
Properties and execution statistics
A property of an operator describes a trait that is used when the operator is executed. An execution statistic is a value collected during query execution to help you assess performance of the operator.
The Distributed union operator has additional distinct execution statistics.Properties
| Name | Description |
|---|---|
| Execution method | In Row execution, the operator processes one row at a time. In Batch execution, the operator processes a batch of rows at once. |
Execution statistics
| Name | Description |
|---|---|
| Local parallel executions | The number of subqueries executed in parallel. |
| Remote calls | The number of remote subqueries executed. |
| Latency | Elapsed time of all the executions done in the operator. |
| Cumulative latency | The total time of the current operator and its descendants. |
| CPU time | Sum of CPU time spent executing the operator. |
| Cumulative CPU time | The total CPU time spent executing the operator and its descendants. |
| Execution time | The total amount of time taken to run the query and process results. |
| Rows returned | The number of rows output by this operator |
| Number of executions | The number of times the operator was executed. Some executions can run in parallel. |
Generally, executions are in parallel, unlike cross apply executions. Because of this, latency numbers on distributed operators are cumulative, unlike most operators, which report how much latency that operator added. The number of executions under a distributed union is based on the table's split boundaries, which in turn depend on data size and load, and potentially include the use_additional_parallelism statement hint. This approach to statistics applies to all distributed operators.
Distributed apply
A distributed apply (DA) operator extends the apply join operator by executing across multiple servers. The input side groups rows into batches (unlike a regular cross apply operator, which acts on only one input row at a time). The DA map side is a set of plain apply join operators that execute on remote servers. A distributed apply join supports the same apply methods as apply join.
Properties and execution statistics
A property of an operator describes a trait that is used when the operator is executed. An execution statistic is a value collected during query execution to help you assess performance of the operator.
The Distributed apply operator has additional distinct execution statistics.Properties
| Name | Description |
|---|---|
| Execution method | In Row execution, the operator processes one row at a time. In Batch execution, the operator processes a batch of rows at once. |
Execution statistics
| Name | Description |
|---|---|
| Local parallel executions | The number of subqueries executed in parallel. |
| Remote calls | The number of remote subqueries executed. |
| Number of batches | A batch is a dynamic collection of rows that are processed at the same time. This shows the number of batches a distributed cross apply sent from the input to the map side. |
| Latency | Elapsed time of all the executions done in the operator. |
| Cumulative latency | The total time of the current operator and its descendants. |
| CPU time | Sum of CPU time spent executing the operator. |
| Cumulative CPU time | The total CPU time spent executing the operator and its descendants. |
| Execution time | The total amount of time taken to run the query and process results. |
| Rows returned | The number of rows output by this operator |
| Number of executions | The number of times the operator was executed. Some executions can run in parallel. |
Distributed cross apply
The following query demonstrates this operator:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
The execution plan appears as follows:
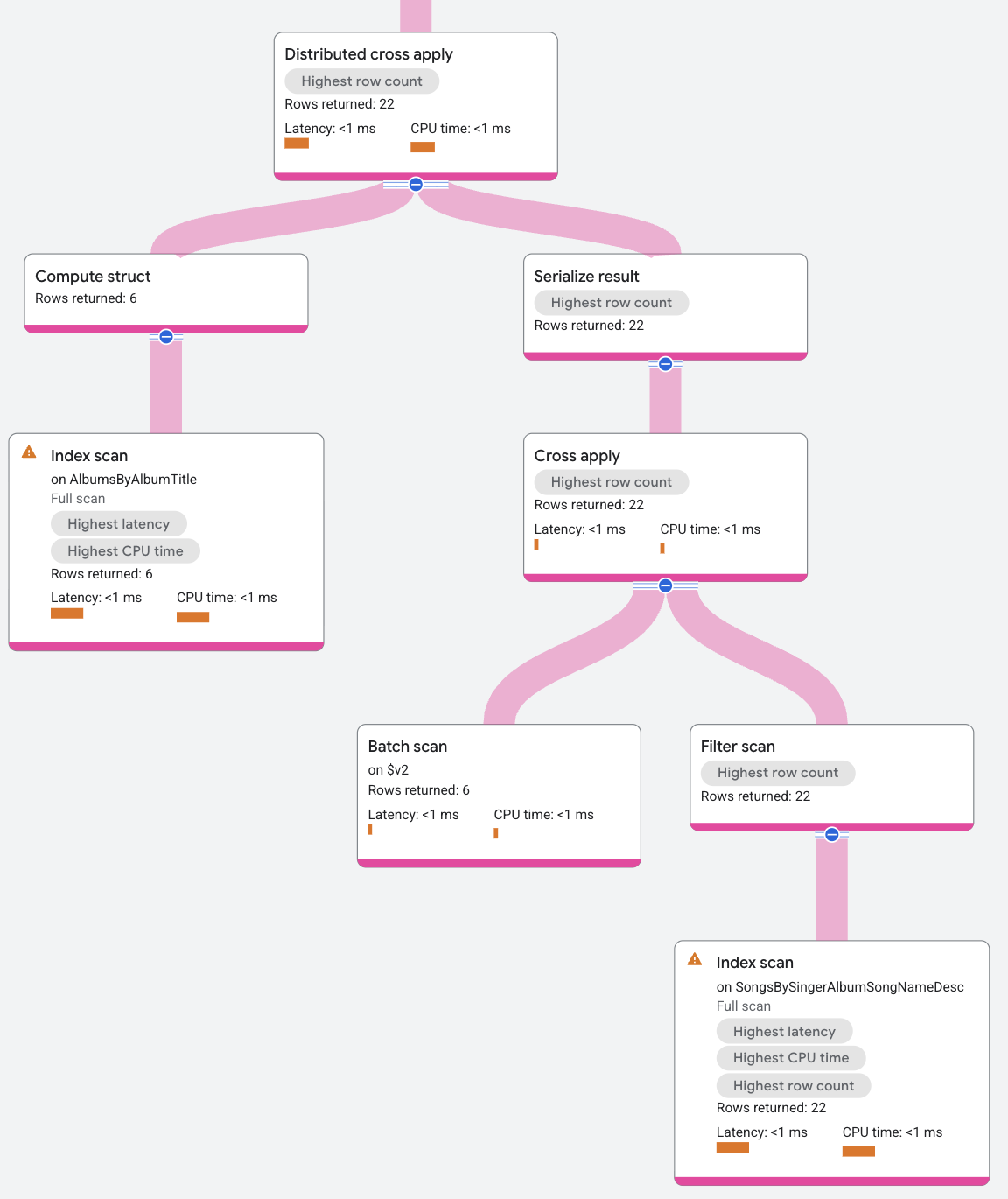
The DCA input contains an index scan on the
SongsBySingerAlbumSongNameDesc index that batches rows of AlbumId. The map
side for the DCA is a standard cross apply, where the input is a batch of rows, and
the map side is an index scan on the index AlbumsByAlbumTitle, subject to the
predicate of AlbumId in the input row matching the AlbumId key in the
AlbumsByAlbumTitle index. The mapping returns the SongName for the
SingerId values in the batched input rows.
To summarize the DCA process for this example, the DCA's input is the batched
rows from the Albums table, and the DCA's output is the application of these
rows to the map of the index scan.
Distributed outer apply
A Distributed outer apply is a DA with left outer join semantics. See outer apply for details on the semantics.
The following query demonstrates this operator:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
The execution plan appears as follows:
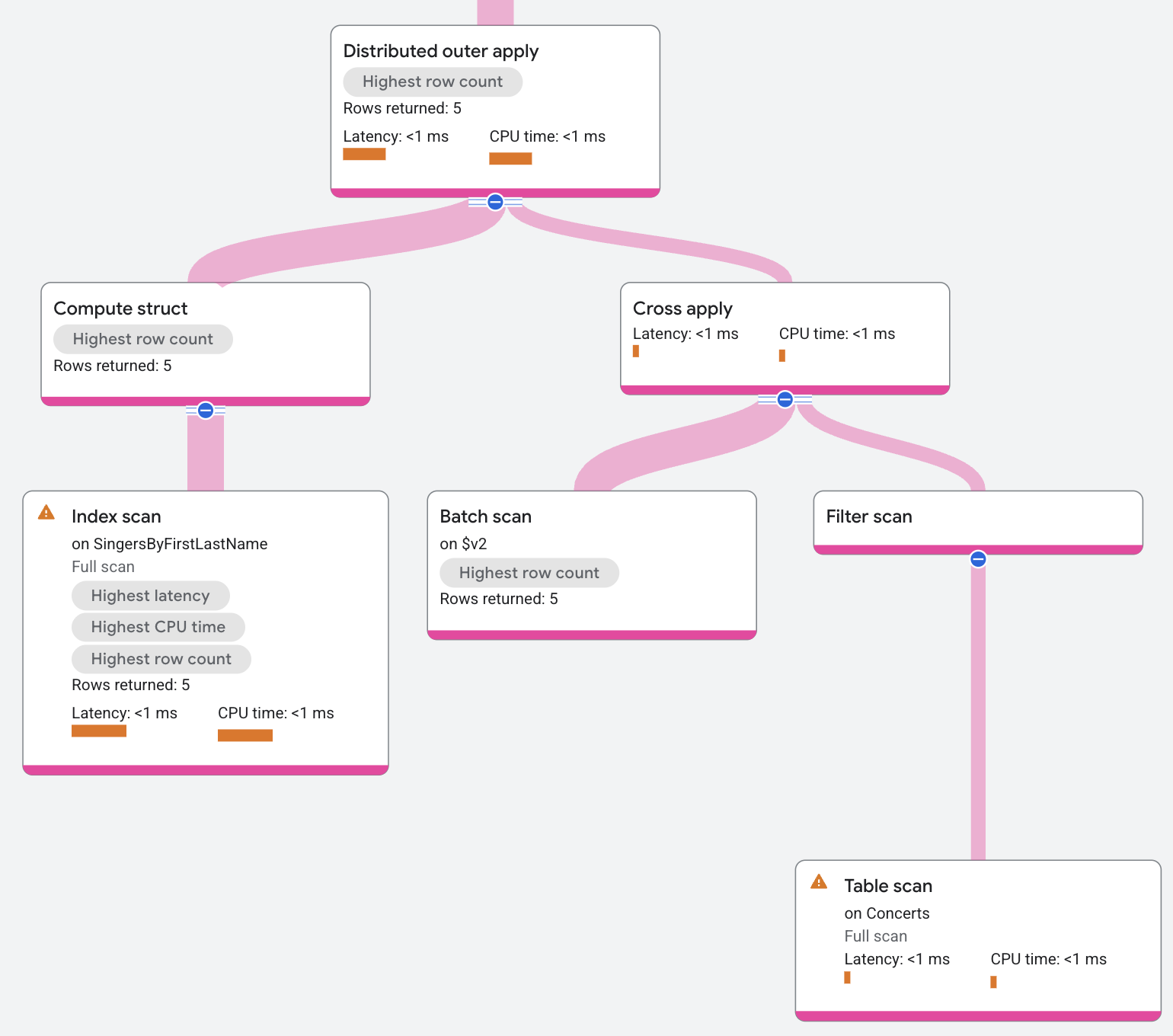
Distributed semi apply
A Distributed semi apply is a DA with semi join semantics. See semi apply for details on the semantics.
Distributed anti-semi apply
A Distributed anti-semi apply is a DA with anti-semi join semantics. See anti-semi apply for details on the semantics.
Distributed merge union
The distributed merge union operator distributes a query across multiple remote servers. It then combines the query results to produce a sorted result, known as a distributed merge sort.
A distributed merge union executes the following steps:
The root server sends a subquery to each remote server that hosts a split of the queried data. The subquery includes instructions that results are sorted in a specific order.
Each remote server executes the subquery on its split, then sends the results back in the requested order.
The root server merges the sorted subquery to produce a completely sorted result.
Distributed merge union is enabled by default for Spanner Version 3 and later.
Properties and execution statistics
A property of an operator describes a trait that is used when the operator is executed. An execution statistic is a value collected during query execution to help you assess performance of the operator.
The Distributed apply operator has additional distinct execution statistics.Properties
| Name | Description |
|---|---|
| Execution method | In Row execution, the operator processes one row at a time. In Batch execution, the operator processes a batch of rows at once. |
Execution statistics
| Name | Description |
|---|---|
| Local parallel executions | The number of subqueries executed in parallel. |
| Remote calls | The number of remote subqueries executed. |
| Number of batches | A batch is a dynamic collection of rows that are processed at the same time. This shows the number of batches a distributed cross apply sent from the input to the map side. |
| Latency | Elapsed time of all the executions done in the operator. |
| Cumulative latency | The total time of the current operator and its descendants. |
| CPU time | Sum of CPU time spent executing the operator. |
| Cumulative CPU time | The total CPU time spent executing the operator and its descendants. |
| Execution time | The total amount of time taken to run the query and process results. |
| Rows returned | The number of rows output by this operator |
| Number of executions | The number of times the operator was executed. Some executions can run in parallel. |
Push broadcast hash join
A push broadcast hash join operator is a distributed hash-join-based implementation of SQL joins. The push broadcast hash join operator reads rows from the input side in order to construct a batch of data. The operator broadcasts that batch to all servers containing map side data. On the destination servers where the batch of data is received, the operator builds a hash join using the batch as the build side data and scans the local data as the probe side of the hash join.
Push broadcast hash join has the following advantages:
- If the build table is small, it can be sent to all map side splits.
- The map side table can be scanned, with or without residual filters. This occurs when the join keys are not the same as the map table's primary keys.
Push broadcast hash join isn't selected automatically by the optimizer. To use
this operator, set the join method to PUSH_BROADCAST_HASH_JOIN on the
query hint, as shown in the following example:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
The execution plan appears as follows:
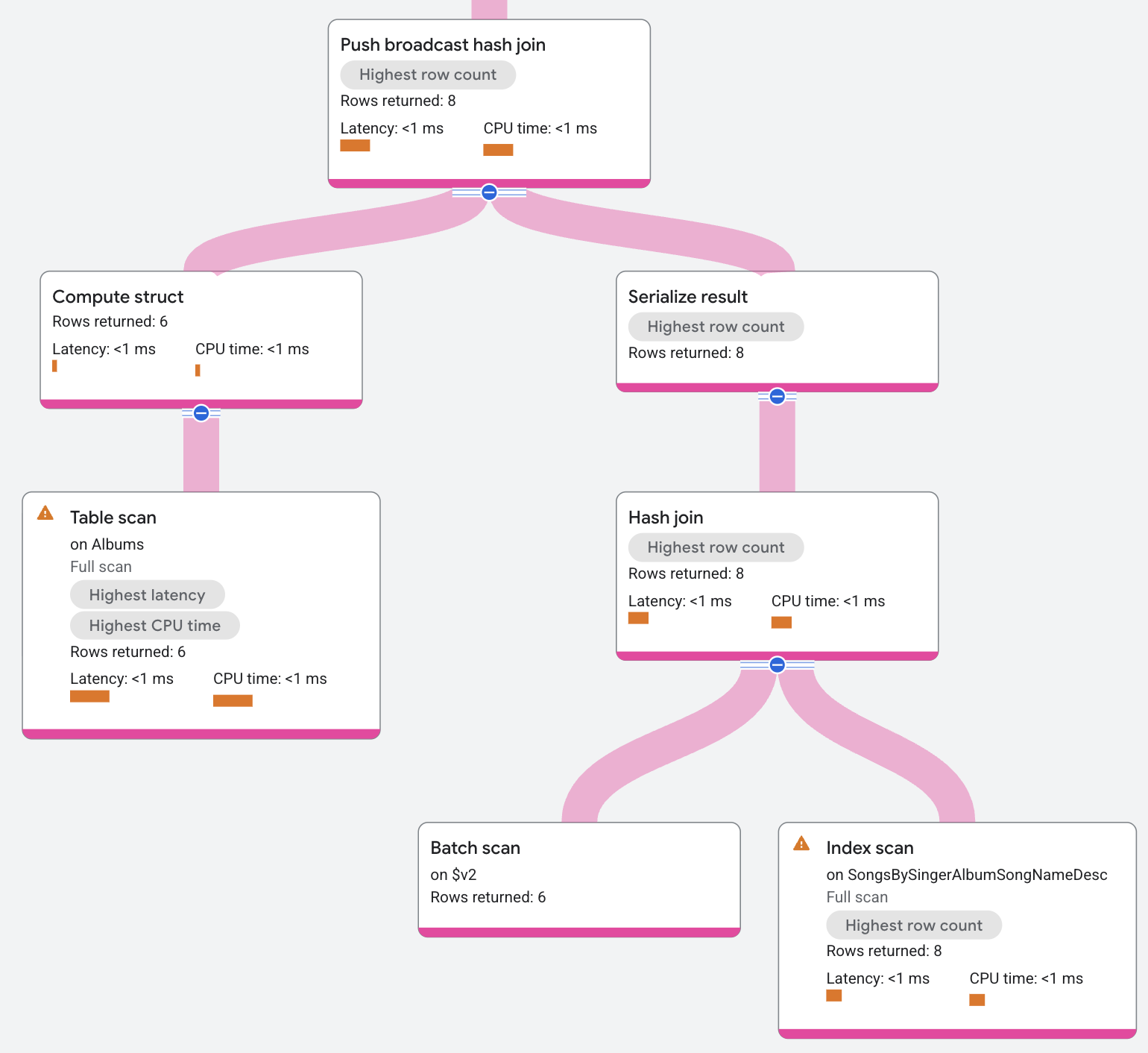
The input to the Push broadcast hash join is the AlbumsByAlbumTitle index.
The operator serializes that input into a batch of data. The operator sends that batch to all
the local splits of the index SongsBySingerAlbumSongNameDesc, where the operator deserializes the batch
and builds it into a hash table. The hash table then uses the
local index data as a probe returning resulting matches.
Resulting matches might also be filtered by a residual condition before they're returned. (An example of where residual conditions appear is in non-equality joins).
Properties and execution statistics
A property of an operator describes a trait that is used when the operator is executed. An execution statistic is a value collected during query execution to help you assess performance of the operator.
The Distributed apply operator has additional distinct execution statistics.Properties
| Name | Description |
|---|---|
| Execution method | In Row execution, the operator processes one row at a time. In Batch execution, the operator processes a batch of rows at once. |
Execution statistics
| Name | Description |
|---|---|
| Local parallel executions | The number of subqueries executed in parallel. |
| Remote calls | The number of remote subqueries executed. |
| Number of batches | A batch is a dynamic collection of rows that are processed at the same time. This shows the number of batches a distributed cross apply sent from the input to the map side. |
| Latency | Elapsed time of all the executions done in the operator. |
| Cumulative latency | The total time of the current operator and its descendants. |
| CPU time | Sum of CPU time spent executing the operator. |
| Cumulative CPU time | The total CPU time spent executing the operator and its descendants. |
| Execution time | The total amount of time taken to run the query and process results. |
| Rows returned | The number of rows output by this operator |
| Number of executions | The number of times the operator was executed. Some executions can run in parallel. |