
Verteilte Operatoren werden auf mehreren Servern ausgeführt, im Gegensatz zu Blatt-, unären, binären oder n-ären Operatoren.
Folgende verteilte Operatoren gibt es:
Datenbankschema
Die Abfragen und Ausführungspläne auf dieser Seite basieren auf dem folgenden Datenbankschema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Sie können die folgenden DML-Anweisungen (Data Manipulation Language) verwenden, um diesen Tabellen Daten hinzuzufügen:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Der Operator "Distributed Union" bildet die Basis, von der "Distributed Cross Apply" und "Distributed Outer Apply" abgeleitet werden.
Verteilte Operatoren treten in Ausführungsplänen mit einer Distributed Union-Variante über einer oder mehreren Local Distributed Union-Varianten auf. Eine "Distributed Union"-Variante führt die Remoteverteilung von Teilplänen durch.
Eine lokale Variante von „Distributed Union“ befindet sich über den einzelnen Scans, die für die Abfrage ausgeführt werden. Die lokalen Varianten von „Distributed Union“ sorgen für eine stabile Abfrageausführung, wenn Neustarts zum dynamischen Ändern von Split-Grenzen auftreten. Obwohl dieser Operator im visuellen Plan ausgeblendet ist, ist er immer vorhanden.
Wann immer es möglich ist, verwendet eine Variante von „Distributed Union“ ein geteiltes Prädikat für die Split-Bereinigung. Beim Split-Pruning führen die Remoteserver Teilpläne nur für die Splits aus, die das Prädikat erfüllen. Dadurch werden Latenz und Abfrageleistung verbessert.
Distributed Union
Der Operator Distributed Union teilt eine oder mehrere Tabellen konzeptionell in mehrere Splits auf, wertet eine Teilabfrage für jeden "Split" unabhängig aus und fasst dann alle Ergebnisse zusammen.
Die folgende Abfrage veranschaulicht diesen Operator:
SELECT s.songname,
s.songgenre
FROM songs AS s
WHERE s.singerid = 2
AND s.songgenre = 'ROCK';
/*-----------------+-----------+
| SongName | SongGenre |
+-----------------+-----------+
| Starting Again | ROCK |
| The Second Time | ROCK |
| Fight Story | ROCK |
+-----------------+-----------*/
Der Ausführungsplan sieht so aus:
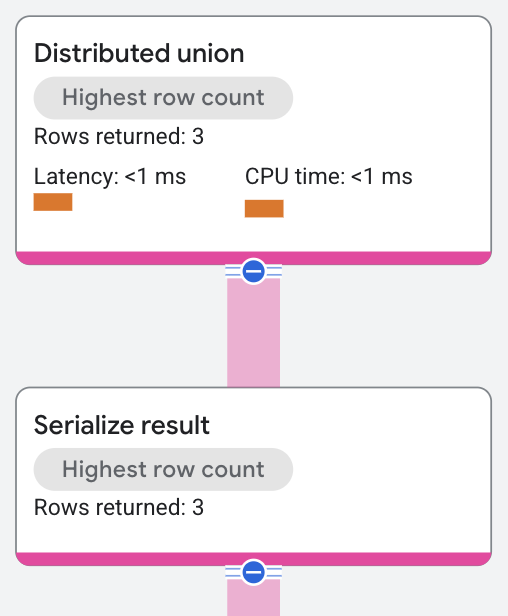
Der Operator "Distributed Union" sendet Teilpläne an die Remoteserver, die einen Tabellenscan der Splits ausführen, für die das Prädikat WHERE s.SingerId = 2 AND s.SongGenre = 'ROCK' erfüllt ist.
Der Operator Serialize Result berechnet die Werte SongName und SongGenre aus den Zeilen, die von den Tabellenscans zurückgegeben werden. Der Operator "Distributed Union" gibt dann die kombinierten Ergebnisse von den Remoteservern zurück, wenn die SQL-Abfrageergebnisse vorliegen.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Der Operator Distributed Union hat zusätzliche eindeutige Ausführungsstatistiken.Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Lokale parallele Ausführungen | Die Anzahl der parallel ausgeführten Unterabfragen. |
| Remote-Aufrufe | Die Anzahl der ausgeführten Remote-Unterabfragen. |
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Im Gegensatz zu „Cross Apply“-Ausführungen werden Ausführungen in der Regel parallel ausgeführt. Daher sind die Latenzzahlen für verteilte Operatoren kumulativ. Bei den meisten Operatoren wird dagegen angegeben, wie viel Latenz durch den jeweiligen Operator hinzugefügt wurde. Die Anzahl der Ausführungen in einer verteilten UNION basiert auf den Aufteilungsgrenzen der Tabelle, die wiederum von der Datengröße und ‑last abhängen und möglicherweise den Anweisungshinweis use_additional_parallelism enthalten. Dieser Ansatz für Statistiken gilt für alle verteilten Operatoren.
Distributed Apply
Der Operator Distributed Apply (DA) erweitert den Operator Apply Join durch die Ausführung auf verschiedenen Servern. Auf der Input-Seite werden Zeilen in Batches gruppiert, im Gegensatz zu einem regulären „Cross Apply“-Operator, der jeweils nur eine Eingabezeile behandelt. Auf der Map-Seite ist DA eine Gruppe von einfachen Apply-Join-Operatoren, die auf Remoteservern ausgeführt werden. Ein Distributed Apply-Join unterstützt dieselben Apply-Methoden wie ein Apply-Join.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Der Operator Distributed Apply hat zusätzliche eindeutige Ausführungsstatistiken.Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Lokale parallele Ausführungen | Die Anzahl der parallel ausgeführten Unterabfragen. |
| Remote-Aufrufe | Die Anzahl der ausgeführten Remote-Unterabfragen. |
| Anzahl der Batches | Ein Batch ist eine dynamische Sammlung von Zeilen, die gleichzeitig verarbeitet werden. Hier sehen Sie die Anzahl der Batches, die von der Eingabe an die Map-Seite gesendet wurden. |
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Distributed Cross Apply
Die folgende Abfrage veranschaulicht diesen Operator:
SELECT albumtitle
FROM songs
JOIN albums
ON albums.albumid = songs.albumid;
/*-----------------------+
| AlbumTitle |
+-----------------------+
| Green |
| Nothing To Do With Me |
| Play |
| Total Junk |
| Green |
+-----------------------*/
Der Ausführungsplan sieht so aus:
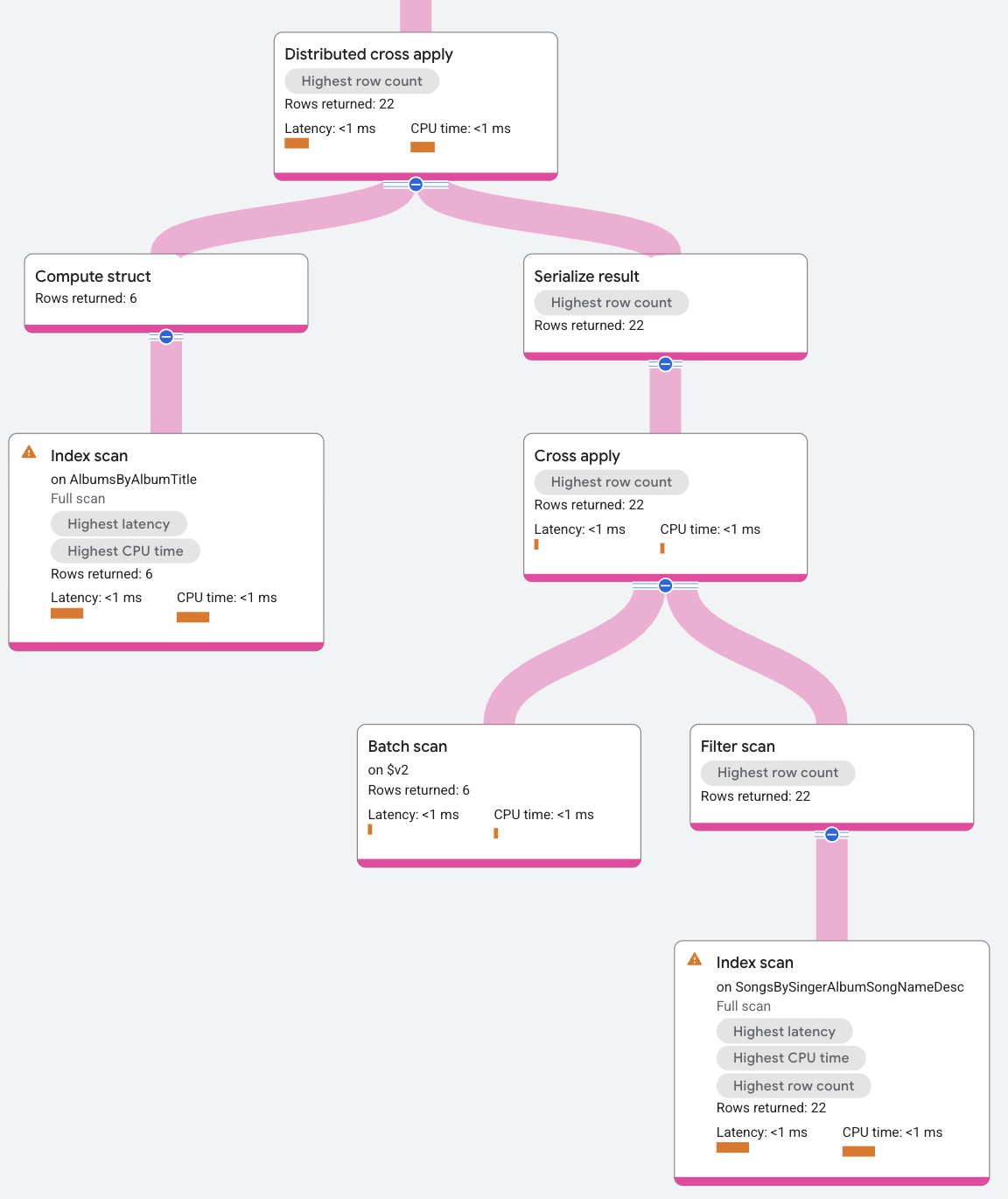
Der DCA-Eingang enthält einen Index-Scan auf dem Index SongsBySingerAlbumSongNameDesc, der Reihen von AlbumId stapelt. Die Map-Seite für den DCA ist ein standardmäßiger Cross Apply-Vorgang, bei dem die Eingabe ein Batch von Zeilen ist und die Map-Seite ein Indexscan des Index AlbumsByAlbumTitle ist. Dabei muss das Prädikat von AlbumId in der Eingabezeile mit dem Schlüssel AlbumId im Index AlbumsByAlbumTitle übereinstimmen. Die Zuordnung gibt den SongName für die SingerId-Werte in den zusammengeführten Eingabezeilen zurück.
Der DCA-Vorgang für dieses Beispiel im Überblick: Die Eingabedaten des DCA sind die zu Batches zusammengefassten Zeilen der Tabelle Albums und die Ausgabedaten ergeben sich aus der Anwendung dieser Zeilen auf die Zuordnung (Map) des Indexscans.
Distributed Outer Apply
Ein Distributed Outer Apply ist ein DA mit Left Outer Join-Semantik. Weitere Informationen zur Semantik finden Sie unter outer apply.
Die folgende Abfrage veranschaulicht diesen Operator:
SELECT lastname,
concertdate
FROM singers LEFT OUTER join@{JOIN_TYPE=APPLY_JOIN} concerts
ON singers.singerid=concerts.singerid;
/*----------+-------------+
| LastName | ConcertDate |
+----------+-------------+
| Trentor | 2014-02-18 |
| Smith | 2011-09-03 |
| Smith | 2010-06-06 |
| Lomond | 2005-04-30 |
| Martin | 2015-11-04 |
| Richards | |
+----------+-------------*/
Der Ausführungsplan sieht so aus:
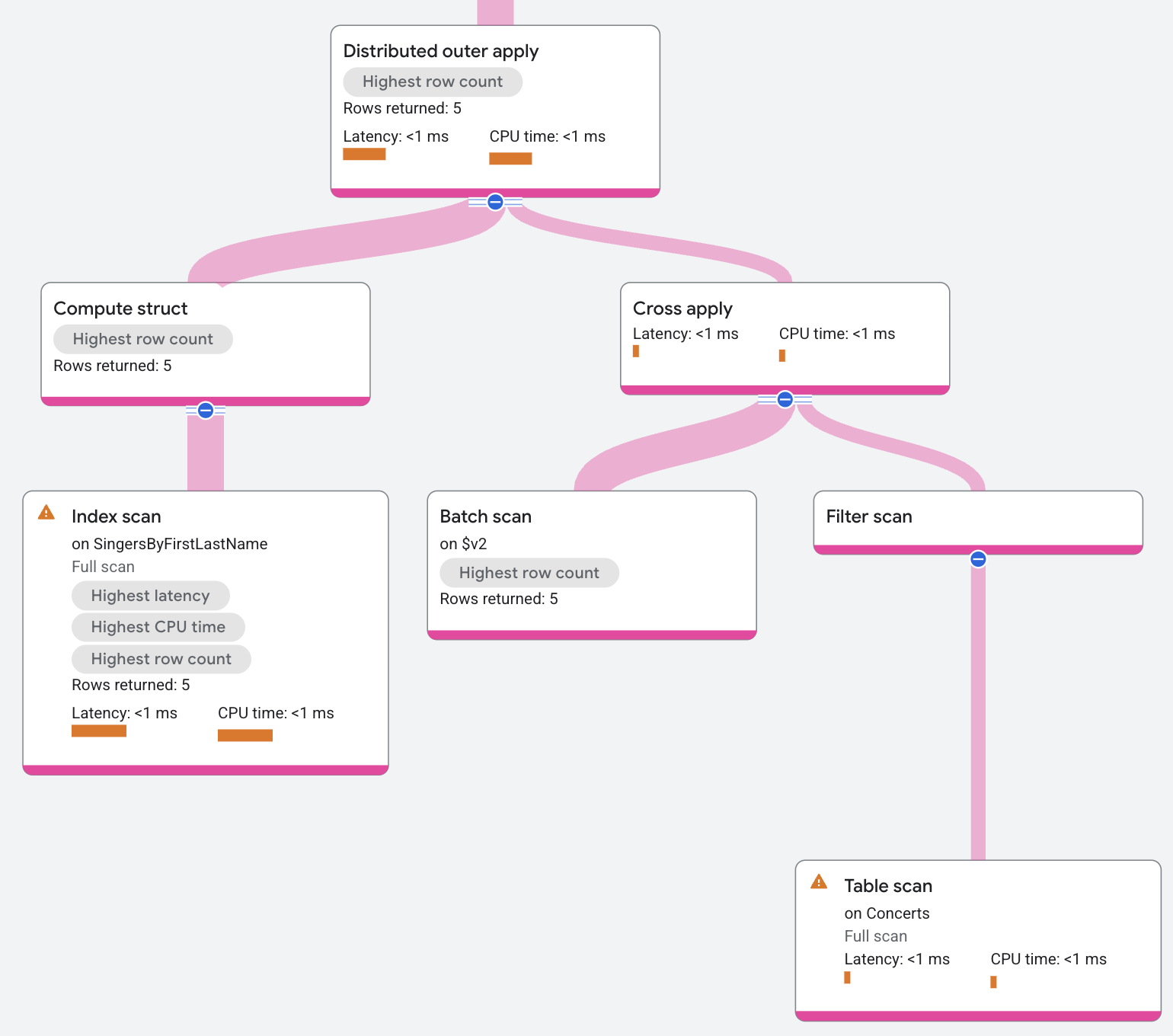
Distributed Semi Apply
Ein Distributed Semi Apply ist ein DA mit Semi-Join-Semantik. Weitere Informationen zur Semantik finden Sie unter semi apply.
Distributed Anti-Semi Apply
Ein Distributed Anti-Semi Apply ist ein DA mit Anti-Semi-Join-Semantik. Weitere Informationen zur Semantik finden Sie unter anti-semi apply.
Distributed Merge Union
Der Operator Distributed Merge Union verteilt eine Abfrage auf mehrere Remoteserver. Anschließend werden die Abfrageergebnisse kombiniert, um ein sortiertes Ergebnis zu erhalten, das als Distributed Merge Sort bezeichnet wird.
Bei einer verteilten Zusammenführung werden die folgenden Schritte ausgeführt:
Der Root-Server sendet eine Unterabfrage an jeden Remoteserver, auf dem ein Split der abgefragten Daten gehostet wird. Die Unterabfrage enthält Anweisungen, dass die Ergebnisse in einer bestimmten Reihenfolge sortiert werden.
Jeder Remoteserver führt die Unterabfrage für seinen Split aus und sendet die Ergebnisse dann in der angeforderten Reihenfolge zurück.
Der Stammserver führt die sortierte Unterabfrage zusammen, um ein vollständig sortiertes Ergebnis zu erhalten.
Distributed Merge-Union ist für Spanner-Version 3 und höher standardmäßig aktiviert.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Der Operator Distributed Apply hat zusätzliche eindeutige Ausführungsstatistiken.Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Lokale parallele Ausführungen | Die Anzahl der parallel ausgeführten Unterabfragen. |
| Remote-Aufrufe | Die Anzahl der ausgeführten Remote-Unterabfragen. |
| Anzahl der Batches | Ein Batch ist eine dynamische Sammlung von Zeilen, die gleichzeitig verarbeitet werden. Hier sehen Sie die Anzahl der Batches, die von der Eingabe an die Map-Seite gesendet wurden. |
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Push Broadcast Hash Join
Der Operator Push Broadcast Hash Join ist eine verteilte, Hash-Join-basierte Implementierung von SQL-Joins. Der Operator „Push Broadcast Hash Join” liest die Zeilen der Eingabeseite aus, um einen Datenbatch zu erstellen. Der Operator sendet diesen Batch an alle Server, die Map-Nebendaten enthalten. Auf den Zielservern, auf denen der Batch von Daten empfangen wird, erstellt der Operator einen Hash Join, wobei der Batch als Build-Nebendaten erstellt und die lokalen Daten dann als Probeseite des Hash Joins gescannt werden.
Push Broadcast Hash Join bietet folgende Vorteile:
- Wenn die Build-Tabelle klein ist, kann sie an alle Splits auf der Kartenseite gesendet werden.
- Die Karte kann mit oder ohne Restfilter gescannt werden. Das passiert, wenn die Join-Schlüssel nicht mit den Primärschlüsseln der Zuordnungstabelle übereinstimmen.
Push Broadcast Hash Join wird vom Optimierungstool nicht automatisch ausgewählt. Um diesen Operator zu verwenden, legen Sie die Join-Methode für den Abfragehinweis auf PUSH_BROADCAST_HASH_JOIN fest, wie im folgenden Beispiel gezeigt:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=push_broadcast_hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Der Ausführungsplan sieht so aus:
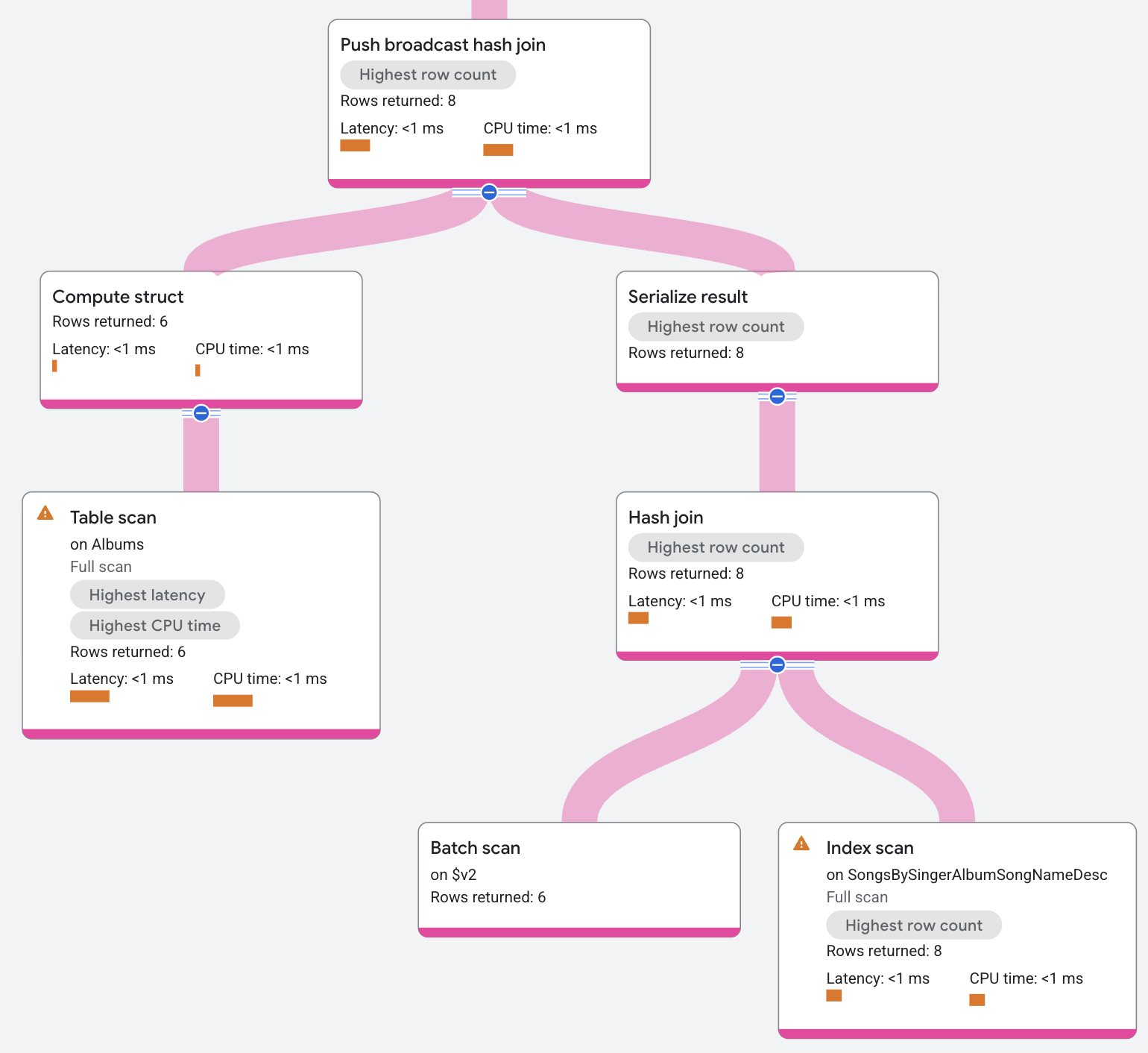
Die Eingabe für den Push Broadcast Hash Join ist der Index AlbumsByAlbumTitle.
Der Operator serialisiert diese Eingabe in einem Datenbatch. Der Operator sendet diesen Batch an alle lokalen Splits des Index SongsBySingerAlbumSongNameDesc, wo er den Batch deserialisiert und in eine Hashtabelle einfügt. Die Hashtabelle verwendet dann die lokalen Indexdaten als Prüfung, die resultierende Übereinstimmungen zurückgibt.
Resultierende Übereinstimmungen können auch durch eine Residualbedingung gefiltert werden, bevor sie zurückgegeben werden. Ein Beispiel für Residualbedingungen sind Non-Equality Joins.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Der Operator Distributed Apply hat zusätzliche eindeutige Ausführungsstatistiken.Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Lokale parallele Ausführungen | Die Anzahl der parallel ausgeführten Unterabfragen. |
| Remote-Aufrufe | Die Anzahl der ausgeführten Remote-Unterabfragen. |
| Anzahl der Batches | Ein Batch ist eine dynamische Sammlung von Zeilen, die gleichzeitig verarbeitet werden. Hier sehen Sie die Anzahl der Batches, die von der Eingabe an die Map-Seite gesendet wurden. |
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |