
Ein binärer Operator hat zwei untergeordnete relationale Elemente. Diese binären Operatoren gibt es:
Datenbankschema
Die Abfragen und Ausführungspläne auf dieser Seite basieren auf dem folgenden Datenbankschema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Sie können die folgenden DML-Anweisungen (Data Manipulation Language) verwenden, um diesen Tabellen Daten hinzuzufügen:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Apply Join
Ein Apply Join ist der primäre Join-Operator, der von Spanner verwendet wird. Apply-Join-Operatoren führen eine zeilenorientierte Verarbeitung durch, im Gegensatz zu Operatoren, die eine datensatzbasierte Verarbeitung ausführen, z. B. Hash Join. Der Operator „Apply“ hat zwei Eingaben: Input (linkes untergeordnetes Element) und Map (rechtes untergeordnetes Element). Der Apply-Operator wendet jede Zeile auf der Eingabeseite mithilfe einer Apply-Methode auf die Map-Seite an: Cross, Outer, Semi oder Anti-Semi. Außerdem wird auf der Kartenseite eines Distributed Apply eine Variante von Apply Join angezeigt.
Der Apply-Join-Operator ist am effizientesten, wenn Folgendes zutrifft:
- Die Kardinalität der Eingabe ist niedrig.
- Der Join-Schlüssel ist ein Präfix des Primärschlüssels auf der Map-Seite.
- In der Abfrage werden zwei verschränkte Tabellen verknüpft.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Cross Apply
Bei einem Cross Apply wird ein Inner Join ausgeführt, bei dem nur übereinstimmende Zeilen zurückgegeben werden.
Die folgende Abfrage veranschaulicht diesen Operator:
In der Abfrage wird der Vorname jedes Sängers zusammen mit dem Namen nur eines seiner Songs angefordert.
SELECT si.firstname,
(SELECT so.songname
FROM songs AS so
WHERE so.singerid = si.singerid
LIMIT 1)
FROM singers AS si;
/*-----------+--------------------------+
| FirstName | Unspecified |
+-----------+--------------------------+
| Alice | Not About The Guitar |
| Catalina | Let's Get Back Together |
| David | NULL |
| Lea | NULL |
| Marc | NULL |
+-----------+--------------------------*/
Die erste Spalte wird mit Werten aus der Tabelle Singers und die zweite mit Werten aus der Tabelle Songs gefüllt. In den Fällen, in denen eine SingerId in der Tabelle Singers vorhanden war, aber keine übereinstimmende SingerId in der Tabelle Songs gefunden werden konnte, enthält die zweite Spalte NULL.
Der Ausführungsplan beginnt so:
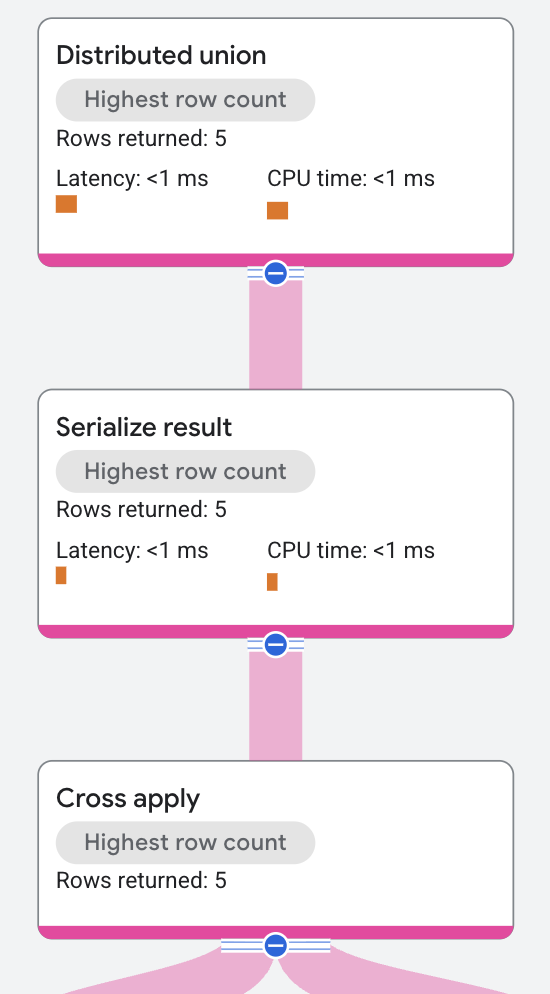
Der übergeordnete Knoten ist der Operator Distributed Union. Der Operator „Distributed Union“ verteilt Teilpläne an Remoteserver. Der Teilplan enthält den Operator Serialize Result, der den Vornamen des Interpreten und den Namen eines Titels des Interpreten berechnet und jede Ausgabezeile serialisiert.
Der Operator "Serialize Result" erhält seine Eingabe vom Operator "Cross Apply".
Die Eingabeseite für den Operator "Cross Apply" stammt aus einem Scan der Tabelle Singers.
Der Ausführungsplan wird so fortgesetzt:
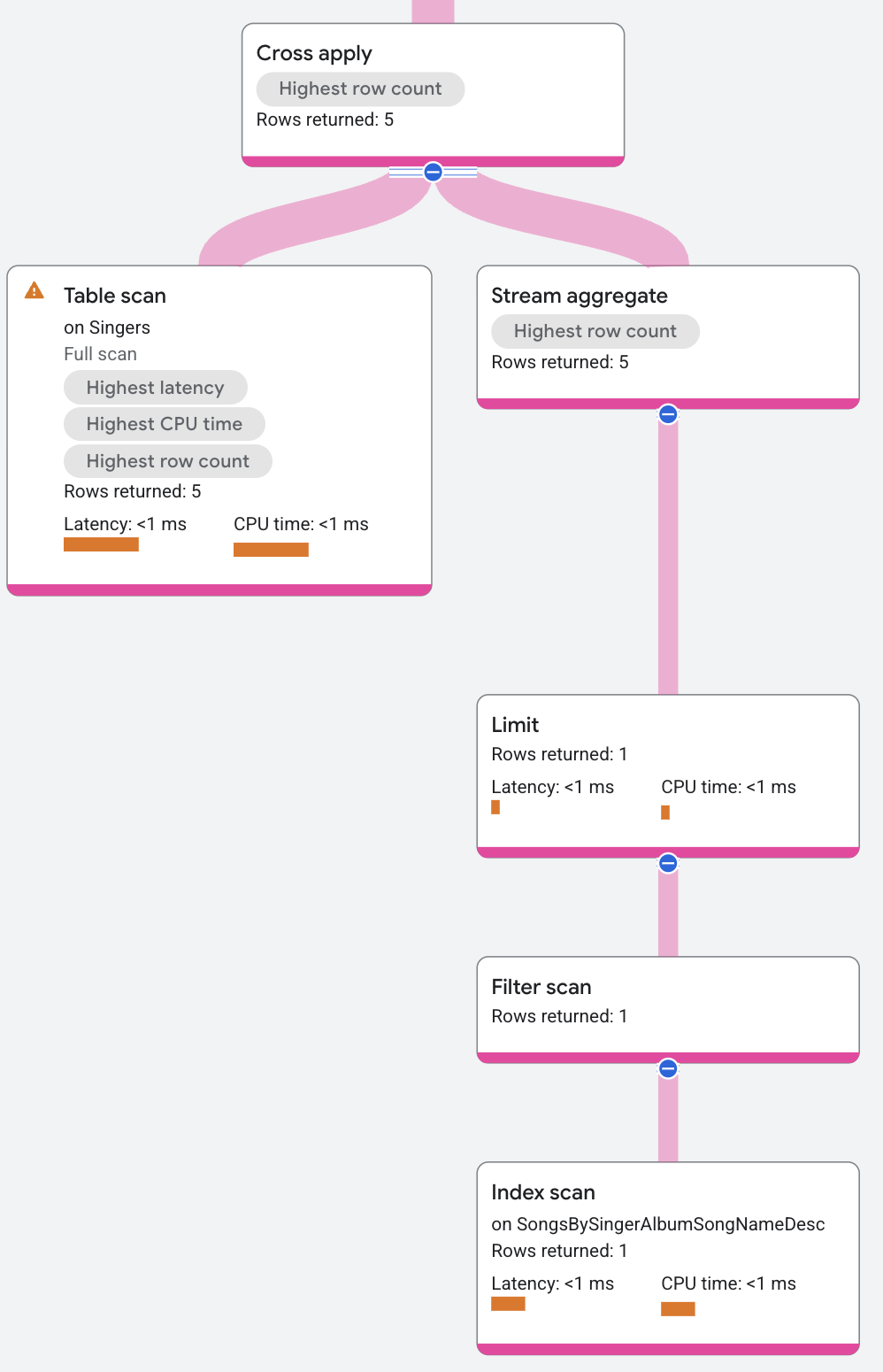
Die Eingabedaten unter Map für den Operator "Cross Apply" enthalten (von oben nach unten):
- Den Operator Aggregate, der
Songs.SongNamezurückgibt - den Operator "Limit", der die Anzahl der zurückgegebenen Titel je Interpret begrenzt
- Einen Indexscan des Index
SongsBySingerAlbumSongNameDesc
Der Operator "Cross Apply" ordnet jede von Input erhaltene Zeile den von Map erhaltenen Zeilen mit derselben SingerId zu. Die Ausgabe des Operators "Cross Apply" setzt sich aus dem Wert FirstName aus der Eingabezeile von Input und dem Wert SongName aus der Eingabezeile von Map zusammen.
Der Wert SongName lautet NULL, wenn es unter Map keine Zeile gibt, die der SingerId entspricht. Der im Ausführungsplan übergeordnete Operator "Distributed Union" fasst dann alle Ausgabezeilen von den Remoteservern zusammen und gibt sie als Abfrageergebnisse zurück.
Outer Apply
Ein Outer Apply-Vorgang bietet die Semantik für Left Outer Join. Damit wird sichergestellt, dass bei jeder Ausführung auf der Map-Seite mindestens eine Zeile zurückgegeben wird, wobei bei Bedarf eine mit Nullen aufgefüllte Zeile erstellt wird.
Semi Apply
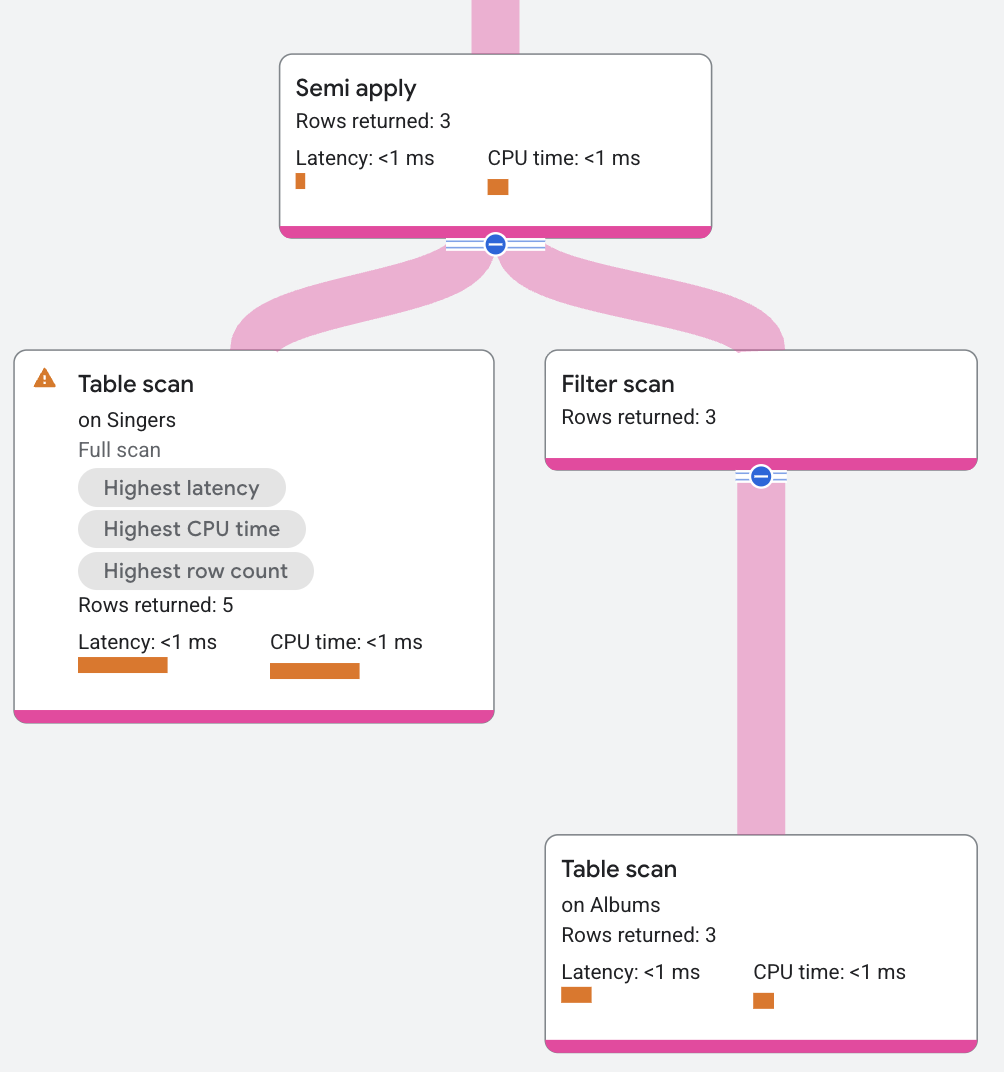
Der Operator Semi Apply gibt Eingabespalten nur zurück, wenn auf der Map-Seite eine Übereinstimmung auftritt.
Die folgende Abfrage verwendet einen Semi-Join, um herauszufinden, welche Sänger ein Album haben:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| Marc | Richards |
| Catalina | Smith |
| Alice | Trentor |
| Lea | Martin |
+-----------+----------*/
Das Plansegment sieht so aus:
Anti-Semi-Apply
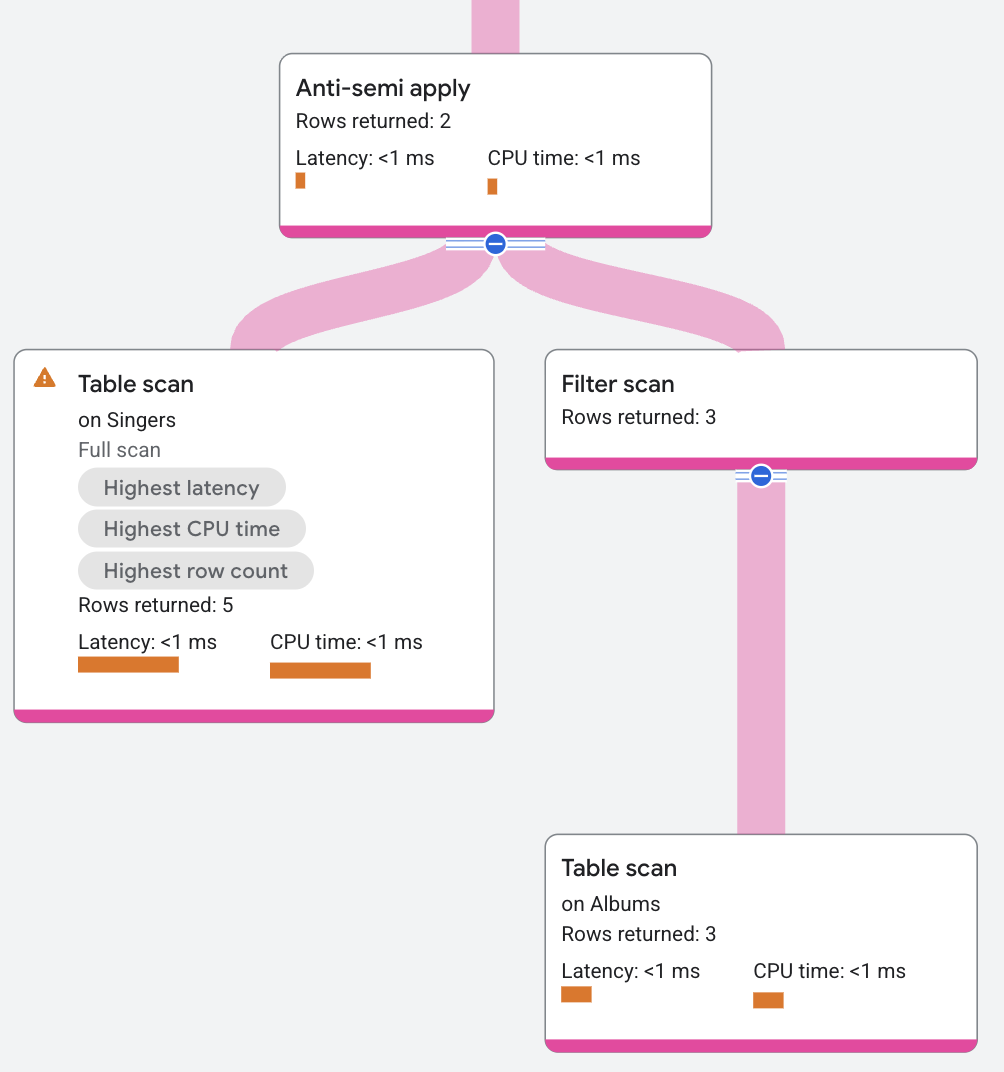
Der Operator Anti-Semi Apply ähnelt dem Operator Semi Apply. Er gibt jedoch die Spalten der Eingabetabelle nur zurück, wenn auf der Map-Seite keine Übereinstimmung gefunden wird.
Die folgende Abfrage verwendet einen Anti-Semi-Join, um herauszufinden, welche Sänger kein Album haben:
SELECT
FirstName,
LastName
FROM
Singers
WHERE
SingerId NOT IN (
SELECT
SingerId
FROM
Albums);
/*-----------+----------+
| FirstName | LastName |
+-----------+----------+
| David | Lomond |
+-----------+----------*/
Das Plansegment sieht so aus:
Hash Join
Der Operator Hash Join ist eine hashbasierte Implementierung von SQL-Join. Hash Joins führen eine setbasierte Verarbeitung aus. Der Operator „Hash Join“ liest die als Build markierten Eingabezeilen (linkes untergeordnetes Element) aus und fügt sie basierend auf einer Join-Bedingung in eine Hashtabelle ein. Der Operator „Hash Join“ liest dann die als Probe markierten Eingabezeilen aus (rechtes untergeordnetes Element). Für jede Zeile, die der Operator „Hash Join“ aus der „Probe“-Eingabe ausliest, sucht er nach übereinstimmenden Zeilen in der Hash-Tabelle. Der Operator „Hash Join“ gibt die übereinstimmenden Zeilen als Ergebnis zurück.
Hash-Join bietet folgende Vorteile:
- Die Eingaben müssen nicht sortiert sein.
- Beim Erstellen der Hashtabelle wird ein Bloom-Filter berechnet. Mit dem Operator werden Zeilen auf der Probeseite ausgeschlossen, die keine Übereinstimmungen haben. Beachten Sie, dass es sich hierbei um einen Residualfilter und nicht um einen Suchfilter handelt.
Die folgende Abfrage veranschaulicht diesen Operator:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=hash_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Das Segment des Ausführungsplans sieht so aus:
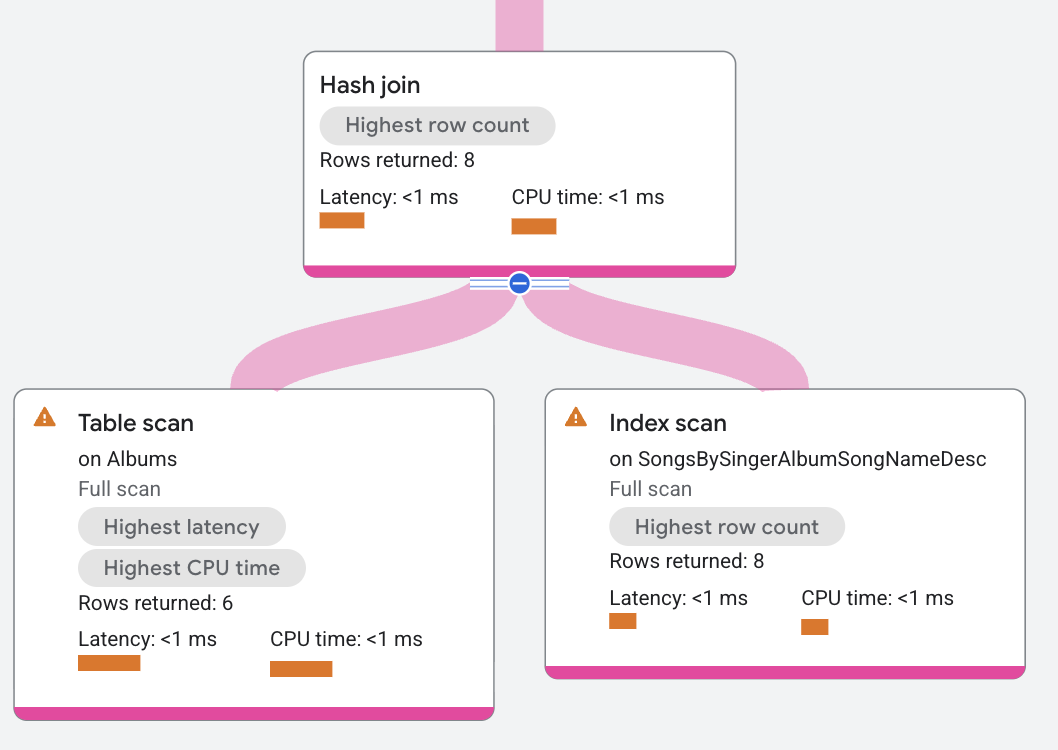
Im Ausführungsplan ist Build ein Operator des Typs Distributed Union, der Scans auf die Tabelle Albums verteilt. Probe ist ein Operator des Typs Distributed Union, der Scans auf dem Index SongsBySingerAlbumSongNameDesc verteilt.
Der Operator „Hash Join” liest alle Zeilen unter „Build” aus. Jede „Build”-Zeile wird basierend auf den Spalten der Bedingung a.SingerId =
s.SingerId AND a.AlbumId = s.AlbumId in einer Hashtabelle abgelegt. Als Nächstes liest der Operator „Hash Join” alle Zeilen unter „Probe” aus. Der Operator „Hash Join” sucht für jede „Probe”-Zeile nach Übereinstimmungen mit der Hashtabelle. Die resultierenden Übereinstimmungen werden vom Operator „Hash Join” zurückgegeben.
Resultierende Übereinstimmungen in der Hashtabelle können auch durch eine Residualbedingung gefiltert werden, bevor sie zurückgegeben werden. Ein Beispiel für Residualbedingungen sind Non-Equality Joins. Hash Join-Ausführungspläne können aufgrund von Speicherverwaltung und Join-Varianten komplex sein. Der Hauptalgorithmus eines Hash Join ist auf die Verarbeitung von Inner-, Semi-, Anti- und Outer Join-Varianten ausgelegt.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Merge join
Der Operator Merge Join ist eine zusammengeführte Implementierung des SQL Join. Beide Seiten des Joins erzeugen Zeilen, die nach den Spalten sortiert sind, die in der Join-Bedingung verwendet werden. Der Merge Join verarbeitet beide Eingabestreams gleichzeitig und gibt Zeilen aus, wenn die Join-Bedingung erfüllt ist. Wenn die Eingaben nicht sortiert sind, fügt das Optimierungstool dem Plan explizite Sort-Operatoren hinzu.
Merge Join bietet folgende Vorteile:
- Wenn die Daten bereits sortiert sind, ist kein Arbeitsspeicher erforderlich.
- Auch wenn die Daten nicht sortiert sind, kann bei einem verteilten Join die Sortierung für jeden einzelnen Split durchgeführt werden, anstatt eine große Hashtabelle im Stamm zu erstellen.
Merge Join wird vom Optimierungstool nicht automatisch ausgewählt. Um diesen Operator zu verwenden, setzen Sie die Join-Methode im Abfragehinweis auf MERGE_JOIN, wie im folgenden Beispiel gezeigt:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.singerid = s.singerid
AND a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
| Nothing To Do With Me | Not About The Guitar |
+-----------------------+--------------------------*/
Der Ausführungsplan sieht so aus:
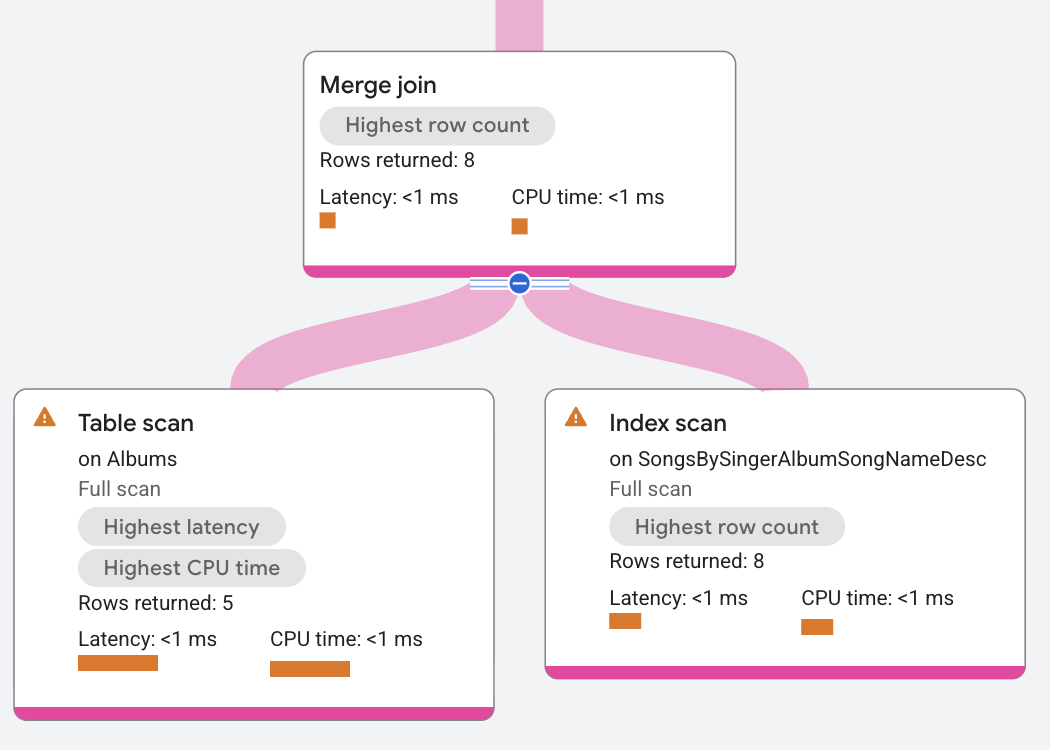
In diesem Ausführungsplan wird der Merge Join verteilt, sodass der Join an der Stelle ausgeführt wird, an der sich die Daten befinden. Dadurch kann der Merge Join in diesem Beispiel ohne zusätzliche Sortieroperatoren ausgeführt werden, da beide Tabellenscans bereits nach SingerId, AlbumId, der Join-Bedingung, sortiert sind. In diesem Plan wird der linke Scan der Tabelle Albums immer dann ausgeführt, wenn deren SingerId, AlbumId kleiner ist als die Werte SingerId_1, AlbumId_1 des rechten Scans. Ebenso wird der rechte Scan fortgesetzt, wenn seine Werte kleiner als die Werte des linken Scans sind. Bei dieser Zusammenführung wird weiterhin nach Äquivalenzen gesucht, um übereinstimmende Zeilen zurückzugeben.
Betrachten Sie ein weiteres Beispiel für einen Merge Join mit der folgenden Abfrage:
SELECT a.albumtitle,
s.songname
FROM albums AS a join@{join_method=merge_join} songs AS s
ON a.albumid = s.albumid;
/*-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Total Junk | The Second Time |
| Total Junk | Starting Again |
| Total Junk | Nothing Is The Same |
| Total Junk | Let's Get Back Together |
| Total Junk | I Knew You Were Magic |
| Total Junk | Blue |
| Total Junk | 42 |
| Total Junk | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Green | Not About The Guitar |
| Nothing To Do With Me | The Second Time |
| Nothing To Do With Me | Starting Again |
| Nothing To Do With Me | Nothing Is The Same |
| Nothing To Do With Me | Let's Get Back Together |
| Nothing To Do With Me | I Knew You Were Magic |
| Nothing To Do With Me | Blue |
| Nothing To Do With Me | 42 |
| Nothing To Do With Me | Not About The Guitar |
| Play | The Second Time |
| Play | Starting Again |
| Play | Nothing Is The Same |
| Play | Let's Get Back Together |
| Play | I Knew You Were Magic |
| Play | Blue |
| Play | 42 |
| Play | Not About The Guitar |
| Terrified | Fight Story |
+-----------------------+--------------------------*/
Der Ausführungsplan sieht so aus:
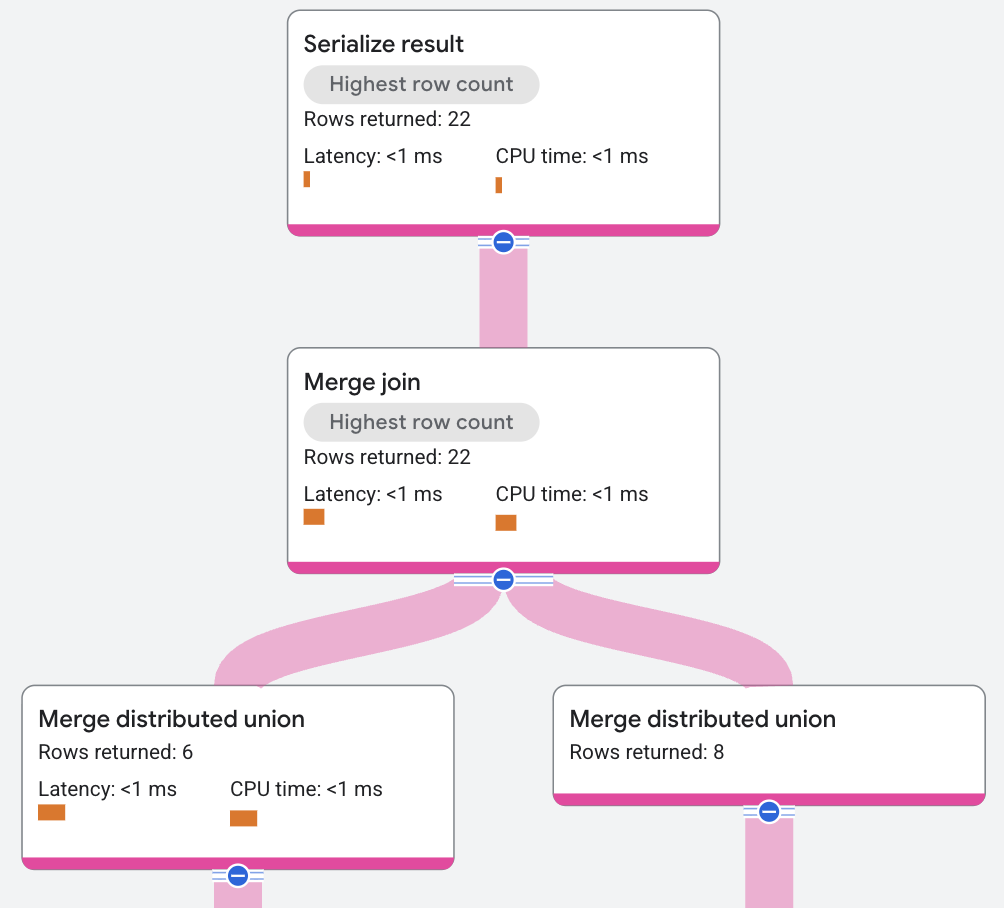
Im vorherigen Ausführungsplan hat das Abfrageoptimierungstool zusätzliche Sortieroperatoren eingeführt, um den Merge Join auszuführen. Die Bedingung JOIN in der Beispielabfrage bezieht sich nur auf AlbumId, wodurch die Daten nicht gespeichert werden. Daher muss eine Sortierung hinzugefügt werden. Die Abfrage-Engine unterstützt einen Algorithmus für verteiltes Zusammenführen, wodurch die Sortierung lokal und nicht global erfolgen kann und die CPU-Kosten verteilt und parallelisiert werden.
Die resultierenden Übereinstimmungen können auch durch eine Residualbedingung gefiltert werden. Ein Beispiel für Residualbedingungen sind Non-Equality Joins. Aufgrund von zusätzlichen Sortieranforderungen können die Merge-Join-Ausführungspläne sehr komplex sein. Der Hauptalgorithmus eines Merge Join verarbeitet Inner-, Semi-, Anti- und Outer Join-Varianten.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |
Rekursive Vereinigung
Mit dem Operator Recursive Union werden zwei Eingaben zusammengeführt: eine für den base-Fall und eine für den recursive-Fall. Sie wird in Diagrammabfragen mit quantifizierten Pfaddurchläufen verwendet. Die Basiseingabe wird zuerst und genau einmal verarbeitet. Die rekursive Eingabe wird verarbeitet, bis die Rekursion beendet wird. Die Rekursion wird beendet, wenn die Obergrenze (falls angegeben) erreicht ist oder wenn die Rekursion keine neuen Ergebnisse liefert. Im folgenden Beispiel wird die Tabelle Collaborations dem Schema hinzugefügt und ein Eigenschaftsgraph mit dem Namen MusicGraph erstellt.
CREATE TABLE Collaborations (
SingerId INT64 NOT NULL,
FeaturingSingerId INT64 NOT NULL,
AlbumTitle STRING(MAX) NOT NULL,
) PRIMARY KEY(SingerId, FeaturingSingerId, AlbumTitle);
CREATE OR REPLACE PROPERTY GRAPH MusicGraph
NODE TABLES(
Singers
KEY(SingerId)
LABEL Singers PROPERTIES(
BirthDate,
FirstName,
LastName,
SingerId,
SingerInfo)
)
EDGE TABLES(
Collaborations AS CollabWith
KEY(SingerId, FeaturingSingerId, AlbumTitle)
SOURCE KEY(SingerId) REFERENCES Singers(SingerId)
DESTINATION KEY(FeaturingSingerId) REFERENCES Singers(SingerId)
LABEL CollabWith PROPERTIES(
AlbumTitle,
FeaturingSingerId,
SingerId),
);
Mit der folgenden Graphabfrage werden Sänger gefunden, die mit einem bestimmten Sänger oder mit dessen Mitarbeitern zusammengearbeitet haben.
GRAPH MusicGraph
MATCH (singer:Singers {singerId:42})-[c:CollabWith]->{1,2}(featured:Singers)
RETURN singer.SingerId AS singer, featured.SingerId AS featured
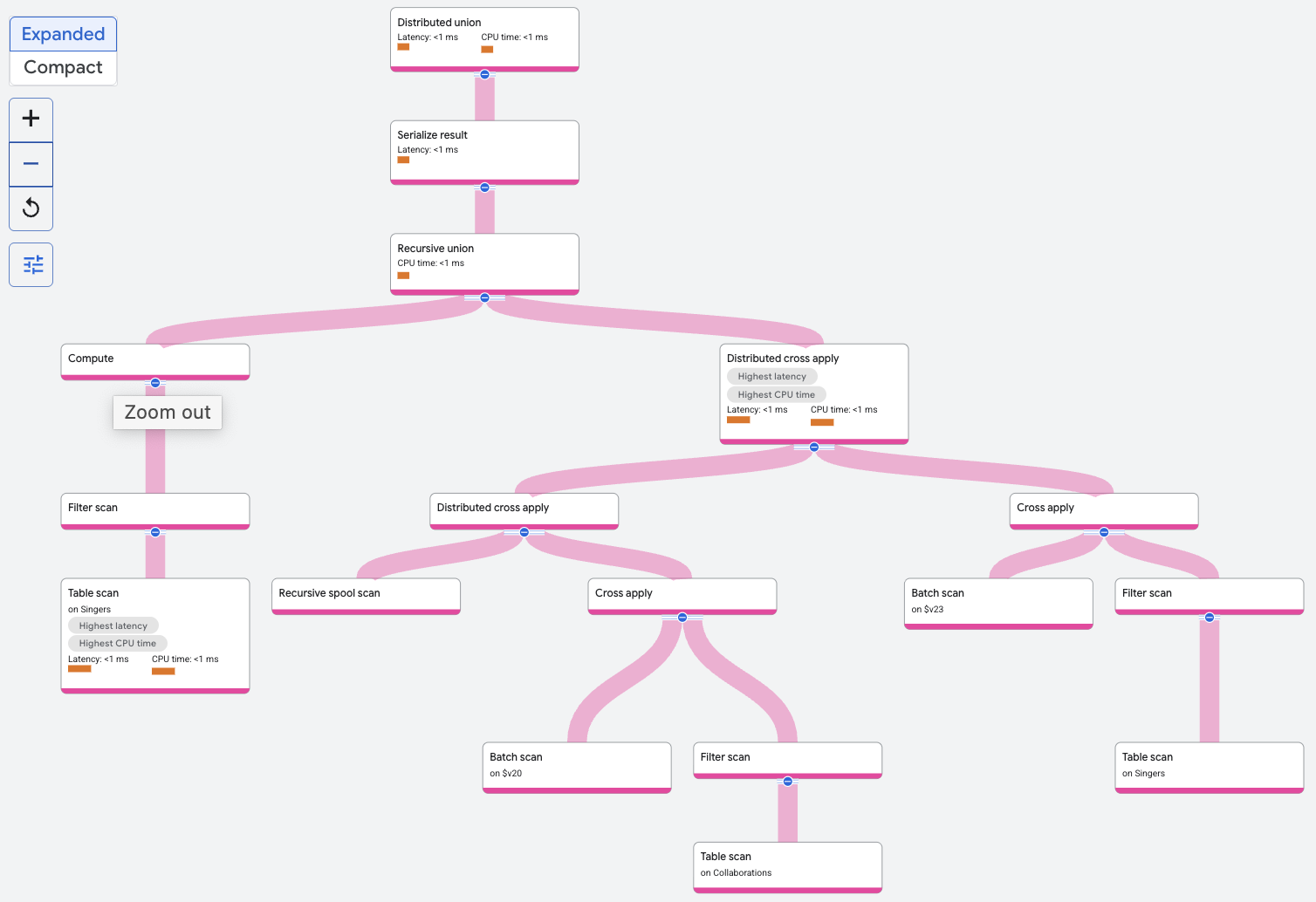
Der Operator Recursive Union filtert die Tabelle Singers, um den Sänger mit der angegebenen SingerId zu finden. Dies ist die Basiseingabe für die rekursive Union. Die rekursive Eingabe für die rekursive UNION besteht aus einem Distributed Cross Apply- oder einem anderen Join-Operator für andere Abfragen, bei denen die Collaborations-Tabelle wiederholt mit den Ergebnissen der vorherigen Iteration des Joins verknüpft wird. Die Zeilen aus der Basiseingabe bilden die nullte Iteration.
Bei jeder Iteration wird die Ausgabe der Iteration durch den rekursiven Spool-Scan gespeichert. Zeilen aus dem rekursiven Spool-Scan werden mit der Tabelle Collaborations über spoolscan.featuredSingerId = Collaborations.SingerId verknüpft. Die Rekursion wird nach zwei Iterationen beendet, da dies die in der Abfrage angegebene Obergrenze ist.
Attribute und Ausführungsstatistiken
Eine Eigenschaft eines Operators beschreibt ein Merkmal, das bei der Ausführung des Operators verwendet wird. Eine Ausführungsstatistik ist ein Wert, der während der Ausführung einer Abfrage erfasst wird, um die Leistung des Operators zu bewerten.
Eigenschaften
| Name | Beschreibung |
|---|---|
| Ausführungsmethode | Bei der zeilenweisen Ausführung verarbeitet der Operator jeweils eine Zeile. Bei der Batchausführung verarbeitet der Operator einen Batch von Zeilen gleichzeitig. |
Ausführungsstatistiken
| Name | Beschreibung |
|---|---|
| Latenz | Verstrichene Zeit aller Ausführungen im Operator. |
| Kumulative Latenz | Die Gesamtzeit des aktuellen Operators und seiner untergeordneten Elemente. |
| CPU-Zeit | Summe der CPU-Zeit, die für die Ausführung des Operators aufgewendet wurde. |
| Kumulative CPU-Zeit | Die gesamte CPU-Zeit, die für die Ausführung des Operators und seiner untergeordneten Elemente aufgewendet wurde. |
| Ausführungszeit | Die Gesamtzeit, die zum Ausführen der Abfrage und zum Verarbeiten der Ergebnisse benötigt wurde. |
| Zurückgegebene Zeilen | Die Anzahl der Zeilen, die von diesem Operator ausgegeben werden |
| Anzahl der Ausführungen | Gibt an, wie oft der Operator ausgeführt wurde. Einige Ausführungen können parallel ausgeführt werden. |