
本頁說明在 Spanner 中實作多租戶的各種方式。此外,也會討論資料管理模式和租戶生命週期管理。本文適用於資料庫架構師、資料架構師和工程師,他們在 Spanner 上實作多租戶應用程式,並將 Spanner 做為關聯式資料庫。並根據該情境,列出儲存多租戶資料的各種方法。本文中會交替使用「租戶」、「客戶」和「機構」等詞彙,表示存取多租戶應用程式的實體。本頁提供的範例是以人力資源 (HR) SaaS 供應商在 Google Cloud上實作多租戶應用程式為基礎。其中一項需求是,多位 HR SaaS 供應商的客戶必須存取多租戶應用程式。這些顧客稱為租戶。
多用戶群架構
多租戶是指軟體應用程式的單一或少數幾個執行個體,為多個租戶或客戶提供服務。這個軟體模式可從單一租戶或客戶擴充至數百或數千個。這種做法是雲端運算平台的基本做法,因為多個機構會共用基礎架構。
您可以將多租戶視為一種根據共用運算資源 (例如資料庫) 進行分區的形式。以公寓大樓的租戶為例:租戶共用基礎架構,例如水管和電線,但每位租戶都有專屬的公寓空間。多租戶是大多數 (如果不是全部) 軟體即服務 (SaaS) 應用程式的一部分。
Spanner 是全代管、企業級、分散式且一致的資料庫,結合了關聯資料庫模型的優點和非關聯水平擴充性。 Google CloudSpanner 具有關聯語意,包括結構定義、強制執行的資料型別、同步一致性、多重陳述式 ACID 交易,以及實作 ANSI 2011 SQL 的 SQL 查詢語言。 這項服務可確保定期維護或區域故障時不會停機,並提供可用性達 99.999%的服務水準協議。 Spanner 也提供高可用性和擴充性,支援現代多租戶應用程式。
租戶資料對應條件的條件
在多租戶應用程式中,每個租戶的資料都會透過基礎 Spanner 資料庫的其中一種架構方法隔離。以下列出將租戶資料對應至 Spanner 的不同架構方法:
- 執行個體:每個租戶都只會位於一個 Spanner 執行個體中,且該執行個體只會有一個資料庫供該租戶使用。
- 資料庫:租戶位於單一 Spanner 執行個體中的資料庫,該執行個體包含多個資料庫。
- 資料表:租戶位於資料庫內的專屬資料表,且多個租戶可位於同一個資料庫。
- 資料列:租戶資料是資料庫資料表中的資料列。這些表格會與其他租戶共用。
上述條件稱為資料管理模式,詳情請參閱「多租戶資料管理模式」一節。討論內容會依據下列條件:
- 資料隔離:多個租戶之間的資料隔離程度是多租戶技術的主要考量因素。舉例來說,資料是否需要實體或邏輯上的區隔,以及是否可為每個房客的資料設定獨立的存取控制清單 (ACL)。隔離作業取決於其他類別下所選的條件。舉例來說,某些法規和法規遵循要求可能會規定更高的隔離程度。
- 靈活度:租戶可輕鬆執行上線和下線活動,例如建立執行個體、資料庫、資料表或資料列。
- 作業:實作一般、租戶專屬資料庫作業和管理活動的可用性或複雜度。例如定期維護、記錄、備份或災難復原作業。
- 擴充性:可順暢擴充,因應未來成長需求。每個模式的說明都包含模式可支援的租戶人數。
- 效能:
- 資源隔離:能夠為每個租戶分配專屬資源、解決鄰近干擾現象,並為每個租戶提供可預測的讀取和寫入效能。
- 每個租戶的最低資源數:每個租戶的平均最低資源數。這不一定代表您需要為每位房客支付至少這個金額,而是所有 N 位房客加起來的總金額至少要達到 N * 這個金額。
- 資源效率:可使用其他房客的閒置資源,節省整體成本。
- 選擇位置以最佳化延遲時間:為每個租戶選擇特定複製拓撲,讓每個租戶的資料都能放在最適合該租戶的位置,以獲得最佳延遲時間。
- 法規和法規遵循:可滿足高度監管產業和國家/地區的要求,這些產業和國家/地區需要完全隔離資源和維護作業。舉例來說,法國的資料落地規定要求個人識別資訊只能儲存在法國境內。金融業通常需要客戶自行管理的加密金鑰 (CMEK),且每個租戶可能想使用自己的加密金鑰。
下一節將詳細說明與這些條件相關的各項資料管理模式。為特定租戶組合選取資料管理模式時,請使用相同條件。
多租戶資料管理模式
以下各節說明四種主要的資料管理模式:執行個體、資料庫、表格和資料列。
執行個體
為提供完整的隔離功能,執行個體資料管理模式會將每個租戶的資料儲存在各自的 Spanner 執行個體和資料庫中。一個 Spanner 執行個體可以有一或多個資料庫。在這個模式中,只會建立一個資料庫。以稍早討論的人資應用程式為例,每個客戶機構都會建立一個資料庫,並使用個別的 Spanner 執行個體。
如下圖所示,資料管理模式的每個執行個體都有一個租戶。
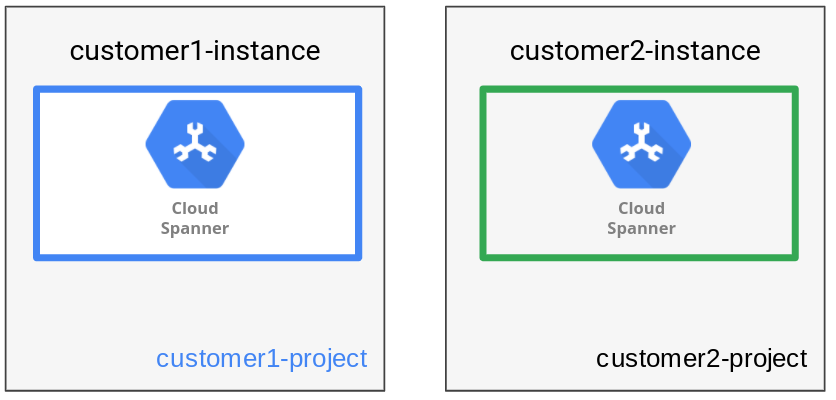
為每個房客提供個別執行個體,可使用個別Google Cloud 專案,為不同房客建立個別信任範圍。另一項優點是,您可以根據每個租戶的位置 (單一區域或多區域),選擇每個執行個體設定,進而提升位置彈性和效能。
這項架構可擴充至任意數量的租戶。SaaS 供應商可在所需區域建立任意數量的執行個體,不受任何硬性限制。
下表列出執行個體資料管理模式對不同條件的影響。
| 條件 | 執行個體:每個執行個體資料管理模式一個租戶 |
|---|---|
| 資料隔離 |
|
| 靈活性 |
|
| 作業 |
|
| 規模 |
|
| 效能 |
|
| 法規遵循需求 |
|
總而言之,主要重點如下:
- 優點:隔離程度最高
- 缺點:管理作業負擔最大,且由於每個房客至少需要 100 個 PU,因此成本可能較高。不支援跨租戶共用資源。
執行個體資料管理模式最適合下列情境:
- 不同房客分布在廣泛的區域,需要本地化解決方案。
- 部分租戶的法規和法規遵循要求,需要更高層級的安全性和稽核通訊協定。
- 租戶規模差異極大,因此在高流量、高流量租戶之間共用資源,可能會導致爭用和相互效能降低。
資料庫
在資料庫資料管理模式中,每個租戶都位於單一 Spanner 執行個體內的資料庫。單一執行個體可以包含多個資料庫。如果一個執行個體無法容納所有租戶,請建立多個執行個體。這個模式表示多個租戶共用單一 Spanner 執行個體。
每個執行個體最多只能有 100 個資料庫,這是 Spanner 的硬性限制。也就是說,如果 SaaS 供應商需要擴充超過 100 位客戶,就必須建立及使用多個 Spanner 執行個體。
以人力資源應用程式為例,SaaS 供應商會在 Spanner 執行個體中,為每個租戶建立及管理個別資料庫。
如下圖所示,資料管理模式的每個資料庫都有一個租戶。
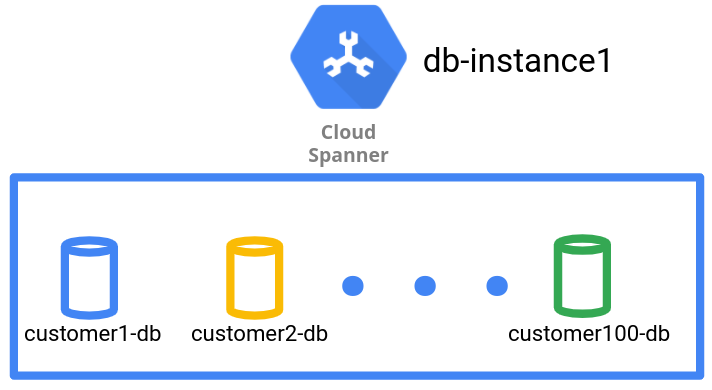
資料庫資料管理模式可在資料庫層級,為不同租戶的資料實現邏輯隔離。不過,由於這是單一 Spanner 執行個體,除非使用地理區域分區功能,否則所有租戶資料庫都會共用相同的複製拓撲,以及底層的運算和儲存空間設定。您可以使用 Spanner 地理區域分區功能,在不同位置建立執行個體分區,並在同一執行個體中,為不同資料庫使用不同執行個體分區。
下表概述資料庫資料管理模式對不同條件的影響。
| 條件 | 資料庫 — 每個資料庫資料管理模式一個租戶 |
|---|---|
| 資料隔離 |
|
| 靈活性 |
|
| 作業 |
|
| 擴充 |
|
| 效能 |
|
| 法規遵循需求 |
|
總而言之,主要重點如下:
- 優點:資料和資源隔離程度中等;資源效率中等;每個租戶可以有自己的備份和 CMEK。
- 缺點:每個執行個體的房客數量有限;如果未使用地理位置分割功能,位置彈性較低。
資料庫資料管理模式最適合下列情境:
- 多位客戶位於同一資料存放位置,或受同一監管機構管轄。
- 租戶需要以系統為基礎的資料分離機制,以及備份和還原資料的功能,但可接受共用基礎架構資源。
- 租戶必須使用自己的 CMEK。
- 成本是重要的考量因素。每個租戶所需的最低資源低於執行個體的成本。我們希望房客能使用其他房客的閒置資源。
資料表
在資料表資料管理模式中,單一資料庫 (實作單一結構定義) 會用於多個租戶,而每個租戶的資料會使用一組獨立的資料表。如要區分這些資料表,可以在資料表名稱中加入「tenant ID」,做為前置字串、後置字串或具名結構定義。
與前述選項 (執行個體和資料庫管理模式) 相比,為每個租戶使用一組獨立資料表的資料管理模式,提供的隔離程度低得多。上線程序包括建立新資料表,以及相關的參照完整性和索引。
每個資料庫最多只能有 5,000 個資料表。部分客戶可能會因為這項限制而無法使用應用程式。
此外,為每個客戶使用個別資料表,可能會導致大量待處理的結構定義更新作業。這類積壓工作需要很長時間才能解決。
以人力資源應用程式為例,SaaS 供應商可以為每位客戶建立一組資料表,並在資料表名稱中加入 tenant ID 前置字元。例如:customer1_employee、customer1_payroll 和 customer1_department。或者,他們可以使用租戶 ID 做為具名結構定義,並將資料表命名為 customer1.employee、customer1.payroll 和 customer1.department。
如下圖所示,資料表資料管理模式會為每個租戶提供一組資料表。
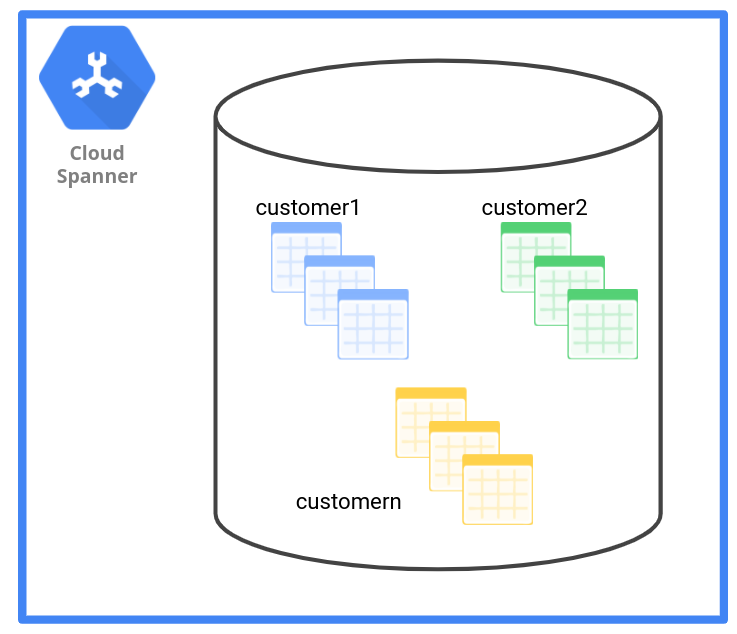
下表概略說明表格資料管理模式對不同條件的影響。
| 條件 | 資料表:每個租戶資料管理模式各有一組資料表 |
|---|---|
| 資料隔離 |
|
| 靈活性 |
|
| 作業 |
|
| 規模 |
|
| 效能 |
|
| 法規遵循需求 |
|
總而言之,主要重點如下:
- 優點:擴充性和資源效率適中。
- 缺點:
- 中等程度的資料隔離和資源隔離。
- 如果經常加入新房客,系統可能會限制結構定義更新作業。
- 如果未使用地理位置分割功能,位置資訊會不夠彈性。
- 無法個別監控租戶。目前只有資料表大小統計資料,可提供資料表層級的資源消耗資訊。
- 租戶無法擁有自己的 CMEK 和備份。
表格資料管理模式最適合下列情境:
- 多租戶應用程式並無資料分離的法律要求,但您希望進行邏輯分離和安全控管。
- 成本是重要的考量因素。每個租戶的最低成本比每個資料庫的成本更低。
列
最後一種資料管理模式是為多個租戶提供一組通用資料表,其中每個資料列都屬於特定租戶。這個資料管理模式代表極端的多元租戶層級,從基礎架構到結構定義再到資料模型,所有項目都由多個租戶共用。在資料表中,資料列會根據主鍵分區,且 tenant ID 是鍵的第一個元素。從擴充的角度來看,Spanner 最適合這個模式,因為它可以無限擴充資料表。
以 HR 應用程式為例,薪資表的主鍵可以是 customerID 和 payrollID 的組合。
如下圖所示,資料列資料管理模式會為多個租戶提供一個資料表。

與所有其他模式不同,在資料列模式中,無法為不同租戶分別控管資料存取權。如果每個租戶都有自己的資料庫資料表,使用較少的資料表代表結構定義更新作業完成速度會更快。這個做法在很大程度上簡化了新進人員訓練、離職程序和作業。
下表概述列資料管理模式對不同條件的影響。
| 條件 | 資料列:每個租戶資料管理模式的一組資料列 |
|---|---|
| 資料隔離 |
|
| 靈活性 |
|
| 作業 |
|
| 擴充 |
|
| 效能 |
|
| 法規遵循需求 |
|
總而言之,主要重點如下:
- 優點:可高度擴充、作業負擔低,且簡化了結構定義管理。
- 缺點:資源爭用嚴重;缺乏各租戶的安全控管和監控機制。
這個模式最適合下列情境:
- 內部應用程式適用於不同部門,相較於維護的便利性,嚴格的資料安全隔離並非主要考量。
- 如果租戶使用免費層級應用程式,同時盡量減少資源佈建,則可盡量共用資源。
資料管理模式和租戶生命週期管理
下表從高層次比較所有條件的各種資料管理模式。
| 執行個體 | 資料庫 | 資料表 | 列 | |
|---|---|---|---|---|
| 資料隔離 | 完成 | 高 | 中 | 低 |
| 靈活彈性 | 低 | 中 | 中 | 最高 |
| 操作簡單 | 高 | 高 | 低 | 低 |
| 擴充規模 | 高 | 有限 (除非達到限制時使用其他執行個體) | 受限 (除非達到上限時使用其他資料庫) | 最高 |
| 效能1 - 資源隔離 | 高 | 低 | 低 | 低 |
| 效能1 - 每個租戶的最低資源 | 高 | 中高 | 中 | 每個租戶沒有最低用量限制 |
| 效能1 - 資源效率 | 低 | 高 | 高 | 高 |
| 效能1 - 選擇地點以最佳化延遲 | 高 | 中 | 中 | 中 |
| 法規與法規遵循 | 最高 | 高 | 中 | 低 |
1 效能取決於結構定義設計和查詢最佳做法。這裡的值僅為平均預期。
針對特定多租戶應用程式,最適合的資料管理模式是根據條件,滿足大部分需求的模式。如果不需要特定條件,可以忽略該條件所在的列。
結合資料管理模式
通常,單一資料管理模式就足以滿足多租戶應用程式的需求。在這種情況下,設計可以採用單一資料管理模式。
部分多租戶應用程式需要同時採用多種資料管理模式。舉例來說,支援免費層級、一般層級和企業層級的多租戶應用程式。
免費方案:
- 必須符合成本效益
- 必須設有資料量上限
- 通常僅支援部分功能
- 列資料管理模式是免費方案的理想候選者
- 租戶管理作業簡單明瞭
- 不必建立專屬或專用的租戶資源
一般級:
- 適合沒有特別強大的擴充或隔離需求付費客戶。
- 資料表資料管理模式或資料庫資料管理模式是適合常規層級的候選模式:
- 資料表和索引專供租戶使用。
- 在資料庫資料管理模式中,備份作業相當簡單
- 表格資料管理模式不支援備份。
- 您必須在 Spanner 外部實作租戶備份功能。
Enterprise 級:
- 通常是高階層級,在各方面都完全自主。
- 租戶擁有專屬資源,包括專屬的擴充功能和完整隔離功能。
- 執行個體資料管理模式非常適合企業層級。
最佳做法是將不同的資料管理模式放在不同的資料庫中。雖然可以在 Spanner 資料庫中合併不同的資料管理模式,但這樣會難以實作應用程式的存取邏輯和生命週期作業。
「應用程式設計」一節說明使用單一或多個資料管理模式時,適用的一些多租戶應用程式設計考量。
管理租戶生命週期
房客有生命週期。因此,您必須在多租戶應用程式中實作相應的管理作業。除了建立、更新及刪除房客的基本作業外,請考慮下列其他資料相關作業:
匯出租戶資料:
- 刪除租戶時,最佳做法是先匯出租戶的資料,並視需要提供資料集給對方。
- 使用資料列或資料表資料管理模式時,多租戶應用程式系統必須實作匯出功能,或將資料對應至資料庫功能 (資料庫匯出),並實作自訂邏輯,從中擷取與租戶對應的資料部分。
備份租戶資料:
- 使用執行個體或資料庫資料管理模式,並為個別租戶備份資料時,請使用資料庫的匯出或備份功能。
- 使用資料表或資料列資料管理模式,並為個別租戶備份資料時,多租戶應用程式必須實作這項作業。Spanner 資料庫無法判斷哪些資料屬於哪個房客。
遷移租戶資料:
如要將租戶從某個資料管理模式移至另一個模式 (或在相同資料管理模式中,將租戶從某個執行個體或資料庫移至另一個執行個體或資料庫),必須先從某個資料管理模式擷取資料,然後將該資料插入新的資料管理模式。
- 如果應用程式可能會停機,請執行匯出/匯入作業。
- 如果無法停機,請執行零停機時間資料庫遷移作業。
遷移租戶的另一個原因是減輕「吵雜鄰居」問題。
應用程式設計
設計多租戶應用程式時,請實作可識別租戶的業務邏輯。也就是說,應用程式每次執行商業邏輯時,都必須處於已知租戶的環境中。
從資料庫的角度來看,應用程式設計是指每個查詢都必須針對租戶所在的資料管理模式執行。以下各節將說明多租戶應用程式設計的一些核心概念。
動態租戶連線和查詢設定
將租戶資料動態對應至租戶應用程式要求時,會使用對應設定:
- 如果是資料庫資料管理模式或執行個體資料管理模式,只要有連線字串,就能存取租戶的資料。
- 如果是資料表資料管理模式,則必須判斷正確的資料表名稱。
- 如要管理資料列資料,請使用適當的述詞擷取特定房客的資料。
租戶可位於四種資料管理模式的任一模式。下列對應實作適用於一般情況,也就是同時使用所有資料管理模式的多租戶應用程式連線設定。如果特定租戶採用某種模式,部分多租戶應用程式會對所有租戶使用一種資料管理模式。以下對應關係會隱含涵蓋這個情況。
如果租戶執行商業邏輯 (例如員工使用租戶 ID 登入),應用程式邏輯就必須判斷租戶的資料管理模式、特定租戶 ID 的資料位置,以及 (視需要) 資料表命名慣例 (適用於資料表模式)。
這項應用程式邏輯需要租戶對應至資料管理模式。在下列程式碼範例中,connection string 是指存放租戶資料的資料庫。這個範例會識別 Spanner 執行個體和資料庫。對於資料管理模式執行個體和資料庫,下列程式碼足以讓應用程式連線及執行查詢:
tenant id -> (data management pattern,
database connection string)
資料表和列資料管理模式需要額外設計。
資料表資料管理模式
在資料表資料管理模式中,同一個資料庫內有多個租戶。每個租戶都有一組專屬的資料表。資料表會依名稱區分。哪些資料表屬於哪個房客是確定的。
其中一種做法是將每個租戶的資料表放在以租戶命名的命名空間中,並使用 namespace.name 完全限定資料表名稱。舉例來說,您可以在 ID 為 356 的租戶命名空間 T356 內放置 EMPLOYEE 資料表,而應用程式可以使用 T356.EMPLOYEE 將要求傳送至該資料表。
另一種做法是在資料表名稱前面加上租戶 ID。舉例來說,ID 為 356 的租戶,EMPLOYEE 資料表會稱為 T356_EMPLOYEE。應用程式必須先在每個資料表前面加上 tenant
ID 前置字元,再將查詢傳送至對應傳回的資料庫。
如要使用其他文字取代租戶 ID,可以維護從租戶 ID 到具名結構定義命名空間或資料表前置字元的對應。
為簡化應用程式邏輯,您可能會導入一個間接層級。舉例來說,您可以搭配應用程式使用通用程式庫,自動附加租戶呼叫的命名空間或資料表前置字元。
資料列資料管理模式
列資料管理模式也需要類似的設計。在這個模式中,只有一個結構定義。系統會以資料列的形式儲存租戶資料。如要正確存取資料,請在每個查詢中附加述詞,選取適當的租戶。
如要找出適當的租戶,其中一個方法是在每個資料表中加入名為 TENANT 的資料欄。為提升資料隔離效果,這個資料欄值應屬於主鍵。欄值為 tenant ID。每項查詢都必須將述詞 AND TENANT = tenant ID 附加至現有的 WHERE 子句,或新增含有述詞 AND TENANT = tenant
ID 的 WHERE 子句。
如要連線至資料庫並建立適當的查詢,應用程式邏輯中必須提供租戶 ID。可以做為參數傳遞,或儲存為執行緒情境。
部分生命週期作業需要修改租戶對資料管理模式的對應設定,例如在資料管理模式之間移動租戶時,您必須更新資料管理模式和資料庫連線字串。您可能也需要更新資料表前置字串。
查詢生成和歸因
多租戶應用程式的基本原則是,多個租戶可以共用單一雲端資源。上述資料管理模式都屬於這個類別,但如果單一租戶分配到單一 Spanner 執行個體,則不在此限。
資源共用不只是共用資料,監控和記錄也會共用。舉例來說,在資料表資料管理模式和資料列資料管理模式中,所有租戶的所有查詢都會記錄在同一個稽核記錄中。
如果系統記錄了查詢,就必須檢查查詢文字,判斷查詢是為哪個租戶執行。在資料列管理模式中,您必須剖析述詞。在資料表資料管理模式中,您必須剖析其中一個資料表名稱。
在資料庫資料管理模式或執行個體資料管理模式中,查詢文字不含任何租戶資訊。如要取得這些模式的租戶資訊,您必須查詢租戶至資料管理模式的對應資料表。
您不必剖析查詢文字,即可判斷特定查詢的租戶,進而輕鬆分析記錄和查詢。如要為所有資料管理模式的查詢統一識別租戶,方法是在查詢文字中加入含有 tenant ID 的註解,以及 (選用) label。
下列查詢會選取由 TENANT 356 識別的租戶所有員工資料。為避免剖析 SQL 語法並從述詞中擷取租戶 ID,租戶 ID 會以註解形式新增。無須剖析 SQL 語法,即可擷取註解。
SELECT * FROM EMPLOYEE
-- TENANT 356
WHERE TENANT = 'T356';
或
SELECT * FROM T356_EMPLOYEE;
-- TENANT 356
採用這種設計後,系統會將為租戶執行的每項查詢歸給該租戶,與資料管理模式無關。如果租戶從某個資料管理模式移至另一個模式,查詢文字可能會變更,但查詢文字中的歸因會維持不變。
上述程式碼範例只是一種方法。另一種方法是插入 JSON 物件做為註解,而非標籤和值:
SELECT * FROM T356_EMPLOYEE;
-- {"TENANT": 356}
您也可以使用標記將查詢歸因於房客,並在內建的 spanner_sys 資料表中查看統計資料。
租戶存取生命週期作業
視設計理念而定,多租戶應用程式可以直接實作先前說明的資料生命週期作業,也可以建立個別的租戶管理工具。
無論採用哪種實作策略,生命週期作業都可能必須在沒有應用程式邏輯同時執行的情況下執行,例如將租戶從一個資料管理模式移至另一個模式時,應用程式邏輯無法執行,因為資料不在單一資料庫中。如果資料不在單一資料庫中,從應用程式的角度來看,還需要執行兩項額外作業:
- 停止租戶:停用所有應用程式邏輯存取權,但允許資料生命週期作業。
- 啟動租戶:應用程式邏輯可以存取租戶的資料,同時停用會干擾應用程式邏輯的生命週期作業。
雖然不常用,但緊急終止租戶可能也是另一項重要的生命週期作業。懷疑發生違規事件時,請使用這項關閉功能,禁止存取租戶的所有資料,包括應用程式邏輯和生命週期作業。資料庫內外都可能發生違規事件。
此外,也必須提供相應的生命週期作業,以移除緊急狀態。這類作業可能需要兩名以上的管理員同時登入,才能實作相互控制。
應用程式隔離
各種資料管理模式支援不同程度的租戶資料隔離。從最隔離的層級 (執行個體) 到最不隔離的層級 (資料列),都有不同程度的隔離機制。
在多租戶應用程式的環境中,也必須做出類似的部署決策:所有租戶是否都使用相同的應用程式部署,存取各自的資料 (可能採用不同的資料管理模式)?舉例來說,單一 Kubernetes 叢集可能支援所有租戶,而當租戶存取資料時,同一個叢集會執行商業邏輯。
或者,如同資料管理模式,不同租戶可能會導向不同的應用程式部署作業。大型租戶可能專屬應用程式部署,而小型租戶或免費層級的租戶則共用應用程式部署。
您可以使用資料庫資料管理模式,讓所有租戶共用單一應用程式部署作業,不必直接將本文討論的資料管理模式,與對等的應用程式資料管理模式相符。資料庫資料管理模式和所有這些租戶可以共用單一應用程式部署作業。
多租戶是重要的應用程式設計資料管理模式,尤其是在資源效率扮演重要角色的情況下。Spanner 支援多種資料管理模式,可用於實作多租戶應用程式。 這項服務可確保定期維護或區域故障時不會停機,並提供可用性達 99.999%的服務水準協議。 此外,透過提供高可用性和可擴充性,也支援現代多租戶應用程式。