
במאמר הזה מוסבר איך למדוד את k-אנונימיות של מערך נתונים באמצעות Sensitive Data Protection ולהציג אותו באופן ויזואלי ב-Data Studio. כך תוכלו גם להבין טוב יותר את הסיכון ולעזור להעריך את הפשרות שאתם עשויים לעשות לגבי התועלת אם אתם מצנזרים נתונים או מסירים מהם פרטים מזהים.
הנושא הזה מתמקד בהצגה חזותית של מדד הסיכון לזיהוי מחדש של אנונימיות k, אבל אפשר להשתמש באותן שיטות גם כדי להציג חזותית את מדד l-הגיוון.
במאמר הזה אנחנו מניחים שאתם כבר מכירים את המושג k-אנונימיות ואת השימוש בו להערכת האפשרות לזיהוי מחדש של רשומות במערך נתונים. כדאי גם להכיר את האופן שבו מחשבים אנונימיות מסוג k באמצעות Sensitive Data Protection, ואת השימוש ב-Data Studio.
מבוא
טכניקות להסרת פרטי הזיהוי יכולות לעזור לכם להגן על הפרטיות של הנושאים בזמן שאתם מעבדים נתונים או משתמשים בהם. אבל איך יודעים אם בוצע מספיק טשטוש של פרטים מזהים במערך נתונים? איך תדעו אם האנונימיזציה גרמה לאובדן נתונים גדול מדי לתרחיש השימוש שלכם? כלומר, איך אפשר להשוות בין הסיכון לחשיפת זהות לבין התועלת של הנתונים כדי לקבל החלטות מבוססות-נתונים?
חישוב ערך האנונימיות k של מערך נתונים עוזר לענות על השאלות האלה על ידי הערכת האפשרות לזהות מחדש את הרשומות במערך הנתונים. Sensitive Data Protection כולל פונקציונליות מובנית לחישוב ערך k-אנונימיות במערך נתונים על סמך מזהים למחצה שאתם מציינים. כך תוכלו להעריך במהירות אם הסרת הפרטים המזהים מעמודה מסוימת או משילוב של עמודות תגרום לכך שיהיה יותר או פחות סיכוי לזהות מחדש את מערך הנתונים.
מערך נתונים לדוגמה
בהמשך מופיעות כמה שורות ראשונות מתוך מערך נתונים גדול לדוגמה.
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
לצורך המדריך הזה, לא נתייחס ל-user_id, כי נתמקד במזהים למחצה. בתרחיש מהעולם האמיתי, כדאי לוודא ש-user_id מצונזר או ש-נוצר לו טוקן בצורה מתאימה. העמודה score היא קניינית למערך הנתונים הזה, ולא סביר שתוקף יוכל לגלות אותה באמצעים אחרים, ולכן לא תכללו אותה בניתוח. ההתמקדות תהיה בעמודות age ו-title שנותרו, שבאמצעותן תוקף יכול ללמוד על אדם מסוים דרך מקורות נתונים אחרים. השאלות שאתם מנסים לענות עליהן לגבי מערך הנתונים הן:
- מה תהיה ההשפעה של שני המזהים למחצה –
ageו-title– על הסיכון הכולל לשחזור פרטי הזיהוי של הנתונים שהוסרו מהם פרטים מזהים? - איך החלת טרנספורמציה של הסרת פרטים מזהים תשפיע על הסיכון הזה?
חשוב לוודא שהשילוב של age ושל title לא ימופה למספר קטן של משתמשים. לדוגמה, נניח שיש רק משתמש אחד במערך הנתונים שהתפקיד שלו הוא Programmer I והגיל שלו הוא 69. תוקף יכול להשוות את המידע הזה לנתונים דמוגרפיים או למידע אחר שזמין, להבין מי האדם ולגלות את ערך הציון שלו.
מידע נוסף על התופעה הזו מופיע בסעיף מזהי ישויות וחישוב של k-אנונימיות בנושא ניתוח סיכונים.
שלב 1: חישוב k-אנונימיות במערך הנתונים
קודם כל, משתמשים ב-Sensitive Data Protection כדי לחשב את האנונימיות k במערך הנתונים על ידי שליחת ה-JSON הבא למשאב DlpJob. ב-JSON הזה, מגדירים את מזהה הישות לעמודה user_id, ומזהים את שני המזהים למחצה כעמודות age ו-title. אתם גם מנחים את Sensitive Data Protection לשמור את התוצאות בטבלה ב-BigQuery חדשה.
קלט JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}אחרי שמשימת ה-k-anonymity של k מסתיימת, Sensitive Data Protection שולח את תוצאות המשימה לטבלה ב-BigQuery בשם dlp-demo-2.dlp_testing.test_results.
שלב 2: קישור התוצאות ל-Data Studio
בשלב הבא, מחברים את הטבלה ב-BigQuery שנוצרה בשלב 1 לדוח חדש ב-Data Studio.
פותחים את Data Studio.
לוחצים על יצירה > דוח.
בחלונית הוספת נתונים לדוח, בקטע התחברות לנתונים, לוחצים על BigQuery. יכול להיות שתצטרכו לתת ל-Data Studio הרשאת גישה לטבלאות BigQuery.
בבורר העמודות, בוחרים באפשרות הפרויקטים שלי. לאחר מכן בוחרים את הפרויקט, מערך הנתונים והטבלה. בסיום, לוחצים על הוספה. אם מוצגת הודעה שלפיה אתם עומדים להוסיף נתונים לדוח הזה, לוחצים על Add to report.
תוצאות הסריקה של k-אנונימיות נוספו עכשיו לדוח החדש של Data Studio. בשלב הבא יוצרים את התרשים.
שלב 3: יצירת התרשים
כדי להוסיף ולהגדיר את התרשים:
- ב-Data Studio, אם מופיעה טבלה של ערכים, בוחרים אותה ולוחצים על Delete כדי להסיר אותה.
- בתפריט הוספה, לוחצים על תרשים משולב.
- לוחצים ומציירים מלבן באזור העריכה במקום שבו רוצים שהתרשים יופיע.
לאחר מכן, מגדירים את נתוני התרשים בכרטיסייה נתונים כך שהתרשים יציג את ההשפעה של שינוי הגודל וטווח הערכים של הדליים:
- כדי לנקות את השדות בכותרות הבאות, מצביעים על כל שדה ולוחצים על X, כמו שמוצג כאן:
- מאפיין טווח התאריכים
- מאפיין
- מדד
- מיון
- אחרי שמנקים את כל השדות, גוררים את השדה upper_endpoint מהעמודה שדות זמינים אל הכותרת מאפיין.
- גוררים את השדה upper_endpoint לכותרת Sort (מיון) ובוחרים באפשרות Ascending (עולה).
- גוררים את השדות bucket_size ו-bucket_value_count אל הכותרת Metric.
- מעבירים את העכבר מעל הסמל שמימין למדד bucket_size ומופיע סמל העריכה .
לוחצים על סמל העריכה
ומבצעים את הפעולות הבאות:
- בשדה שם, מקלידים
Unique row loss. - בקטע סוג, בוחרים באפשרות אחוז.
- בקטע חישוב השוואה, בוחרים באפשרות אחוז מהסך הכולל.
- בקטע חישוב מצטבר, בוחרים באפשרות סכום מצטבר.
- בשדה שם, מקלידים
- חוזרים על השלב הקודם בשביל המדד bucket_value_count, אבל בשדה Name מזינים
Unique quasi-identifier combination loss.
בסיום, העמודה אמורה להופיע כמו שמוצג כאן:
לבסוף, מגדירים את התרשים כך שיוצג תרשים קו לשני המדדים:
- לוחצים על הכרטיסייה סגנון בחלונית שמשמאל לחלון.
- גם בסדרה 1 וגם בסדרה 2, בוחרים באפשרות קו.
- כדי לראות את התרשים הסופי בנפרד, לוחצים על הלחצן הצגה בפינה השמאלית העליונה של החלון.
התרשים הבא הוא דוגמה לתרשים אחרי שמבצעים את השלבים הקודמים.
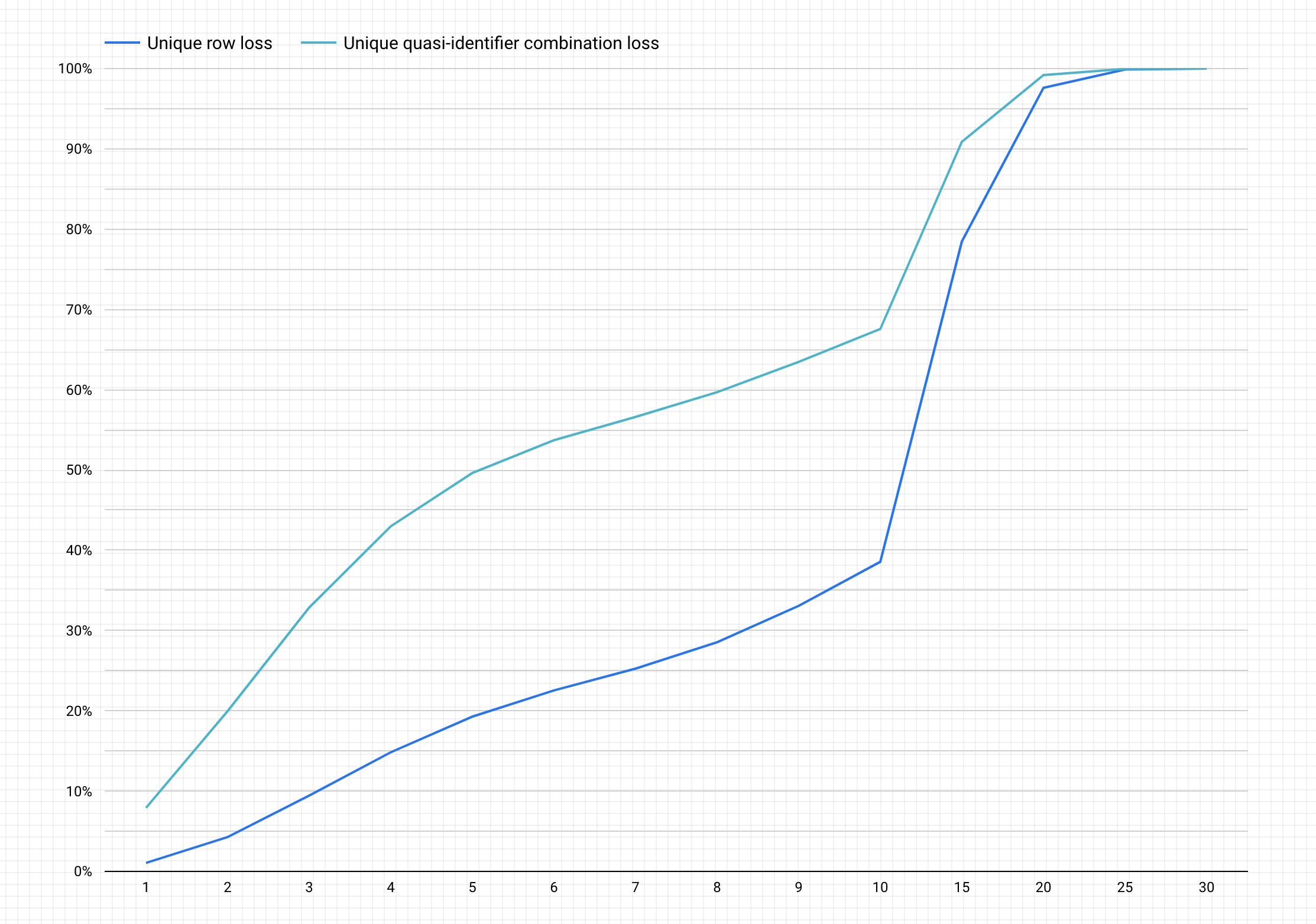
הסבר על התרשים
בתרשים שנוצר, בציר ה-y מוצג אחוז אובדן הנתונים הפוטנציאלי עבור שורות ייחודיות ושילובים ייחודיים של מזהים למחצה, כדי להשיג בציר ה-x ערך של k-אנונימיות.
ערכים גבוהים יותר של k-anonymity מצביעים על סיכון נמוך יותר לשחזור פרטי זיהוי. עם זאת, כדי להשיג ערכי אנונימיות k גבוהים יותר, תצטרכו להסיר אחוזים גבוהים יותר מסך השורות ושילובים ייחודיים רבים יותר של מזהים למחצה, מה שעלול להקטין את התועלת של הנתונים.
למזלכם, מחיקת נתונים היא לא האפשרות היחידה לצמצום הסיכון לחשיפת זהות. טכניקות אחרות להסרת פרטים מזהים יכולות ליצור איזון טוב יותר בין אובדן נתונים לבין שימושיות. לדוגמה, כדי לטפל בסוג אובדן הנתונים שקשור לערכי k-אנונימיות גבוהים יותר ולקבוצת הנתונים הזו, אפשר לנסות להגדיר טווחים של גילאים או של תפקידים כדי לצמצם את הייחודיות של שילובים של גיל ותפקיד. לדוגמה, אפשר לנסות לסווג את הגילאים לטווחים של 20-25, 25-30, 30-35 וכן הלאה. מידע נוסף על האופן שבו עושים זאת זמין במאמרים הכללה ו-bucketing והסרת פרטים מזהים ממידע אישי רגיש בתוכן טקסט.