
K-anonymity היא מאפיין של מערך נתונים שמציין את האפשרות לזהות מחדש את הרשומות שלו. מערך נתונים הוא k-אנונימי אם המזהים למחצה של כל אדם במערך הנתונים זהים לפחות ל-k – 1 אנשים אחרים שנכללים גם הם במערך הנתונים.
אפשר לחשב את ערך ה-k-anonymity על סמך עמודה אחת או יותר, או שדות, של קבוצת נתונים. בנושא הזה נסביר איך לחשב ערכי אנונימיות מסוג k עבור קבוצת נתונים באמצעות Sensitive Data Protection. לפני שממשיכים, מומלץ לעיין בנושא המושג ניתוח סיכונים כדי לקבל מידע נוסף על k-anonymity או על ניתוח סיכונים באופן כללי.
לפני שמתחילים
לפני שממשיכים, חשוב לוודא שביצעתם את הפעולות הבאות:
- נכנסים לחשבון Google.
- בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו. כניסה לדף לבחירת הפרויקט
- מוודאים שהחיוב מופעל בפרויקט Google Cloud . איך מוודאים שהחיוב מופעל בפרויקט?
- מפעילים את התכונה Sensitive Data Protection. הפעלת Sensitive Data Protection
- בוחרים מערך נתונים ב-BigQuery לניתוח. Sensitive Data Protection מחשב את מדד האנונימיות k על ידי סריקה של טבלה ב-BigQuery.
- קובעים מזהה (אם רלוונטי) ולפחות מזהה למחצה אחד במערך הנתונים. מידע נוסף זמין במאמר מונחים וטכניקות לניתוח סיכונים.
חישוב k-anonymity
הכלי Sensitive Data Protection מבצע ניתוח סיכונים בכל פעם שמריצים משימת ניתוח סיכונים. קודם צריך ליצור את העבודה באמצעות מסוףGoogle Cloud , שליחת בקשת DLP API או שימוש בספריית לקוח של Sensitive Data Protection.
המסוף
נכנסים לדף Create risk analysis במסוף Google Cloud .
בקטע Choose input data (בחירת נתוני קלט), מציינים את הטבלה ב-BigQuery שרוצים לסרוק. לשם כך, מזינים את מזהה הפרויקט שמכיל את הטבלה, את מזהה מערך הנתונים של הטבלה ואת שם הטבלה.
בקטע Privacy metric to compute (מדד הפרטיות לחישוב), בוחרים באפשרות k-anonymity (אנונימיות מסוג k).
בקטע מזהה משימה, אפשר לתת לעבודה מזהה מותאם אישית ולבחור מיקום משאב שבו Sensitive Data Protection יעבד את הנתונים. בסיום, לוחצים על המשך.
בקטע Define fields, מציינים מזהים ומזהים למחצה עבור משימת הסיכון של k-anonymity. Sensitive Data Protection ניגש למטא-נתונים של טבלה ב-BigQuery שציינתם בשלב הקודם ומנסה לאכלס את רשימת השדות.
- מסמנים את התיבה המתאימה כדי לציין ששדה מסוים הוא מזהה (ID) או מזהה למחצה (QI). צריך לבחור 0 או 1 מזהים ולפחות 1 מזהים למחצה.
- אם Sensitive Data Protection לא מצליחה לאכלס את השדות, לוחצים על הזנת שם השדה כדי להזין באופן ידני שדה אחד או יותר, ומגדירים כל אחד מהם כמזהה או כמזהה למחצה. בסיום, לוחצים על המשך.
בקטע הוספת פעולות, אפשר להוסיף פעולות אופציונליות שיבוצעו כשהעבודה לזיהוי סיכונים תסתיים. האפשרויות הזמינות הן:
- Save to BigQuery (שמירה ב-BigQuery): שומר את תוצאות הסריקה של ניתוח הסיכונים בטבלה ב-BigQuery.
פרסום ב-Pub/Sub: פרסום התראה בנושא Pub/Sub.
שליחת הודעה באימייל: יישלח אליכם אימייל עם התוצאות. כשמסיימים, לוחצים על יצירה.
תהליך ניתוח הסיכון של k-anonymity מתחיל באופן מיידי.
C#
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Go
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Java
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
PHP
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
REST
כדי להריץ ניתוח סיכונים חדש לחישוב של k-anonymity, שולחים בקשה למשאב projects.dlpJobs, כאשר PROJECT_ID מציין את מזהה הפרויקט:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
הבקשה מכילה אובייקט RiskAnalysisJobConfig, שכולל את המאפיינים הבאים:
אובייקט
PrivacyMetric. כאן מציינים שמחשבים k-anonymity על ידי הכללת אובייקטKAnonymityConfig.אובייקט
BigQueryTableכדי לציין את הטבלה ב-BigQuery שרוצים לסרוק, צריך לכלול את כל הפרטים הבאים:-
projectId: מזהה הפרויקט שמכיל את הטבלה. -
datasetId: מזהה מערך הנתונים של הטבלה. -
tableId: שם הטבלה.
-
קבוצה של אובייקטים מסוג
Actionאחד או יותר, שמייצגים פעולות להפעלה, בסדר שצוין, בסיום העבודה. כל אובייקטActionיכול להכיל אחת מהפעולות הבאות:SaveFindingsobject: שומר את התוצאות של סריקת ניתוח הסיכונים בטבלה ב-BigQuery.
PublishToPubSubobject: פרסום התראה בנושא Pub/Sub.JobNotificationEmailsobject: נשלח אליכם אימייל עם התוצאות.
באובייקט
הערכים האלה של הצעות המחיר משמשים ליצירת ההיסטוגרמה וטבלאות הפלט.KAnonymityConfigמציינים את הפרטים הבאים:-
quasiIds[]: מזהים למחצה (אובייקטים מסוגFieldId) שצריך לסרוק ולהשתמש בהם כדי לחשב את האנונימיות מסוג k. כשמציינים כמה מזהים למחצה, הם נחשבים כמפתח מורכב יחיד. אין תמיכה במבנים ובסוגי נתונים חוזרים, אבל יש תמיכה בשדות בתוך שדות, בתנאי שהם לא מבנים בעצמם או שהם לא בתוך שדה חוזר. -
entityId: ערך מזהה אופציונלי, שאם הוא מוגדר, מציין שכל השורות שמתאימות לכלentityIdנפרד צריכות להיות מקובצות יחד לחישוב של k-אנונימיות. בדרך כלל,entityIdהיא עמודה שמייצגת משתמש ייחודי, כמו מספר לקוח או מזהה משתמש. כשסמלentityIdמופיע בכמה שורות עם ערכים שונים של מזהים למחצה, השורות האלה יצורפו ליצירת קבוצה מרובה שתשמש כמזהים למחצה של הישות הזו. מידע נוסף על מזהי ישויות זמין במאמר מזהי ישויות וחישוב אנונימיות מסוג k בנושא ניתוח סיכונים.
ברגע ששולחים בקשה ל-DLP API, מתחילה משימת ניתוח הסיכון.
הצגת רשימה של משימות ניתוח סיכונים שהושלמו
אפשר לראות רשימה של משימות ניתוח הסיכונים שהופעלו בפרויקט הנוכחי.
המסוף
כדי להציג רשימה של משימות ניתוח סיכונים שפועלות ושל משימות שהופעלו בעבר במסוףGoogle Cloud :
במסוף Google Cloud , פותחים את Sensitive Data Protection.
לוחצים על הכרטיסייה משימות וטריגרים של משימות בחלק העליון של הדף.
לוחצים על הכרטיסייה Risk jobs (משימות בסיכון).
מופיע פרסום המשרה עם סיכון.
פרוטוקול
כדי לראות את רשימת המשימות של ניתוח הסיכונים שפועלות כרגע ואלה שפעלו בעבר, שולחים בקשת GET למשאב projects.dlpJobs. הוספת מסנן של סוג העבודה (?type=RISK_ANALYSIS_JOB) מצמצמת את התגובה רק למשרות של ניתוח סיכונים.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
התגובה שתקבלו מכילה ייצוג JSON של כל משימות ניתוח הסיכונים הנוכחיות והקודמות.
צפייה בתוצאות של משימת k-anonymity
ב-Sensitive Data Protection ב- Google Cloud console יש תרשימים מובנים של משימות k-anonymity שהושלמו. אחרי שמבצעים את ההוראות שבקטע הקודם, ברשימת המשימות של ניתוח הסיכונים, בוחרים את המשימה שרוצים לראות את התוצאות שלה. אם ההרצה של העבודה הסתיימה בהצלחה, החלק העליון של הדף פרטי ניתוח הסיכונים ייראה כך:
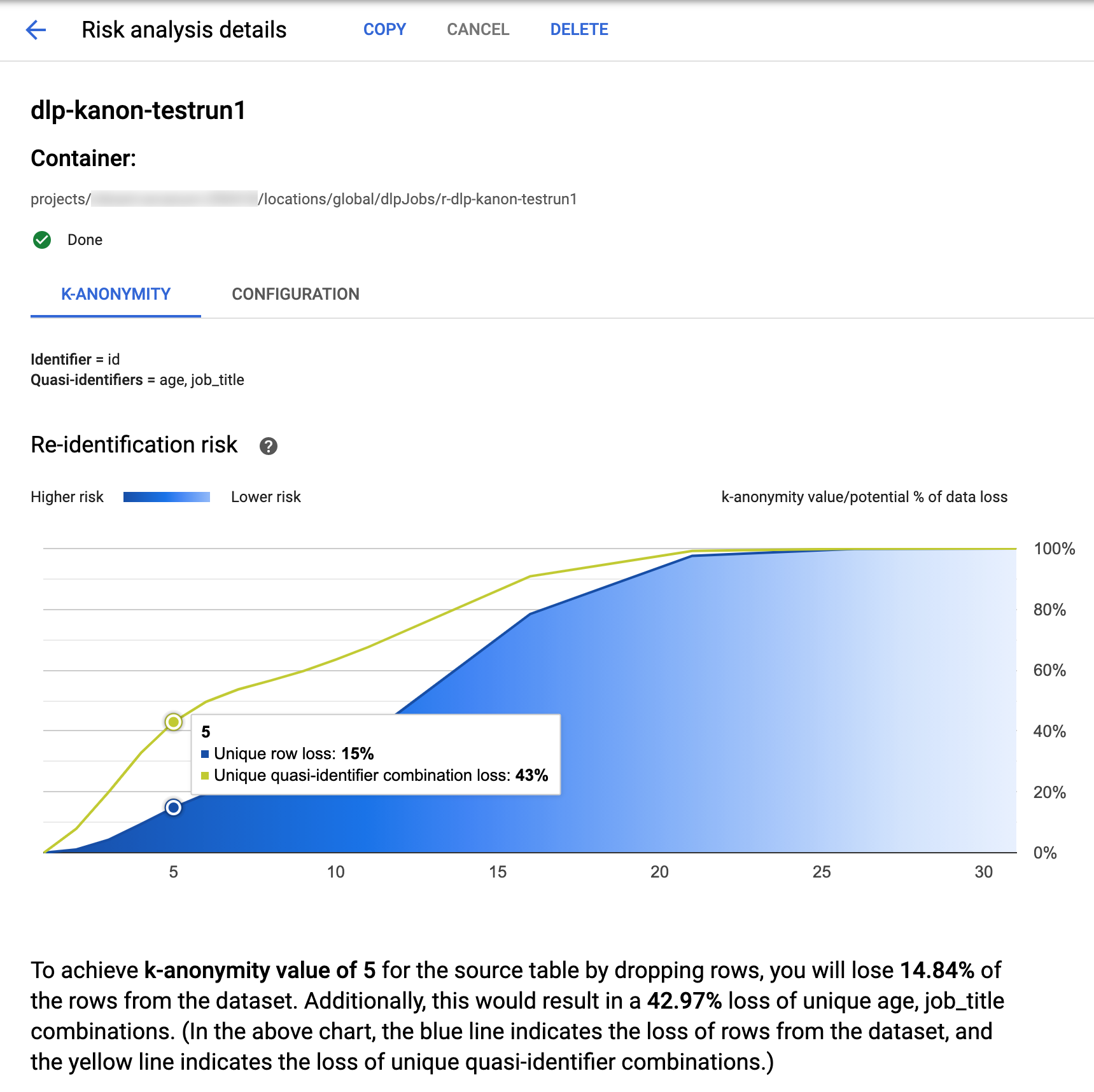
בחלק העליון של הדף מופיע מידע על משימת הסיכון של אנונימיות k, כולל מזהה המשימה ומיקום המשאב בקטע Container.
כדי לראות את התוצאות של חישוב ה-k-anonymity, לוחצים על הכרטיסייה K-anonymity. כדי לראות את ההגדרה של ניתוח הסיכונים, לוחצים על הכרטיסייה Configuration.
בכרטיסייה K-anonymity מופיעים קודם מזהה הישות (אם יש) והמזהים למחצה שמשמשים לחישוב k-anonymity.
תרשים סיכון
בתרשים Re-identification risk, בציר y מוצג אחוז אובדן הנתונים הפוטנציאלי עבור שורות ייחודיות ושילובים ייחודיים של מזהים למחצה, כדי להשיג בציר x ערך של k-anonymity. הצבע של התרשים מציין גם את הסיכון הפוטנציאלי. גוונים כהים יותר של כחול מציינים סיכון גבוה יותר, וגוונים בהירים יותר מציינים סיכון נמוך יותר.
ערכים גבוהים יותר של k-anonymity מצביעים על סיכון נמוך יותר לשחזור פרטי זיהוי. עם זאת, כדי להשיג ערכי אנונימיות k גבוהים יותר, תצטרכו להסיר אחוזים גבוהים יותר מסך השורות ושילובים ייחודיים רבים יותר של מזהים למחצה, מה שעלול להקטין את התועלת של הנתונים. כדי לראות ערך ספציפי של אחוז הפסד פוטנציאלי עבור ערך מסוים של k-אנונימיות, מעבירים את העכבר מעל התרשים. כפי שמוצג בצילום המסך, מופיע הסבר קצר בתרשים.
כדי לראות פרטים נוספים על ערך ספציפי של k-anonymity, לוחצים על נקודה על הגרף המתאימה. הסבר מפורט מופיע מתחת לתרשים, וטבלת נתונים לדוגמה מופיעה בהמשך הדף.
טבלת נתוני סיכון לדוגמה
המרכיב השני בדף התוצאות של משימת הסיכון הוא טבלת נתוני הדגימה. היא מציגה שילובים של מזהים למחצה עבור ערך נתון של k-אנונימיות.
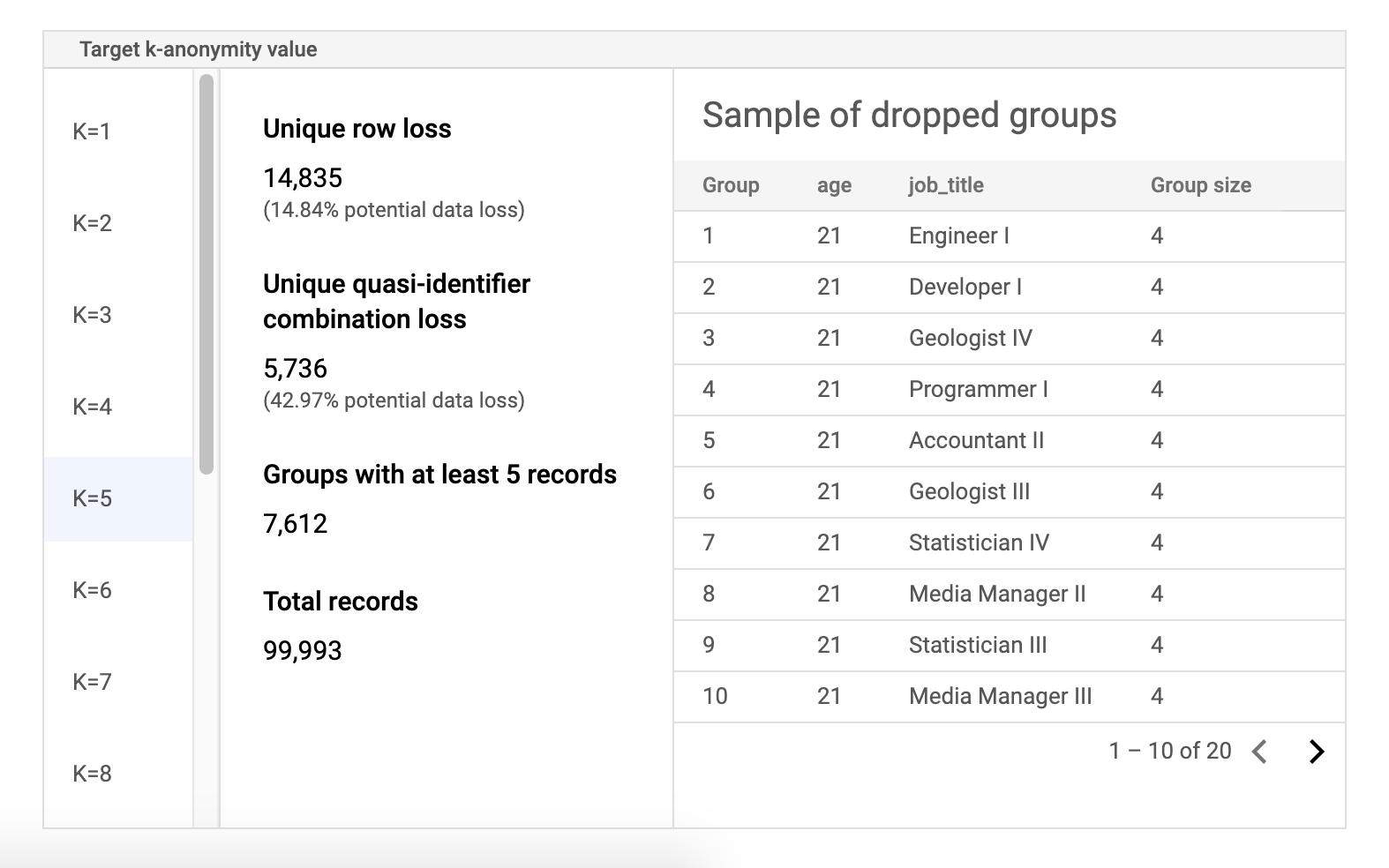
בעמודה הראשונה בטבלה מפורטים ערכי ה-k-אנונימיות. לוחצים על ערך של אנונימיות מסוג k כדי לראות נתוני מדגם תואמים שצריך להסיר כדי להשיג את הערך הזה.
בעמודה השנייה מוצג אובדן הנתונים הפוטנציאלי של שורות ייחודיות ושילובים של מזהים למחצה, וגם מספר הקבוצות עם לפחות k רשומות והמספר הכולל של הרשומות.
בעמודה האחרונה מוצגת דוגמה של קבוצות שמשתפות שילוב של מזהה למחצה, לצד מספר הרשומות שקיימות לשילוב הזה.
אחזור פרטי משימה באמצעות REST
כדי לאחזר את התוצאות של ניתוח הסיכון של אנונימיות מסוג k באמצעות REST API, שולחים את בקשת ה-GET הבאה למשאב projects.dlpJobs. מחליפים את PROJECT_ID במזהה הפרויקט ואת JOB_ID במזהה של המשימה שרוצים לקבל את התוצאות שלה.
מזהה המשרה הוחזר כשמתחילים את המשרה, ואפשר גם לאחזר אותו על ידי רשימת כל המשרות.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
הבקשה מחזירה אובייקט JSON שמכיל מופע של העבודה. תוצאות הניתוח נמצאות בתוך המפתח "riskDetails", באובייקט AnalyzeDataSourceRiskDetails. מידע נוסף מופיע בהפניית ה-API של המשאב DlpJob.
דוגמת קוד: חישוב של k-anonymity עם מזהה ישות
בדוגמה הזו נוצרת משימה של ניתוח סיכונים שמחשבת את k-anonymity עם מזהה ישות.
מידע נוסף על מזהי ישויות זמין במאמר מזהי ישויות וחישוב אנונימיות מסוג k.
C#
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Go
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Java
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Node.js
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
PHP
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
Python
מידע על התקנת ספריית הלקוח של Sensitive Data Protection והשימוש בה מופיע במאמר ספריות הלקוח של Sensitive Data Protection.
כדי לבצע אימות ב-Sensitive Data Protection, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לסביבת פיתוח מקומית.
המאמרים הבאים
- ll-diversity של מערך נתונים
- איך מחשבים את הערך של מפת k עבור מערך נתונים
- איך מחשבים את ערך δ-הנוכחות של מערך נתונים