
במאמר הזה מתוארים סוגי האירועים שאפשר להציג כהערות בתרשימים. אירוע הוא פעילות, כמו הפעלה מחדש או קריסה, שמשפיעה על הפעולה של מערכת. הצגת אירועים יכולה לעזור לכם ליצור קורלציה בין נתונים ממקורות שונים כשאתם מנסים לפתור בעיה.
לכל אירוע מצורפים קישורים למקורות מידע או למסמכי פתרון בעיות, וגם מידע על שאילתות לגבי האירוע. לדוגמה, כשמזהים אירועים באמצעות ניתוח היומנים, מסופקת שאילתה שמתאימה לשימוש ב-Logs Explorer או במדיניות התראות שמבוססת על יומנים.
כדי להוסיף הערות לתרשימים, צריך להגדיר את מרכז הבקרה או את הכרטיסייה שבה מוצג התרשים. לדוגמה, אפשר להגדיר את רוב לוחות הבקרה שמופיעים בדף לוחות בקרה במסוף Google Cloud כך שיוצגו בהם אירועים. באופן דומה, אתם יכולים להגדיר כרטיסיות Observability ספציפיות לשירותים מסוימים, כמו Compute Engine ו-Google Kubernetes Engine, כך שיוצגו בהן אירועים. מידע על הגדרות זמין במאמר בנושא הצגת אירועים בלוח בקרה.
בצילום המסך הבא מוצג תרשים עם כמה אירועים שזוהו בניתוח של רשומות ביומן, ואירוע אחד של Service Health:
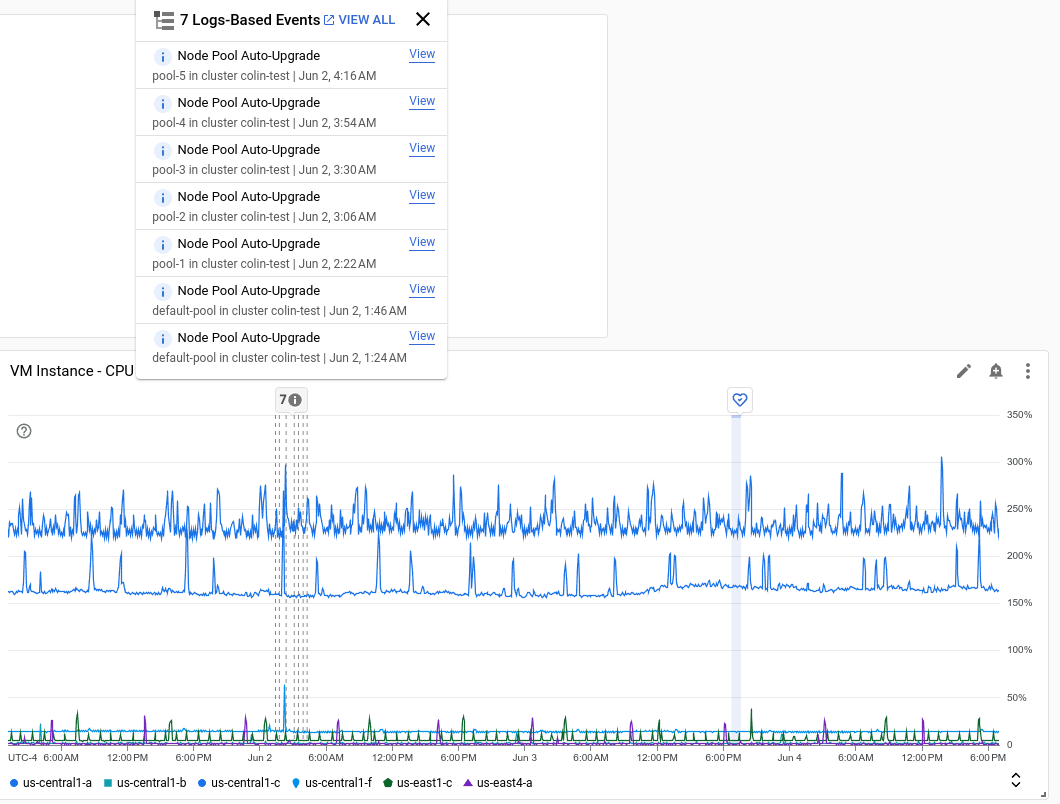
כל הערה יכולה לכלול רשימה של כמה אירועים. בצילום המסך הקודם, מופיע אירוע של פריסת GKE.
סוגי אירועים של התראות
בקטע הזה מתוארים סוגי האירועים של ההתראות שיכולים להופיע בלוח בקרה.
ההתראה נפתחה
התראות על אירועים פתוחים עוזרות לכם לקשר בין הנתונים בתרשים לבין הזמן שבו אירועים נפתחו. אירוע של פתיחת התראה מוצג כשמתקיימים התנאים הבאים:
- האירוע התואם נפתח במהלך טווח הזמן שצוין במרכז הבקרה.
- האירוע התואם לא נסגר.
הערות שנוצרו לגבי אירועים שנפתחו מחוץ לטווח הזמן שצוין בלוח הבקרה לא מוצגות. באופן דומה, אירוע של פתיחת התראה לא מוצג אם האירוע התואם נפתח ואז נסגר בטווח הזמן שצוין במרכז הבקרה.
ההסבר הקצר על אירוע שקשור להתראה כולל את הפרטים הבאים:
- שם מדיניות ההתראות.
- פרטי הסיכום, אם הם זמינים. לדוגמה, המידע הזה יכול לכלול את ערך הסף ואת הערך שנמדד.
- משך האירוע, והתאריך והשעה שבהם האירוע נפתח.
- תוויות של מדדים ומשאבים. יכול להיות שלא כל התוויות יוצגו בתיבת הטיפ.
- לחצן הצגה, שפותח את הדף פרטים של האירוע.
סוגי אירועים ב-Google Kubernetes Engine
בקטע הזה מתוארים סוגי האירועים של Google Kubernetes Engine שאפשר להציג בלוח בקרה.
עומס עבודה (workload) של GKE שעבר תיקון או עדכון
סוג האירוע הזה עוזר לכם לפתור בעיות בפריסת עומסי עבודה של GKE או בשינויים ב-StatefulSet, כי יכול להיות שיש קשר בין האירועים האלה לבין ירידה בביצועים או בעיות אחרות בביצועים. סוג האירוע הזה מוצג כשיוצרים, מעדכנים או מוחקים עומס עבודה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
מידע נוסף זמין במאמרים סקירה כללית על פריסת עומסי עבודה והצגת מדדי יכולת התבוננות.
קריסה של Pod ב-GKE
סוג האירוע הזה עוזר לכם לזהות ולפתור בעיות שקשורות לקריסות של פודים ב-GKE. קריסות של Pod יכולות לקרות בגלל חוסר זיכרון או שגיאה באפליקציה. סוג האירוע הזה מוצג כשמתרחש אחד מהמקרים הבאים:
- סטטוס רצף המודעות הוא
CrashLoopBackoff - ה-Pod מסתיים עם קוד יציאה שאינו אפס.
- ה-Pod מסתיים עם מצב של חוסר בזיכרון.
- ה-Pod מוצא מהמערכת.
- בדיקת המוכנות או בדיקת הפעילות נכשלה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
מידע לפתרון בעיות זמין במאמר פתרון בעיות: CrashLoopBackOff.
התזמון של פוד GKE נכשל
סוג האירוע הזה עוזר לכם לזהות ולפתור בעיות שקשורות ל-pods שלא ניתן לתזמן בצומת. סוג האירוע הזה מוצג כשתזמון הפוד נכשל בגלל אחת מהסיבות הבאות:
- אין מספיק מעבד (CPU) בצומת.
- אין מספיק זיכרון בצומת.
- אין צמתים ל-taints או ל-tolerations.
- צמתים שמגיעים למגבלה המקסימלית של ה-Pod.
- מאגר הצמתים הגיע לגודל המקסימלי.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
מידע על פתרון בעיות זמין במאמר פתרון בעיות: אי אפשר לתזמן פוד.
יצירת מאגר GKE נכשלה
סוג האירוע הזה עוזר לכם לזהות ולפתור בעיות שקשורות ליצירת קונטיינר GKE. יצירת הקונטיינר עלולה להיכשל בגלל סיבות כמו טעינת נפח שנכשלה או משיכת תמונה שנכשלה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
מידע על פתרון בעיות בשליפת תמונות זמין במאמר פתרון בעיות בשליפת תמונות.
הגדלה והקטנה של קבוצות Pod בהתאם לעומס
האירוע הזה מאפשר לכם לראות את השינויים בגודל של Horizontal Pod Autoscaler, שבעקבותיהם גדל או קטן מספר הפודים הפעילים של עומס עבודה. מידע נוסף זמין במאמר בנושא התאמה אופקית של קבוצות Pod לעומס.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
הגדלה והקטנה של האשכול בהתאם לעומס
האירוע הזה מאפשר לכם לראות מתי המידרוג האוטומטי של האשכול מגדיל או מקטין את מספר הצמתים במאגר הצמתים של האשכול. מידע נוסף זמין במאמרים מידע על מידרוג אוטומטי של אשכולות והצגת אירועים של מידרוג אוטומטי של אשכולות.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
יצירה ומחיקה של אשכול
האירוע הזה עוקב אחרי פעולות של יצירה ומחיקה של אשכולות GKE. מידע נוסף זמין במאמרים בנושא יצירת אשכול Autopilot, יצירת אשכול אזורי ומחיקת אשכול.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
עדכון אשכול
האירוע הזה עוקב אחרי עדכונים באשכול GKE. העדכונים כוללים שדרוגים אוטומטיים של גרסת מישור הבקרה, שדרוגים ידניים ושינויים בהגדרות האשכול. מידע נוסף זמין במאמרים בנושא שדרוג ידני של אשכול או מאגר צמתים ושדרוגים של אשכולות רגילים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
עדכון מאגר צמתים
האירוע הזה עוקב אחרי עדכונים של מאגרי צמתים ב-GKE. העדכונים כוללים שדרוגים אוטומטיים של גרסאות של מאגרי צמתים, וגם שדרוגים ידניים, שינויים בהגדרות ושינויים בגודל. מידע נוסף זמין במאמרים בנושא שדרוג ידני של אשכול או מאגר צמתים ושדרוגים של אשכולות רגילים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
סוגי אירועים ב-Cloud Run
בקטע הזה מתוארים סוגי האירועים ב-Cloud Run שאפשר להציג בלוח בקרה.
פריסה ב-Cloud Run
סוג האירוע הזה עוזר לכם לזהות ולפתור בעיות בפריסות של Cloud Run. יכול להיות שהפריסה תיכשל בגלל סיבות כמו חשבון שירות שנמחק, הרשאות לא נכונות, ייבוא של מאגר נכשל או הפעלה של מאגר נכשלה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
מידע לפתרון בעיות זמין במאמר פתרון בעיות: בעיות ב-Cloud Run.
סוגי אירועים ב-Cloud SQL
בקטע הזה מתוארים סוגי האירועים של Cloud SQL שאפשר להציג בלוח בקרה.
יתירות כשל ב-Cloud SQL
סוג האירוע הזה עוזר לכם לזהות מתי מתרחשים מעברים אוטומטיים או ידניים לגיבוי. מעבר לגיבוי (failover) מתרחש כשיש כשל במופע או באזור, והמופע במצב המתנה הופך למופע הראשי החדש. במהלך מעבר לגיבוי, Cloud SQL עובר אוטומטית להצגת נתונים ממופע הגיבוי.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
מידע נוסף מופיע במאמר בנושא זמינות גבוהה.
התחלה או הפסקה של Cloud SQL
סוג האירוע הזה עוזר לכם לזהות מקרים שבהם מופעלת, מושבתת או מופעלת מחדש מכונת Cloud SQL באופן ידני. כשעוצרים מכונה, גם כל החיבורים, הקבצים הפתוחים והפעולות שפועלות נעצרים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
מידע נוסף זמין במאמרים מידע על זמינות גבוהה והפעלה, עצירה והפעלה מחדש של מכונות.
אחסון ב-Cloud SQL
סוג האירוע הזה עוזר לכם לזהות אירועים שקשורים לאחסון ב-Cloud SQL, כולל מקרים שבהם האחסון במסד הנתונים מלא, ומקרים שבהם מסד נתונים מושבת בגלל שהגיע לקיבולת האחסון. יכול להיות שמסדי נתונים שהגיעו לקיבולת האחסון שלהם ושלא הופעל בהם אחסון אוטומטי ייסגרו כדי למנוע פגיעה בנתונים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
סוגי אירועים של Cloud Interconnect
בקטע הזה מתוארים סוגי האירועים של Cloud Interconnect שאפשר להציג בלוח בקרה.
התחזוקה של Interconnect החלה
סוג האירוע הזה עוקב אחרי תחילת התחזוקה של התשתית לחיבור בין רשתות. במהלך אירוע התחזוקה, סשנים של Border Gateway Protocol (BGP) בקבצים מצורפים של רשת מקומית וירטואלית (VLAN) מושבתים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id("maintenance.googleapis.com/maintenance_events")
jsonPayload.resource.type="compute.googleapis.com/Interconnect"
jsonPayload.state="RUNNING"
labels."maintenance.googleapis.com/updated_fields" : "state"
מידע נוסף זמין במאמר בנושא אירועי תחזוקה של התשתית.
התחזוקה של Interconnect הסתיימה
סוג האירוע הזה עוקב אחרי סיום התחזוקה של התשתית בחיבור בין רשתות. כתובות ה-MAC של מכשיר הקצה ברשת אתרנט יכולות להשתנות אחרי אירועי תחזוקה מסוימים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id("maintenance.googleapis.com/maintenance_events")
jsonPayload.resource.type="compute.googleapis.com/Interconnect"
jsonPayload.state="SUCCEEDED"
labels."maintenance.googleapis.com/updated_fields" : "state"
מידע נוסף זמין במאמר בנושא אירועי תחזוקה של התשתית.
סוגי אירועים ב-Cloud VPN
בקטע הזה מתוארים סוגי האירועים של Cloud VPN שאפשר להציג בלוח בקרה.
תחזוקת VPN
סוג האירוע הזה עוקב אחרי תחזוקת התשתית של משימת VPN. האירועים האלה כוללים את האירועים 'התחלת תחזוקה' ו'השלמת תחזוקה'.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id("cloud.googleapis.com/ipsec_events")
resource.type="vpn_gateway"
(
textPayload:"Starting VPN task maintenance" OR
textPayload:"VPN task maintenance Completed"
)
הצרה של בוררי התנועה ב-VPN
סוג האירוע הזה עוזר לזהות מתי מצמצמים את בוררי התנועה עבור SA צאצא. הנתונים האלה כוללים אירועים של בוררי תנועה מקומיים ומרחוקים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id("cloud.googleapis.com/ipsec_events")
resource.type="vpn_gateway"
(
textPayload:"Warning: Local traffic selectors narrowed for Child SA" OR
textPayload:"Warning: Remote traffic selectors narrowed for Child SA"
)
סוגי אירועים ב-Compute Engine
בקטע הזה מפורטים סוגי האירועים ב-Compute Engine שאפשר להציג בלוח בקרה.
סגירת מכונות וירטואליות
סוג האירוע הזה עוזר לכם לזהות סיומים של מכונות וירטואליות (VM), כולל איפוסים ועצירות שהופעלו באופן ידני, סיומים של מערכת הפעלה אורחת, סיומים של תחזוקה ושגיאות של המארח.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
מידע נוסף זמין במאמרים הפעלה והפסקה של מכונה וירטואלית ופתרון בעיות בהשבתה והפעלה מחדש של מכונות וירטואליות.
כשל בהפעלת מופע של VM
האירוע הזה עוקב אחרי כשלים בהפעלת מכונות וירטואליות של Compute Engine. האירוע מציג כשלים בהתחלה בגלל חוסר במלאי, מיצוי של מרחב כתובות IP, חריגה ממכסת השימוש או שגיאות בשלמות של מכונות וירטואליות מוגנות.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
שגיאה במערכת ההפעלה האורחת של מכונת VM
האירוע הזה עוקב אחרי שגיאות ספציפיות במערכת ההפעלה האורחת של מופע VM ב-Compute Engine, כפי שנרשמו ביומני המסוף הטורי. השגיאות שמתבצע אחריהן מעקב הן: הכונן מלא, טעינת מערכת הקבצים נכשלה וכשלי הפעלה שמפעילים את מצב החירום של Linux.
כדי שהאירועים האלה יהיו גלויים, צריך להפעיל את רישום הפלט של היציאה הטורית ב-Cloud Logging על ידי הגדרת serial-port-logging-enable=true במכונה הווירטואלית או במטא-נתונים של הפרויקט. מידע נוסף זמין במאמר בנושא הפעלה והשבתה של רישום ביומן של פלט יציאה טורית.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
עדכון של קבוצת מופעי מכונה מנוהלים
סוג האירוע הזה עוזר לכם לזהות מתי קבוצת מופעי המכונה המנוהלים (MIG) שלכם עודכנה. לדוגמה, מכונות וירטואליות נוספו או הוסרו, או שמגבלת הגודל עודכנה. למידע נוסף, ראו החלה אוטומטית של עדכוני הגדרות של מכונות וירטואליות בקבוצת MIG.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
מידע נוסף זמין במאמרים בנושא עבודה עם מופעים מנוהלים ופתרון בעיות בקבוצות של מופעים מנוהלים.
הכלי לשינוי גודל אוטומטי של קבוצת מופעי מכונה מנוהלים
האירוע הזה עוקב אחרי החלטות לגבי שינוי גודל שמתקבלות על ידי קנה המידה האוטומטי של MIG. ההחלטות האלה יכולות לכלול שינויים בגודל המומלץ של קבוצת MIG, או שינוי בסטטוס של קנה המידה האוטומטי עצמו. מידע נוסף זמין במאמר בנושא קבוצות של מופעים עם שינוי גודל אוטומטי.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
סוגי אירועים במרכז האישי ב-Service Health
בקטע הזה מתוארים הסוגים של המרכז האישי ב-Service Health שאפשר להציג בלוח בקרה.
Google Cloud אירוע
במהלך פתרון בעיות, יכול להיות שתרצו להבחין בין כשלים שנגרמים על ידי שירות שבבעלותכם לבין כשלים שנגרמים על ידי שירותGoogle Cloud שאתם משתמשים בו. כשמפעילים את ההערות של המרכז האישי ב-Service Health בלוח הבקרה, אפשר לראות שיבושים או אירועים שקשורים לזמינות של שירותים ב- Google Cloud שירותים. כאן אפשר לראות רשימה של שירותים שמשולבים עם Service Health.
בניגוד לסוגים אחרים של אירועים, Google Cloud אירועים לא מזוהים באמצעות ניתוח של רשומות ביומן. אם רוצים לקבל התראה כשהאירועים האלה מתרחשים, צריך ליצור מדיניות התראות. אפשר לבחור מדיניות התראות שהוגדרה מראש באמצעות האפשרויות בדף Service Health Dashboard. מידע נוסף זמין במאמר מדריך למתחילים: הגדרת התראה.
Monitoring מזהה Google Cloud אירועים על ידי שליחת בקשה אל Service Health API, ואז מסנן את התגובה לאירועים שרלוונטיים לנתונים שמוצגים. הבקשה כוללת את ההגדרות הבאות:
הספירה
Relevanceמוגדרת לערכיםRELATED,IMPACTEDאוPARTIALLY_RELATED. ההגבלה הזו מבטיחה שבלוח הבקרה יוצגו רק אירועים שקשורים ל Google Cloud שירותים שבהם נעשה שימוש בפרויקטGoogle Cloud .הערך של המונה
DetailedStateלא מוגדר כ-FALSE_POSITIVE.
ההערות ב-Service Health מוצגות עם שעת התחלה ומשך. המשך מוצג על ידי שינוי צבע הרקע של התרשים. בהסבר הקצר על Google Cloud אירוע מופיעים הפרטים הבאים:
- שירות Google Cloud .
- האם התקרית פתוחה או נפתרה.
- התאריך ושעת ההתחלה של האירוע.
- צ'יפים שבהם מוצגים מספר המוצרים והמיקומים המושפעים. כדי לראות את המוצרים או המיקומים הרלוונטיים, מציבים את מצביע העכבר מעל הצ'יפ המתאים.
- לחצן View, שכשלוחצים עליו נפתח דף הפרטים של האירוע.
למידע על שליחת בקשה ל-Service Health API, קראו את המאמר בדיקת שיבושים באמצעות Service Health.
מידע על פתרון בעיות זמין במאמר פתרון בעיות נפוצות ב-Service Health.
סוגי אירועים של בדיקת זמינות
בקטע הזה מתוארים סוגי האירועים של בדיקת זמינות שאפשר להציג בלוח בקרה.
כשל בבדיקת זמני פעילות
סוג האירוע הזה עוזר לכם לזהות כשלים בבדיקות זמינות מאזורים מוגדרים.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
מידע לפתרון בעיות זמין במאמר פתרון בעיות בבדיקות סינתטיות ובבדיקות זמינות.
סוגי אירועים של Agent for SAP
בקטע הזה מתוארים סוגי האירועים של Agent for SAP שאפשר להציג בלוח בקרה.
זמינות של SAP
סוג האירוע הזה עוזר לכם לזהות אירועים שקשורים לזמינות של Agent for SAP. האירועים האלה מופעלים כשזמינות של SAP HANA, SAP NetWeaver או Pacemaker Cluster משתנה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
סוג האירוע הזה עוזר לכם לזהות אירועים שקשורים ל-Agent for SAP Backint. כל גיבוי או שחזור של Backint כותב אירוע עם פרטים על הצלחה או כישלון, יחד עם נתוני ההעברה. גיבויים ושחזורים של יומנים מוצגים רק במקרה של כשל, בעוד שגיבויים ושחזורים של נתונים מוצגים גם במקרה של הצלחה וגם במקרה של כשל.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
SAP Operations
סוג האירוע הזה עוזר לכם לזהות אירועים שקשורים לפעולות של Agent for SAP. האירועים האלה מופעלים כשסטטוס השכפול של SAP HANA משתנה.
אם רוצים ליצור מדיניות התראות שמבוססת על יומנים לסוג האירוע הזה, משתמשים בשאילתה הבאה:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
המאמרים הבאים
במאמר הצגת אירועים בלוח בקרה מוסבר איך להציג אירועים בלוחות הבקרה.