
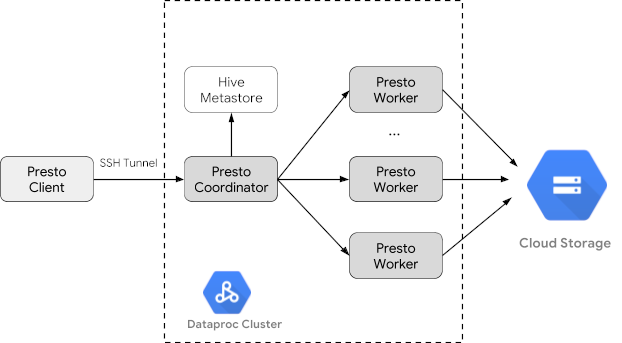
Trino(旧 Presto)は、1 つ以上の異種混合データソースに分散された大規模なデータセットをクエリするために設計された分散 SQL クエリエンジンです。Trino は、コネクタを介して Hive、MySQL、Kafka などのデータソースに対してクエリを実行できます。このチュートリアルでは、次の方法について説明します。
- Managed Service for Apache Spark クラスタに Trino サービスをインストールする
- クラスタ上の Trino サービスと通信するローカルマシンにインストールされた Trino クライアントから一般公開データをクエリする
- Trino Java JDBC ドライバを介してクラスタ上の Trino サービスと通信する Java アプリケーションからクエリを実行する
目標
- BigQuery からデータを抽出する
- データを CSV ファイルとして Cloud Storage にデータを読み込む
- データを変換する
- データを Hive 外部テーブルとして公開し、Trino でデータをクエリ可能にする
- データを CSV 形式から Parquet 形式に変換してクエリを高速化する
費用
このドキュメントでは、課金対象である次の コンポーネントを使用します Google Cloud:
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
まだ作成していない場合は、 Google Cloud プロジェクトとこのチュートリアルで使用するデータを保持する Cloud Storage バケットを作成します。 1. プロジェクトの設定- アカウントにログインします。 Google Cloud を初めて使用する場合は、 アカウントを作成して、実際のシナリオで Google プロダクトのパフォーマンスを評価してください。 Google Cloud新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Google Cloud CLI をインストールします。
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
Google Cloud CLI をインストールします。
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します:
gcloud init
- コンソールで Cloud Storage の Google Cloud [**バケット**] ページに移動します。
- [ [Create]] をクリックします。
- [バケットの作成] ページでユーザーのバケット情報を入力します。次のステップに進むには、[続行] をクリックします。
- [スタートガイド] セクションで、次の操作を行います。
-
[データの保存場所の選択] セクションで、次の操作を行います。
- ロケーション タイプを選択してください。
- [Location type] プルダウン メニューから、バケットのデータが永続的に保存されるロケーションを選択します。
- ロケーション タイプとして [デュアルリージョン] を選択した場合は、関連するチェックボックスを使用して [ターボ レプリケーション] を有効にすることもできます。
- クロスバケット レプリケーションを設定するには、
[Storage Transfer Service 経由でクロスバケット レプリケーションを追加する] を選択し、
次の手順を実施します:
クロスバケット レプリケーションを設定する
- [バケット] メニューで、バケットを選択します。
[レプリケーション設定] セクションで、[構成] をクリックして、レプリケーション ジョブの設定を構成します。
[**クロスバケット レプリケーションを構成する**] ペインが表示されます。
- オブジェクト名の接頭辞で複製するオブジェクトをフィルタするには、 オブジェクトを追加または除外する接頭辞を入力し、 [接頭辞を追加] をクリックします。
- 複製されたオブジェクトのストレージ クラスを設定するには、 [Storage class] メニューからストレージ クラスを選択します。 この手順をスキップすると、複製されたオブジェクトはデフォルトで宛先バケットのストレージ クラスを使用します。
- [完了] をクリックします。
-
[データの保存場所の選択] セクションで、次の操作を行います。
- バケットのデフォルトのストレージ クラスを選択するか、バケットデータのストレージ クラスを自動的に管理するAutoclassを選択します。
- 階層名前空間を有効にするには、 [データ量が多いワークロード向けにストレージを最適化] セクションで、 [このバケットで階層的な名前空間を有効にする] を選択します。
- In the [オブジェクトへのアクセスを制御する方法を選択する] セクションで、バケットに 公開アクセスの防止 を適用するかどうかを選択し、バケットのオブジェクトに使用する アクセス制御方法 を選択します。
-
[オブジェクト データを保護する方法を選択する] セクションで、次の操作を行います。
- [**データ保護**] で、バケットに設定するオプションを選択します。
- 削除(復元可能)を有効にするには、 [削除(復元可能)ポリシー(データ復旧用)] チェックボックスをオンにして、 削除後にオブジェクトを保持する日数を指定します。
- [オブジェクトのバージョニング]を設定するには、 [オブジェクトのバージョニング(バージョン管理用)] チェックボックスをオンにして、 オブジェクトごとのバージョンの最大数と、 非現行バージョンが期限切れになるまでの日数を指定します。
- オブジェクトとバケットで保持ポリシーを有効にするには、[保持(コンプライアンス用)] チェックボックスをオンにして、次の操作を行います。
- [オブジェクト保持ロック]を有効にするには、 [オブジェクト保持を有効にする]チェックボックスをオンにします。
- [Bucket Lock] を有効にするには、[バケット保持ポリシーを設定する] チェックボックスをオンにして、保持期間の単位と保持期間を選択します。
- オブジェクト データの暗号化方法を選択するには、 [データ暗号化] セクション()を開き、 [データの暗号化] 方法を選択します。
- [**データ保護**] で、バケットに設定するオプションを選択します。
- [作成] をクリックします。
Managed Service for Apache Spark クラスタを作成する
optional-components フラグ
(イメージ バージョン 2.1 以降で使用可能)を使用して、Managed Service for Apache Spark クラスタを作成し、クラスタに
Trino オプション コンポーネントをインストールします。また、enable-component-gateway フラグを使用して、
コンポーネント ゲートウェイを有効にし、
コンソールから Trino ウェブ UI にアクセスできるようにします。 Google Cloud
- 環境変数を設定する
- PROJECT: プロジェクト ID
- BUCKET_NAME: 始める前にで作成した Cloud Storage バケットの名前
- REGION: このチュートリアルで使用するクラスタが作成されるリージョン。例: 「us-west1」
- WORKERS: このチュートリアルでは 3~5 人のワーカーをおすすめします
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- ローカルマシンで Google Cloud CLI を実行して、クラスタを作成します。
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
データの準備
bigquery-public-data の chicago_taxi_trips データセットを CSV ファイルとして Cloud Storage にエクスポートし、データを参照する Hive 外部テーブルを作成します。
- ローカルマシンで次のコマンドを実行して、始める前にで作成した Cloud Storage バケットに、BigQuery のタクシーデータをヘッダーのない CSV ファイルとしてインポートします。
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Cloud Storage バケット内の CSV ファイルと Parquet ファイルに基づいて Hive 外部テーブルを作成します。
- Hive 外部テーブル
chicago_taxi_trips_csvを作成します。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Hive 外部テーブルの作成を確認します。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - 同じ列に別の Hive 外部テーブル
chicago_taxi_trips_parquetを作成します。ただし、クエリ パフォーマンスを向上させるために、データは Parquet 形式で保存します。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Hive CSV テーブルから Hive Parquet テーブルにデータを読み込みます。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - データが正しく読み込まれたことを確認します。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Hive 外部テーブル
クエリを実行する
クエリは、Trino CLI またはアプリケーションからローカルで実行できます。
Trino CLI のクエリ
このセクションでは、Trino CLI を使用して Hive Parquet taxi データセットをクエリする方法を説明します。
- ローカルマシンで次のコマンドを実行して、クラスタのマスターノードに SSH 接続します。コマンドの実行中、ローカル ターミナルは応答しなくなります。
gcloud compute ssh trino-cluster-m
- クラスタのマスターノードの SSH ターミナル ウィンドウで、マスターノードで実行されている Trino サーバーに接続する Trino CLI を実行します。
trino --catalog hive --schema default
trino:defaultプロンプトで、Trino で Hive テーブルの検出が可能なことを確認します。show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
trino:defaultプロンプトからクエリを実行し、Parquet と CSV データのクエリのパフォーマンスを比較します。- Parquet データのクエリ
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV データのクエリ
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet データのクエリ
Java アプリケーションのクエリ
Trino Java JDBC ドライバを介して Java アプリケーションからクエリを実行する方法は次のとおりです。
1. Trino Java JDBC ドライバをダウンロードします。
1. Maven pom.xml にある trino-jdbc 依存関係を追加します。
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}ロギングとモニタリング
ロギング
Trino のログは、クラスタのマスターノードとワーカーノードの /var/log/trino/ にあります。
ウェブ UI
クラスタのマスターノード上で実行されている Trino ウェブ UI をローカル ブラウザで開くには、コンポーネント ゲートウェイの URL を表示してアクセスするをご覧ください。
モニタリング
Trino は、ランタイム テーブルを介してクラスタのランタイム情報を公開します。(trino:default からの)Trino セッションのプロンプトで、次のクエリを実行してランタイム テーブルのデータを表示します。
select * FROM system.runtime.nodes;
クリーンアップ
チュートリアルが終了したら、作成したリソースをクリーンアップして、割り当ての使用を停止し、課金されないようにできます。次のセクションで、リソースを削除または無効にする方法を説明します。
プロジェクトの削除
課金されないようにする最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- コンソールで [**リソースの管理**] ページに移動します。 Google Cloud
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、 [Shut down] をクリックしてプロジェクトを削除します。
クラスタの削除
- クラスタを削除するには:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
バケットの削除
- 始める前にで作成した Cloud Storage バケットを削除する(バケットに保存されているデータファイルを含む)には:
gcloud storage rm gs://${BUCKET_NAME} --recursive