
Puoi creare un cluster Managed Service for Apache Spark con un'immagine personalizzata che include i pacchetti preinstallati. Questa pagina mostra come creare un'immagine personalizzata e installarla su un cluster Managed Service for Apache Spark.
Considerazioni e limitazioni sull'utilizzo
Durata dell'immagine personalizzata:per garantire che i cluster ricevano gli aggiornamenti del servizio e le correzioni di bug più recenti, la creazione di cluster con un'immagine personalizzata è limitata a 365 giorni dalla data di creazione dell'immagine personalizzata. Tieni presente che i cluster esistenti creati con un'immagine personalizzata possono essere eseguiti a tempo indeterminato.
Potresti dover utilizzare l'automazione se vuoi creare cluster con un'immagine personalizzata specifica per un periodo superiore a 365 giorni. Per saperne di più, consulta Crea un cluster con un'immagine personalizzata scaduta.
Solo Linux: le istruzioni riportate in questo documento si applicano solo ai sistemi operativi Linux. Altri sistemi operativi potrebbero essere supportati nelle future release di Managed Service for Apache Spark.
Immagini di base supportate:le build di immagini personalizzate richiedono l'avvio da un'immagine di base di Managed Service for Apache Spark. Sono supportate le seguenti immagini di base:Debian, Rocky Linux e Ubuntu.
- Disponibilità delle immagini di base: le nuove immagini annunciate nelle note di rilascio di Managed Service for Apache Spark non sono disponibili per l'utilizzo come base per le immagini personalizzate fino a una settimana dopo la data dell'annuncio.
Utilizzo di componenti facoltativi:
2.2e immagini di base precedenti: per impostazione predefinita, tutti i componenti facoltativi di Managed Service for Apache Spark (pacchetti e configurazioni del sistema operativo) sono installati sull'immagine personalizzata. Puoi personalizzare le versioni e le configurazioni dei pacchetti del sistema operativo.2.3e successive: solo i componenti facoltativi selezionati vengono installati nell'immagine personalizzata (vedi ilgenerate_custom_image.pyflag --optional-components).
Indipendentemente dall'immagine di base utilizzata per l'immagine personalizzata, quando crei il cluster, devi elencare o selezionare i componenti facoltativi.
Esempio: comando di creazione del cluster Google Cloud CLI:
gcloud dataproc clusters create CLUSTER_NAME --image=CUSTOM_IMAGE_URI \ --optional-components=COMPONENT_NAME \ ... other flags
Se il nome del componente non viene specificato durante la creazione del cluster, il componente facoltativo, inclusi eventuali pacchetti e configurazioni del sistema operativo personalizzati, verrà eliminato.
Utilizzo di immagini personalizzate ospitate:se utilizzi un'immagine personalizzata ospitata in un altro progetto, il service account dell'agente di servizio Managed Service for Apache Spark nel tuo progetto deve disporre dell'autorizzazione
compute.images.getper l'immagine nel progetto host. Puoi concedere questa autorizzazione assegnando il ruoloroles/compute.imageUserall'immagine ospitata al service account dell'agente di servizio Managed Service for Apache Spark del tuo progetto (vedi Condivisione di immagini personalizzate all'interno di un'organizzazione).Utilizzo dei secret MOK (Machine Owner Key) di avvio protetto: Per attivare l'avvio protetto con l'immagine personalizzata di Managed Service for Apache Spark, procedi nel seguente modo:
Abilita l'API Secret Manager (
secretmanager.googleapis.com. Managed Service for Apache Spark genera e gestisce una coppia di chiavi utilizzando il servizio Secret Manager.Aggiungi il flag
--service-account="SERVICE_ACCOUNT"al comandogenerate_custom_image.pyquando generi un'immagine personalizzata. Nota: devi concedere al account di servizio il ruolo Secret Manager Viewer (roles/secretmanager.viewer) nel progetto e il ruolo Secret Manager Accessor (roles/secretmanager.secretAccessor) nei secret pubblici e privati.Per maggiori informazioni con esempi, consulta
README.mde altri file all'interno della directory examples/secure-boot del repositoryGoogleCloudDataproc/custom-imagessu GitHub.Per disattivare l'avvio protetto:per impostazione predefinita, gli script di immagini personalizzate di Managed Service for Apache Spark generano e gestiscono una coppia di chiavi utilizzando Secret Manager quando vengono eseguiti da un cluster Managed Service for Apache Spark. Se non vuoi utilizzare l'avvio protetto con la tua immagine personalizzata, includi
--trusted-cert=""(valore del flag vuoto) nel comandogenerate_custom_image.pyquando generi l'immagine personalizzata.
Prima di iniziare
Assicurati di configurare il progetto prima di generare l'immagine personalizzata.
Configura il progetto
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc API, Compute Engine API, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installa Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc API, Compute Engine API, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Installa Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init - Installa Python 3.11 o versioni successive
- Prepara uno script di personalizzazione che installi pacchetti personalizzati e/o
aggiorni le configurazioni, ad esempio:
#! /usr/bin/bash apt-get -y update apt-get install python-dev apt-get install python-pip pip install numpy
crea un bucket Cloud Storage nel tuo progetto
- Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci le informazioni sul bucket. Per passare al passaggio successivo, fai clic su Continua.
-
Nella sezione Inizia, segui questi passaggi:
- Inserisci un nome univoco globale che soddisfi i requisiti per la denominazione dei bucket.
- Per aggiungere un'etichetta bucket, espandi la sezione Etichette (), fai clic su add_box
Aggiungi etichetta e specifica un
keye unvalueper l'etichetta.
-
Nella sezione Scegli dove archiviare i tuoi dati, segui questi passaggi:
- Seleziona un Tipo di località.
- Scegli una posizione in cui i dati del bucket vengono archiviati in modo permanente dal menu a discesa Tipo di località.
- Se selezioni il tipo di località a due regioni, puoi anche scegliere di attivare la replica turbo utilizzando la casella di controllo pertinente.
- Per configurare la replica tra bucket, seleziona
Aggiungi una replica tra bucket mediante Storage Transfer Service e
segui questi passaggi:
Configura la replica tra bucket
- Nel menu Bucket, seleziona un bucket.
Nella sezione Impostazioni di replica, fai clic su Configura per configurare le impostazioni per il job di replica.
Viene visualizzato il riquadro Configura replica tra bucket.
- Per filtrare gli oggetti da replicare in base al prefisso del nome dell'oggetto, inserisci un prefisso da cui includere o escludere gli oggetti, quindi fai clic su Aggiungi un prefisso.
- Per impostare una classe di archiviazione per gli oggetti replicati, seleziona una classe di archiviazione dal menu Classe di archiviazione. Se salti questo passaggio, gli oggetti replicati utilizzeranno per impostazione predefinita la classe di archiviazione del bucket di destinazione.
- Fai clic su Fine.
-
Nella sezione Scegli come archiviare i tuoi dati, segui questi passaggi:
- Seleziona una classe di archiviazione predefinita per il bucket o Autoclass per la gestione automatica della classe di archiviazione dei dati del bucket.
- Per attivare lo spazio dei nomi gerarchico, nella sezione Ottimizza l'archiviazione per workload con uso intensivo dei dati, seleziona Abilita uno spazio dei nomi gerarchico in questo bucket.
- Nella sezione Scegli come controllare l'accesso agli oggetti, seleziona se il bucket applica o meno la prevenzione dell'accesso pubblico e seleziona un metodo di controllo dell'accesso per gli oggetti del bucket.
-
Nella sezione Scegli come proteggere i dati degli oggetti, segui questi passaggi:
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
- Per attivare l'eliminazione temporanea, fai clic sulla casella di controllo Policy di eliminazione temporanea (per il recupero dei dati) e specifica il numero di giorni per cui vuoi conservare gli oggetti dopo l'eliminazione.
- Per impostare il controllo delle versioni degli oggetti, seleziona la casella di controllo Controllo delle versioni degli oggetti (per il controllo delle versioni) e specifica il numero massimo di versioni per oggetto e il numero di giorni dopo i quali scadono le versioni non correnti.
- Per attivare il criterio di conservazione su oggetti e bucket, seleziona la casella di controllo Conservazione (per la conformità), quindi procedi nel seguente modo:
- Per attivare il blocco della conservazione degli oggetti, fai clic sulla casella di controllo Abilita conservazione degli oggetti.
- Per attivare Bucket Lock, fai clic sulla casella di controllo Imposta criterio di conservazione del bucket e scegli un'unità di tempo e una durata per il periodo di conservazione.
- Per scegliere come verranno criptati i dati degli oggetti, espandi la sezione Crittografia dei dati () e seleziona un metodo di crittografia dei dati.
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
-
Nella sezione Inizia, segui questi passaggi:
- Fai clic su Crea.
Generare un'immagine personalizzata
Utilizzi generate_custom_image.py, un programma Python, per creare un'immagine personalizzata di Managed Service for Apache Spark.
Come funziona
Il programma generate_custom_image.py avvia un'istanza VM Compute Engine temporanea con l'immagine di base Managed Service for Apache Spark specificata, quindi esegue lo script di personalizzazione all'interno dell'istanza VM per installare pacchetti personalizzati e/o aggiornare le configurazioni. Al termine dello script di personalizzazione, l'istanza VM viene arrestata e viene creata un'immagine personalizzata di Managed Service for Apache Spark dal disco dell'istanza VM. La VM temporanea viene eliminata dopo la creazione dell'immagine personalizzata. L'immagine personalizzata viene salvata e può essere utilizzata per
creare cluster Managed Service for Apache Spark.
Il programma generate_custom_image.py utilizza gcloud CLI
per eseguire flussi di lavoro in più passaggi su Compute Engine.
Esegui il codice
Fork o clona i file su GitHub all'indirizzo Managed Service for Apache Spark custom images.
Poi, esegui lo script generate_custom_image.py per fare in modo che Managed Service for Apache Spark
generi e salvi l'immagine personalizzata.
python3 generate_custom_image.py \ --image-name=CUSTOM_IMAGE_NAME \ [--family=CUSTOM_IMAGE_FAMILY_NAME] \ --dataproc-version=IMAGE_VERSION \ --customization-script=LOCAL_PATH \ --zone=ZONE \ --gcs-bucket=gs://BUCKET_NAME \ [--no-smoke-test]
Flag obbligatori
--image-name: il nome dell'output per l'immagine personalizzata.--dataproc-version: la versione dell'immagine di Managed Service for Apache Spark da utilizzare nell'immagine personalizzata. Specifica la versione nel formatox.y.z-osox.y.z-rc-os, ad esempio "2.0.69-debian10".--customization-script: un percorso locale del tuo script che lo strumento eseguirà per installare i pacchetti personalizzati o eseguire altre personalizzazioni. Questo script viene eseguito come script di avvio Linux solo sulla VM temporanea utilizzata per creare l'immagine personalizzata. Puoi specificare uno script di inizializzazione diverso per altre azioni di inizializzazione che vuoi eseguire quando crei un cluster con la tua immagine personalizzata.Immagini tra progetti:se la tua immagine personalizzata viene utilizzata per creare cluster in progetti diversi, può verificarsi un errore a causa della cache dei comandi
gcloudogsutilarchiviata nell'immagine. Puoi evitare questo problema includendo il seguente comando nello script di personalizzazione per cancellare le credenziali memorizzate nella cache.rm -r /root/.gsutil /root/.config/gcloud
--zone: la zona Compute Engine in cuigenerate_custom_image.pycreerà una VM temporanea da utilizzare per creare l'immagine personalizzata.--gcs-bucket: un URI nel formatogs://BUCKET_NAMEche punta al tuo bucket Cloud Storage.generate_custom_image.pyscrive i file di log in questo bucket.
--family: la famiglia di immagini per l'immagine personalizzata. Le famiglie di immagini vengono utilizzate per raggruppare immagini simili e possono essere utilizzate durante la creazione di un cluster come puntatore all'immagine più recente della famiglia. Ad esempio,custom-2-2-debian12.--no-smoke-test: questo è un flag facoltativo che disattiva lo smoke test della nuova immagine personalizzata. Lo smoke test crea un cluster di test Managed Service for Apache Spark con l'immagine appena creata, esegue un piccolo job e poi elimina il cluster al termine del test. Lo smoke test viene eseguito per impostazione predefinita per verificare che la nuova immagine personalizzata possa creare un cluster Managed Service for Apache Spark funzionale. La disattivazione di questo passaggio utilizzando il flag--no-smoke-testvelocizza il processo di compilazione dell'immagine personalizzata, ma il suo utilizzo non è consigliato.--subnet: la subnet da utilizzare per creare la VM che crea l'immagine personalizzata di Managed Service for Apache Spark. Se il tuo progetto fa parte di un VPC condiviso, devi specificare l'URL completo della subnet nel seguente formato:projects/HOST_PROJECT_ID/regions/REGION/subnetworks/SUBNET.--optional-components: questo flag è disponibile solo quando si utilizzano versioni dell'immagine di base2.3e successive. Un elenco di componenti facoltativi, come SOLR, RANGER, TRINO, DOCKER, FLINK, HIVE_WEBHCAT, ZEPPELIN, HUDI, ICEBERG e PIG (PIG è disponibile come componente facoltativo nelle versioni dell'immagine2.3e successive), da installare nell'immagine.Esempio: comando di creazione del cluster Google Cloud CLI:
gcloud dataproc clusters create CLUSTER_NAME --image=CUSTOM_IMAGE_URI \ --optional-components=COMPONENT_NAME \ ... other flags
Per un elenco dei flag facoltativi disponibili, consulta Optional Arguments su GitHub.
Se generate_custom_image.py ha esito positivo, l'imageURI dell'immagine personalizzata viene
visualizzato nell'output della finestra del terminale (l'imageUri completo è mostrato in grassetto di seguito):
...
managedCluster:
clusterName: verify-image-20180614213641-8308a4cd
config:
gceClusterConfig:
zoneUri: ZONE
masterConfig:
imageUri: https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME
...
INFO:__main__:Successfully built Dataproc custom image: CUSTOM_IMAGE_NAME
INFO:__main__:
#####################################################################
WARNING: DATAPROC CUSTOM IMAGE 'CUSTOM_IMAGE_NAME'
WILL EXPIRE ON 2018-07-14 21:35:44.133000.
#####################################################################
Etichette personalizzate delle versioni immagine (utilizzo avanzato)
Quando utilizzi lo strumento per immagini personalizzate standard di Managed Service for Apache Spark, lo strumento
imposta un'etichetta goog-dataproc-version sull'immagine
personalizzata creata. L'etichetta riflette le funzionalità e i protocolli utilizzati da
Managed Service for Apache Spark per gestire il software sull'immagine.
Utilizzo avanzato: se utilizzi una procedura personalizzata per creare un'immagine Managed Service for Apache Spark personalizzata, devi aggiungere manualmente l'etichetta goog-dataproc-version all'immagine personalizzata, nel seguente modo:
Estrai l'etichetta
goog-dataproc-versiondall'immagine di base di Managed Service for Apache Spark utilizzata per creare l'immagine personalizzata.gcloud compute images describe ${BASE_DATAPROC_IMAGE} \ --project cloud-dataproc \ --format="value(labels.goog-dataproc-version)"Imposta l'etichetta sull'immagine personalizzata.
gcloud compute images add-labels IMAGE_NAME --labels=[KEY=VALUE,...]
Utilizza un'immagine personalizzata
Specifichi l'immagine personalizzata quando crei un cluster Managed Service for Apache Spark. Un'immagine personalizzata viene salvata in Cloud Compute Images ed è valida per creare un cluster Managed Service for Apache Spark per 365 giorni dalla data di creazione (vedi Creare un cluster con un'immagine personalizzata scaduta per utilizzare un'immagine personalizzata dopo la data di scadenza di 365 giorni).
URI immagine personalizzato
Trasferisci imageUri dell'immagine personalizzata all'operazione di creazione del cluster.
Questo URI può essere specificato in uno dei tre modi seguenti:
- URI completo:
https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/`gs://`BUCKET_NAME` - URI parziale:
projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME - Nome breve: CUSTOM_IMAGE_NAME
Le immagini personalizzate possono essere specificate anche tramite il relativo URI della famiglia, che sceglie sempre l'immagine più recente all'interno della famiglia di immagini.
- URI completo:
https://www.googleapis.com/compute/beta/projects/PROJECT_ID/global/images/family/CUSTOM_IMAGE_FAMILY_NAME/var> - URI parziale:
projects/PROJECT_ID/global/images/family/CUSTOM_IMAGE_FAMILY_NAME
Trovare l'URI immagine personalizzato
Google Cloud CLI
Esegui questo comando per elencare i nomi delle tue immagini personalizzate.
gcloud compute images list
Passa il nome della tua immagine personalizzata al comando seguente per elencare
l'URI (selfLink) della tua immagine personalizzata.
gcloud compute images describe custom-image-name
Snippet di output:
... name: CUSTOM_IMAGE_NAME selfLink: https://www.googleapis.com/compute/v1/projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME ...
Console
- Apri la pagina
Compute Engine→Immagini
nella console Google Cloud , quindi fai clic sul nome dell'immagine.
Puoi inserire una query nel campo
filter imagesper limitare il numero di immagini visualizzate.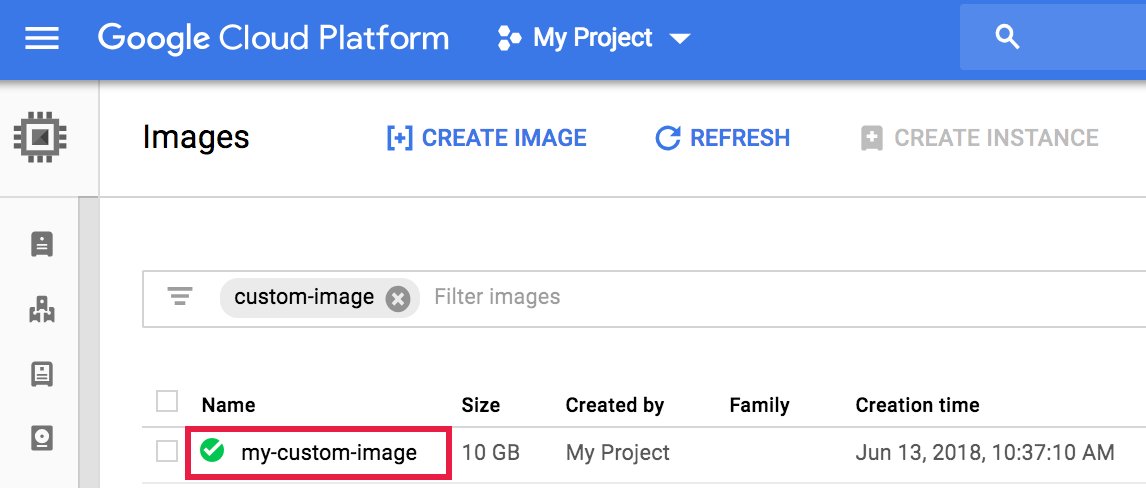
- Viene visualizzata la pagina Dettagli immagini. Fai clic su
REST equivalente.
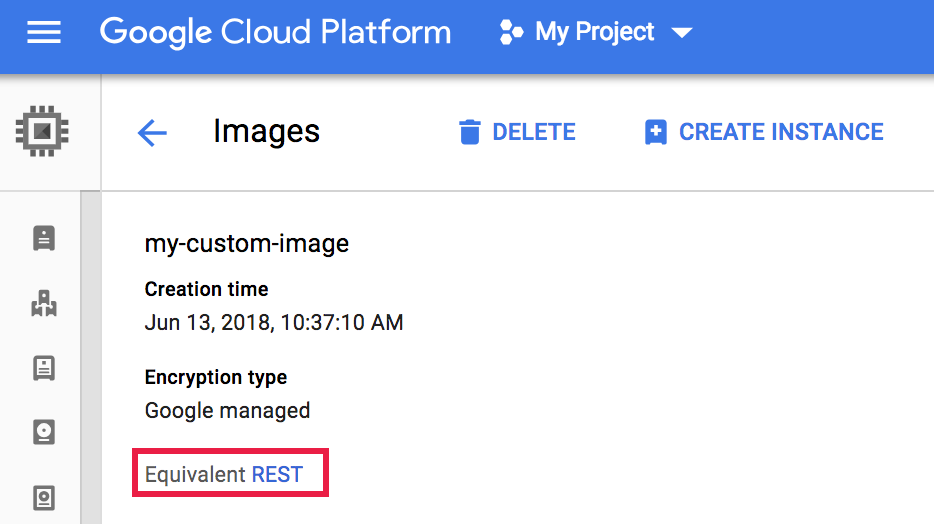
- La risposta REST elenca informazioni aggiuntive sull'immagine, tra cui
selfLink, ovvero l'URI dell'immagine.{ ... "name": "my-custom-image", "selfLink": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME", "sourceDisk": ..., ... }
Crea un cluster con un'immagine personalizzata
Crea un cluster con utilizzando gcloud CLI, l'API Managed Service for Apache Spark o la consoleGoogle Cloud .
Interfaccia a riga di comando gcloud
Crea un cluster Managed Service for Apache Spark con un'immagine personalizzata utilizzando il comando
dataproc clusters create
con il flag --image.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM_IMAGE_URI \ --region=REGION \ ... other flags
API REST
Crea un cluster con un'immagine personalizzata specificando l'URI dell'immagine personalizzata
nel campo
InstanceGroupConfig.imageUri
nell'oggetto masterConfig, workerConfig e, se applicabile,
secondaryWorkerConfig incluso in una
richiesta API
cluster.create.
Esempio: richiesta REST per creare un cluster Managed Service for Apache Spark standard (un nodo master, due nodi worker) con un'immagine personalizzata.
POST /v1/projects/PROJECT_ID/regions/REGION/clusters/
{
"clusterName": "CLUSTER_NAME",
"config": {
"masterConfig": {
"imageUri": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME"
},
"workerConfig": {
"imageUri": "projects/PROJECT_ID/global/images/CUSTOM_IMAGE_NAME"
}
}
}
Console
- Apri la pagina Managed Service for Apache Spark Crea un cluster. Il riquadro Configura cluster è selezionato.
- Nella sezione Controllo delle versioni, fai clic su Cambia. Seleziona la scheda Immagine personalizzata, scegli l'immagine personalizzata da utilizzare per il cluster Managed Service for Apache Spark, quindi fai clic su Seleziona. Le VM del cluster verranno sottoposte al provisioning con l'immagine personalizzata selezionata.
Eseguire l'override delle proprietà del cluster Managed Service for Apache Spark con un'immagine personalizzata
Puoi utilizzare immagini personalizzate per sovrascrivere le proprietà del cluster impostate durante la creazione del cluster. Se crei un cluster con un'immagine personalizzata e l'operazione di creazione del cluster imposta proprietà con valori diversi da quelli impostati dall'immagine personalizzata, i valori delle proprietà impostati dall'immagine personalizzata avranno la precedenza.
Per impostare le proprietà del cluster con la tua immagine personalizzata:
Nello script di personalizzazione dell'immagine personalizzata, crea un file
dataproc.custom.propertiesin/etc/google-dataproc, poi imposta i valori delle proprietà del cluster nel file.- File
dataproc.custom.propertiescampione:
dataproc.conscrypt.provider.enable=VALUE dataproc.logging.stackdriver.enable=VALUE
- Esempio di snippet di creazione di file di script di personalizzazione per sostituire due proprietà del cluster:
cat <<EOF >/etc/google-managed-spark/dataproc.custom.properties dataproc.conscrypt.provider.enable=true dataproc.logging.stackdriver.enable=false EOF
- File
Crea un cluster con un'immagine personalizzata scaduta
Per impostazione predefinita, le immagini personalizzate scadono 365 giorni dopo la data di creazione. Per creare un cluster che utilizza un'immagine personalizzata scaduta, completa i seguenti passaggi.
Tentativo di creare un cluster Managed Service for Apache Spark con un'immagine personalizzata scaduta o un'immagine personalizzata che scadrà entro 10 giorni.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM-IMAGE-NAME \ --region=REGION \ ... other flags
gcloud CLI mostrerà un messaggio di errore che include il nome della proprietà
dataproc:dataproc.custom.image.expiration.tokendel cluster e il valore del token.
dataproc:dataproc.custom.image.expiration.token=TOKEN_VALUE
Copia la stringa TOKEN_VALUE negli appunti.
Utilizza gcloud CLI per creare di nuovo il cluster Managed Service for Apache Spark, aggiungendo TOKEN_VALUE copiato come proprietà del cluster.
gcloud dataproc clusters create CLUSTER-NAME \ --image=CUSTOM-IMAGE-NAME \ --properties=dataproc:dataproc.custom.image.expiration.token=TOKEN_VALUE \ --region=REGION \ ... other flags
La creazione del cluster con l'immagine personalizzata dovrebbe riuscire.