
使用 Spark 和 Lakehouse 运行时目录创建湖仓一体
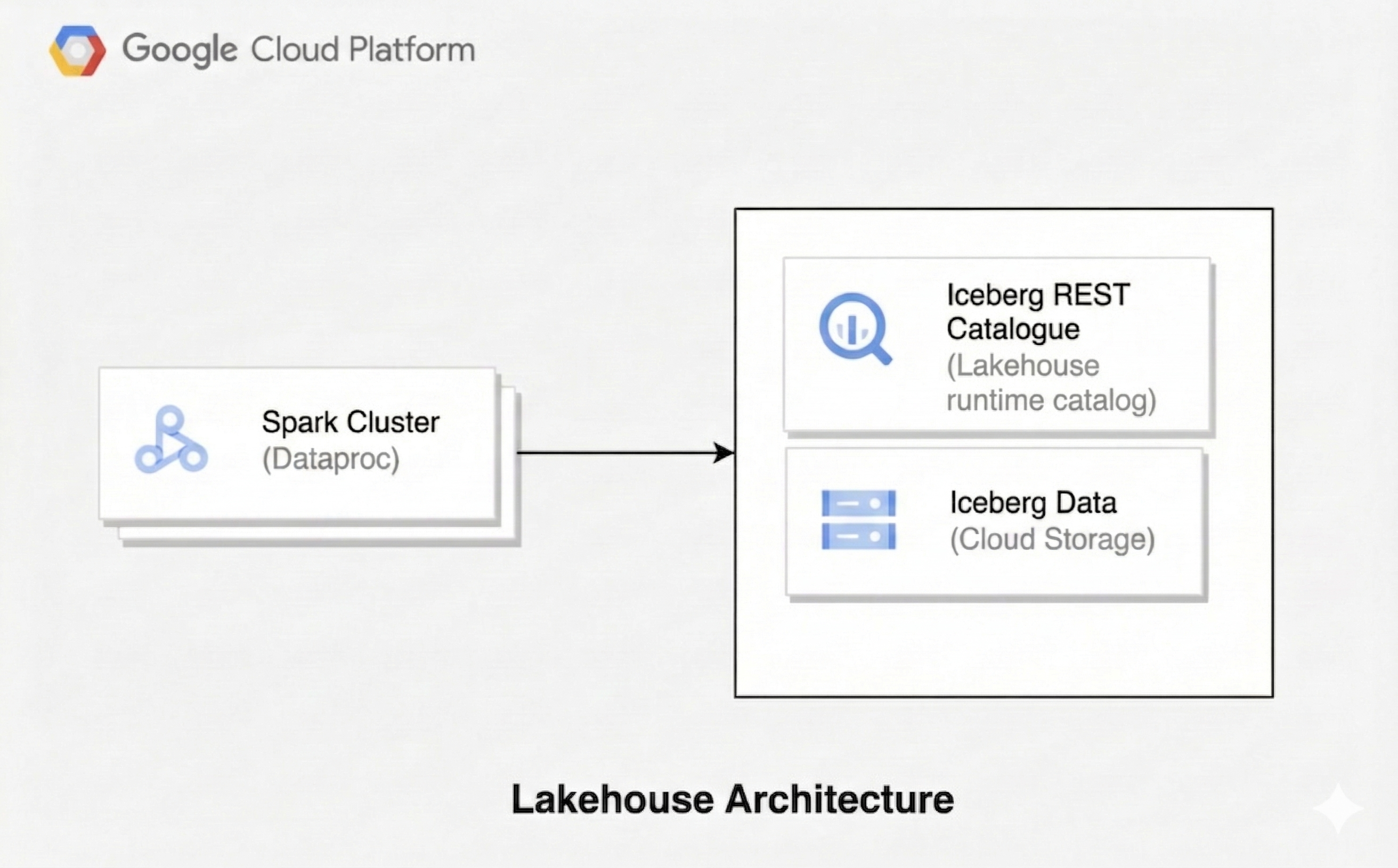
湖仓一体架构结合了数据湖的灵活性和数据仓库的数据管理功能。本文档介绍了如何在 上设置湖仓一体 Google Cloud。您将使用 Apache Iceberg 作为表格式,使用 Managed Service for Apache Spark 进行处理,并使用 Lakehouse 运行时目录 Iceberg REST 目录进行统一元数据管理。
此架构使用 Iceberg 等开放表格式,将数据仓储功能(例如事务和架构演变)添加到 Cloud Storage 中的数据。这种方法为您的数据创建了一个可信来源,各种引擎都可以访问该来源。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud的新用户, 请创建账号,以便在 真实场景中评估我们产品的性能。新客户还可获享 $300 赠金,用于 运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- 创建 Cloud Storage 存储桶 以存储 Iceberg 数据。
所需角色
您需要拥有某些 Identity and Access Management (IAM) 角色才能运行此页面上的示例。根据组织政策,这些角色可能已获授予。如需检查角色授予情况,请参阅 您是否需要授予角色?。
如需详细了解如何授予角色,请参阅 管理对项目、文件夹和组织的访问权限。
用户角色
如需获得创建 Managed Service for Apache Spark 集群所需的权限,请让管理员向您授予以下 IAM 角色:
- Dataproc Editor (
roles/dataproc.editor) 项目的 - Compute Engine 默认服务帐号的
Service Account User (
roles/iam.serviceAccountUser)
服务账号角色
如需确保 Compute Engine 默认服务帐号具有创建 Managed Service for Apache Spark 集群所需的权限,请让管理员向 Compute Engine 默认服务帐号授予项目的 Dataproc Worker (roles/dataproc.worker) IAM 角色。
创建 Managed Service for Apache Spark 集群
创建包含 Iceberg 和 Jupyter 可选组件的 Managed Service for Apache Spark 集群。
如需创建集群,请运行以下
gcloud命令:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'替换以下内容:
CLUSTER_NAME:集群的名称。PROJECT_ID:您的 Google Cloud 项目 ID。REGION:集群的区域,例如us-central1。 Google Cloud
请注意,Lakehouse 运行时目录 Iceberg REST 目录的正常运行不需要设置
dataproc:dataproc.lineage.enabled=true。添加此设置是为了在下面的数据沿袭示例中进行沿袭跟踪。使用 Jupyter 笔记本连接到集群。您可以使用 Vertex AI Workbench 笔记本,也可以直接在集群上启动笔记本。
配置 Spark 会话
在 Jupyter 笔记本中,创建一个配置为使用 Lakehouse 运行时目录 Iceberg REST 目录的 Spark 会话。
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
替换以下内容:
CATALOG_NAME:Iceberg 目录的名称,例如iceberg_catalog。APP_NAME:Spark 应用的名称。GCS_BUCKET:用于存储 Iceberg 表数据的 Cloud Storage 存储桶。PROJECT_ID:您的 Google Cloud 项目 ID。
使用 Spark SQL 管理数据
配置 Spark 会话后,使用 Spark SQL 执行数据管理操作。
创建命名空间。在 Lakehouse 运行时目录 Iceberg REST 目录中,命名空间对应于 BigQuery 数据集。
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")将
NAMESPACE_NAME替换为命名空间的名称,例如spark_lakehouse。以 Iceberg 格式创建基表并插入数据。
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()输出类似于以下内容:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+为新数据创建第二个表。
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()输出类似于以下内容:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+将新数据合并到基表中。
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()输出类似于以下内容:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+更新基表中的记录。
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()输出类似于以下内容:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+从基表中删除记录。
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()输出类似于以下内容:
+---+ | id| +---+ | 3| | 5| | 1| +---+
查询历史快照
通过查询特定快照 ID 来检索表的先前版本。此操作也称为“时间旅行”。
检索
MERGE、UPDATE和DELETE操作之前的表版本的快照 ID。snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]将
NAMESPACE_NAME替换为您创建的命名空间。使用检索到的快照 ID 查询表。
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()输出显示了
MERGE操作之后但在任何UPDATE或DELETE操作之前的表状态。+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
发现数据沿袭
您可以使用 数据沿袭跟踪 Lakehouse 运行时目录
Iceberg REST 目录表
之间的数据移动,数据沿袭
在 Managed Service for Apache Spark 2.2 及更高版本映像中提供。
数据沿袭示例
创建源 Iceberg 表和目标 Iceberg 表,然后复制数据。
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)在 Google Cloud 控制台中,前往 Knowledge Catalog 搜索 页面。
搜索其中一个表,然后点击
Lineage标签: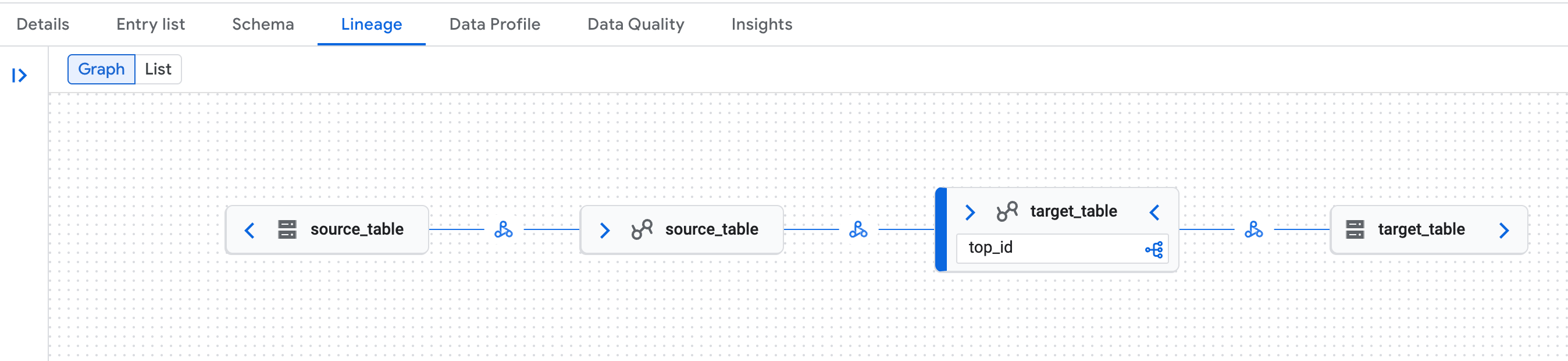
控制台中 Knowledge Catalog 页面中的数据沿袭图示例。 Google Cloud 数据沿袭可识别 Lakehouse 运行时目录 Iceberg REST 目录表的逻辑(Lakehouse 运行时目录表)和物理 (Cloud Storage) 表示形式。
数据沿袭已知问题
在某些 Managed Service for Apache Spark 集群中,由于 OpenLineage 库问题,可能无法
生成完整的数据沿袭。
解决方法:在 Spark 会话配置中,将 spark.sql.catalog.{catalog_name}.uri 属性设置为 https://biglake.googleapis.com/iceberg/v1beta/restcatalog。
后续步骤
- 详细了解 Lakehouse 运行时目录 Iceberg REST 目录。
- 探索 Apache Iceberg 的功能。
- 了解如何从 Lakehouse 运行时目录查询 Iceberg 数据。
- 详细了解 数据沿袭和 Managed Service for Apache Spark。