
Spark と Lakehouse ランタイム カタログでレイクハウスを作成する
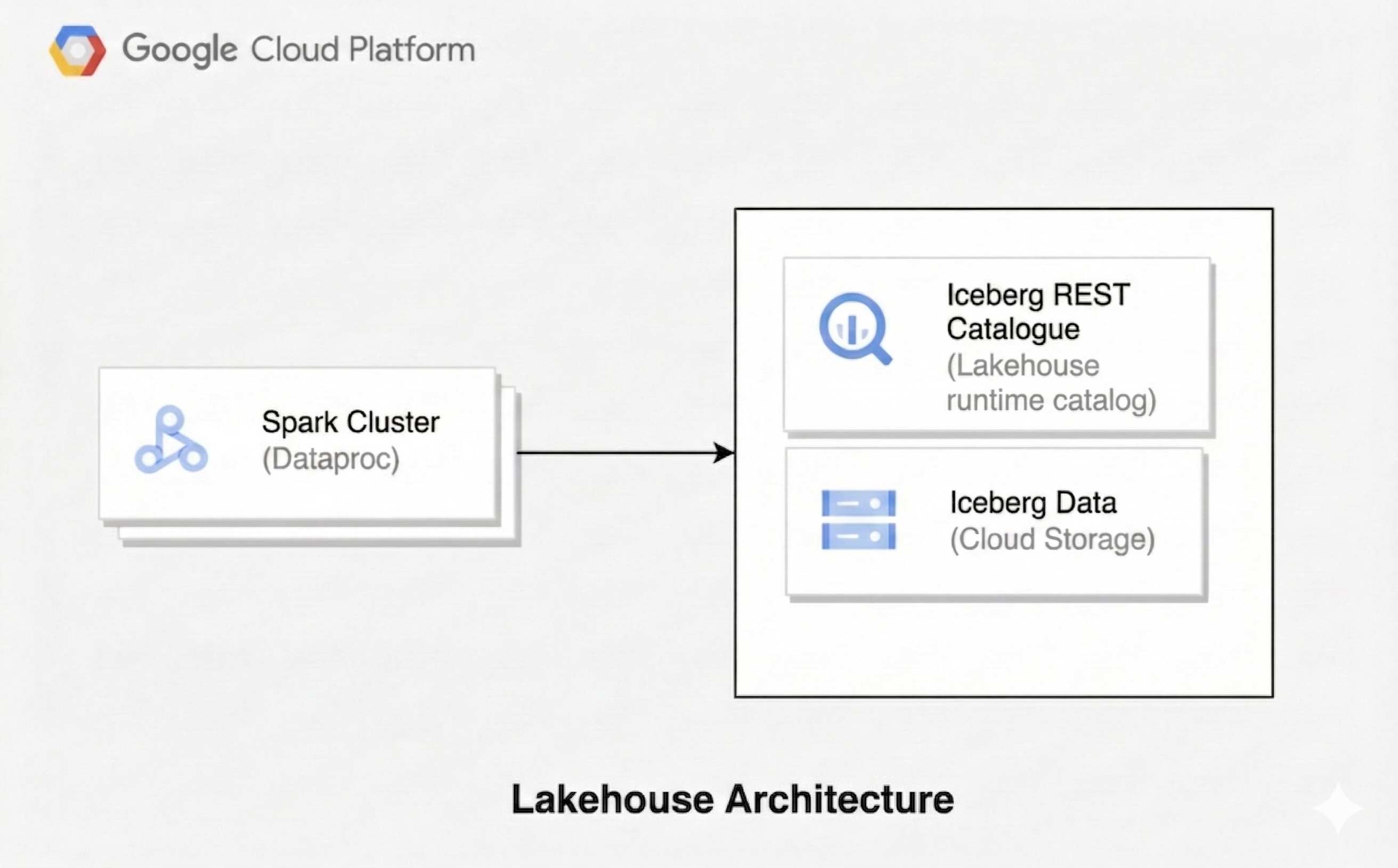
レイクハウス アーキテクチャは、データレイクの柔軟性とデータ ウェアハウスのデータ管理機能を組み合わせたものです。このドキュメントでは、 でレイクハウスを設定する方法について説明します。 Google Cloudテーブル形式として Apache Iceberg、処理に Managed Service for Apache Spark、統合メタデータ管理に Lakehouse ランタイム カタログ Iceberg REST カタログを使用します。
このアーキテクチャでは、Iceberg などのオープン テーブル形式を使用して、トランザクションやスキーマの進化などのデータ ウェアハウス機能を Cloud Storage のデータに追加します。このアプローチでは、さまざまなエンジンからアクセスできるデータの信頼できる唯一の情報源が作成されます。
始める前に
- アカウントにログインします。 Google Cloud を初めて使用する場合は、 アカウントを作成して、実際のシナリオで Google プロダクトのパフォーマンスを評価してください。 Google Cloud新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- Iceberg データを保存する Cloud Storage バケットを作成します。
必要なロール
このページの例を実行するには、特定の Identity and Access Management(IAM)ロールが必要です。組織のポリシーによっては、これらのロールがすでに付与されている場合があります。ロールの付与を確認するには、 ロールを付与する必要がありますか?をご覧ください。
ロールの付与については、 プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
ユーザーロール
Managed Service for Apache Spark クラスタの作成に必要な権限を取得するには、次の IAM ロールを付与するよう管理者に依頼してください。
- Dataproc 編集者 (
roles/dataproc.editor)プロジェクトに対する - Compute Engine のデフォルトのサービス アカウントに対する サービス アカウント ユーザー(
roles/iam.serviceAccountUser)
サービス アカウント ロール
Compute Engine のデフォルトのサービス アカウントに、Managed Service for Apache Spark クラスタの作成に必要な
権限を付与するには、
プロジェクトに対する
Dataproc ワーカー (roles/dataproc.worker)IAM ロールを Compute Engine のデフォルトのサービス アカウントに付与するよう管理者に依頼します。
Managed Service for Apache Spark クラスタを作成する
Iceberg と Jupyter のオプション コンポーネントを使用して、Managed Service for Apache Spark クラスタを作成します。
クラスタを作成するには、次の
gcloudコマンドを実行します。gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'次のように置き換えます。
CLUSTER_NAME: クラスタの名前。PROJECT_ID: 実際の Google Cloud プロジェクト ID。REGION: クラスタのリージョン(例:us-central1)。 Google Cloud
なお、Lakehouse ランタイム カタログ Iceberg REST カタログが正しく動作するために
dataproc:dataproc.lineage.enabled=trueを設定する必要はありません。これは、以下のデータリネージの例でリネージ トラッキングを行うために追加されています。Jupyter ノートブックを使用してクラスタに接続します。Vertex AI Workbench ノートブックを使用するか、クラスタでノートブックを直接起動できます。
Spark セッションを構成する
Jupyter ノートブックで、Lakehouse ランタイム カタログ Iceberg REST カタログを使用するように構成された Spark セッションを作成します。
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config(f'spark.sql.catalog.{catalog_name}.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
次のように置き換えます。
CATALOG_NAME: Iceberg カタログの名前(例:iceberg_catalog)。APP_NAME: Spark アプリケーションの名前。GCS_BUCKET: Iceberg テーブルデータを保存する Cloud Storage バケット。PROJECT_ID: 実際の Google Cloud プロジェクト ID。
Spark SQL でデータを管理する
Spark セッションを構成したら、Spark SQL を使用してデータ管理オペレーションを実行します。
Namespace を作成します。Lakehouse ランタイム カタログ Iceberg REST カタログでは、Namespace は BigQuery データセットに対応します。
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")NAMESPACE_NAMEは、Namespace の名前に置き換えます(例:spark_lakehouse)。Iceberg 形式でベーステーブルを作成し、データを挿入します。
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()出力は次のようになります。
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+新しいデータの 2 つ目のテーブルを作成します。
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()出力は次のようになります。
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+新しいデータをベーステーブルにマージします。
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()出力は次のようになります。
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+ベーステーブルのレコードを更新します。
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()出力は次のようになります。
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+ベーステーブルからレコードを削除します。
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()出力は次のようになります。
+---+ | id| +---+ | 3| | 5| | 1| +---+
過去のスナップショットをクエリする
特定のスナップショット ID をクエリして、テーブルの以前のバージョンを取得します。このオペレーションはタイムトラベルとも呼ばれます。
MERGE、UPDATE、DELETEオペレーションの前のテーブル バージョンのスナップショット ID を取得します。snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]NAMESPACE_NAMEは、作成した Namespace に置き換えます。取得したスナップショット ID を使用してテーブルをクエリします。
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()出力には、
MERGEオペレーションの後、UPDATEオペレーションまたはDELETEオペレーションの前のテーブルの状態が表示されます。+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
データリネージを検出する
Managed Service for Apache Spark 2.2 以降のイメージ バージョンで利用可能な データリネージを使用して、Lakehouse ランタイム カタログ
Iceberg REST カタログ テーブル
間のデータの移動を追跡できます。
データリネージの例
ソースとターゲットの Iceberg テーブルを作成し、データをコピーします。
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)コンソールで、Knowledge Catalog の [Search] ページに移動します。 Google Cloud
いずれかのテーブルを検索し、[
Lineage] タブをクリックします。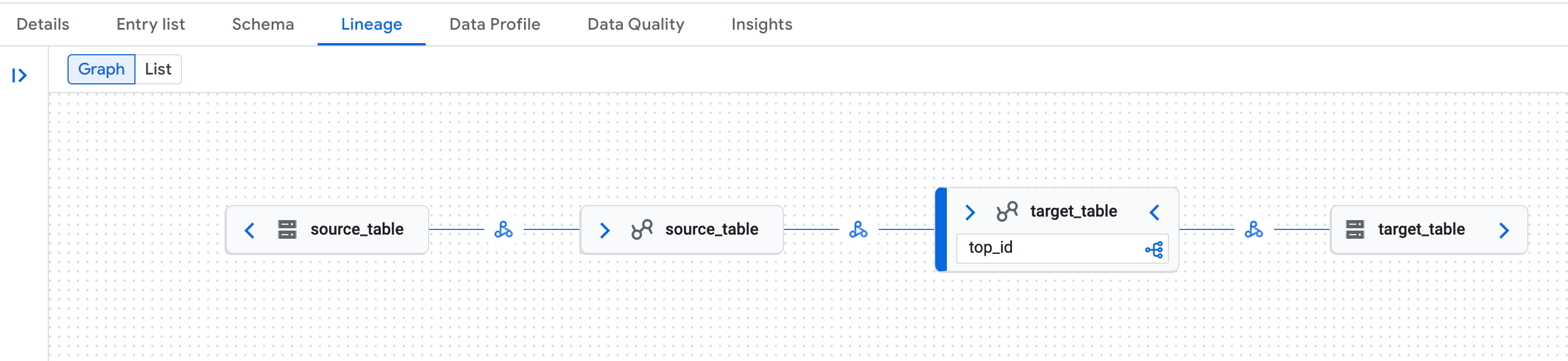
コンソールの Knowledge Catalog ページにあるデータリネージ グラフの例。 Google Cloud データリネージは、Lakehouse ランタイム カタログ Iceberg REST カタログ テーブルの論理表現(Lakehouse ランタイム カタログ テーブル)と物理表現(Cloud Storage)の両方を認識します。
データリネージの既知の問題
一部の Managed Service for Apache Spark クラスタでは、完全なデータリネージが
OpenLineageライブラリの問題により生成されないことがあります。
回避策: Spark セッション構成で、spark.sql.catalog.{catalog_name}.uri プロパティを https://biglake.googleapis.com/iceberg/v1beta/restcatalog に設定します。
次のステップ
- Lakehouse ランタイム カタログ Iceberg REST カタログの詳細を確認する。
- Apache Iceberg の機能を調べる。
- Lakehouse ランタイム カタログから Iceberg データをクエリする方法を確認する。
- データリネージと Managed Service for Apache Spark の詳細を確認する。