
É possível usar o spark-bigquery-connector
com o Serviço Gerenciado para Apache Spark para ler e gravar dados no BigQuery e no dele. Este tutorial demonstra um aplicativo PySpark que usa o spark-bigquery-connector.
Confirmar a versão do conector
Consulte as versões de ambiente de execução do Serviço Gerenciado para Apache Spark para determinar a versão do conector do BigQuery instalada na carga de trabalho em lote ou na versão do ambiente de execução da sessão interativa. Se o conector não estiver listado, consulte Disponibilizar o conector para aplicativos.
Disponibilizar o conector para aplicativos (se necessário)
O conector do BigQuery está instalado em todas as
versões de ambiente de execução do Serviço Gerenciado para Apache Spark compatíveis.
Se você estiver usando uma
versão de ambiente de execução não compatível
que não instala o conector (Spark runtime 1.0), é possível disponibilizar o conector para um
aplicativo de uma das duas maneiras a seguir:
- Use o parâmetro
jarspara apontar para um arquivo jar do conector ao enviar uma carga de trabalho em lote do Serviço Gerenciado para Apache Spark ou executar uma sessão interativa. O exemplo de carga de trabalho em lote a seguir especifica um arquivo jar do conector. Consulte o GoogleCloudDataproc/spark-bigquery-connector repositório no GitHub para conferir uma lista de arquivos jar de conector disponíveis.- Exemplo da Google Cloud CLI:
gcloud dataproc batches submit pyspark \ --region=REGION \ --jars=spark-3.5-bigquery-version.jar \ ... other args
- Exemplo da Google Cloud CLI:
Calcular custos
Este tutorial usa componentes faturáveis do Google Cloud, incluindo:
- Serviço Gerenciado para Apache Spark
- BigQuery
- Cloud Storage
Use a Calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Configurar o faturamento
Por padrão, o projeto associado às credenciais ou à conta de serviço é cobrado pelo uso da API. Para faturar um projeto diferente, defina a seguinte
propriedade de configuração: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Também é possível adicionar essa propriedade a uma operação de leitura ou gravação, da seguinte maneira:
.option("parentProject", "<BILLED-GCP-PROJECT>").
Enviar uma carga de trabalho em lote de contagem de palavras do PySpark
Este exemplo lê dados do BigQuery em um DataFrame do Spark para executar uma contagem de palavras usando a API de origem de dados padrão.
O conector grava a saída de contagem de palavras no BigQuery na seguinte sequência de operações:
Armazena os dados em arquivos temporários no bucket do Cloud Storage.
Copia os dados em uma operação do bucket do Cloud Storage para o BigQuery.
Exclui os arquivos temporários no Cloud Storage após a conclusão da operação de carregamento do BigQuery. Os arquivos temporários também são excluídos após o encerramento do aplicativo Spark. Se a exclusão falhar, será necessário excluir os arquivos temporários indesejados do Cloud Storage, que normalmente são colocados em
gs://BUCKET_NAME/.spark-bigquery-JOB_ID-UUID.
Etapas para executar a carga de trabalho de contagem de palavras
- Abra um terminal local ou o Cloud Shell.
- Crie o
wordcount_datasetcom a ferramenta de linha de comando bq em um terminal local ou no Cloud Shell.bq mk wordcount_dataset
- Crie um bucket do Cloud Storage com a
Google Cloud CLI.
gcloud storage buckets create gs://BUCKET_NAME
BUCKET_NAMEpelo nome do bucket do Cloud Storage criado. - Crie o arquivo
wordcount.pylocalmente em um editor de texto copiando o código PySpark a seguir.#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Cloud Storage bucket used by the connector for temporary BigQuery # export data. bucket = "BUCKET_NAME" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data.samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Envie a carga de trabalho em lote do PySpark:
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=BUCKET_NAME
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para visualizar a tabela de saída no Google Cloud console, abra a BigQuery , selecione a tabelawordcount_outpute clique em Visualizar.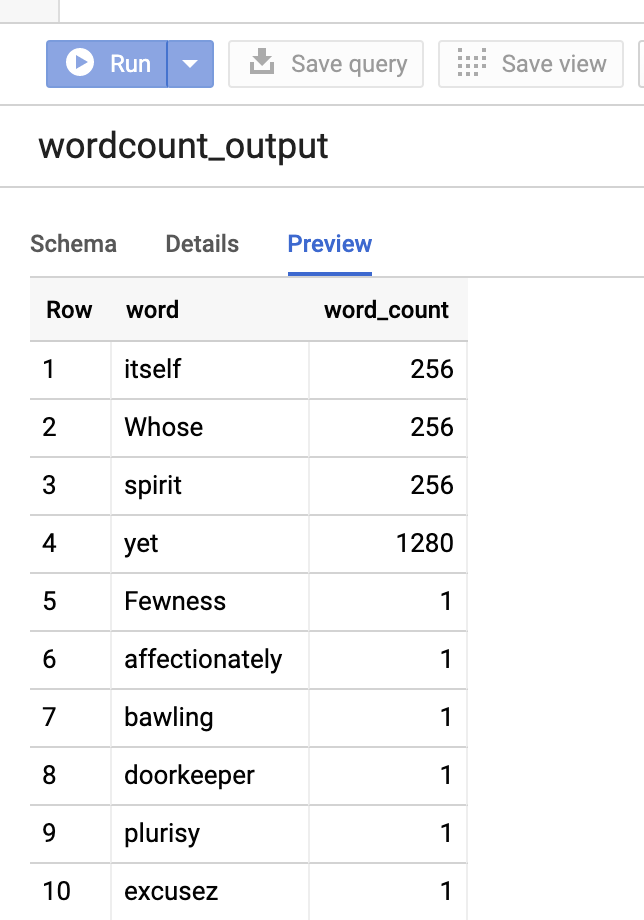
Figura 1: visualizar a tabela de saída no BigQuery
Para mais informações
- Armazenamento do BigQuery e Spark SQL, Python
- Como criar um arquivo de definição de tabela para uma fonte de dados externa
- Usar dados particionados externamente