
Managed Service for Apache Spark バッチ ワークロードとインタラクティブ セッションは、エンドユーザーまたはサービス アカウントの認証情報を使用して実行されます。サービス アカウントの認証情報を使用する場合、バッチ ワークロードまたはインタラクティブ セッションの実行に使用されるサービス アカウントは、バッチまたはセッションのランタイム バージョンによって異なります。
3.0 より前のランタイム サービス アカウント
サービス アカウント認証情報を使用する 3.0 より前の Spark ランタイム バージョンでは、Compute Engine のデフォルトのサービス アカウントまたはユーザー指定のカスタム サービス アカウントを使用して、バッチ ワークロードを送信するか、インタラクティブ セッションを作成します。
3.0 以降のランタイム サービス アカウント
サービス アカウントの認証情報を使用する Spark ランタイム バージョン 3.0 以降では、ユーザー指定のカスタム サービス アカウントを使用してバッチ ワークロードを送信するか、インタラクティブ セッションを作成します。
Managed Service for Apache Spark 3.0 以降のランタイムは、Managed Service for Apache Spark ユーザーの Google Cloud プロジェクトに Dataproc Resource Manager ノード サービス エージェントのロールで Dataproc Resource Manager ノード サービス エージェントのサービス アカウント service-project-number@gcp-sa-dataprocrmnode.iam.gserviceaccount.com を作成します。このサービス アカウントは、ワークロードが作成されたプロジェクトにある Managed Service for Apache Spark リソースに対して次のシステム オペレーションを実行します。
- Cloud Logging と Cloud Monitoring
- Managed Service for Apache Spark Resource Manager ノードの基本オペレーション(
get、heartbeat、mintOAuthTokenなど)
IAM サービス アカウントのロールを表示して管理する
バッチ ワークロードまたはセッション サービス アカウントに付与されているロールを表示して管理するには、次の操作を行います。
Google Cloud コンソールで、[IAM] ページに移動します。
[Google 提供のロール付与を含める] をクリックします。
バッチ ワークロードまたはセッションのデフォルトまたはカスタム サービス アカウントに含まれているロールを表示します。
次の図は、Managed Service for Apache Spark がデフォルトでワークロードまたはセッションのサービス アカウントとして使用する Compute Engine のデフォルトのサービス アカウント
project_number-compute@developer.gserviceaccount.comに含まれている必要な Managed Service for Apache Spark ワーカーロールを示しています。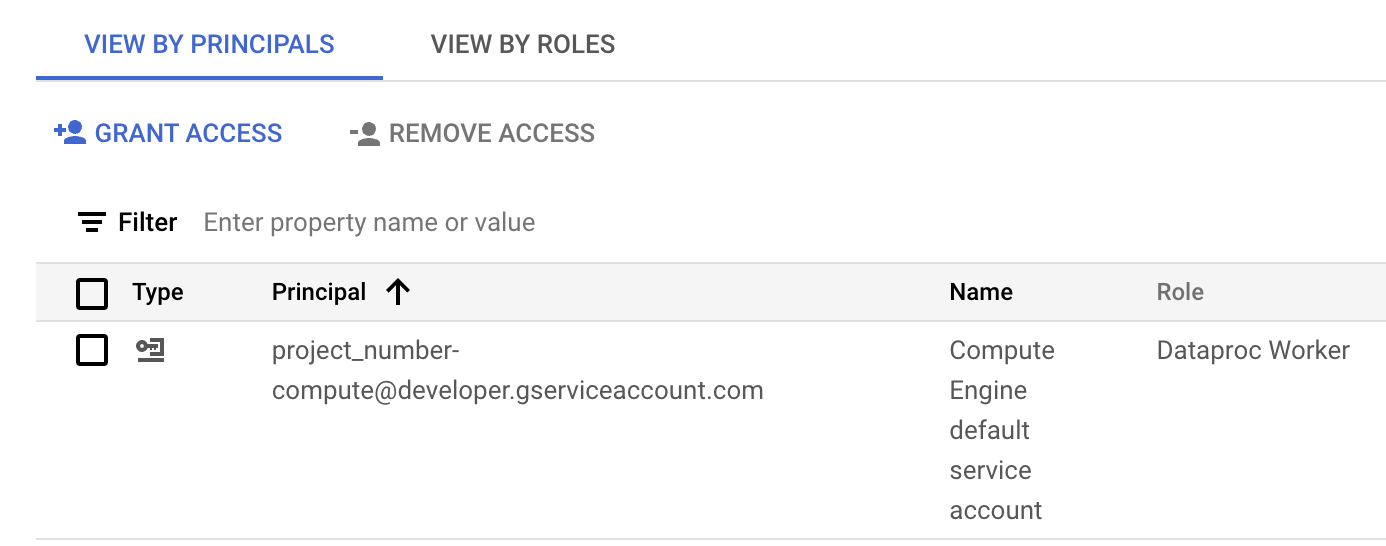
Google Cloud コンソールの IAM セクションで、Compute Engine のデフォルトのサービス アカウントに割り当てられた Managed Service for Apache Spark ワーカーのロール。 サービス アカウントの行に表示されている鉛筆アイコンをクリックして、サービス アカウントのロールを付与または削除できます。
プロジェクト間サービス アカウントの使用方法
バッチ ワークロード プロジェクト(バッチが送信されるプロジェクト)とは異なるプロジェクトのサービス アカウントを使用するバッチ ワークロードを送信できます。このセクションでは、サービス アカウントが存在するプロジェクトを service account project、バッチが送信されるプロジェクトを batch project と呼びます。
プロジェクト間のサービス アカウントを使用してバッチ ワークロードを実行する理由: 別のプロジェクトのサービス アカウントに、そのプロジェクトのリソースへのきめ細かいアクセス権を付与する IAM ロールが割り当てられている場合などが考えられます。
設定の手順
このセクションの例は、3.0 より前のランタイム バージョンで実行されるバッチ ワークロードの送信に適用されます。
サービス アカウント プロジェクトで:
Dataproc API を有効にします。
API を有効にするために必要なロール
API を有効にするには、
serviceusage.services.enable権限を含む Service Usage 管理者 IAM ロール(roles/serviceusage.serviceUsageAdmin)が必要です。詳しくは、ロールを付与する方法をご覧ください。メール アカウント(クラスタを作成するユーザー)に、サービス アカウント プロジェクトのサービス アカウント ユーザーのロールを付与します。また、より細かく制御する場合は、サービス アカウント プロジェクトのサービス アカウントのロールを付与します。
詳細については、プロジェクト レベルでロールを付与する場合はプロジェクト、フォルダ、組織へのアクセスを管理するを、サービス アカウント レベルでサービス アカウントへロールを付与する場合はサービス アカウントに対するアクセス権の管理を参照してください。
gcloud CLI の例:
次のサンプル コマンドでは、ユーザーにサービス アカウントのユーザーロールをプロジェクト レベルで付与します。
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
注:
USER_EMAIL: ユーザー アカウントのメールアドレスをuser:user-name@example.comの形式で入力します。
次のサンプル コマンドでは、ユーザーにサービス アカウントのユーザーロールをサービス アカウント レベルで付与します。
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
注:
USER_EMAIL: ユーザー アカウントのメールアドレスをuser:user-name@example.comの形式で入力します。
サービス アカウントに、バッチ プロジェクトに対する Managed Service for Apache Spark ワーカーのロールを付与します。
gcloud CLI の例:
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
バッチ プロジェクトでは、次の操作を行います。
Managed Service for Apache Spark サービス エージェント サービス アカウントに、サービス アカウント プロジェクトの(より細かく制御する場合はサービス アカウント プロジェクトのサービス アカウントの)サービス アカウント ユーザーとサービス アカウント トークン作成者のロールを付与します。これにより、バッチ プロジェクトの Managed Service for Apache Spark サービス エージェント サービス アカウントに、サービス アカウント プロジェクトのサービス アカウント用のトークンを作成することを許可します。
詳細については、プロジェクト レベルでロールを付与する場合はプロジェクト、フォルダ、組織へのアクセスを管理するを、サービス アカウント レベルでサービス アカウントへロールを付与する場合はサービス アカウントに対するアクセス権の管理を参照してください。
gcloud CLI の例:
次のコマンドは、バッチ プロジェクトの Managed Service for Apache Spark サービス エージェント サービス アカウントに、サービス アカウント ユーザーとサービス アカウント トークン作成者のロールをプロジェクト レベルで付与します。
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
次のサンプル コマンドでは、バッチ プロジェクトの Managed Service for Apache Spark サービス エージェント サービス アカウントに、サービス アカウント ユーザーとサービス アカウント トークン作成者のロールをサービス アカウント レベルで付与します。
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
バッチ プロジェクトの Compute Engine サービス エージェント サービス アカウントに、サービス アカウント プロジェクトの(より細かく制御するには、サービス アカウント プロジェクトのサービス アカウントの)サービス アカウント トークン作成者のロールを付与します。これにより、バッチ プロジェクトの Compute Agent サービス エージェント サービス アカウントに、サービス アカウント プロジェクトのサービス アカウント用のトークンを作成する権限が付与されます。
詳細については、プロジェクト、フォルダ、組織へのアクセスを管理するでプロジェクト レベルでロールを付与し、サービス アカウントに対するアクセス権の管理でサービス アカウント レベルでロールを付与するをご覧ください。
gcloud CLI の例:
次のサンプル コマンドでは、バッチ プロジェクトの Compute Engine サービス エージェント サービス アカウントに、サービス アカウント トークン作成者のロールをプロジェクト レベルで付与します。
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
次のサンプル コマンドでは、クラスタ プロジェクトの Compute Engine サービス エージェント サービス アカウントに、サービス アカウント トークン作成者のロールをサービス アカウント レベルで付与します。
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
バッチ ワークロードを送信する
設定手順を完了すると、バッチ ワークロードを送信できます。バッチ ワークロードに使用するサービス アカウントとして、サービス アカウント プロジェクトのサービス アカウントを指定してください。
権限に基づくエラーのトラブルシューティング
バッチ ワークロードまたはセッションで使用されるサービス アカウントの権限が正しくないか、権限が不足していると、バッチまたはセッションの作成が失敗し、「Driver compute node failed to initialize for batch in 600 seconds」というエラー メッセージが報告されることがあります。このエラーは、割り当てられたタイムアウト時間内に Spark ドライバを起動できなかったことを示します。これは通常、 Google Cloud リソースへの必要なアクセス権がないことが原因です。
この問題をトラブルシューティングするには、サービス アカウントに次の最小限のロールまたは権限があることを確認します。
- Managed Service for Apache Spark ワークロードロール(
roles/dataproc.worker): このロールは、Managed Service for Apache Spark が Spark ワークロードとセッションを管理して実行するために必要な権限を付与します。 - Storage オブジェクト閲覧者(
roles/storage.objectViewer)、Storage オブジェクト作成者(roles/storage.objectCreator)、Storage オブジェクト管理者(roles/storage.admin): Spark アプリケーションが Cloud Storage バケットから読み取るか、Cloud Storage バケットに書き込む場合、サービス アカウントにはバケットにアクセスするための適切な権限が必要です。たとえば、入力データが Cloud Storage バケットにある場合は、Storage Object Viewerが必要です。アプリケーションが Cloud Storage バケットに出力を書き込む場合は、Storage Object CreatorまたはStorage Object Adminが必要です。 - BigQuery データ編集者(
roles/bigquery.dataEditor)または BigQuery データ閲覧者(roles/bigquery.dataViewer): Spark アプリケーションが BigQuery とやり取りする場合は、サービス アカウントに適切な BigQuery ロールがあることを確認します。 - Cloud Logging の権限: 効果的なデバッグを行うには、サービス アカウントに Cloud Logging にログを書き込む権限が必要です。通常は、
Logging Writerロール(roles/logging.logWriter)で十分です。
権限またはアクセスに関連する一般的なエラー
dataproc.workerロールがない: このコアロールがないと、Managed Service for Apache Spark インフラストラクチャがドライバ ノードを適切にプロビジョニングして管理できません。Cloud Storage 権限が不足している: 必要なサービス アカウント権限がない状態で、Spark アプリケーションが Cloud Storage バケットから入力データを読み取ろうとしたり、Cloud Storage バケットに出力を書き込もうとしたりすると、重要なリソースにアクセスできないため、ドライバの初期化が失敗する可能性があります。
ネットワークまたはファイアウォールの問題: VPC Service Controls またはファイアウォール ルールにより、サービス アカウントの Google Cloud API またはリソースへのアクセスが誤ってブロックされることがあります。
サービス アカウントの権限を確認して更新するには:
- Google Cloud コンソールで、[IAM と管理] > [IAM] ページに移動します。
- バッチ ワークロードまたはセッションで使用されるサービス アカウントを見つけます。
- 必要なロールが割り当てられていることを確認します。追加されていない場合は、追加します。
Managed Service for Apache Spark のロールと権限の一覧については、Managed Service for Apache Spark の権限と IAM ロールをご覧ください。