
您可以將使用者標籤套用至 Managed Service for Apache Spark 叢集和工作,以便將這些資源分組,然後進行篩選並建立清單。在建立資源的當下 (亦即建立叢集或提交工作時),標籤就會與資源建立關聯。資源與標籤建立關聯後,任何對資源執行的作業 (叢集的建立、更新、修補或刪除;工作的提交、更新、取消或刪除) 都會沿用該標籤,可據以篩選並列出相關叢集、工作和作業。
其他與叢集資源相關聯的 Compute Engine 資源 (例如虛擬機器執行個體和磁碟) 也都可以加上標籤。
什麼是標籤?
標籤是一種鍵/值組合,可指派給 Managed Service for Apache Spark 叢集和工作,有助於在大規模環境下整理資源,並依所需精細程度管理成本。每項資源均可加上標籤,並根據標籤篩選資源。標籤相關資訊會轉送到帳單系統,方便依照標籤詳細分析帳單費用。使用內建的帳單報表,可依資源標籤篩選成本並加以分組。此外,亦可使用標籤查詢帳單資料匯出檔。
標籤需求條件
套用於資源的標籤必須符合下列需求條件:
- 每個叢集或工作最多可以有 32 個標籤。
- 每個標籤都必須是鍵/值組合。
- 鍵的長度必須至少為 1 個字元,最多 63 個字元,且不能空白。值可以空白,長度上限為 63 個字元。
- 鍵和值只能使用小寫字母、數字字元、底線和連字號。所有字元都必須使用 UTF-8 編碼,允許國際字元。鍵的開頭必須是小寫字母或國際字元。
- 標籤中的鍵部分不得重複,但可讓多個資源使用相同的鍵。
上述限制適用於各個標籤的鍵和值,以及帶有標籤的個別 Managed Service for Apache Spark 叢集或工作;但是在每項專案內,所有資源可套用的標籤總數並無上限。
標籤的常見用法
以下是一些常見的標籤用途:
團隊或成本中心標籤:依據團隊或成本中心來新增標籤,藉此區別不同團隊 (例如
team:research和team:analytics) 擁有的 Managed Service for Apache Spark 叢集和工作,這類標籤可用於成本會計或預算編列作業。元件標籤:例如
component:redis、component:frontend、component:ingest和component:dashboard。環境或階段標籤:例如
environment:production和environment:test。狀態標籤:例如
state:active、state:readytodelete和state:archive。擁有權標籤:用於識別各項作業的責任團隊,例如:
team:shopping-cart。
我們不建議建立大量的不重複標籤,例如幫時間戳記或每個 API 呼叫的個別值建立標籤。這種做法的問題在於,如果標籤值頻繁變更,或標籤鍵使目錄變得雜亂,就難以有效篩選資源並製作報表。
標籤和標記
標籤是一種註解,可用於查詢資源,但無法設定政策條件。標記則可作為判斷條件:系統可依據資源是否具備特定標記,允許或拒絕相應的政策,進而實現精細的政策控管。詳情請參閱「標記總覽」。
建立及使用 Managed Service for Apache Spark 標籤
gcloud 指令
您可以使用 Google Cloud CLI,指定要在建立 Managed Service for Apache Spark 叢集或提交工作時,套用至該叢集或工作的一或多個標籤。
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Managed Service for Apache Spark 叢集或工作建立完成後,您就可以使用 Google Cloud CLI 更新與該資源相關聯的標籤。
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
同樣地,您可以使用 Google Cloud CLI 並採用下列格式的篩選運算式,按標籤篩選 Managed Service for Apache Spark 資源:labels.<key=value>。
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
如要進一步瞭解如何編寫篩選運算式,請參閱 clusters.list 和 jobs.list Dataproc API 說明文件。
REST API
標籤可以透過 Managed Service for Apache Spark REST API 附加至 Managed Service for Apache Spark 叢集或作業。您可以在建立叢集或提交工作時,使用 clusters.create 和 jobs.submit API 將標籤附加到該叢集或工作。叢集建立完成後,您可以使用 clusters.patch 和 jobs.patch API 編輯標籤。以下是 cluster.create 要求的 JSON 主體,其中含有附加到叢集的 key1:value 標籤。
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
您可以使用 clusters.list 和 jobs.list API 列出符合指定篩選條件的叢集或工作,格式如下:labels.<key=value>。
以下範例是一項 Dataproc API clusters.list HTTPS GET 要求,其中指定了 key=value 標籤篩選條件。呼叫端會插入 project、region、篩選條件 label-key 和 label-value,以及 api-key。請注意,為了方便閱讀,此要求範例分成兩行顯示。
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
如要進一步瞭解如何編寫篩選運算式,請參閱 clusters.list 和 jobs.list Dataproc API 說明文件。
控制台
在建立 Managed Service for Apache Spark 叢集或提交工作時,可以透過 Google Cloud 控制台指定要新增至該資源的一組標籤。
- 在 Managed Service for Apache Spark「Create a cluster」(建立叢集) 頁面的「Customize cluster」(自訂叢集) 面板中,從「Labels」(標籤) 區段將標籤新增至叢集。
- 從 Managed Service for Apache Spark 的「Submit a job」(提交工作) 頁面,為工作新增標籤。
建立 Managed Service for Apache Spark 叢集或提交工作後,即可更新與該資源相關聯的標籤。如要更新標籤,請按一下所列叢集或工作的選取方框,然後按一下 SHOW INFO PANEL。以下是 Managed Service for Apache Spark→List clusters (列出叢集) 頁面的範例。

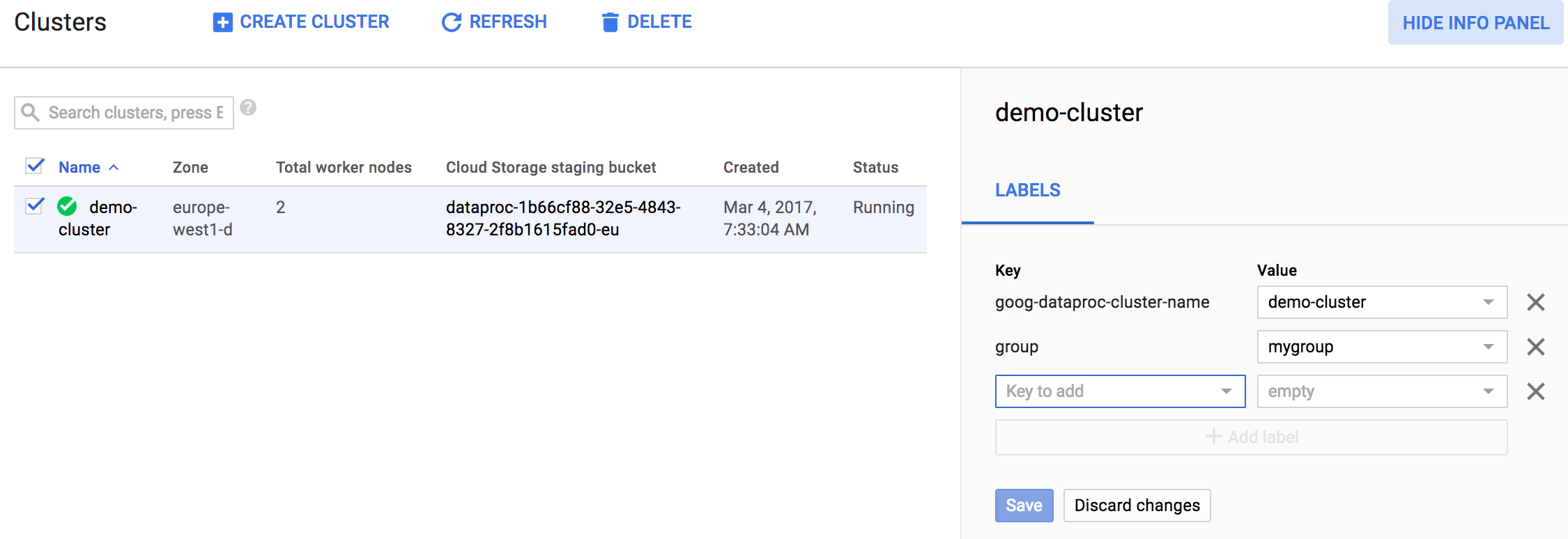
系統顯示資訊面板後,即可更新 Managed Service for Apache Spark 叢集或工作所套用的標籤。以下範例說明如何更新 Managed Service for Apache Spark 叢集套用的標籤。
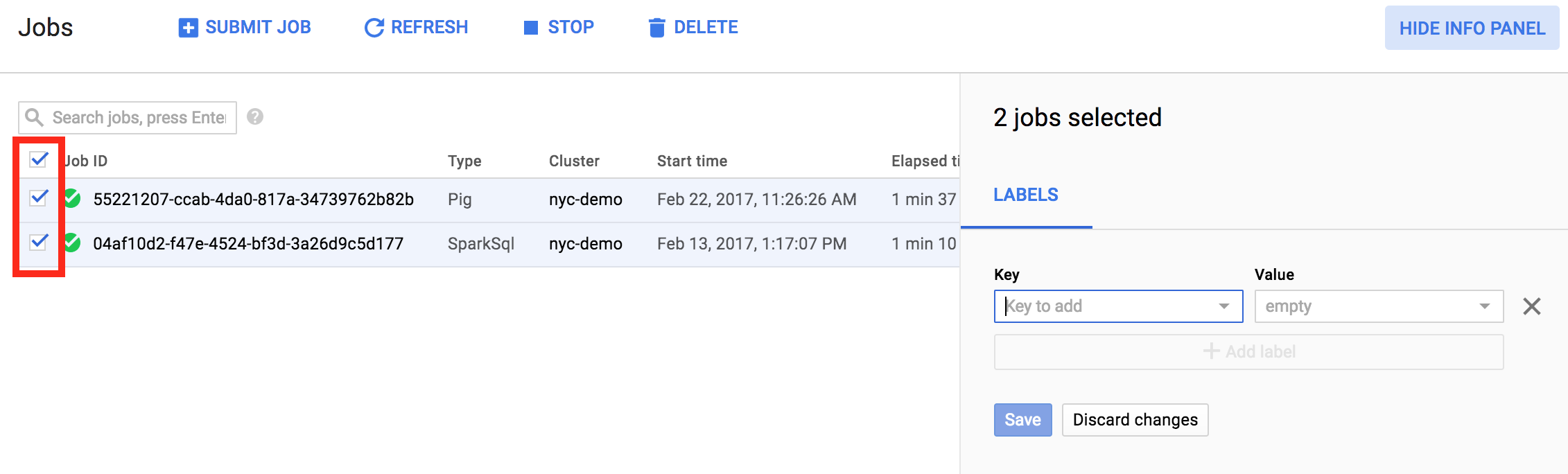
在單次作業中,也可以更新多個項目的標籤。下列範例說明如何同時更新多個 Managed Service for Apache Spark 工作的標籤。
標籤可用於篩選顯示在「Managed Service for Apache Spark→List clusters」(列出叢集) (https://console.cloud.google.com/managed-spark/clusters) 和「Managed Service for Apache Spark→List jobs」(列出工作) (https://console.cloud.google.com/managed-spark/jobs) 頁面上的 Managed Service for Apache Spark 資源。在頁面頂端,您可以使用搜尋模式 `labels.

自動套用的標籤
建立或更新叢集時,Managed Service for Apache Spark 會將數個標籤自動套用於叢集和叢集資源。例如在建立叢集時,Managed Service for Apache Spark 會將標籤套用於虛擬機器、永久磁碟和加速器。自動套用的標籤會有特殊的 goog-dataproc 前置字元。
下列 goog-dataproc 標籤會自動套用於 Managed Service for Apache Spark 資源。在建立叢集時,任何針對預留 goog-dataproc 標籤所指定的值,都會覆寫系統自動提供的值。因此,不建議自行設定這些標籤的值。
| 標籤 | 說明 |
|---|---|
goog-dataproc-cluster-name |
使用者指定的叢集名稱。 |
goog-dataproc-cluster-uuid |
不重複的叢集 ID。 |
goog-dataproc-location |
Managed Service for Apache Spark 區域叢集端點 |
這些自動套用的標籤有多種用途,包括: