
Managed Service for Apache Spark のきめ細かい IAM は、クラスタ、ジョブ、オペレーション、ワークフロー テンプレート、自動スケーリング ポリシーの各レベルで権限を付与できる機能です。
たとえば、あるユーザーにはクラスタ閲覧者のロールを付与してプロジェクト内のクラスタを表示できるようにし、別のユーザーにはジョブ編集者のロールを付与してジョブの表示だけでなく更新とキャンセルもできるようにします。Managed Service for Apache Spark のきめ細かい IAM の各ロールで有効になる、特定の Google Cloud CLI コマンドの詳細については、きめ細かい IAM で有効になる SDK コマンドをご覧ください。
Managed Service for Apache Spark のきめ細かい IAM ロールと権限
Managed Service for Apache Spark のきめ細かい IAM では、Managed Service for Apache Spark リソースで次の各権限を持つロールを以下のように設定できます。
クラスタのロール
| ロール | 権限 |
|---|---|
| 閲覧者 | dataproc.clusters.get |
| 編集者 | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop |
| オーナー | dataproc.clusters.get dataproc.clusters.list dataproc.clusters.delete dataproc.clusters.update dataproc.clusters.use dataproc.clusters.start dataproc.clusters.stop dataproc.clusters.setIamPolicy dataproc.clusters.getIamPolicy |
ジョブのロール
| ロール | 権限 |
|---|---|
| 閲覧者 | dataproc.jobs.get |
| 編集者 | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update |
| オーナー | dataproc.jobs.get dataproc.jobs.cancel dataproc.jobs.delete dataproc.jobs.update dataproc.jobs.setIamPolicy dataproc.jobs.getIamPolicy |
オペレーションのロール
| ロール | 権限 |
|---|---|
| 閲覧者 | dataproc.operations.get |
| 編集者 | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete |
| オーナー | dataproc.jobs.get dataproc.operations.cancel dataproc.operations.delete dataproc.operations.setIamPolicy dataproc.operations.getIamPolicy |
ワークフロー テンプレートのロール
| ロール | 権限 |
|---|---|
| 閲覧者 | dataproc.workflowTemplates.get |
| 編集者 | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update |
| オーナー | dataproc.workflowTemplates.get dataproc.workflowTemplates.delete dataproc.workflowTemplates.update dataproc.workflowTemplates.setIamPolicy dataproc.workflowTemplates.getIamPolicy |
自動スケーリング ポリシーのロール
| ロール | 権限 |
|---|---|
| 閲覧者 | dataproc.autoscalingPolicies.get |
| 編集者 | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update |
| オーナー | dataproc.autoscalingPolicies.get dataproc.autoscalingPolicies.use dataproc.autoscalingPolicies.delete dataproc.autoscalingPolicies.update dataproc.autoscalingPolicies.setIamPolicy dataproc.autoscalingPolicies.getIamPolicy |
Managed Service for Apache Spark のきめ細かい IAM を使用する
このセクションでは、Managed Service for Apache Spark のきめ細かい IAM を使用して、既存の Managed Service for Apache Spark リソースに対するロールをユーザーに割り当てる方法について説明します。Identity and Access Management(IAM)ロールの更新と削除の詳細については、プロジェクト、フォルダ、組織へのアクセスを管理するをご覧ください。
gcloud コマンド
- リソースの IAM ポリシーを取得し、JSON ファイルに書き込みます(resource-type は、clusters、jobs、operations、workflow-templates、または autoscaling-policies になります)。
gcloud dataproc resource-type get-iam-policy resource-id \ --region=region \ --format=json > iam.json
- JSON ファイルの内容は次のようになります。
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - テキスト エディタを使用して、新しいバインディング オブジェクトを bindings 配列に追加し、ユーザーとそのユーザーに対するリソース アクセスのロールを定義します。たとえば、閲覧者ロール(
roles/viewer)をユーザーsean@example.comに付与するには、前の例を変更して新しいバインディング オブジェクトを追加します(次の例の太字の部分)。注:gcloud dataproc resource-type get-iam-policyから受け取ったetag値を必ず返すようにしてください。etag のドキュメントをご覧ください。{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-get-iam-policy" } - 次のコマンドを実行して、新しい bindings 配列でクラスタのポリシーを更新します(resource-type は、clusters、jobs、operations、workflow-templates、または autoscaling-policies になります)。
gcloud dataproc resource-type set-iam-policy resource-name \ --region=region \ --format=json iam.json
- このコマンドでは、更新したポリシーが出力されます。
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
REST API
- resource-type ("clusters" or "jobs" or "operations" or "workflowTemplates" or "autoscalingPolicies") getIamPolicy リクエストを発行して、リソースの IAM ポリシーを取得します。
クラスタ getIamPolicy の例:
GET https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:getIamPolicy
- JSON ファイルの内容は次のようになります。
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] } ], "etag": "string" } - テキスト エディターを使用して、次の JSON ポリシー オブジェクトを作成し、Managed Service for Apache Spark サービスから受け取った bindings 配列を囲みます。getIamPolicy レスポンスで受け取った etag 値を必ず返すようにしてください(etag のドキュメントをご覧ください)。次に、ユーザーと、そのユーザーのクラスタ アクセスのロールを定義する新しいバインディング オブジェクトを bindings 配列に追加します。たとえば、閲覧者ロール(
roles/viewer)をユーザーsean@example.comに付与するには、上記の例を変更して新しいバインディング オブジェクトを追加します(下の太字の部分)。{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } } setIamPolicyリクエストを発行して、更新したポリシーをリソースに設定します。クラスタ setIamPolicy の例:
POST https://dataproc.googleapis.com/v1/projects/projectName/regions/region/clusters/clusterName:setIamPolicy Request body
{ "policy": { "version": "", "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "value-from-getIamPolicy" } }- JSON レスポンスの内容は次のようになります。
レスポンス
{ "bindings": [ { "role": "roles/editor", "members": [ "user:mike@example.com", "group:admins@example.com", "domain:google.com", "serviceAccount:my-other-app@appspot.gserviceaccount.com" ] }, { "role": "roles/viewer", "members": [ "user:sean@example.com" ] } ], "etag": "string" }
コンソール
Google Cloud コンソールの [Managed Service for Apache Spark クラスタ] ページに移動し、クラスタ名の左側のボックスをクリックして、[権限/ラベル] パネルを開きます(このパネルが表示されない場合は、ページの右上にある [情報パネルを表示] をクリックします)。[権限] タブで、Managed Service for Apache Spark ロールを選択し、[プリンシパルを追加] ボックスに 1 つ以上のアカウント アドレスを追加して、[追加] をクリックします。
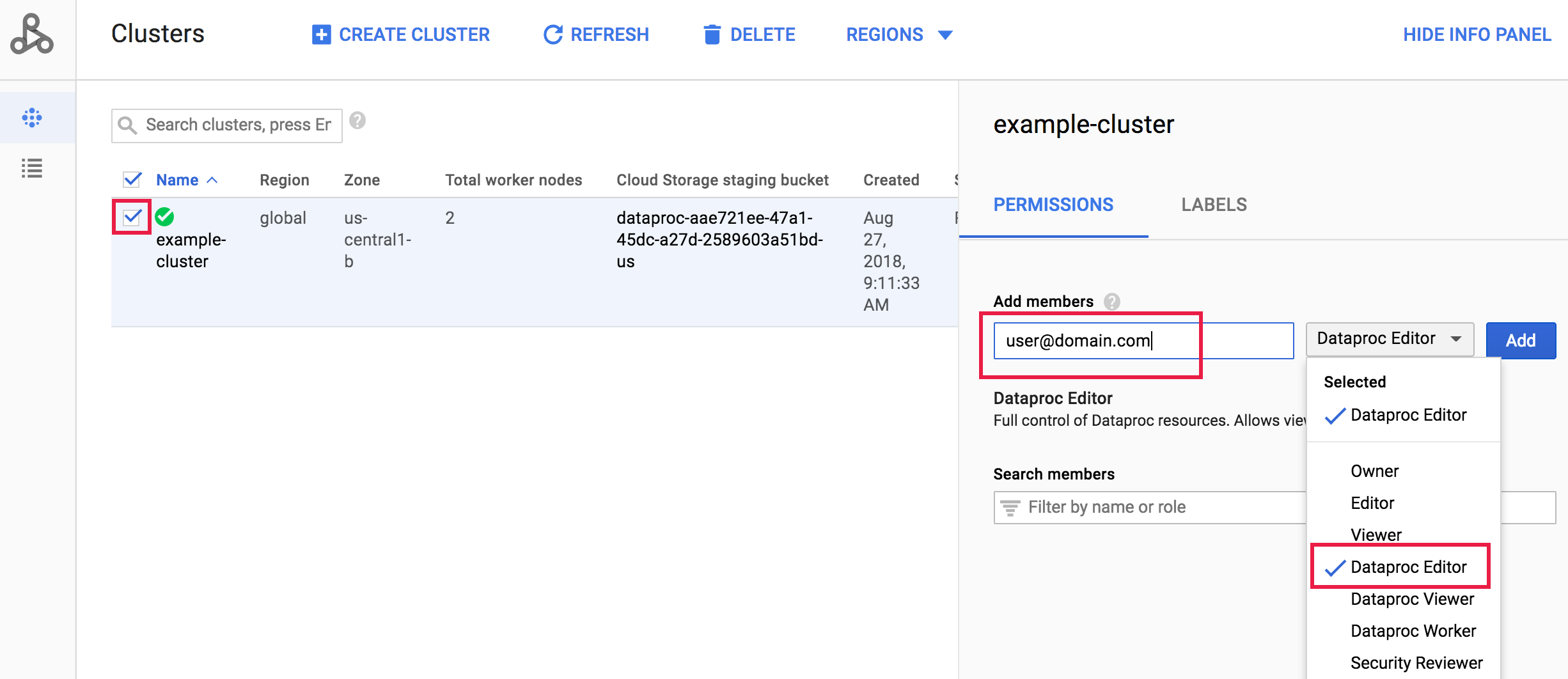
きめ細かい IAM で有効になる SDK コマンド
このセクションでは、きめ細かい IAM ロールにより Managed Service for Apache Spark リソースに対して有効になる gcloud dataproc コマンドについて説明します。
クラスタ
| IAM ロール | コマンド |
|---|---|
| 閲覧者 | gcloud dataproc clusters describe cluster-name |
| 編集者 | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-name |
| オーナー | gcloud dataproc clusters describe cluster-namegcloud dataproc clusters listgcloud dataproc clusters delete cluster-namegcloud dataproc clusters diagnose cluster-namegcloud dataproc clusters update cluster-namegcloud beta dataproc clusters start cluster-namegcloud beta dataproc clusters stop cluster-namegcloud dataproc clusters get-iam-policy cluster-namegcloud dataproc clusters set-iam-policy cluster-name |
ジョブ
| IAM ロール | コマンド |
|---|---|
| 閲覧者 | gcloud dataproc jobs describe job-id |
| 編集者 | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-id |
| オーナー | gcloud dataproc jobs delete job-idgcloud dataproc jobs describe job-idgcloud dataproc jobs kill job-idgcloud dataproc jobs update job-idgcloud dataproc jobs wait job-idgcloud dataproc jobs get-iam-policy job-idgcloud dataproc jobs set-iam-policy job-id |
運用
| IAM ロール | コマンド |
|---|---|
| 閲覧者 | gcloud dataproc operations describe operation-id |
| 編集者 | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-id |
| オーナー | gcloud dataproc operations delete operation-idgcloud dataproc operations describe operation-idgcloud dataproc operations cancel operation-idgcloud dataproc operations get-iam-policy operation-idgcloud dataproc operations set-iam-policy operation-id |
ワークフロー テンプレート
| IAM ロール | コマンド |
|---|---|
| 閲覧者 | gcloud dataproc workflow-templates describe template-id |
| 編集者 | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-id |
| オーナー | gcloud dataproc workflow-templates delete template-idgcloud dataproc workflow-templates describe template-idgcloud dataproc workflow-templates remove-job template-idgcloud dataproc workflow-templates run template-idgcloud dataproc workflow-templates get-iam-policy template-idgcloud dataproc workflow-templates set-iam-policy template-id |
自動スケーリング ポリシー
| IAM ロール | コマンド |
|---|---|
| 閲覧者 | gcloud dataproc autoscaling-policies describe policy-id |
| 編集者 | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-id |
| オーナー | gcloud dataproc autoscaling-policies delete policy-idgcloud dataproc autoscaling-policies describe policy-idgcloud dataproc autoscaling-policies update policy-idgcloud dataproc clusters create cluster-name --autoscaling-policy policy-idgcloud dataproc autoscaling-policies get-iam-policy policy-idgcloud dataproc autoscaling-policies set-iam-policy policy-id |
きめ細かい IAM を使用してジョブを送信する
Managed Service for Apache Spark Granular IAM を使用してプリンシパル(ユーザー、グループまたはサービス アカウント)が指定されたクラスタにジョブを送信できるようにするには、ユーザーにクラスタでの編集者のロールを付与するだけでなく、プロジェクト レベルで追加の権限を設定する必要があります。指定した Managed Service for Apache Spark クラスタでプリンシパルがジョブを送信できるようにするための手順は次のとおりです。
- クラスタが Cloud Storage に接続するために使用できる Cloud Storage バケットを作成します。
- プリンシパルをバケットレベルのポリシーに追加し、そのメンバーの Storage オブジェクト閲覧者ロールを選択します(
roles/storage.objectViewerをご覧ください)。このロールには次の権限が含まれています。storage.objects.getstorage.objects.list
- クラスタの作成時に、
--bucketパラメータを使用して、作成したバケットの名前をクラスタに渡します(gcloud dataproc clusters create --bucketをご覧ください)。 - クラスタを作成したら、プリンシパルに編集者またはオーナーのロールを付与するポリシーをそのクラスタに設定します(Managed Service for Apache Spark のきめ細かい IAM を使用するをご覧ください)。
- 次の権限を持つ IAM カスタムロールを作成します。
dataproc.jobs.createdataproc.jobs.get
- Google Cloud コンソールの [IAM] ページでプリンシパルを選択または追加し、カスタムロールを選択してそのプリンシパルに適用します。